
 Périphériques technologiques
IA
Explorer les limites des agents : AgentQuest, un cadre de référence modulaire pour mesurer et améliorer de manière globale les performances des grands agents de modèles de langage
Périphériques technologiques
IA
Explorer les limites des agents : AgentQuest, un cadre de référence modulaire pour mesurer et améliorer de manière globale les performances des grands agents de modèles de langage
Explorer les limites des agents : AgentQuest, un cadre de référence modulaire pour mesurer et améliorer de manière globale les performances des grands agents de modèles de langage

Basées sur l'optimisation continue de grands modèles, les agents LLM - ces puissantes entités algorithmiques ont montré leur potentiel pour résoudre des tâches de raisonnement complexes en plusieurs étapes. Du traitement du langage naturel à l'apprentissage profond, les agents LLM deviennent progressivement le centre d'intérêt de la recherche et de l'industrie. Ils peuvent non seulement comprendre et générer le langage humain, mais également formuler des stratégies, effectuer des tâches dans divers environnements et même utiliser des appels d'API et du codage pour créer. solutions.
Dans ce contexte, la proposition du framework AgentQuest constitue une étape importante. Il fournit non seulement une plateforme de benchmarking modulaire pour l'évaluation et la progression des agents LLM, mais fournit également une plateforme de recherche grâce à son API facile à étendre. . Personnel fournit un outil puissant pour suivre et améliorer les performances de ces agents à un niveau plus granulaire. Le cœur d'AgentQuest réside dans ses indicateurs d'évaluation innovants - taux de progression et taux de répétition, qui peuvent révéler le modèle de comportement de l'agent dans la résolution des tâches, guidant ainsi l'optimisation et l'ajustement de l'architecture.
"AgentQuest : Un cadre de référence modulaire pour mesurer les progrès et améliorer les agents LLM" est rédigé par une équipe de recherche diversifiée des laboratoires européens NEC, du Politecnico di Torino et de l'université allemande San Cyril y Medo. Cet article sera présenté lors du chapitre nord-américain de la conférence 2024 de l'Association for Computational Linguistics (NAACL-HLT 2024), qui marque que les résultats de recherche de l'équipe dans le domaine de la technologie du langage humain ont été reconnus par leurs pairs, ce qui n'est pas seulement la valeur du cadre AgentQuest La reconnaissance est également une affirmation du potentiel de développement futur des agents LLM.
En tant qu'outil de mesure et d'amélioration des capacités des agents de grands modèles de langage (LLM), la principale contribution du framework AgentQuest est de fournir une plateforme de benchmarking modulaire et évolutive. Cette plate-forme peut non seulement évaluer les performances d'un agent sur une tâche spécifique, mais également révéler le modèle de comportement de l'agent en train de résoudre le problème en montrant le modèle de comportement de l'agent en train de résoudre le problème. L'avantage d'AgentQuest est sa flexibilité et son ouverture, qui permettent aux chercheurs de personnaliser les benchmarks en fonction de leurs besoins, favorisant ainsi le développement de la technologie des agents LLM.
Présentation du framework AgentQuest
Le framework AgentQuest est un outil de recherche innovant conçu pour mesurer et améliorer les performances des agents de modèles de langage à grande échelle (LLM). Il permet aux chercheurs de suivre systématiquement les progrès d'un agent dans l'exécution de tâches complexes et d'identifier les domaines potentiels d'amélioration en fournissant une série modulaire de références et de mesures d'évaluation.
AgentQuest est un framework modulaire qui prend en charge plusieurs benchmarks et architectures d'agents. Il introduit deux nouvelles métriques - le taux de progression et le taux de répétition - pour évaluer le comportement des architectures d'agents. Ce cadre définit une interface standard pour connecter des architectures d'agents arbitraires à un ensemble diversifié de références et calculer les taux de progression et de répétition à partir de ceux-ci.
Dans AgentQuest, quatre tests de référence ont été inclus : ALFWorld, Lateral Thinking Puzzles, Mastermind et Numerical Solitude. De plus, AgentQuest introduit également de nouveaux tests. Vous pouvez facilement ajouter des tests supplémentaires sans apporter de modifications aux agents testés.
