
 Périphériques technologiques
IA
Un texte long ne peut pas tuer RAG : le vecteur SQL+ pilote les grands modèles et le nouveau paradigme du Big Data, la base de données MyScale AI est officiellement open source
Périphériques technologiques
IA
Un texte long ne peut pas tuer RAG : le vecteur SQL+ pilote les grands modèles et le nouveau paradigme du Big Data, la base de données MyScale AI est officiellement open source
Un texte long ne peut pas tuer RAG : le vecteur SQL+ pilote les grands modèles et le nouveau paradigme du Big Data, la base de données MyScale AI est officiellement open source

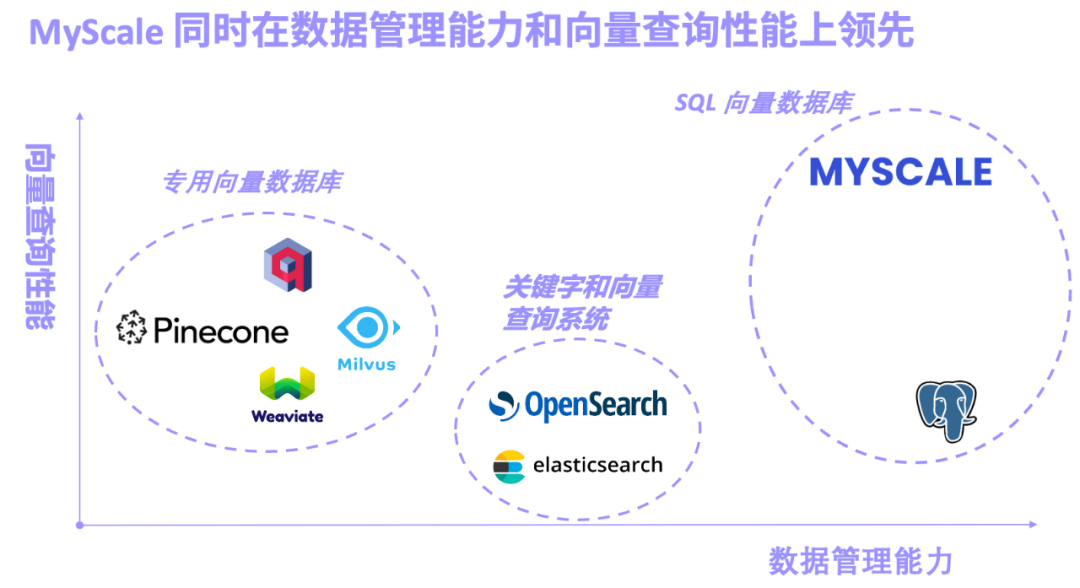
La combinaison de grands modèles et de bases de données d'IA est devenue une formule gagnante pour réduire les coûts et augmenter l'efficacité des grands modèles et rendre le Big Data véritablement intelligent.

Les bases de données vectorielles spécialisées représentées par Pinecone/Weaviate/Milvus sont conçues et construites pour la récupération de vecteurs dès le début. Les performances de récupération de vecteurs sont excellentes, mais la fonction générale de gestion des données est faible. Les systèmes de récupération de mots-clés et de vecteurs représentés par Elasticsearch/OpenSearch sont largement utilisés en production en raison de leurs fonctions complètes de récupération de mots-clés. Cependant, ils occupent beaucoup de ressources système et la précision des requêtes conjointes et les performances des mots-clés et des vecteurs ne sont pas satisfaisantes. . Les gens obtiennent ce qu’ils veulent. Les bases de données vectorielles SQL représentées par pgvector (plug-in de recherche vectorielle pour PostgreSQL) et la base de données MyScale AI sont basées sur SQL et disposent de puissantes fonctions de gestion de données. Cependant, en raison des inconvénients du stockage de lignes PostgreSQL et des limitations des algorithmes vectoriels, pgvector a une faible précision dans les requêtes vectorielles complexes.
Grâce au perfectionnement à long terme de la base de données SQL dans des scénarios de données structurées massives, MyScaleDB
Dans les scénarios d'application d'IA complexes réels, la combinaison de SQL et de vecteurs peut considérablement augmenter la flexibilité de la modélisation des données et simplifier le processus de développement. Par exemple, dans le projet Science Navigator coopérant entre l'équipe MyScale et l'Institut d'intelligence scientifique de Pékin, MyScaleDB est utilisé pour récupérer des données massives de la littérature scientifique et effectuer des réponses intelligentes aux questions. Il existe plus de 10 structures de tables SQL principales, dont beaucoup établissent. vecteurs.Et index de table inversé, et utilisez la clé primaire et la clé étrangère pour faire l'association. Dans les requêtes réelles, le système impliquera également des requêtes conjointes de données structurées, vectorielles et par mots-clés, ainsi que des requêtes associées sur plusieurs tables. Ces modélisations et corrélations sont difficiles à réaliser dans une base de données vectorielles dédiée, ce qui entraînera également une itération lente du système final, des requêtes inefficaces et une maintenance difficile.
Diagramme schématique de la structure de la table principale de NScience Navigator (les colonnes de corps en gras établissent des index vectoriels ou des index inversés)
60 %
L'équilibre entre performances et coûts dans les scènes réelles En raison de l'importance et de la grande attention accordée aux applications de grands modèles, de plus en plus d'équipes ont investi dans la piste des bases de données vectorielles. L’objectif initial de tout le monde était d’améliorer le QPS dans les scénarios de recherche vectorielle pure, mais la
Dans le scénario RAG, les performances des requêtes vectorielles pures ont un excès de 10x, les vecteurs occupent d'énormes ressources, le manque de fonctions de requête conjointes, les performances et la précision médiocres sont souvent la norme dans les bases de données vectorielles propriétaires actuelles.
