
 Périphériques technologiques
IA
Systèmes de recommandation basés sur l'inférence causale : bilan et perspectives
Périphériques technologiques
IA
Systèmes de recommandation basés sur l'inférence causale : bilan et perspectives
Systèmes de recommandation basés sur l'inférence causale : bilan et perspectives

Le thème de ce partage est celui des systèmes de recommandation basés sur l'inférence causale. Nous passons en revue les travaux antérieurs connexes et proposons des perspectives d'avenir dans cette direction.
Pourquoi devons-nous utiliser la technologie d'inférence causale dans les systèmes de recommandation ? Les travaux de recherche existants utilisent l'inférence causale pour résoudre trois types de problèmes (voir l'article TOIS 2023 Causal Inference in Recommender Systems: A Survey and Future Directions de Gao et al.) :
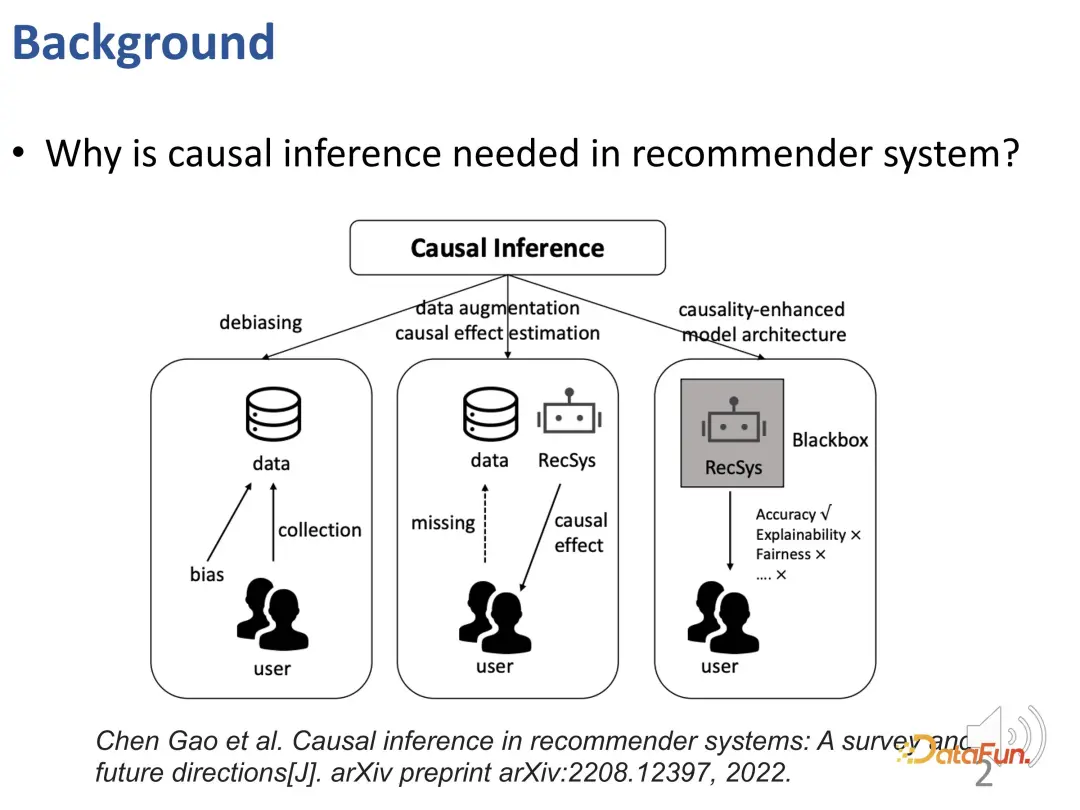
Premièrement, dans le système de recommandation, Là Divers biais (BIAIS), l'inférence causale est un outil efficace pour supprimer ces biais.
Pour résoudre les problèmes de rareté des données et d'incapacité à estimer avec précision les effets causals, les systèmes de recommandation peuvent être confrontés à des défis. Afin de résoudre ce problème, des méthodes d'amélioration des données ou d'estimation des effets causals basées sur l'inférence causale peuvent être utilisées pour résoudre efficacement les problèmes de rareté des données et de difficulté à estimer les effets causals.
Enfin, les modèles de recommandation peuvent être mieux construits en utilisant des connaissances causales ou des connaissances causales préalables pour guider la conception du système de recommandation. Cette méthode permet au modèle de recommandation de surpasser le modèle de boîte noire traditionnel, améliorant non seulement la précision, mais améliorant également considérablement l'interprétabilité et l'équité.
Partant de ces trois idées, ce partage présente les trois parties de travail suivantes :
- Démêler l'intérêt des utilisateurs et la conformité pour la recommandation (Y. Zheng, Chen Gao, et al. Démêler l'intérêt des utilisateurs et la conformité pour la recommandation avec intégration causale [C]//Actes de la Web Conference 2021. 2021 : 2980-2991.)
- Apprentissage du désenchevêtrement de l'intérêt à long terme et de l'intérêt à court terme (Y. Zheng, Chen Gao*, et al. Disenttangling long and short- intérêts à long terme pour la recommandation[C]//Actes de la conférence Web ACM 2022. 2022 : 2256-2267.)
- Débiaisation de la recommandation vidéo courte (Y. Zheng, Chen Gao*, et al. DVR : micro- vidéo recommandation optimisant le gain de temps de visionnage sous biais de durée[C]//Actes de la 30e Conférence internationale de l'ACM sur le multimédia 2022 : 334-345.)
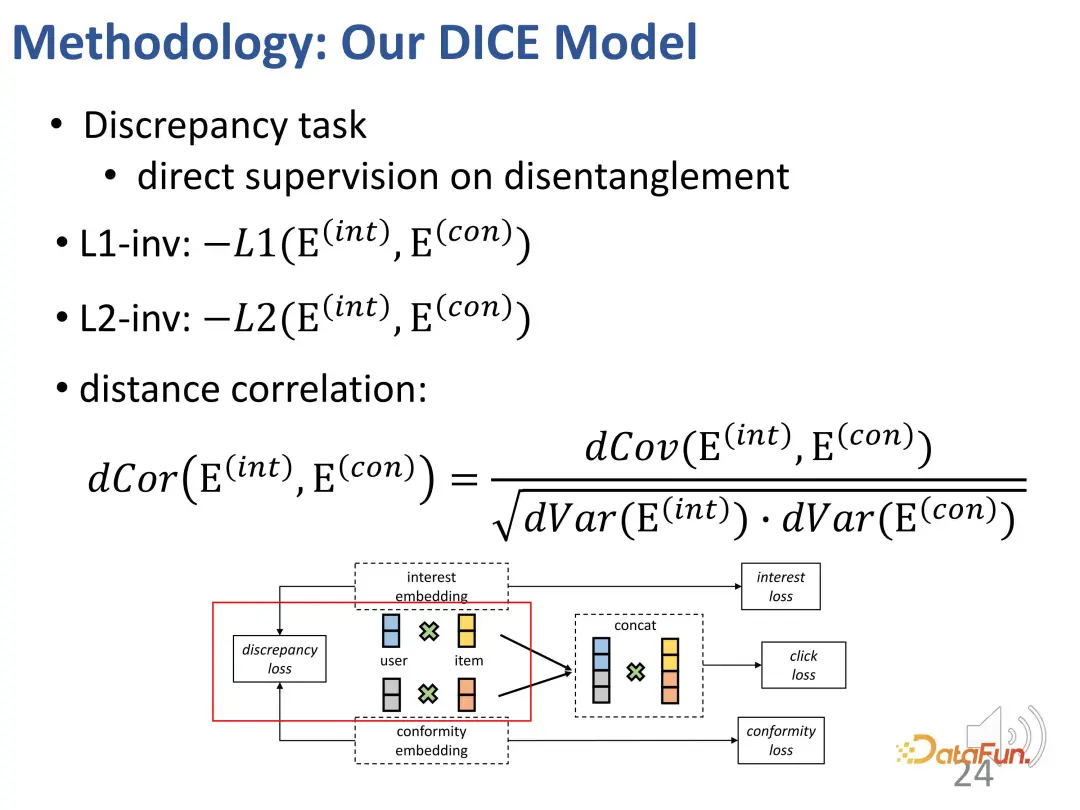
1. Apprentissage du désenchevêtrement des intérêts et de la conformité des utilisateurs
. Tout d’abord, apprenez les représentations correspondantes des intérêts des utilisateurs et de la discrimination de conformité grâce à des méthodes d’inférence causale. Cela appartient à la troisième partie du cadre de classification susmentionné, qui consiste à rendre le modèle plus interprétable lorsqu’il existe une connaissance préalable des causes et des effets.
Retour au contexte de la recherche. On peut observer qu’il existe des raisons profondes et différentes derrière l’interaction entre les utilisateurs et les produits. D'une part, il s'agit de l'intérêt propre de l'utilisateur et, d'autre part, les utilisateurs peuvent avoir tendance à suivre les pratiques des autres utilisateurs (conformité). Dans un système spécifique, cela peut se manifester par le volume des ventes ou la popularité. Par exemple, le système de recommandation existant affichera les produits les plus vendus en première position, ce qui fait que la popularité au-delà des propres intérêts de l'utilisateur affecte l'interaction et provoque des biais. Par conséquent, afin de formuler des recommandations plus précises, il est nécessaire de faire la distinction entre l’apprentissage et la résolution des représentations des deux parties.
Pourquoi avons-nous besoin d'apprendre les représentations démêlées ? Ici, faisons une explication plus approfondie. Une représentation démêlée peut aider à surmonter le problème de la distribution incohérente (OOD) des données d'entraînement hors ligne et des données expérimentales en ligne. Dans un système de recommandation réel, si un modèle de système de recommandation hors ligne est formé selon une certaine distribution de données, il faut tenir compte du fait que la distribution des données peut changer lorsqu'elle est déployée en ligne. Le comportement final de l'utilisateur est produit par l'action conjointe de conformité et d'intérêt. L'importance relative de ces deux parties est différente entre les environnements en ligne et hors ligne, ce qui peut entraîner une modification de la distribution des données et si la distribution change, il n'y a aucune garantie que cela se produise. l’intérêt pour l’apprentissage restera toujours efficace. Il s’agit d’un problème de distribution croisée. L'image ci-dessous peut illustrer visuellement ce problème. Dans cette figure, il existe une différence de répartition entre les ensembles de données d'entraînement et de test : la même forme, mais sa taille et sa couleur ont changé. Pour la prédiction de forme, les modèles traditionnels peuvent déduire des formes en fonction de la taille et de la couleur sur l'ensemble de données d'entraînement. Par exemple, les rectangles sont bleus et les plus grands, mais l'inférence ne s'applique pas à l'ensemble de données de test.
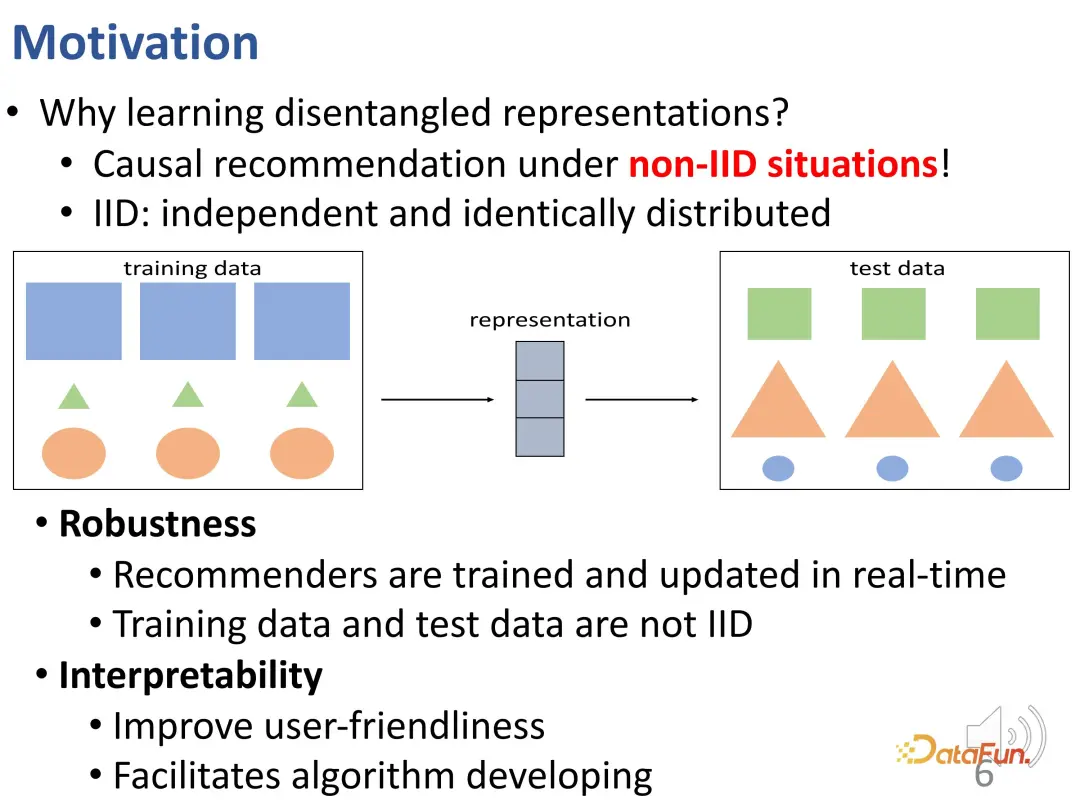
Si vous souhaitez mieux surmonter cette difficulté, vous devez effectivement vous assurer que la représentation de chaque partie est déterminée par le facteur correspondant. C’est une des motivations pour apprendre les représentations démêlées. Les modèles capables de démêler les facteurs latents peuvent obtenir de meilleurs résultats dans des situations de distribution croisée similaires à la figure ci-dessus : par exemple, le démêlage apprend des facteurs tels que le contour, la couleur et la taille, et préfère utiliser les contours pour prédire les formes.