 Photos
Photos
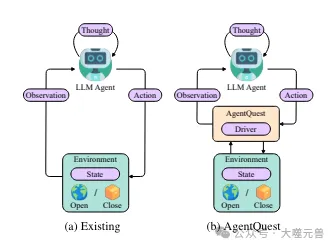
Figure 1 : Aperçu de l'interaction de base des agents dans le cadre actuel AgentQuest. AgentQuest définit une interface commune pour interagir avec les benchmarks et calculer les mesures de progression, simplifiant l'ajout de nouveaux benchmarks et permettant aux chercheurs d'évaluer et de tester leurs architectures d'agents.
Composition et fonctionnalité de base
Le cœur du framework AgentQuest est sa conception modulaire, qui permet aux chercheurs d'ajouter ou de modifier des benchmarks selon leurs besoins. Cette flexibilité est obtenue en séparant les benchmarks et les mesures d'évaluation en modules indépendants, chacun pouvant être développé et optimisé indépendamment. Les principaux composants du framework incluent :
Module Benchmark : ce sont des tâches prédéfinies que l'agent doit effectuer. Ils vont des simples jeux de mots aux énigmes logiques complexes.
Module d'indicateurs d'évaluation : fournit un ensemble d'outils pour quantifier les performances des agents, tels que le taux de progression et le taux de répétition. Ces indicateurs aident les chercheurs à comprendre le modèle de comportement des agents dans les tâches.
Interface API : permet aux chercheurs de connecter leurs propres architectures d'agents au framework AgentQuest, ainsi que d'interagir avec des sources de données et des services externes.
L'importance des benchmarks et des métriques modulaires
Un avantage clé des benchmarks modulaires est qu'ils fournissent un moyen standardisé d'évaluer les performances de différents agents. Cela signifie que les chercheurs peuvent comparer les résultats de différents agents dans les mêmes conditions, garantissant ainsi la cohérence et la comparabilité des résultats. En outre, la conception modulaire permet également aux chercheurs d'adapter les critères de référence aux besoins d'études spécifiques, ce qui est souvent difficile à réaliser dans les cadres d'analyse comparative traditionnels.
Les mesures d’évaluation sont tout aussi importantes car elles fournissent des informations approfondies sur les performances de l’agent. Par exemple, le taux de progression peut montrer l'efficacité d'un agent dans la résolution d'une tâche, tandis que le taux de répétition révèle si un agent reste bloqué dans les répétitions de certaines étapes, ce qui pourrait indiquer la nécessité d'améliorer le processus de prise de décision.
Extensibilité d'AgentQuest
L'interface API d'AgentQuest est la clé de son évolutivité. Grâce à l'API, les chercheurs peuvent facilement intégrer AgentQuest dans les flux de travail de recherche existants, qu'il s'agisse d'ajouter de nouveaux points de référence, de mesures d'évaluation ou de se connecter à des sources de données et à des services externes. Cette évolutivité accélère non seulement le processus itératif de recherche, mais favorise également la collaboration interdisciplinaire, car des experts de différents domaines peuvent travailler ensemble pour résoudre des questions de recherche communes à l'aide du cadre AgentQuest.
Le framework AgentQuest fournit une plate-forme puissante pour la recherche et le développement d'agents LLM grâce à ses métriques d'analyse comparative et d'évaluation modulaires, et à son extensibilité via des API. Cela favorise non seulement la standardisation et la reproductibilité de la recherche, mais ouvre également la voie à de futures innovations et collaborations entre agents intelligents.
Metriques de benchmarking et d'évaluation
Dans le cadre AgentQuest, l'analyse comparative est un élément clé pour évaluer les performances des agents LLM. Ces tests fournissent non seulement un environnement standardisé pour comparer les capacités de différents agents, mais peuvent également révéler les modèles de comportement des agents lors de la résolution de problèmes spécifiques.
AgentQuest expose une seule interface Python unifiée, à savoir le pilote et deux classes qui reflètent les composants de l'interaction agent-environnement (c'est-à-dire les observations et les actions). La classe d'observation a deux propriétés requises : (i) sortie, une chaîne rapportant des informations sur l'état de l'environnement (ii) achèvement, une variable booléenne indiquant si la tâche finale est actuellement terminée ; Les classes d'action ont un attribut obligatoire, la valeur d'action. Il s'agit de la chaîne générée directement par l'agent. Une fois traité et fourni à l’environnement, il déclenche des changements dans l’environnement. Pour personnaliser les interactions, les développeurs peuvent définir des propriétés facultatives.