Adresse du projet MyScale Vector Database Benchmark :
Machine learning + big data ont fait le succès d'Internet et de la précédente génération de systèmes d'information A l'ère des big models, l'équipe MyScale s'engage également à proposer une nouvelle génération de solutions big model + big data. Avec une
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment supprimer un référentiel par git
Apr 17, 2025 pm 04:03 PM
Comment supprimer un référentiel par git
Apr 17, 2025 pm 04:03 PM
Pour supprimer un référentiel GIT, suivez ces étapes: Confirmez le référentiel que vous souhaitez supprimer. Suppression locale du référentiel: utilisez la commande RM -RF pour supprimer son dossier. Supprimer à distance un entrepôt: accédez à l'entrepôt, trouvez l'option "Supprimer l'entrepôt" et confirmez l'opération.
 Comment générer des clés SSH dans Git
Apr 17, 2025 pm 01:36 PM
Comment générer des clés SSH dans Git
Apr 17, 2025 pm 01:36 PM
Afin de se connecter en toute sécurité à un serveur GIT distant, une clé SSH contenant des clés publiques et privées doit être générée. Les étapes pour générer une touche SSH sont les suivantes: Ouvrez le terminal et entrez la commande ssh-keygen -t rsa -b 4096. Sélectionnez l'emplacement d'enregistrement de la clé. Entrez une phrase de mot de passe pour protéger la clé privée. Copiez la clé publique sur le serveur distant. Enregistrez correctement la clé privée car ce sont les informations d'identification pour accéder au compte.
 Comment télécharger des projets GIT vers local
Apr 17, 2025 pm 04:36 PM
Comment télécharger des projets GIT vers local
Apr 17, 2025 pm 04:36 PM
Pour télécharger des projets localement via GIT, suivez ces étapes: installer Git. Accédez au répertoire du projet. Clonage du référentiel distant à l'aide de la commande suivante: Git Clone https://github.com/username/repository-name.git
 Que faire si le téléchargement git n'est pas actif
Apr 17, 2025 pm 04:54 PM
Que faire si le téléchargement git n'est pas actif
Apr 17, 2025 pm 04:54 PM
Résolve: lorsque la vitesse de téléchargement GIT est lente, vous pouvez prendre les étapes suivantes: Vérifiez la connexion réseau et essayez de changer la méthode de connexion. Optimiser la configuration GIT: augmenter la taille du tampon post (Git Config - Global Http.PostBuffer 524288000) et réduire la limite à basse vitesse (Git Config - Global Http.LowspeedLimit 1000). Utilisez un proxy GIT (comme Git-Proxy ou Git-LFS-Proxy). Essayez d'utiliser un client GIT différent (comme SourceTree ou GitHub Desktop). Vérifiez la protection contre les incendies
 Comment ajouter des clés publiques au compte GIT
Apr 17, 2025 pm 02:42 PM
Comment ajouter des clés publiques au compte GIT
Apr 17, 2025 pm 02:42 PM
Comment ajouter une clé publique à un compte GIT? Étape: générer une paire de clés SSH. Copiez la clé publique. Ajoutez une clé publique dans Gitlab ou GitHub. Testez la connexion SSH.
 Comment gérer le conflit du code GIT
Apr 17, 2025 pm 02:51 PM
Comment gérer le conflit du code GIT
Apr 17, 2025 pm 02:51 PM
Le conflit de code fait référence à un conflit qui se produit lorsque plusieurs développeurs modifient le même morceau de code et provoquent la fusion de Git sans sélectionner automatiquement les modifications. Les étapes de résolution incluent: ouvrez le fichier contradictoire et découvrez le code contradictoire. Furiez le code manuellement et copiez les modifications que vous souhaitez maintenir dans le marqueur de conflit. Supprimer la marque de conflit. Enregistrer et soumettre des modifications.
 Comment utiliser Git Rebase
Apr 17, 2025 pm 04:00 PM
Comment utiliser Git Rebase
Apr 17, 2025 pm 04:00 PM
Git Rebase est utilisé pour réappliquer une nouvelle ligne de base pour nettoyer l'historique ou déplacer les branches. Comment utiliser: Créer une branche cible Sélectionnez le commit à réappliquer et exécuter la commande GIT Rebase, spécifier la branche cible et la portée de la validation pour résoudre les conflits, continuer à réappliquer les modifications de vérification des engagements restants.
 Comment résoudre le problème de recherche efficace dans les projets PHP? Typesense vous aide à y parvenir!
Apr 17, 2025 pm 08:15 PM
Comment résoudre le problème de recherche efficace dans les projets PHP? Typesense vous aide à y parvenir!
Apr 17, 2025 pm 08:15 PM
Lors du développement d'un site Web de commerce électronique, j'ai rencontré un problème difficile: comment atteindre des fonctions de recherche efficaces en grande quantité de données de produit? Les recherches traditionnelles de base de données sont inefficaces et ont une mauvaise expérience utilisateur. Après quelques recherches, j'ai découvert le moteur de recherche TypeSense et résolu ce problème grâce à son client PHP officiel TypeSense / TypeSen-PHP, ce qui a considérablement amélioré les performances de recherche.