L'approche traditionnelle consiste à utiliser la méthode IPS pour équilibrer la popularité des produits. Cette méthode pénalise les items trop populaires (ces items ont un poids plus important en termes de conformité) lors du processus d’apprentissage du modèle de système de recommandation. Mais cette approche regroupe l’intérêt et la conformité sans les séparer efficacement.

Il existe des premiers travaux sur l'apprentissage de la représentation causale (intégration causale) par l'inférence causale. L'inconvénient de ce type de travail est qu'il doit s'appuyer sur certains ensembles de données non biaisés et contraindre le processus d'apprentissage d'ensembles de données biaisés via ensembles de données non biaisés. Même s’il ne faut pas grand-chose, une petite quantité de données impartiales est encore nécessaire pour apprendre des représentations démêlées. Son applicabilité dans les systèmes réels est donc relativement limitée.

- Conformité variable : La conformité est en fait un concept plus général ou plus courant, qui implique un biais de popularité. La conformité est déterminée à la fois par l'utilisateur et par l'article. La conformité d'un utilisateur sur différents articles peut être différente, et vice versa.
- Difficulté du démêlage : Il est assez difficile d'apprendre directement une représentation démêlée. Seules des données d'observation (un comportement affecté à la fois par l'intérêt et la conformité) peuvent être obtenues, mais il n'existe aucune vérité fondamentale sur l'intérêt de l'utilisateur, c'est-à-dire qu'il n'y a pas d'étiquette explicite pour l'intérêt et la conformité eux-mêmes.
- Caractère multicausal du comportement de l'utilisateur : Une certaine interaction de l'utilisateur peut provenir de l'action d'un seul facteur ou de la combinaison de deux facteurs. Le système de recommandation nécessite une conception minutieuse pour intégrer efficacement les deux facteurs.
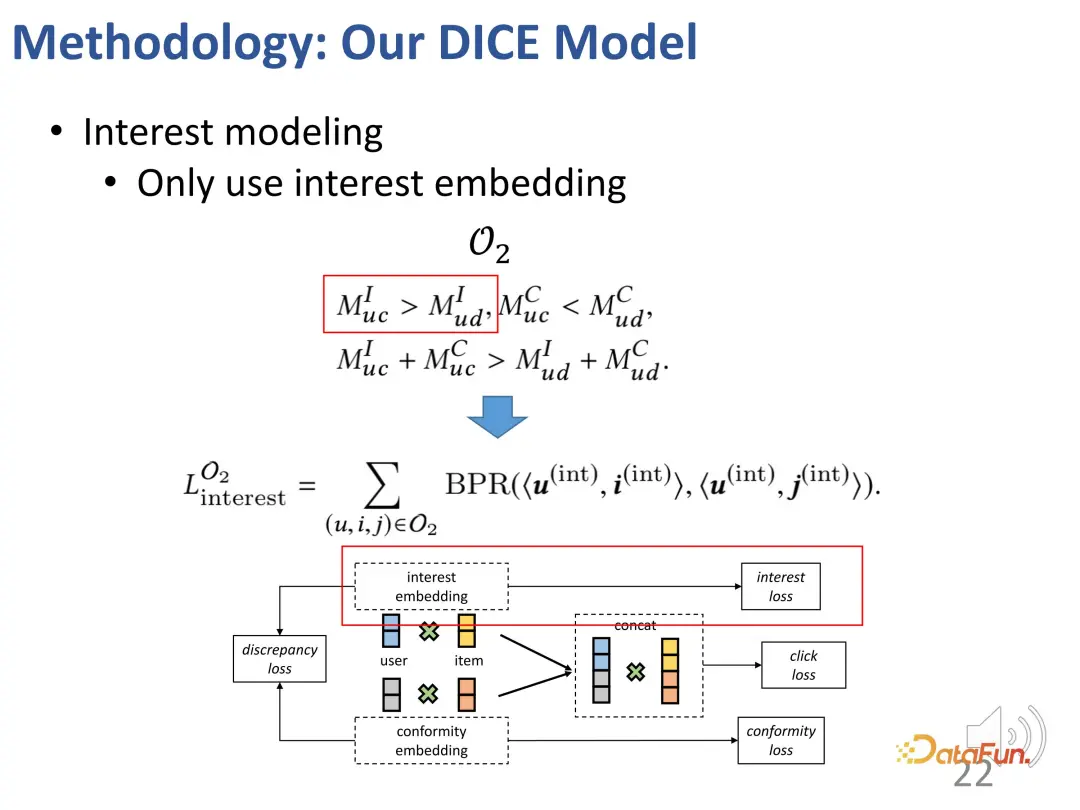
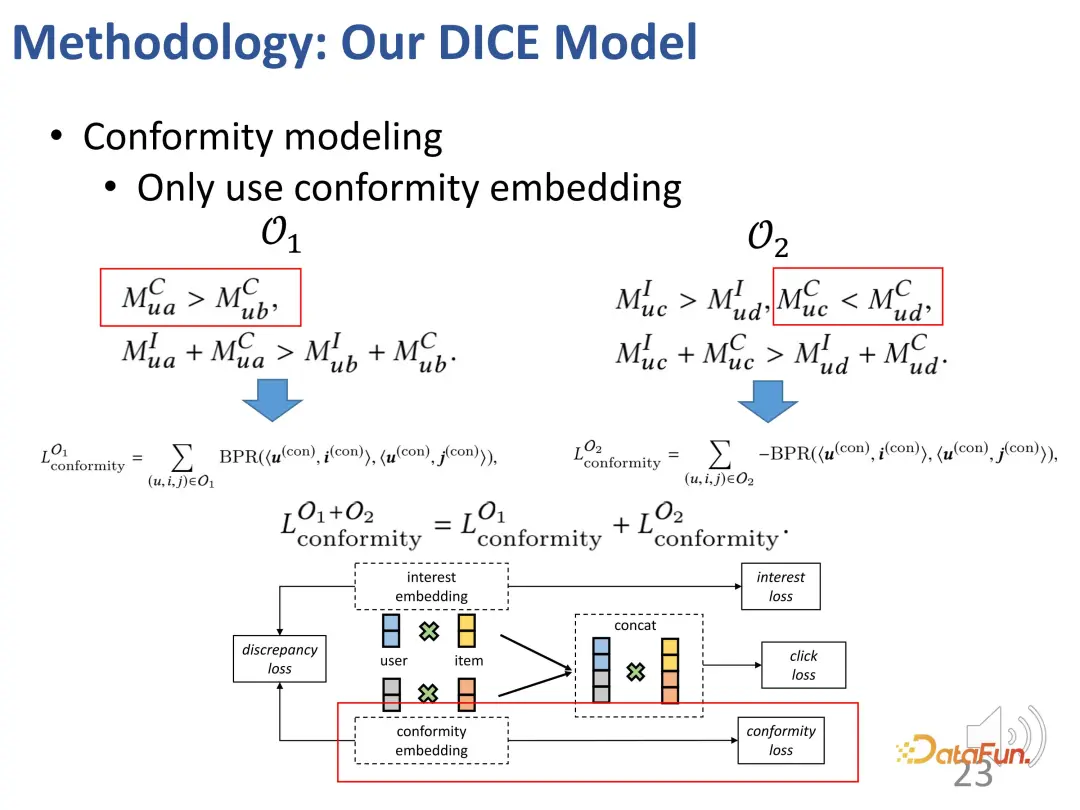
- Afin de résoudre le premier défi, des représentations correspondantes sont définies pour les utilisateurs et les produits en termes d'intérêt et de conformité. Premièrement, l’intégration de l’interaction entre les utilisateurs et les produits dans un espace de grande dimension peut exprimer efficacement une conformité diversifiée. Deuxièmement, cette méthode peut effectivement démêler directement l’intérêt et la conformité dans un espace de grande dimension, au lieu de s’appuyer sur une représentation commune, obtenant ainsi l’indépendance des deux.
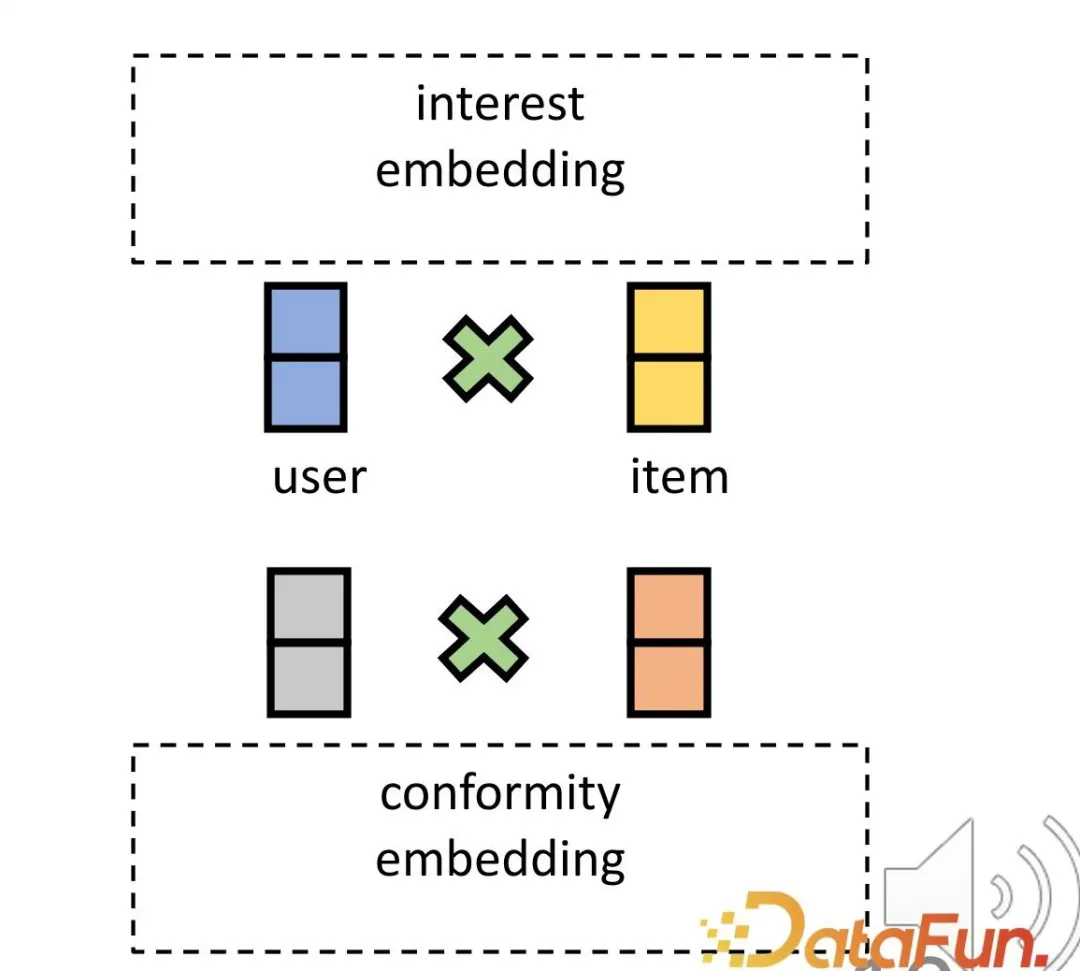
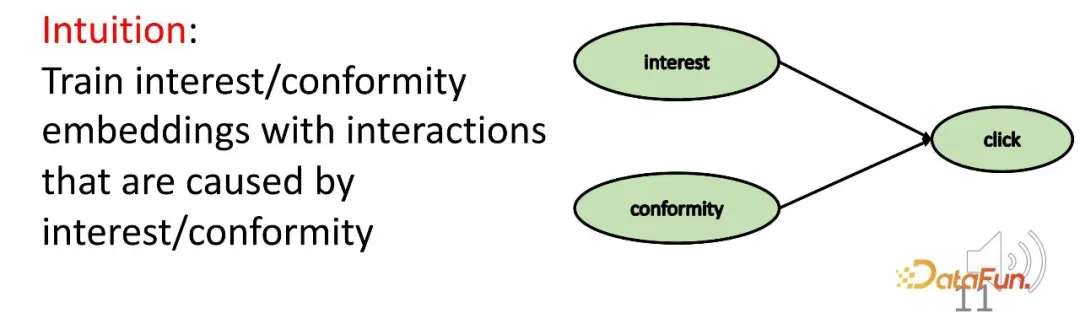
- Afin de résoudre le deuxième défi, la relation de collision dans l'inférence causale est utilisée. L'intérêt et la conformité conduisent conjointement au comportement, et il existe une relation de collision qui est utilisée pour obtenir des données causales spécifiques afin d'apprendre les représentations correspondantes pour les deux parties.