Mastermind Benchmark
Mastermind est un jeu de logique classique dans lequel les joueurs doivent deviner un code couleur caché. Dans le cadre AgentQuest, ce jeu est utilisé comme l'un des points de référence, où l'agent est chargé de déterminer le code correct à travers une série de suppositions. Après chaque supposition, l'environnement fournit un retour indiquant à l'agent combien de couleurs étaient correctes mais dans de mauvaises positions, et combien étaient correctes dans les couleurs et les positions. Ce processus se poursuit jusqu'à ce que l'agent devine le code correct ou atteigne une limite prédéfinie d'étapes.
 Figure 2 : Nous fournissons ici un exemple de Mastermind mettant en œuvre l'interaction.
Figure 2 : Nous fournissons ici un exemple de Mastermind mettant en œuvre l'interaction.
Sudoku Benchmark
Le Sudoku est un autre puzzle logique populaire qui oblige les joueurs à remplir des nombres dans une grille 9x9 afin que chaque ligne, chaque colonne et chaque sous-grille 3x3 n'ait aucun nombre répété. Dans le cadre AgentQuest, le Sudoku est utilisé comme référence pour évaluer les capacités d'un agent en matière de raisonnement et de planification spatiale. L'agent doit générer des stratégies efficaces de remplissage de nombres et résoudre l'énigme en un nombre limité de mouvements.
Métriques d'évaluation : taux de progression et taux de répétition
AgentQuest introduit deux nouvelles mesures d'évaluation : le taux de progression (PR) et le taux de répétition (RR). Le taux de progression est une valeur comprise entre 0 et 1 qui mesure la progression de l'agent dans l'accomplissement d'une tâche. Il est calculé en divisant le nombre de jalons atteints par l'agent par le nombre total de jalons. Par exemple, dans le jeu Mastermind, si l'agent devine deux couleurs et emplacements corrects sur un total de quatre suppositions, le taux de progression est de 0,5.
Le taux de répétition mesure la tendance d'un agent à répéter des actions identiques ou similaires lors de l'exécution d'une tâche. Lors du calcul du taux de répétition, toutes les actions précédentes de l'agent sont prises en compte et une fonction de similarité est utilisée pour déterminer si l'action en cours est similaire aux actions précédentes. Le taux de répétition est calculé en divisant le nombre de répétitions par le nombre total de répétitions (moins la première étape).
Évaluez et améliorez les performances des agents LLM grâce à des métriques
Ces métriques fournissent aux chercheurs un outil puissant pour analyser et améliorer les performances des agents LLM. En observant les taux de progression, les chercheurs peuvent comprendre l’efficacité d’un agent pour résoudre un problème et identifier d’éventuels goulots d’étranglement. Dans le même temps, l'analyse des taux de redoublement peut révéler d'éventuels problèmes dans le processus de prise de décision de l'agent, comme une dépendance excessive à l'égard de certaines stratégies ou un manque d'innovation.
 Tableau 1 : Aperçu des benchmarks disponibles dans AgentQuest.
Tableau 1 : Aperçu des benchmarks disponibles dans AgentQuest.
En général, les indicateurs de test et d'évaluation de référence dans le cadre AgentQuest fournissent un système d'évaluation complet pour le développement d'agents LLM. Grâce à ces outils, les chercheurs peuvent non seulement évaluer les performances actuelles des agents, mais également guider les futures améliorations, favorisant ainsi l'application et le développement d'agents LLM dans diverses tâches complexes.
Cas d'application d'AgentQuest
Les cas d'application réels du framework AgentQuest fournissent une compréhension approfondie de ses fonctions et de ses effets grâce à Mastermind et à d'autres tests de référence, nous pouvons observer les performances des agents LLM dans différents scénarios. , et analyser comment leurs performances peuvent être améliorées grâce à des stratégies spécifiques.
Cas d'application Mastermind
Dans le jeu Mastermind, le framework AgentQuest est utilisé pour évaluer la capacité de raisonnement logique de l'agent. L'agent doit deviner un code caché composé de chiffres, et après chaque supposition, le système fournit un retour indiquant le numéro et l'emplacement du numéro correct. Grâce à ce processus, l'agent apprend à ajuster sa stratégie de deviner en fonction des commentaires pour atteindre ses objectifs plus efficacement.
Dans les applications pratiques, les performances initiales de l'agent peuvent ne pas être idéales et des suppositions identiques ou similaires sont souvent répétées, ce qui entraîne un taux de répétition élevé. Cependant, en analysant les données sur les taux de progression et de répétition, les chercheurs peuvent identifier les lacunes du processus décisionnel de l'agent et prendre des mesures pour l'améliorer. Par exemple, en introduisant un composant de mémoire, l'agent peut se souvenir des suppositions précédentes et éviter de répéter des tentatives inefficaces, améliorant ainsi l'efficacité et la précision.
Cas d'application d'autres benchmarks
En plus de Mastermind, AgentQuest comprend également d'autres benchmarks tels que le Sudoku, les jeux de mots et les puzzles logiques. Dans ces tests, les performances de l'agent sont également affectées par les mesures du taux de progression et du taux de répétition. Par exemple, dans le test Sudoku, l'agent doit remplir une grille 9x9 afin que les nombres de chaque ligne, chaque colonne et chaque sous-grille 3x3 ne soient pas répétés. Cela nécessite que l'agent ait des capacités de raisonnement spatial et des capacités de planification stratégique.
Dans ces tests, l'agent peut rencontrer différents défis. Certains agents peuvent être excellents en raisonnement spatial mais déficients en planification stratégique. Grâce aux commentaires détaillés fournis par le framework AgentQuest, les chercheurs peuvent identifier les zones problématiques de manière ciblée et améliorer les performances globales de l'agent grâce à l'optimisation des algorithmes ou à l'ajustement des méthodes de formation.
L'impact des composants mémoire
L'ajout de composants mémoire a un impact significatif sur les performances de l'agent. Dans le test Mastermind, après avoir ajouté le composant mémoire, l'agent a pu éviter de répéter des suppositions invalides, réduisant ainsi considérablement le taux de répétition. Cela augmente non seulement la vitesse à laquelle l’agent résout les problèmes, mais augmente également le taux de réussite. De plus, le composant mémoire permet également à l’agent d’apprendre et de s’adapter plus rapidement face à des problèmes similaires, améliorant ainsi son efficacité d’apprentissage à long terme.
Dans l'ensemble, le framework AgentQuest fournit un outil puissant pour l'évaluation et l'amélioration des performances des agents LLM en fournissant des mesures d'analyse comparative et d'évaluation modulaires. Grâce à l'analyse de cas d'application réels, nous pouvons constater que les performances de l'agent peuvent être considérablement améliorées en ajustant la stratégie et en introduisant de nouveaux composants, tels que des modules de mémoire.
Configuration expérimentale et analyse des résultats
Dans la configuration expérimentale du framework AgentQuest, les chercheurs ont adopté une architecture de référence basée sur un agent de chat prêt à l'emploi piloté par un grand modèle de langage (LLM) tel que GPT-4. Cette architecture a été choisie car elle est intuitive, facilement extensible et open source, ce qui permet aux chercheurs d'intégrer et de tester facilement différentes stratégies d'agent.
 Photos
Photos
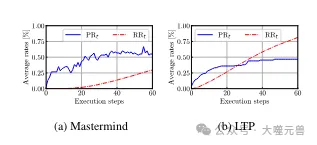
Figure 4 : Taux de progression moyen PRt et taux de répétition RRt pour Mastermind et LTP. Mastermind : RRt est faible au début, mais augmentera après l'étape 22, tandis que la progression s'arrêtera également à 55 %. LTP : initialement, un RRt plus élevé permet aux agents de réussir en effectuant de petits changements, mais plus tard, cela se stabilise.
Configuration expérimentale
La configuration expérimentale comprend plusieurs tests de référence, tels que Mastermind et ALFWorld, chaque test est conçu pour évaluer les performances de l'agent dans un domaine spécifique. Le nombre maximum d'étapes d'exécution est défini dans l'expérience, généralement 60 étapes, afin de limiter le nombre de tentatives que l'agent peut tenter pour résoudre le problème. Cette limitation simule la situation de ressources limitées dans le monde réel et oblige l'agent à trouver la solution la plus efficace dans des tentatives limitées.