- Afin de résoudre le défi multifactoriel du comportement des utilisateurs, une méthode d'apprentissage progressif (CL) multitâche est utilisée pour combiner efficacement ces deux facteurs pour obtenir la recommandation finale.
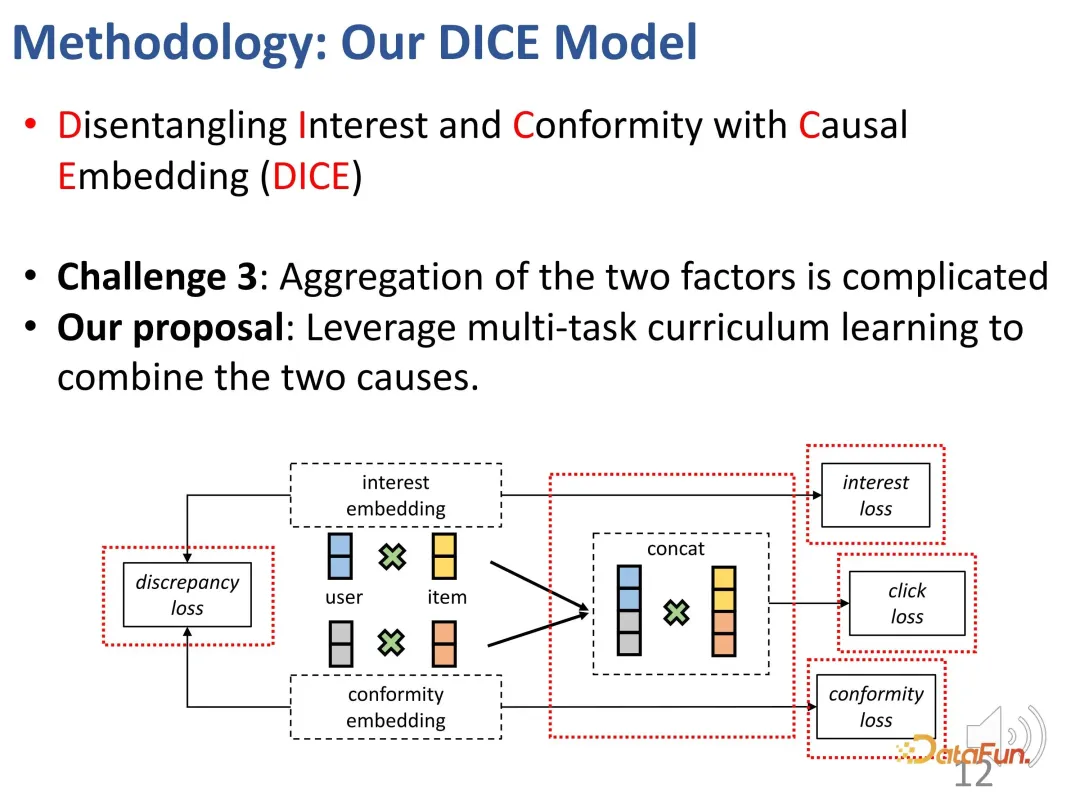
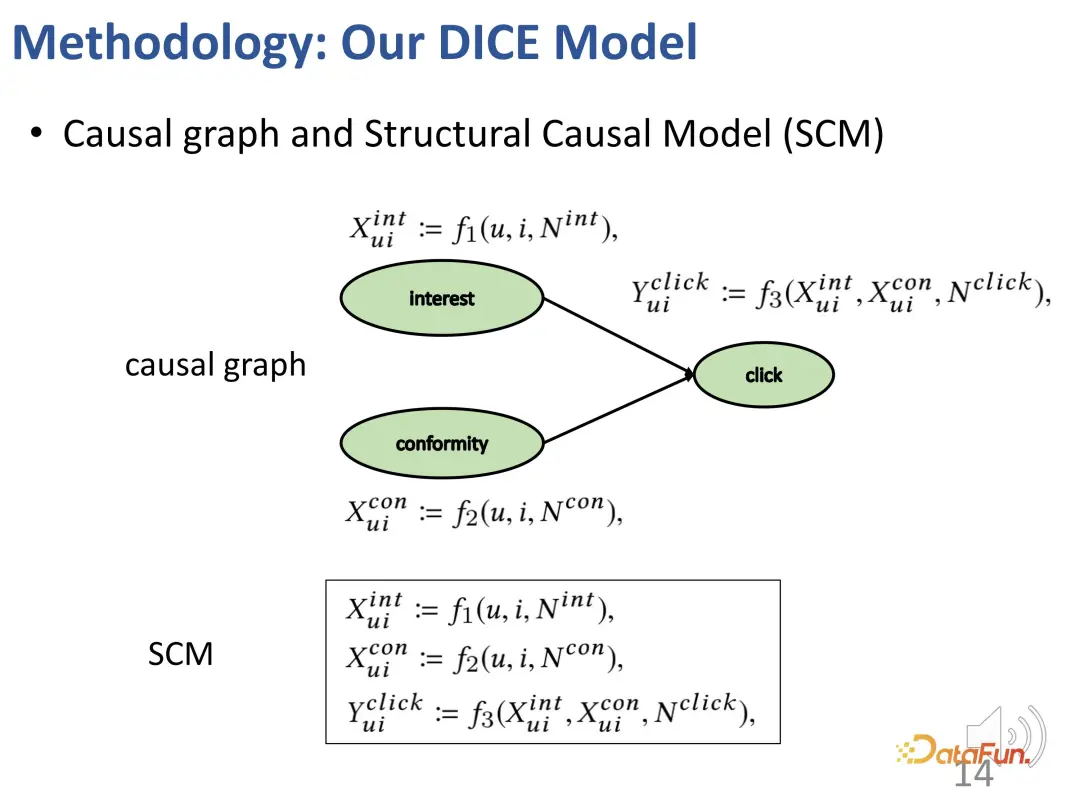
1. Intégration causale
Tout d'abord, construisez un modèle causal structurel, incluant l'intérêt et le comportement grégaire.
2. Apprentissage de la représentation de désenchevêtrement
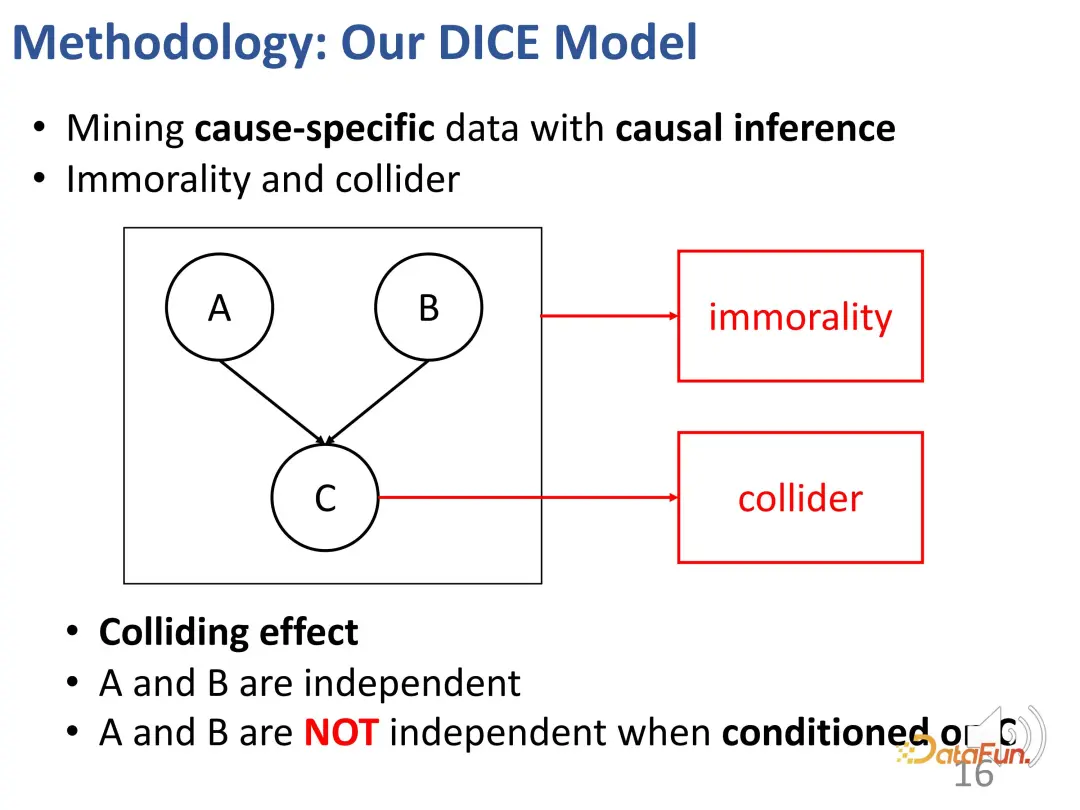
Étant donné une structure de collision comme ci-dessus, lorsque la condition c est fixée, a et b ne sont en réalité pas indépendants. Donnez un exemple pour expliquer cet effet : par exemple, a représente le talent d'un étudiant, b représente la diligence de l'étudiant et c représente si l'étudiant peut réussir un examen. Si cet étudiant réussit l’examen et qu’il n’a pas de talent particulièrement fort, alors il doit avoir travaillé très dur. Un autre étudiant, il a échoué à l'examen, mais il est très talentueux, alors ce camarade de classe ne travaille peut-être pas assez dur.
Basée sur cette idée, la méthode est conçue pour diviser la correspondance d'intérêt et la correspondance de conformité, et utiliser la popularité du produit comme indicateur de conformité.
Le premier cas : si un utilisateur clique sur un élément plus populaire a, mais ne clique pas sur un autre élément moins populaire b, similaire à l'exemple de tout à l'heure, il y aura une relation d'intérêt comme indiqué ci-dessous : a vers le utilisateur La conformité de a est supérieure à celle de b (car a est plus populaire que b), et l'attrait global de a pour les utilisateurs (intérêt + conformité) est supérieur à celui de b (car l'utilisateur a cliqué sur a mais n'a pas cliqué b).
Deuxième cas : Un utilisateur a cliqué sur un élément impopulaire c, mais n'a pas cliqué sur un élément populaire d, ce qui entraîne la relation suivante : la conformité de c aux utilisateurs est inférieure à d (car d est plus populaire que c ), mais l'attrait global de c pour l'utilisateur (intérêt + conformité) est supérieur à d (car l'utilisateur a cliqué sur c mais pas sur d), donc l'intérêt de l'utilisateur pour c est supérieur à d (en raison de la relation de collision, comme mentionné ci-dessus) .
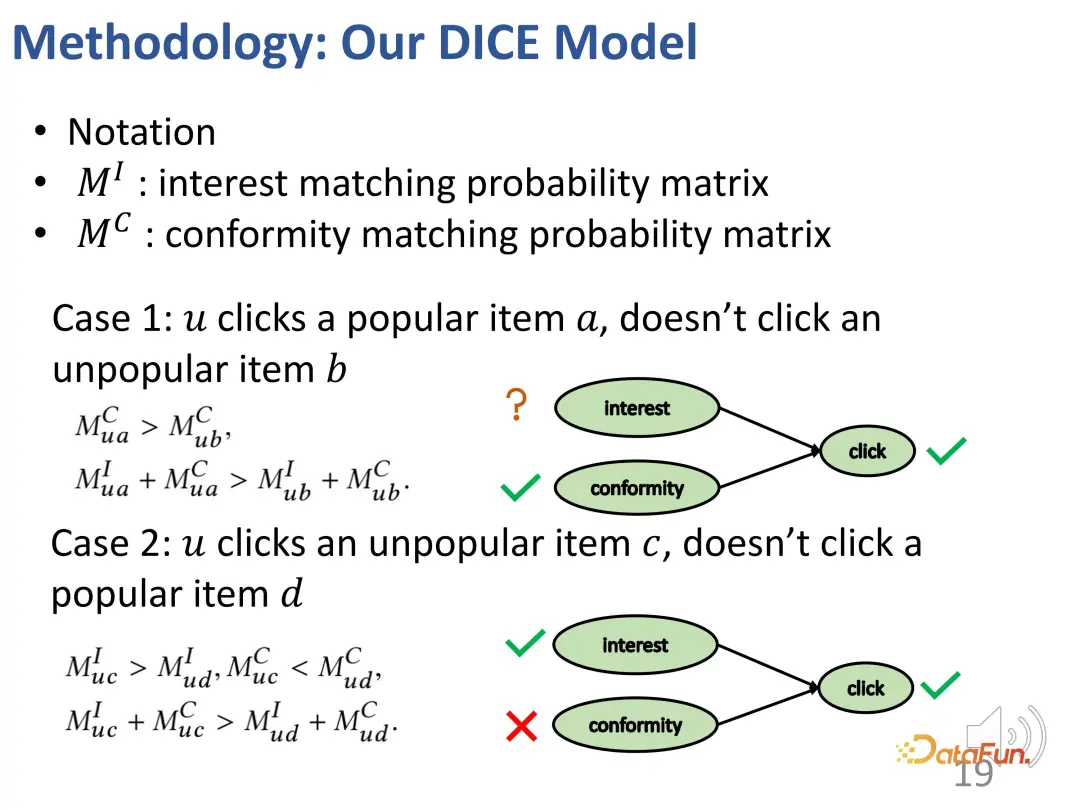
En général, deux ensembles sont construits grâce à la méthode ci-dessus : l'un est constitué des échantillons négatifs qui sont moins populaires que les échantillons positifs (la relation contrastée entre l'intérêt de l'utilisateur pour les échantillons positifs et négatifs est inconnue), et l'autre les autres sont ceux qui sont moins populaires que les échantillons positifs. Les échantillons négatifs où l'échantillon est plus populaire (les utilisateurs sont plus intéressés par les échantillons positifs que par les échantillons négatifs). Sur ces deux parties, la relation d'apprentissage contrastif peut être construite pour entraîner les vecteurs de représentation des deux parties de manière ciblée.