Analyse des résultats expérimentaux
Dans le test de référence Mastermind, les résultats expérimentaux montrent que le taux de répétition de l'agent sans composant de mémoire est relativement élevé et le taux de progression est également limité. Cela montre que les agents ont tendance à répéter des suppositions invalides lorsqu’ils tentent de résoudre des problèmes. Cependant, lorsque le composant mémoire a été introduit, les performances de l'agent ont été considérablement améliorées, le taux de réussite passant de 47 % à 60 % et le taux de répétition tombant à 0 %. Cela montre que le composant mémoire est crucial pour améliorer l’efficacité et la précision de l’agent.
 Photos
Photos
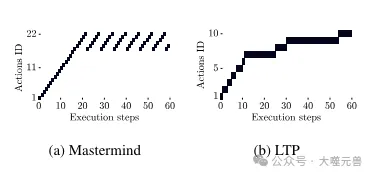
Figure 5 : Exemple d'opérations répétées dans Mastermind et LTP. Mastermind : commence par une série de mouvements uniques, mais se retrouve ensuite coincé à répéter les mêmes mouvements encore et encore. LTP : les actions répétées sont de petites variations sur le même problème qui conduisent à des progrès.
Dans le benchmark ALFWorld, l'agent doit explorer un monde textuel pour localiser des objets. Les résultats expérimentaux montrent que bien que l'agent ait limité les répétitions d'actions lors de l'exploration de l'espace de solutions (RR60 = 6 %), il n'a pas réussi à résoudre tous les jeux (PR60 = 74 %). Cette différence peut être due au fait que l’agent nécessite davantage d’étapes d’exploration lors de la découverte d’objets. En étendant la durée d'exécution du test à 120 étapes, les taux de réussite et de progression se sont améliorés, confirmant ainsi l'utilité d'AgentQuest pour comprendre les échecs des agents.
Ajustement de l'architecture des agents
Selon les indicateurs d'AgentQuest, les chercheurs peuvent ajuster l'architecture des agents. Par exemple, si vous constatez qu’un agent se répète à un rythme élevé sur un certain benchmark, son algorithme de prise de décision devra peut-être être amélioré pour éviter de répéter des tentatives inefficaces. De même, si le taux de progression est faible, le processus d'apprentissage de l'agent devra peut-être être optimisé pour s'adapter plus rapidement à l'environnement et trouver des solutions aux problèmes.
Les mesures de configuration expérimentale et d'évaluation fournies par le framework AgentQuest fournissent des informations approfondies sur les performances des agents LLM. En analysant les résultats expérimentaux, les chercheurs peuvent identifier les forces et les faiblesses d'un agent et ajuster son architecture en conséquence pour améliorer ses performances dans diverses tâches.
Discussion et travaux futurs
La proposition du framework AgentQuest a ouvert une nouvelle voie pour la recherche et le développement d'agents à grand modèle de langage (LLM). Il fournit non seulement une méthode systématique pour mesurer et améliorer les performances des agents LLM, mais favorise également la compréhension approfondie du comportement des agents par la communauté des chercheurs.
L'impact potentiel d'AgentQuest dans la recherche d'agents LLM
AgentQuest permet aux chercheurs de mesurer plus précisément les progrès et l'efficacité des agents LLM sur des tâches spécifiques grâce à ses mesures d'analyse comparative et d'évaluation modulaires. Cette capacité d’évaluation précise est essentielle pour concevoir des agents plus efficaces et plus intelligents. Alors que les agents LLM sont de plus en plus utilisés dans divers domaines, du service client au traitement du langage naturel, les outils d'analyse approfondie fournis par AgentQuest aideront les chercheurs à optimiser le processus décisionnel de l'agent et à améliorer ses performances dans les applications pratiques.
Le rôle d'AgentQuest dans la promotion de la transparence et de l'équité
Une autre contribution importante d'AgentQuest est d'augmenter la transparence de la recherche d'agents LLM. Grâce à des mesures d'évaluation publiques et à des références reproductibles, AgentQuest encourage la pratique de la science ouverte, rendant les résultats de recherche plus facilement vérifiés et comparés. De plus, la nature modulaire d'AgentQuest permet aux chercheurs de personnaliser les critères de référence, ce qui signifie que les tests peuvent être conçus pour différents besoins et contextes, favorisant ainsi la diversité et l'inclusion dans la recherche.