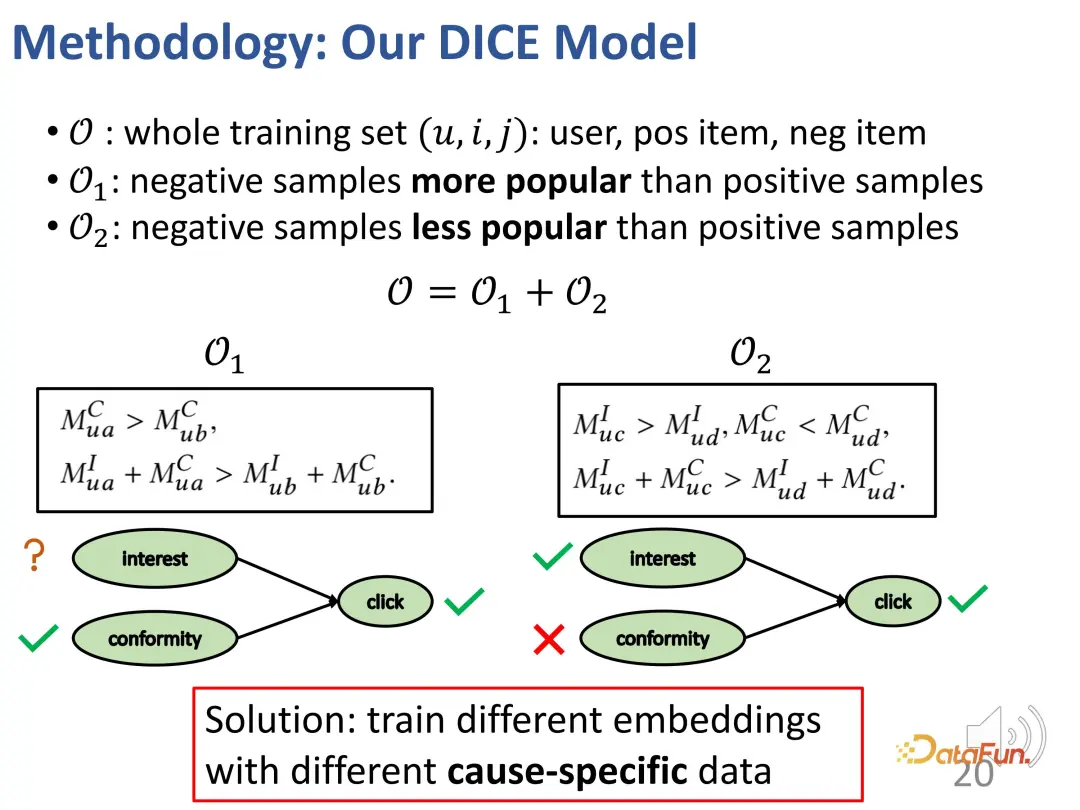
Bien entendu, dans le processus de formation proprement dit, l'objectif principal reste d'adapter le comportement d'interaction observé. Comme la plupart des systèmes de recommandation, la perte BPR est utilisée pour prédire le comportement des clics. (u : utilisateur, i : produit échantillon positif, j : produit échantillon négatif).
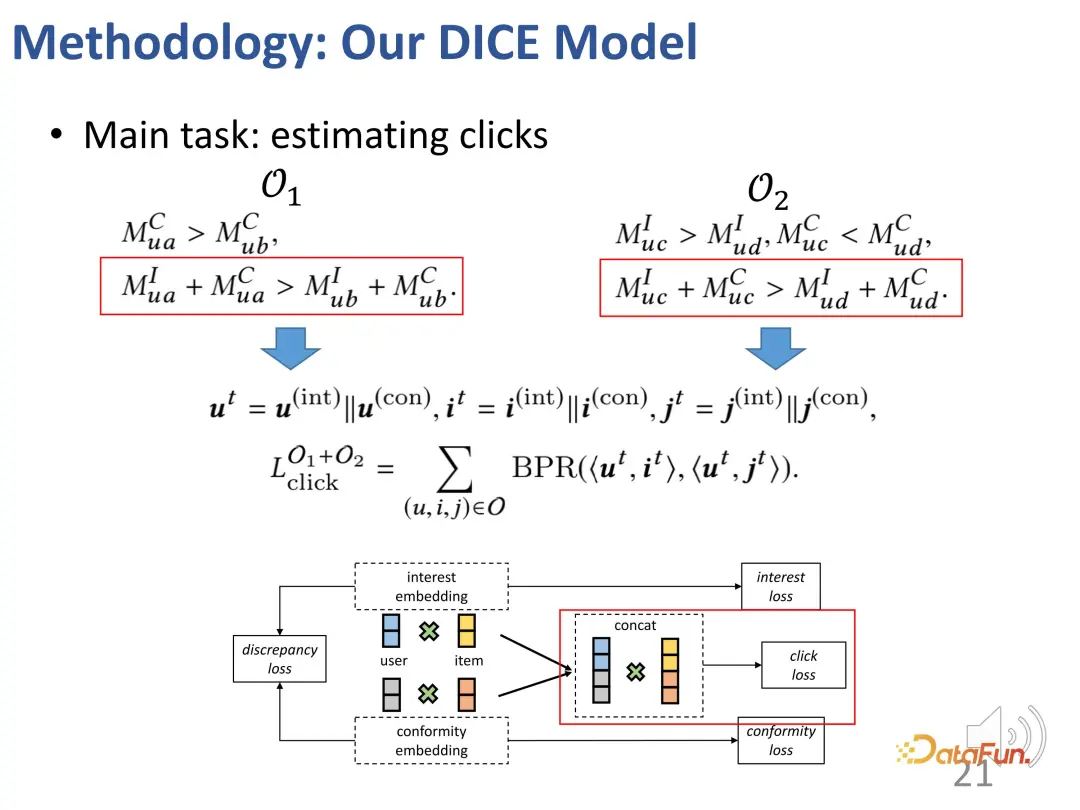
De plus, sur la base des idées ci-dessus, nous avons également conçu deux parties de méthodes d'apprentissage contrastif, introduit la fonction de perte de l'apprentissage contrastif et introduit en outre les contraintes des deux parties des vecteurs de représentation pour optimiser les deux parties des vecteurs de représentation
De plus, les vecteurs de représentation de ces deux parties doivent être contraints d'être le plus éloignés possible l'un de l'autre. En effet, ils peuvent perdre leur distinction s'ils sont trop proches. Par conséquent, une fonction de perte supplémentaire est introduite pour contraindre la distance entre les deux vecteurs de représentation partielle.
3. Apprentissage de cours multi-tâches
En fin de compte, l'apprentissage multi-tâches intégrera plusieurs objectifs ensemble. Au cours de ce processus, une stratégie a été conçue pour assurer une transition progressive de facile à difficile en termes de difficulté d'apprentissage. Au début de la formation, des échantillons moins discriminants sont utilisés pour guider les paramètres du modèle à optimiser dans la bonne direction générale, puis trouver progressivement des échantillons difficiles pour apprendre à affiner davantage les paramètres du modèle. (Les échantillons négatifs présentant une grande différence de popularité par rapport aux échantillons positifs sont considérés comme des échantillons simples, et ceux présentant une petite différence sont considérés comme des échantillons difficiles).

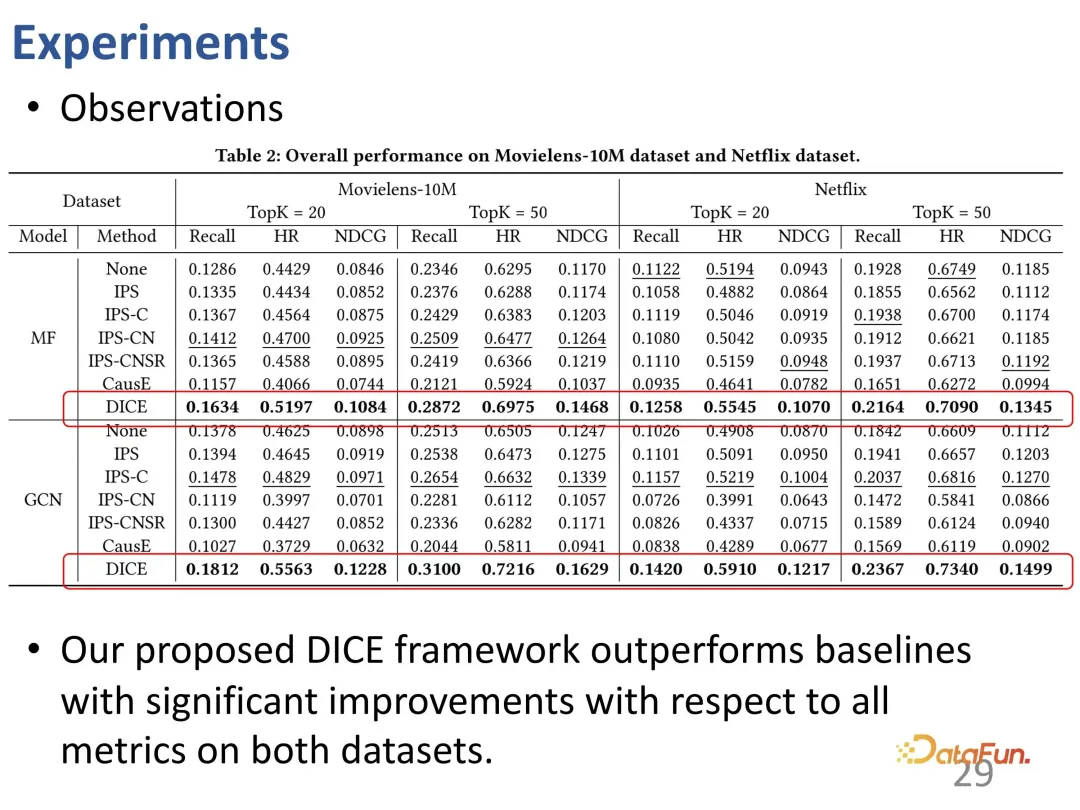
4. L'effet de la méthode
a été testé sur des ensembles de données communs pour examiner les performances de la méthode sur les principaux indicateurs de classement. Étant donné que DICE est un cadre général qui ne dépend pas d'un modèle de recommandation spécifique, différents modèles peuvent être considérés comme une épine dorsale et DICE peut être utilisé comme un cadre plug-and-play.

Tout d'abord, le protagoniste DICE. On peut voir que l'amélioration de DICE est relativement stable sur différents backbones, elle peut donc être considérée comme un cadre général pouvant apporter une amélioration des performances.
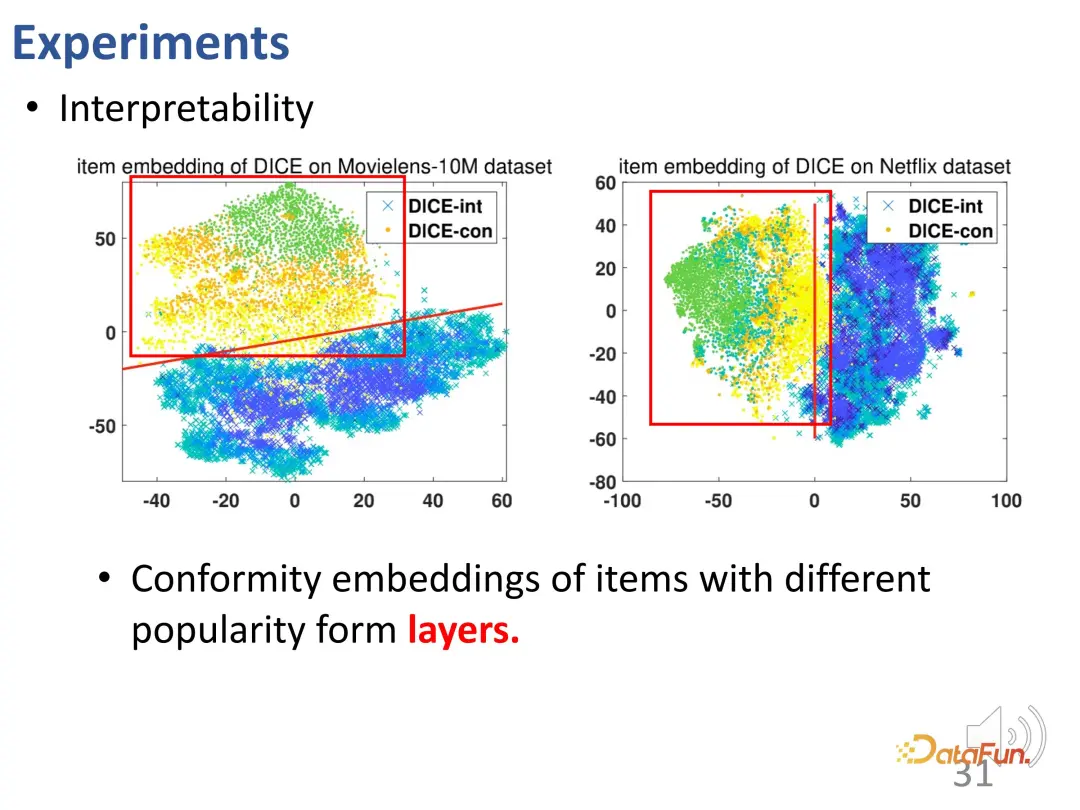
La représentation apprise par DICE est interprétable Après avoir appris séparément les représentations d'intérêt et de conformité, le vecteur de la partie conformité contient la popularité du produit. Par visualisation, on constate qu'elle est bien liée à la popularité (la représentation des différentes popularités montre une stratification évidente : points verts, oranges et jaunes).
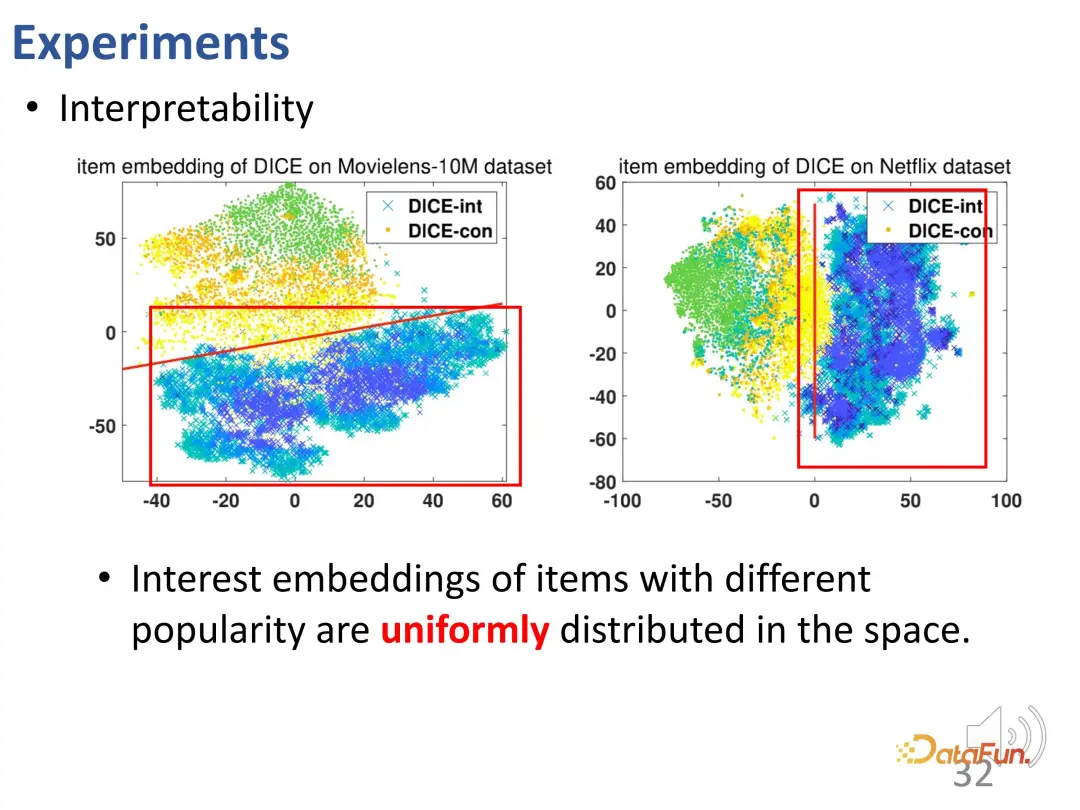
De plus, les représentations vectorielles d'intérêt d'éléments de popularité différente sont réparties uniformément dans l'espace (croix cyanine). La représentation vectorielle de conformité et la représentation vectorielle d'intérêt occupent également des espaces différents et sont séparées par démêlage. Cette visualisation valide que les représentations apprises par DICE sont réellement significatives.
DICE a obtenu l'effet escompté du design. D'autres tests ont été menés sur des données avec différentes intensités d'intervention, et les résultats ont montré que les performances de DICE étaient meilleures que celles de la méthode IPS dans différents groupes expérimentaux.
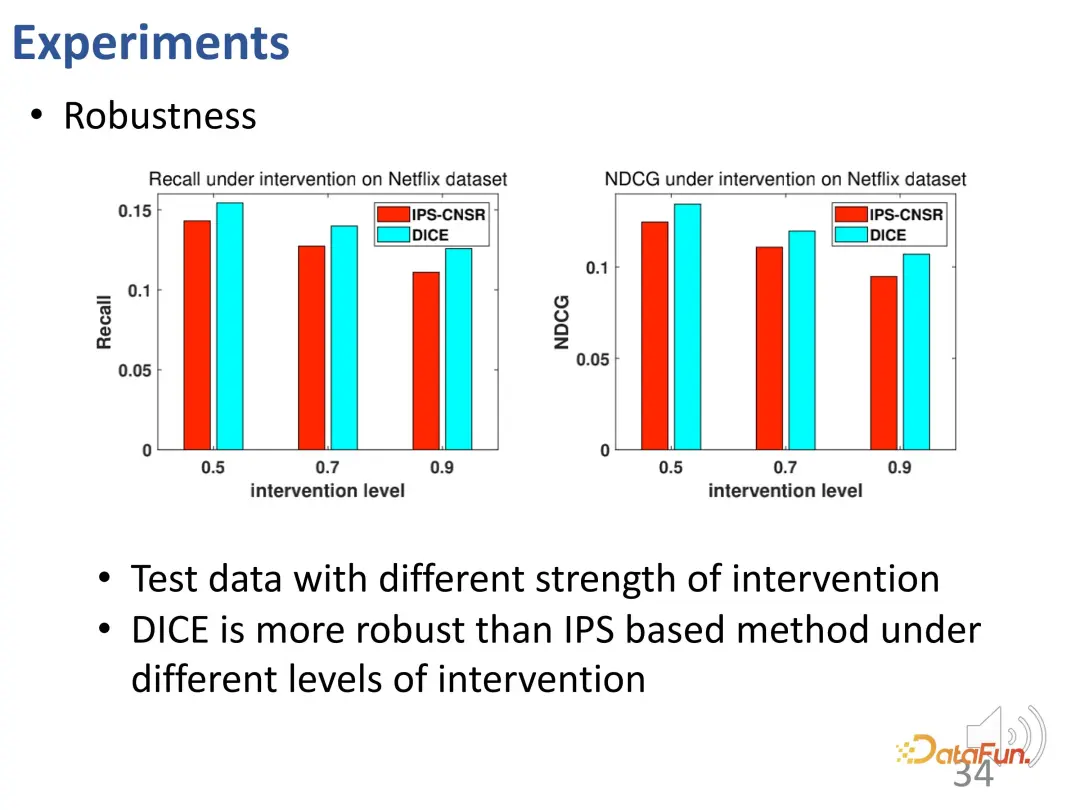
Pour résumer, DICE utilise des outils d'inférence causale pour apprendre les vecteurs de représentation correspondants pour l'intérêt et la conformité respectivement, offrant une bonne robustesse et interprétabilité dans les situations non-IID.

2. Apprentissage du désenchevêtrement de l'intérêt à long terme et de l'intérêt à court terme
Le deuxième ouvrage résout principalement le problème de démêlage de l'intérêt à long terme et de l'intérêt à court terme dans recommandation de séquence, en particulier, les intérêts des utilisateurs sont complexes. Certains intérêts peuvent être relativement stables et sont appelés intérêts à long terme, tandis que d'autres intérêts peuvent être soudains et sont appelés intérêts à court terme. Dans l’exemple ci-dessous, l’utilisateur s’intéresse aux produits électroniques à long terme, mais souhaite acheter des vêtements à court terme. Si ces intérêts peuvent être bien identifiés, les raisons de chaque comportement peuvent être mieux expliquées et les performances de l’ensemble du système de recommandation peuvent être améliorées.

Un tel problème peut être appelé la modélisation des intérêts à long terme et à court terme, c'est-à-dire qu'il peut modéliser de manière adaptative les intérêts à long terme et les intérêts à court terme respectivement, et en déduire davantage quelle partie du le comportement actuel de l'utilisateur est principalement motivé. Si vous pouvez identifier les intérêts qui déterminent actuellement le comportement, vous pourrez mieux faire des recommandations basées sur les intérêts actuels. Par exemple, si l'utilisateur parcourt la même catégorie sur une courte période, cela peut présenter un intérêt à court terme ; si l'utilisateur explore de manière approfondie sur une courte période de temps, il peut être nécessaire de se référer davantage à des recherches à long terme précédemment observées ; intérêts à terme, sans se limiter aux intérêts actuels. En général, les intérêts à long terme et les intérêts à court terme sont de nature différente, et les besoins à long terme et les besoins à court terme doivent être bien démêlés.

De manière générale, on peut considérer que le filtrage collaboratif est en fait une méthode de capture d'intérêt à long terme, car il ignore les changements dynamiques d'intérêt alors que les recommandations de séquences existantes se concentrent davantage sur la modélisation des intérêts à court terme ; ce qui conduit à oublier les intérêts à long terme, et même lorsque les intérêts à long terme sont pris en compte, la modélisation repose toujours principalement sur les intérêts à court terme. Par conséquent, les méthodes existantes ne parviennent toujours pas à combiner ces deux intérêts d’apprentissage.
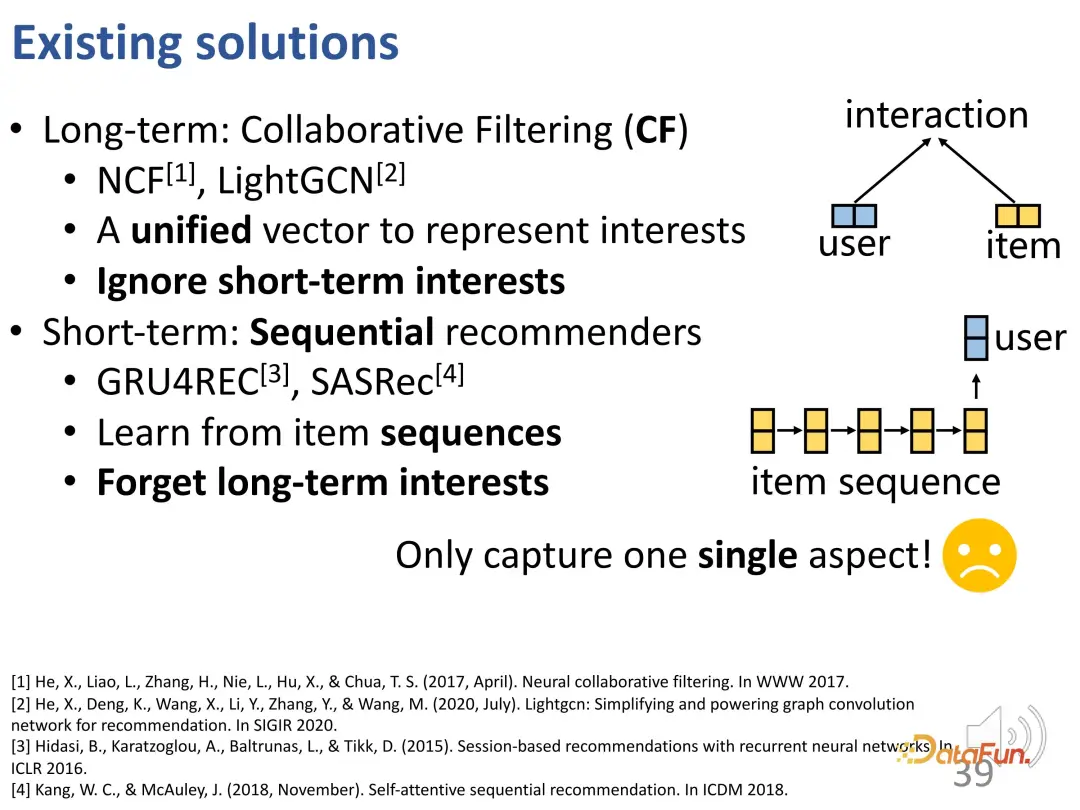
Certains travaux récents ont commencé à envisager la modélisation des intérêts à long terme et à court terme, en concevant séparément des modules à court terme et des modules à long terme, puis en les combinant directement entre eux. Cependant, dans ces méthodes, il n'y a qu'un seul vecteur utilisateur finalement appris, qui contient à la fois des signaux à court terme et des signaux à long terme. Les deux sont encore intriqués et doivent encore être améliorés.
Cependant, découpler les intérêts à long et à court terme reste un défi :
- Premièrement, les intérêts à long terme et à court terme reflètent en fait des différences de préférences qui peuvent être très différentes selon les utilisateurs, et leurs caractéristiques sont également différentes. L’intérêt à long terme est un intérêt général relativement stable, tandis que l’intérêt à court terme est dynamique et peut évoluer rapidement.
- Deuxièmement, il n'y a pas d'étiquettes explicites pour les intérêts longs et courts. La plupart des données finales collectées correspondent en fait au comportement final, et il n’existe aucune vérité fondamentale quant au type d’intérêt auquel elles appartiennent.
- Enfin, on ne sait pas non plus quelle partie des intérêts à long terme et à court terme détermine le comportement actuel, et quelle partie est la plus importante.