Le développement futur d'AgentQuest et les contributions possibles de la communauté de recherche
Suite aux progrès de la technologie, le cadre AgentQuest devrait continuer à être étendu et amélioré. Avec l'ajout de nouveaux benchmarks et indicateurs d'évaluation, AgentQuest sera en mesure de couvrir davantage de types de tâches et de scénarios, offrant ainsi une perspective plus complète pour l'évaluation des agents LLM. De plus, avec les progrès de la technologie de l'intelligence artificielle, AgentQuest peut également intégrer des fonctions plus avancées, telles que la possibilité d'ajuster automatiquement l'architecture de l'agent pour obtenir une optimisation plus efficace des performances.
La contribution de la communauté des chercheurs à AgentQuest fait également partie intégrante de son développement. La nature open source signifie que les chercheurs peuvent partager leurs améliorations et innovations, accélérant ainsi l'avancement du framework AgentQuest. Dans le même temps, les commentaires et l'expérience pratique de la communauté des chercheurs aideront AgentQuest à mieux répondre aux besoins des applications pratiques et à promouvoir le développement de la technologie des agents LLM.
Référence : https://arxiv.org/abs/2404.06411
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Méthode de Navicat pour afficher le mot de passe de la base de données MongoDB
Apr 08, 2025 pm 09:39 PM
Il est impossible de visualiser le mot de passe MongoDB directement via NAVICAT car il est stocké sous forme de valeurs de hachage. Comment récupérer les mots de passe perdus: 1. Réinitialiser les mots de passe; 2. Vérifiez les fichiers de configuration (peut contenir des valeurs de hachage); 3. Vérifiez les codes (May Code Hardcode).
 MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL a-t-il besoin d'Internet
Apr 08, 2025 pm 02:18 PM
MySQL peut s'exécuter sans connexions réseau pour le stockage et la gestion des données de base. Cependant, la connexion réseau est requise pour l'interaction avec d'autres systèmes, l'accès à distance ou l'utilisation de fonctionnalités avancées telles que la réplication et le clustering. De plus, les mesures de sécurité (telles que les pare-feu), l'optimisation des performances (choisissez la bonne connexion réseau) et la sauvegarde des données sont essentielles pour se connecter à Internet.
 MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut-il se connecter à MariaDB
Apr 08, 2025 pm 02:33 PM
MySQL Workbench peut se connecter à MARIADB, à condition que la configuration soit correcte. Sélectionnez d'abord "MariADB" comme type de connecteur. Dans la configuration de la connexion, définissez correctement l'hôte, le port, l'utilisateur, le mot de passe et la base de données. Lorsque vous testez la connexion, vérifiez que le service MARIADB est démarré, si le nom d'utilisateur et le mot de passe sont corrects, si le numéro de port est correct, si le pare-feu autorise les connexions et si la base de données existe. Dans une utilisation avancée, utilisez la technologie de mise en commun des connexions pour optimiser les performances. Les erreurs courantes incluent des autorisations insuffisantes, des problèmes de connexion réseau, etc. Lors des erreurs de débogage, analysez soigneusement les informations d'erreur et utilisez des outils de débogage. L'optimisation de la configuration du réseau peut améliorer les performances
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comment résoudre MySQL ne peut pas se connecter à l'hôte local
Apr 08, 2025 pm 02:24 PM
Comment résoudre MySQL ne peut pas se connecter à l'hôte local
Apr 08, 2025 pm 02:24 PM
La connexion MySQL peut être due aux raisons suivantes: le service MySQL n'est pas démarré, le pare-feu intercepte la connexion, le numéro de port est incorrect, le nom d'utilisateur ou le mot de passe est incorrect, l'adresse d'écoute dans my.cnf est mal configurée, etc. 2. Ajustez les paramètres du pare-feu pour permettre à MySQL d'écouter le port 3306; 3. Confirmez que le numéro de port est cohérent avec le numéro de port réel; 4. Vérifiez si le nom d'utilisateur et le mot de passe sont corrects; 5. Assurez-vous que les paramètres d'adresse de liaison dans My.cnf sont corrects.
 Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
Comment utiliser Aws Glue Crawler avec Amazon Athena
Apr 09, 2025 pm 03:09 PM
En tant que professionnel des données, vous devez traiter de grandes quantités de données provenant de diverses sources. Cela peut poser des défis à la gestion et à l'analyse des données. Heureusement, deux services AWS peuvent aider: AWS Glue et Amazon Athena.