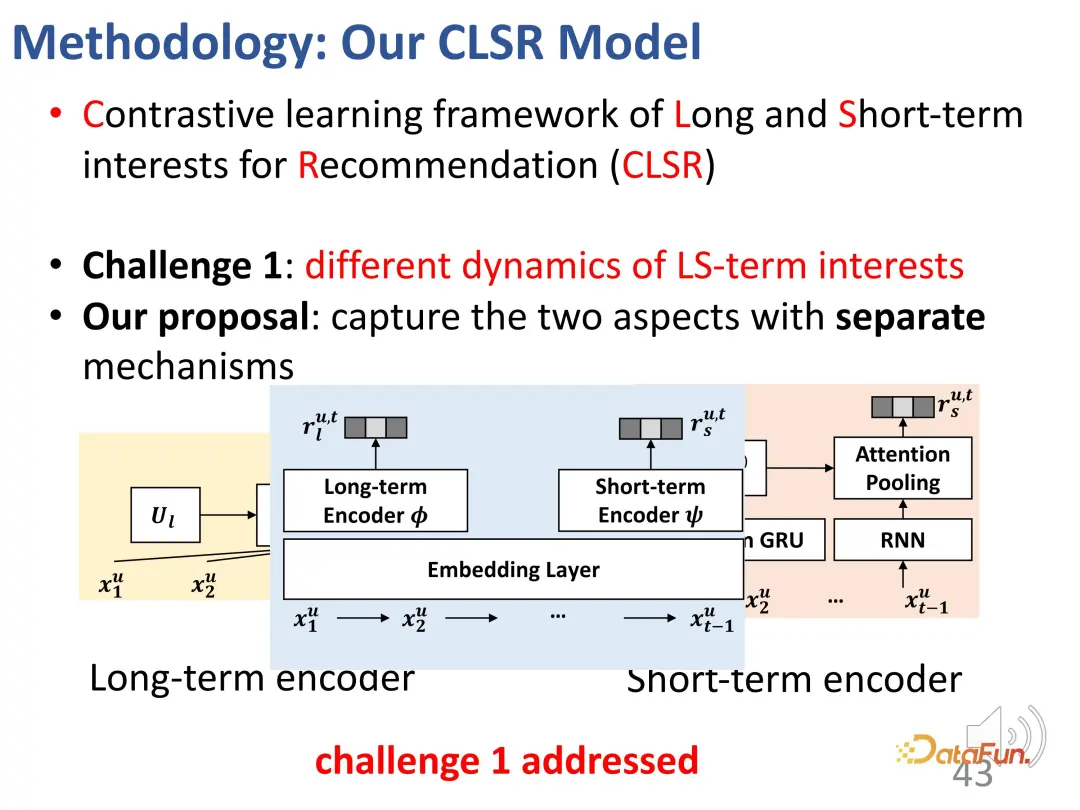
En réponse à cette problématique, une méthode d'apprentissage comparatif est proposée pour modéliser à la fois les intérêts à long terme et à court terme. (Cadre d'apprentissage contrasté des intérêts à long et à court terme pour recommandation (CLSR))
1. Séparation des intérêts à long et à court terme
Pour le premier défi - la séparation des intérêts à long terme et à court terme. intérêts à terme, nous séparons les intérêts à long terme et à court terme Intéressé par l'établissement de mécanismes évolutifs correspondants respectivement. Dans le modèle causal structurel, l'intérêt à long terme est fixé indépendamment du temps, et l'intérêt à court terme est déterminé par l'intérêt à court terme du moment précédent et l'intérêt général à long terme. Autrement dit, pendant le processus de modélisation, les intérêts à long terme sont relativement stables, tandis que les intérêts à court terme évoluent en temps réel.
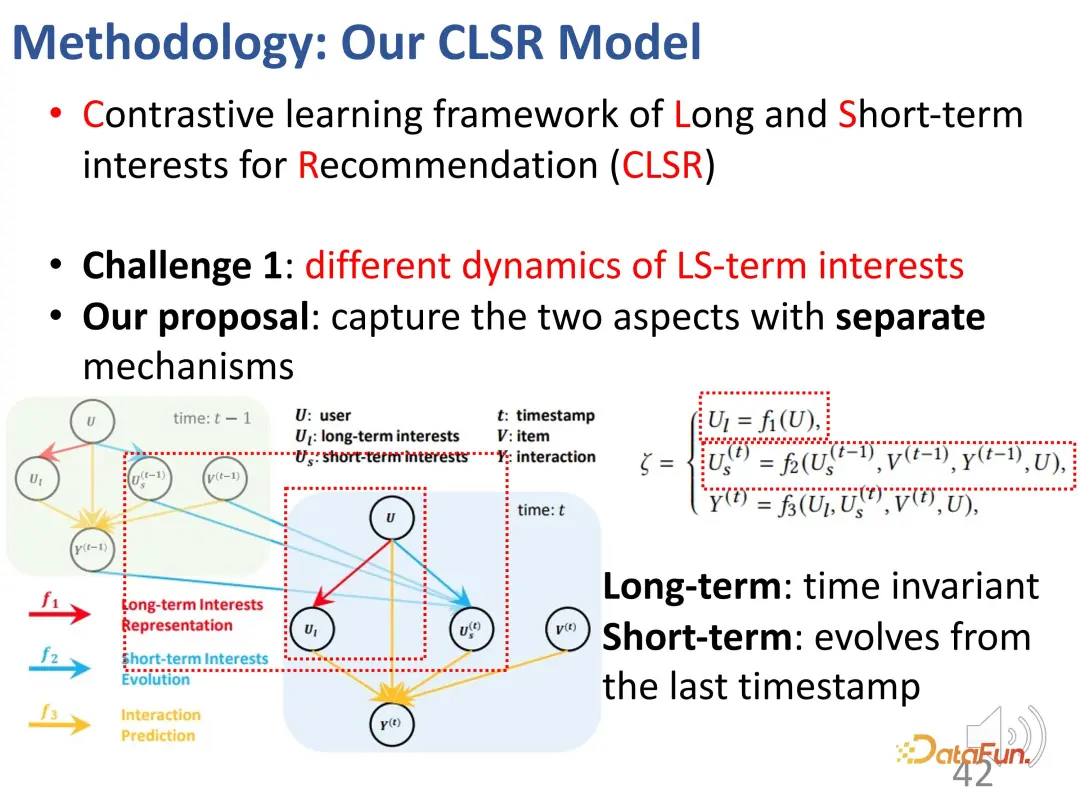
2. L'apprentissage contrastif résout le manque de signaux de supervision explicites
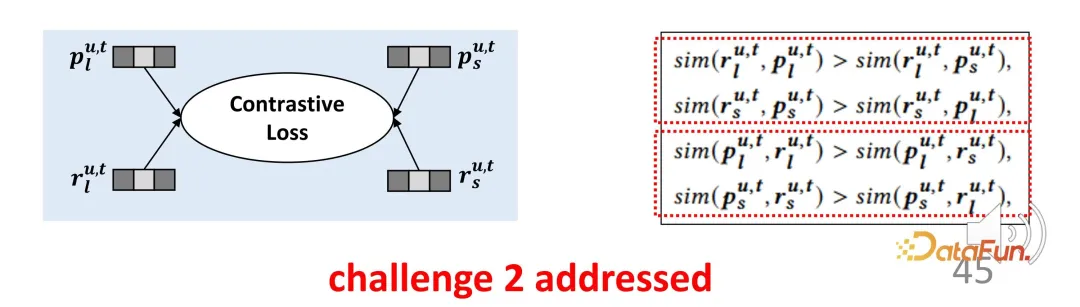
Le deuxième défi est le manque de signaux de supervision explicites pour les deux parties d'intérêt. Afin de résoudre ce problème, des méthodes d'apprentissage contrastées sont introduites pour la supervision et des étiquettes proxy sont construites pour remplacer les étiquettes explicites.
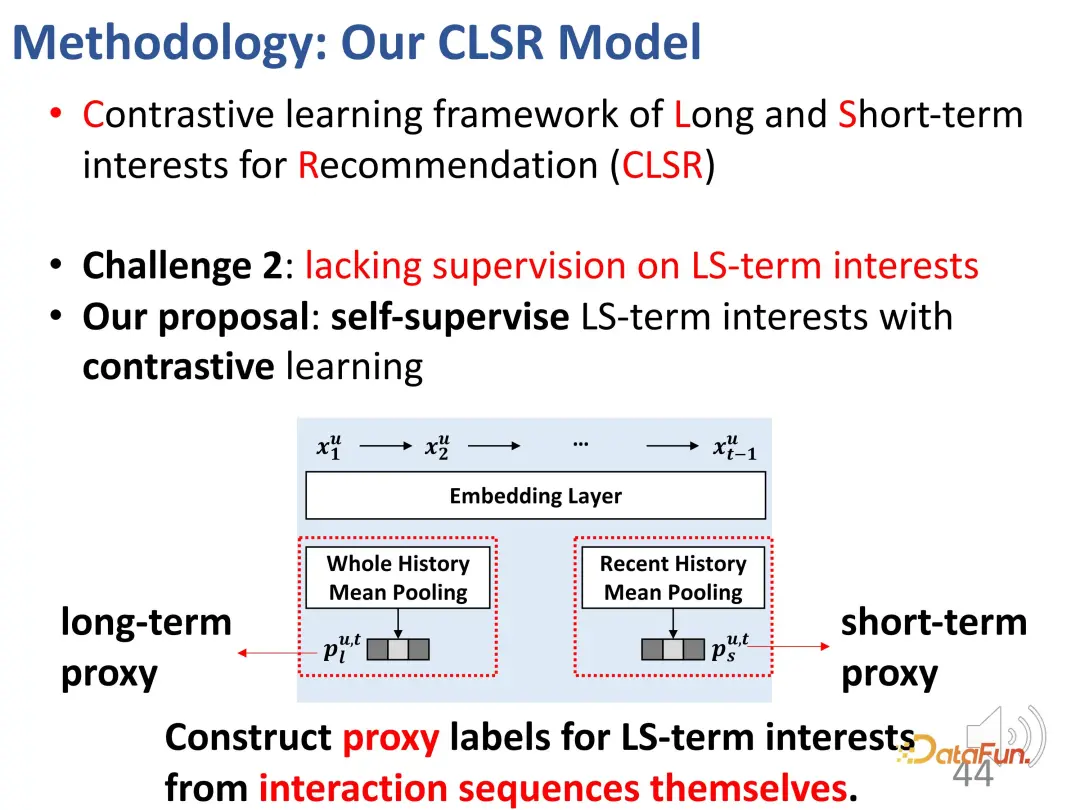
Le label d'agent est divisé en deux parties, l'une est destinée aux agents ayant des intérêts à long terme et l'autre est destinée aux agents ayant des intérêts à court terme.
Utilisez l'intégralité de l'historique de la mutualisation comme étiquette proxy d'intérêt à long terme, afin que la représentation apprise par l'encodeur soit optimisée davantage dans ce sens dans l'apprentissage de l'intérêt à long terme.
est similaire aux intérêts à court terme. La mise en commun moyenne des comportements récents de l'utilisateur est utilisée comme proxy à court terme de la même manière, bien qu'elle ne représente pas directement les intérêts de l'utilisateur, dans le processus d'apprentissage à court terme de l'utilisateur ; intérêts à terme, autant que possible Optimiser dans cette direction. Bien que les représentations d'agents comme
ne représentent pas strictement des intérêts, elles représentent une direction d'optimisation. Pour la représentation d'intérêts à long terme et la représentation d'intérêts à court terme, ils seront aussi proches que possible de la représentation correspondante et resteront à l'écart de la représentation dans l'autre sens, construisant ainsi une fonction de contrainte pour l'apprentissage contrastif. De la même manière, étant donné que la représentation proxy doit être aussi proche que possible de la sortie réelle du codeur, il s'agit d'une fonction de perte symétrique en deux parties. Cette conception compense efficacement le manque de signal de supervision que nous venons de mentionner.
3. Discrimination des pondérations d'intérêt à long terme et à court terme
Le troisième défi est de juger de l'importance de deux parties d'intérêt pour un comportement donné. La conception de cette partie est relativement simple et directe, car il existe déjà deux parties de vecteurs de représentation auparavant, et il n'est pas difficile de les mélanger. Plus précisément, un poids α doit être calculé pour équilibrer les intérêts des deux parties. Lorsque α est relativement important, l’intérêt actuel est principalement dominé par l’intérêt à long terme ; Enfin, une estimation du comportement d'interaction est obtenue.
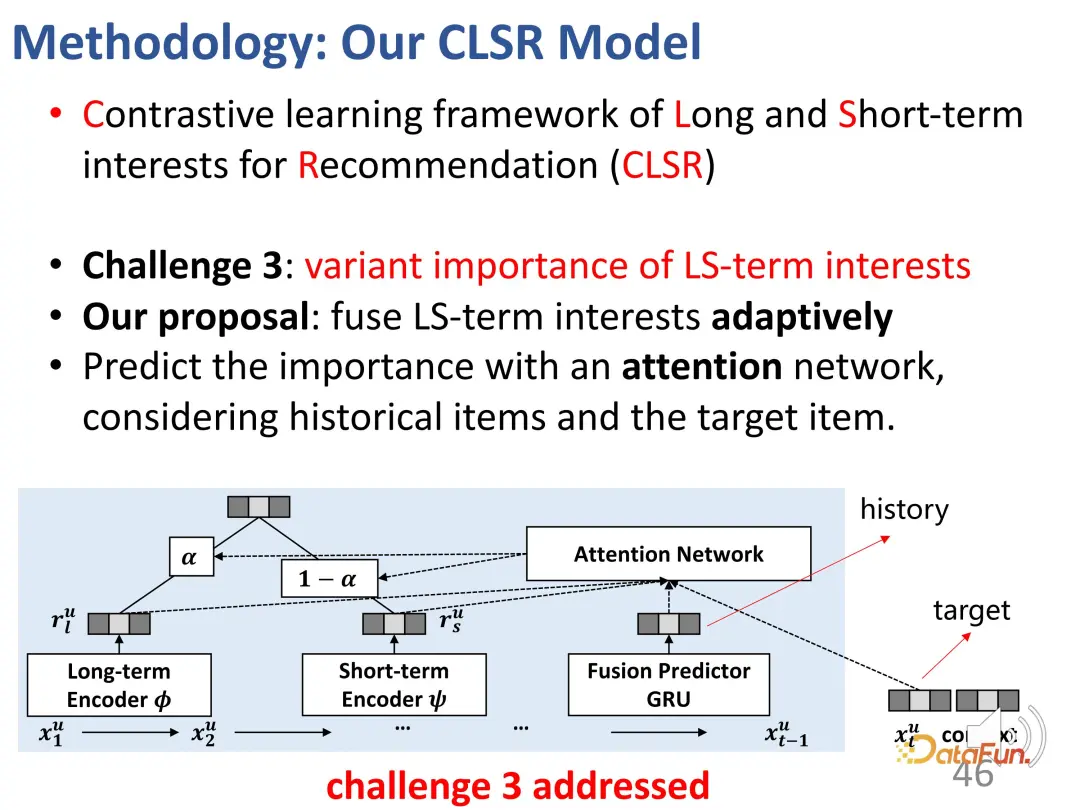
Pour la prédiction, d'une part, c'est la perte du système général de recommandation évoqué ci-dessus, et d'autre part, la fonction de perte de l'apprentissage contrastif y est ajoutée sous une forme pondérée.

Voici le schéma fonctionnel global :
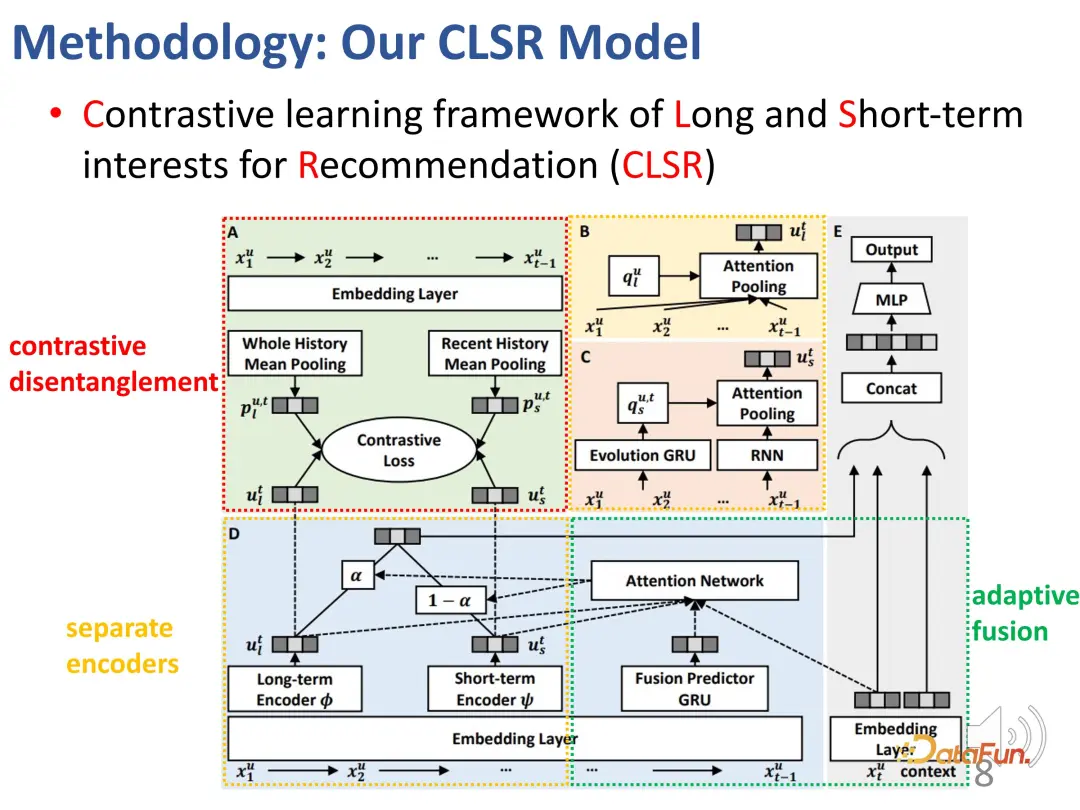
Il y a deux encodeurs distincts (BCD), la représentation de l'agent correspondante et l'objectif de l'apprentissage contrastif (A), et le automatique Mélanger de manière adaptative les intérêts des deux parties.
Dans ce travail, des ensembles de données de recommandation de séquence ont été utilisés, notamment l'ensemble de données de commerce électronique de Taobao et l'ensemble de données vidéo courtes de Kuaishou. Les méthodes sont divisées en trois types : long terme, court terme et combinaison de long terme et de court terme.
4. Résultats expérimentaux

En observant les résultats expérimentaux globaux, nous pouvons voir que les modèles qui ne prennent en compte que les intérêts à court terme fonctionnent mieux que les modèles qui ne prennent en compte que les intérêts à long terme. les modèles de recommandation de séquence sont généralement meilleurs que les modèles purs de filtrage collaboratif statique. Cela est raisonnable, car la modélisation des intérêts à court terme permet de mieux identifier certains des intérêts les plus récents qui ont le plus grand impact sur le comportement actuel.
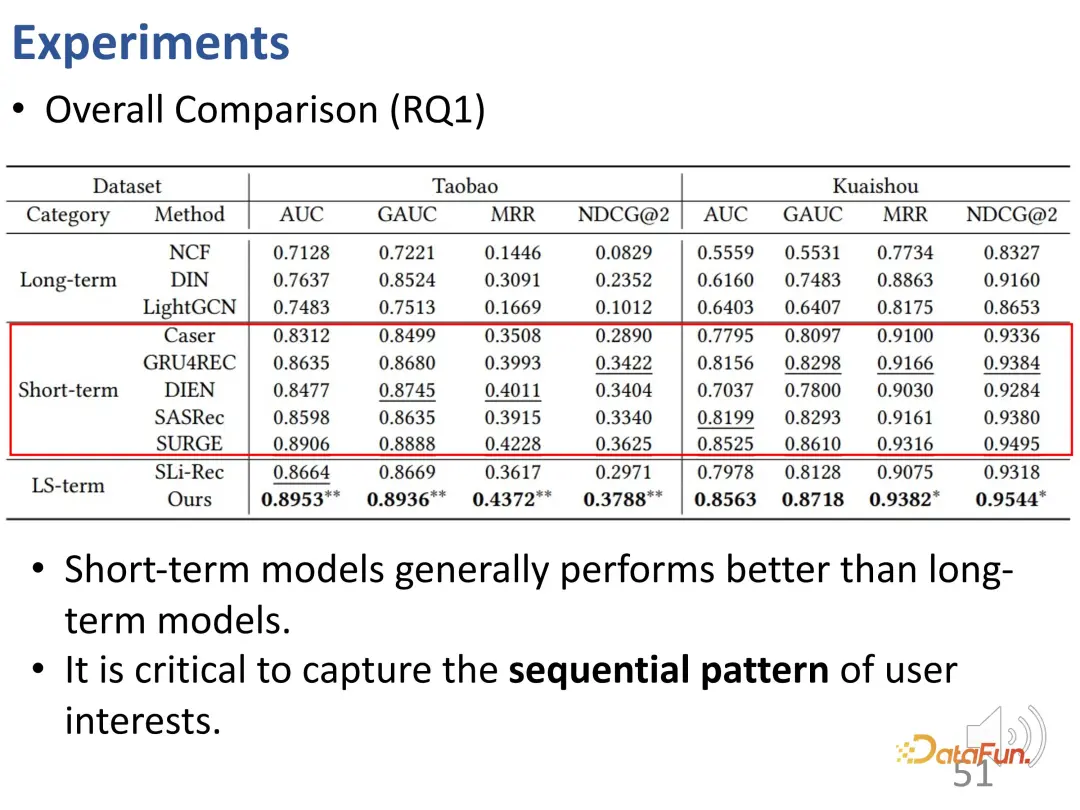
La deuxième conclusion est que le modèle SLi-Rec qui modélise à la fois les intérêts à long terme et à court terme n'est pas nécessairement meilleur que le modèle traditionnel de recommandation de séquence. Cela met en évidence les lacunes des travaux existants. La raison en est que le simple fait de mélanger les deux modèles peut introduire des biais ou du bruit ; comme on peut le voir ici, la meilleure référence est en fait un modèle d’intérêt séquentiel à court terme.
La méthode de découplage des intérêts à long terme et à court terme que nous avons proposée résout le problème de modélisation de démêlage entre les intérêts à long terme et à court terme, et peut obtenir les meilleurs résultats stables sur deux ensembles de données et quatre indicateurs.
Pour étudier plus en profondeur cet effet de démêlage, des expérimentations ont été menées pour des représentations en deux parties correspondant à des intérêts à long terme et à court terme. Comparez l'intérêt à long terme, l'intérêt à court terme de l'apprentissage CLSR et les deux intérêts de l'apprentissage Sli-Rec. Les résultats expérimentaux montrent que notre travail (CLSR) est capable d'obtenir systématiquement de meilleurs résultats sur chaque partie, et prouve également la nécessité de fusionner la modélisation des intérêts à long terme et la modélisation des intérêts à court terme, car en utilisant les deux, le meilleur résultat est l'intégration des intérêts. .
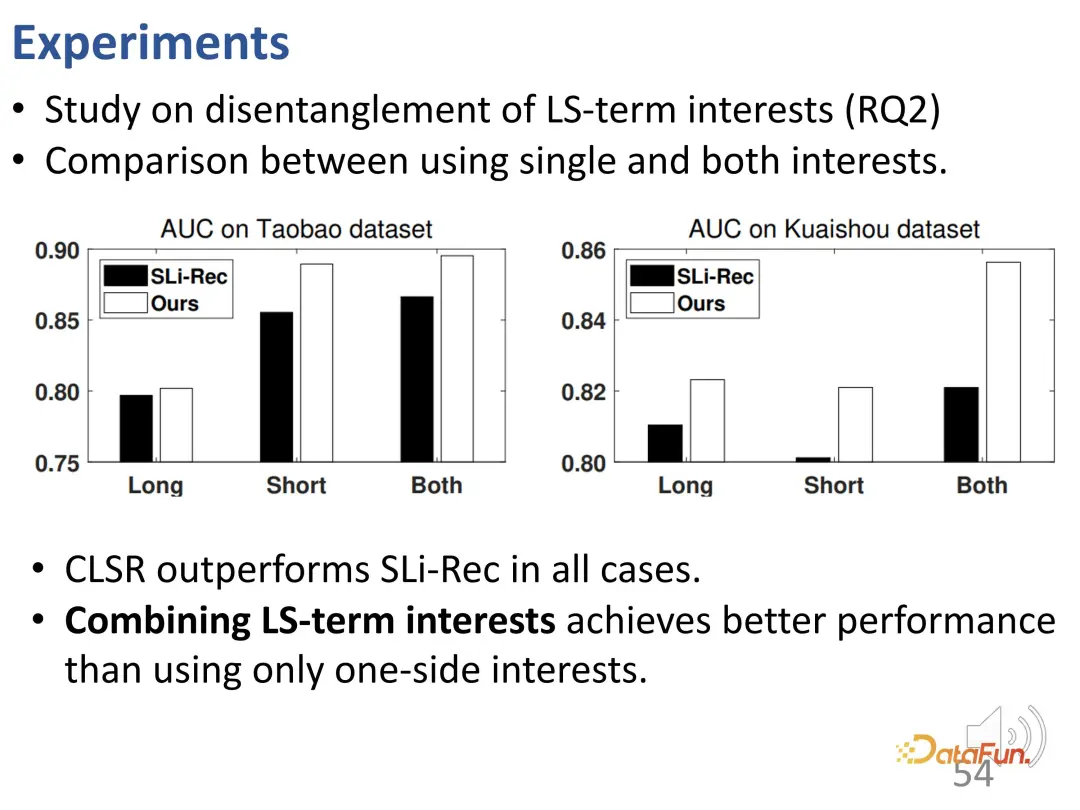
En outre, utilisez le comportement d'achat et le comportement similaire pour des recherches comparatives, car le coût de ces comportements est plus élevé que celui des clics : les achats coûtent de l'argent et les likes nécessitent un certain coût d'exploitation, donc ces intérêts reflètent en fait une préférence plus forte. pour des intérêts stables à long terme. Premièrement, en termes de comparaison des performances, CLSR obtient de meilleurs résultats. De plus, la pondération des deux aspects de la modélisation est plus raisonnable. CLSR est capable d'attribuer des poids plus importants que le modèle SLi-Rec aux comportements plus orientés vers les intérêts à long terme, ce qui est cohérent avec la motivation précédente.

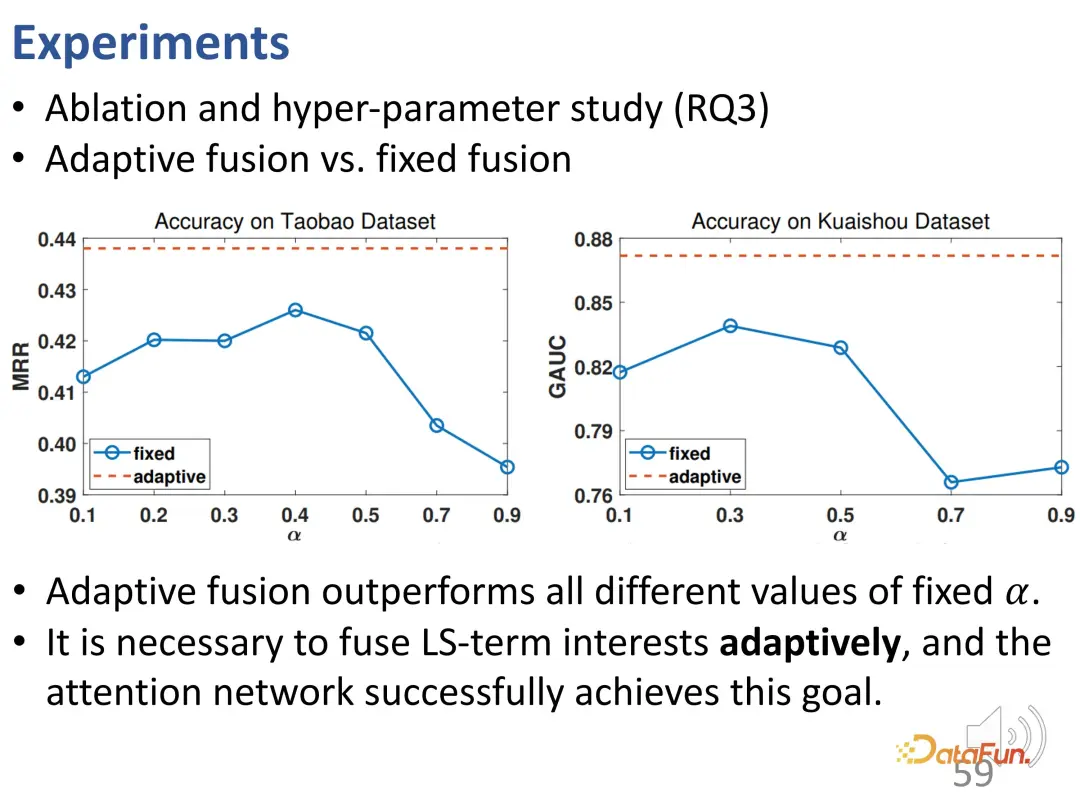
D'autres expériences d'ablation et d'hyperparamètres ont été menées. Premièrement, la fonction de perte de l’apprentissage contrastif a été supprimée et les performances ont diminué, ce qui indique que l’apprentissage contrastif est très nécessaire pour démêler les intérêts à long terme et les intérêts à court terme. Cette expérience prouve en outre que CLSR est un meilleur cadre général car il fonctionne également au-dessus des méthodes existantes (l'apprentissage contrastif auto-supervisé peut améliorer les performances de DIEN) et est une méthode plug-and-play. Les recherches sur β ont révélé qu'une valeur raisonnable est de 0,1.
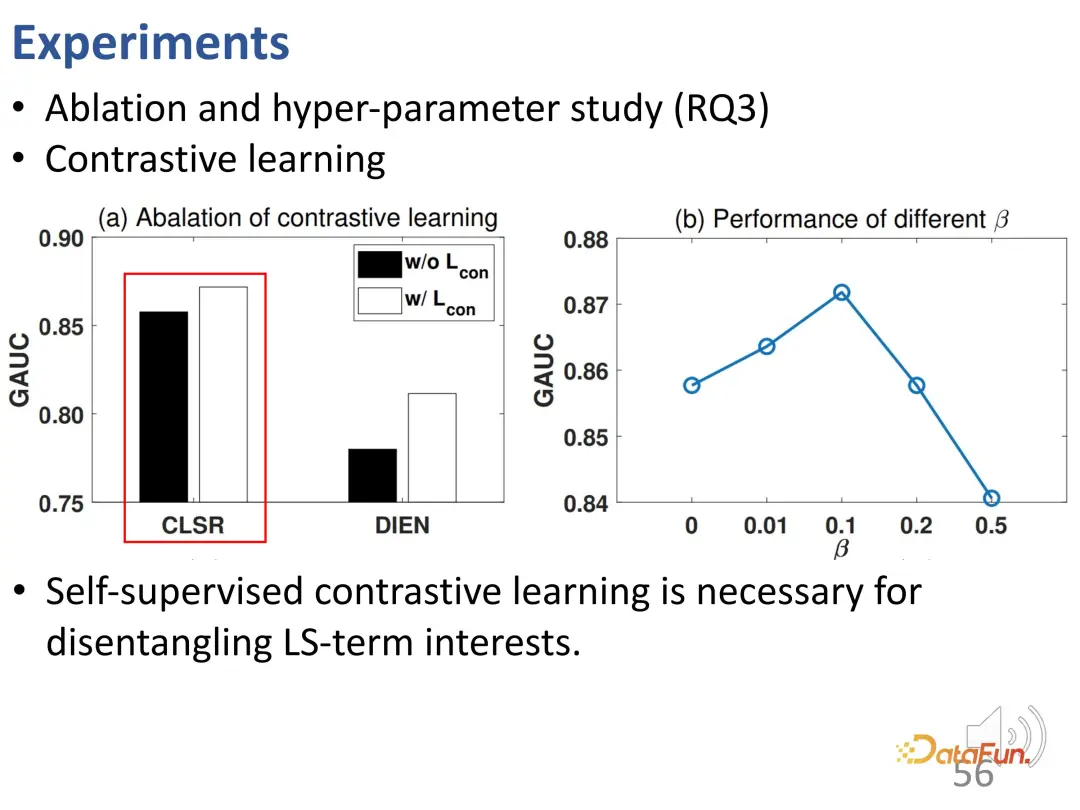
Ensuite, nous étudierons plus en détail la relation entre la fusion adaptative et la fusion simple. La fusion de poids adaptative fonctionne de manière plus stable et meilleure que la fusion de poids fixe à toutes les différentes valeurs α, ce qui vérifie que chaque comportement d'interaction peut être déterminé par des poids de différentes tailles et vérifie que la fusion d'intérêt est obtenue grâce à la fusion adaptative et à la nécessité d'une prédiction comportementale finale. .
Ce travail propose une méthode d'apprentissage contrastif pour modéliser l'intérêt à long terme et l'intérêt à court terme dans les intérêts de séquence, apprendre respectivement les vecteurs de représentation correspondants et réaliser le démêlage. Les résultats expérimentaux démontrent l'efficacité de cette méthode.

3. Débiaiser les recommandations vidéo courtes
Les deux tâches introduites précédemment se concentrent sur le démêlage des intérêts. Le troisième travail se concentre sur la correction comportementale de l’apprentissage par intérêt.
La recommandation de vidéos courtes est devenue un élément très important du système de recommandation. Cependant, les systèmes de recommandation de vidéos courtes existants suivent toujours le paradigme précédent de recommandation de vidéos longues, et certains problèmes peuvent survenir.
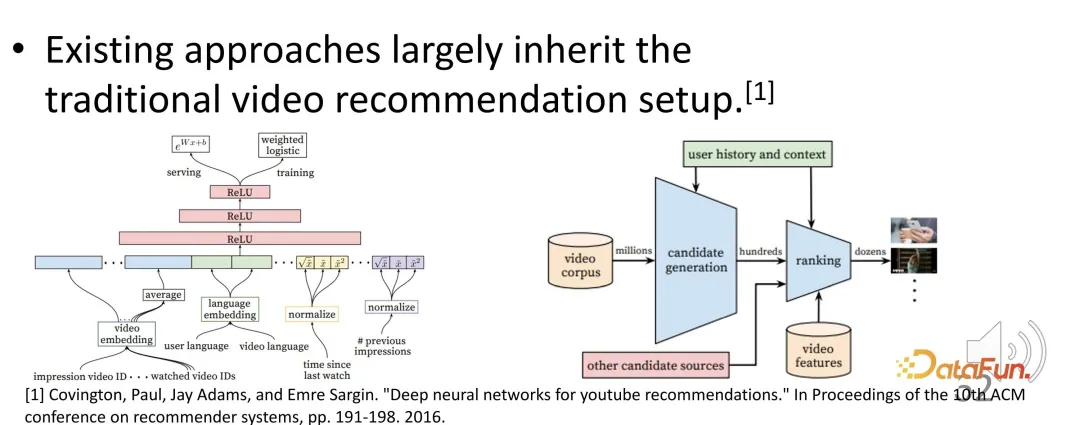
Par exemple, comment évaluer la satisfaction et l'activité des utilisateurs dans de courtes recommandations vidéo ? Quel est l’objectif d’optimisation ? Les objectifs d'optimisation courants sont la durée de visionnage ou la progression du visionnage. Les vidéos courtes dont on estime que les taux d'achèvement et les durées de visionnage sont plus élevés peuvent être mieux classées par le système de recommandation. Il peut être optimisé en fonction de la durée de visionnage pendant la formation et trié en fonction de la durée de visionnage estimée pendant le service, et des vidéos avec une durée de visionnage plus élevée sont recommandées.
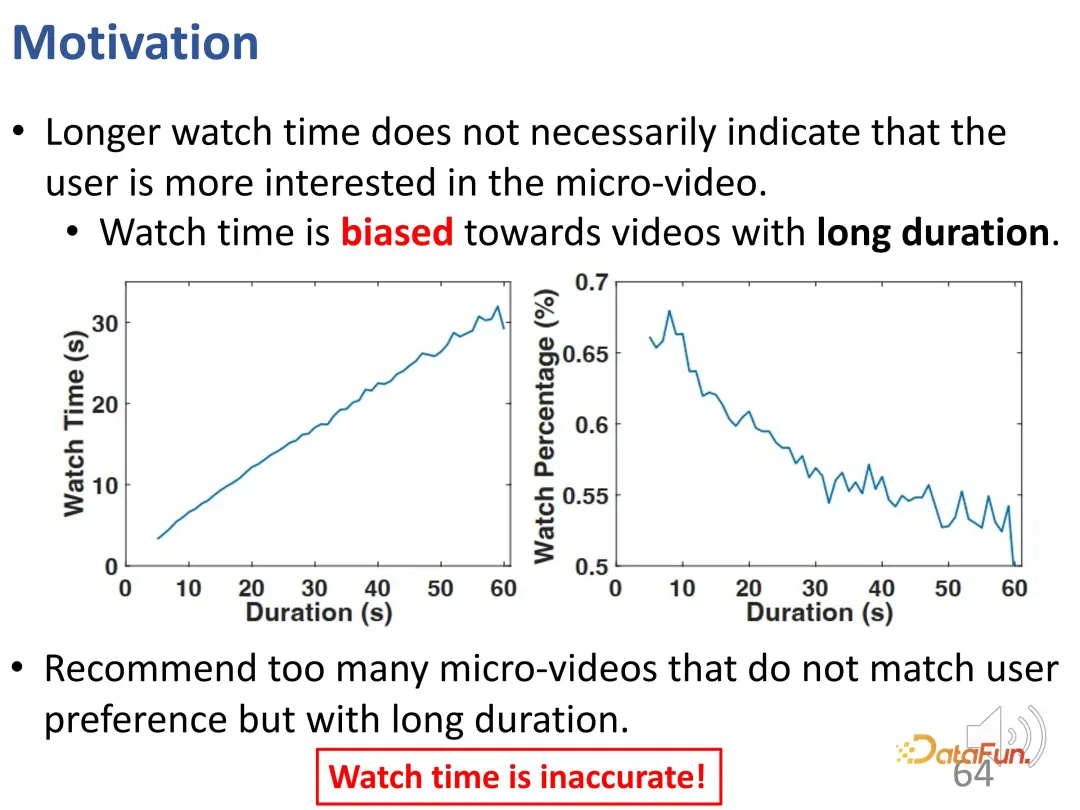
Cependant, un problème dans la recommandation de vidéos courtes est qu'une durée de visionnage plus longue ne signifie pas nécessairement que l'utilisateur est très intéressé par la vidéo courte, c'est-à-dire que la longueur de la vidéo courte elle-même est un écart très important. Dans les systèmes de recommandation utilisant les objectifs d’optimisation ci-dessus (durée de visionnage ou progression du visionnage), les vidéos plus longues présentent un avantage naturel. Recommander trop de longues vidéos de ce type peut ne pas correspondre aux intérêts de l'utilisateur. Cependant, en raison du coût opérationnel lié au fait que les utilisateurs sautent des vidéos, l'évaluation obtenue par des tests en ligne réels ou une formation hors ligne sera très élevée. Il ne suffit donc pas de se fier uniquement à l’heure de la montre.
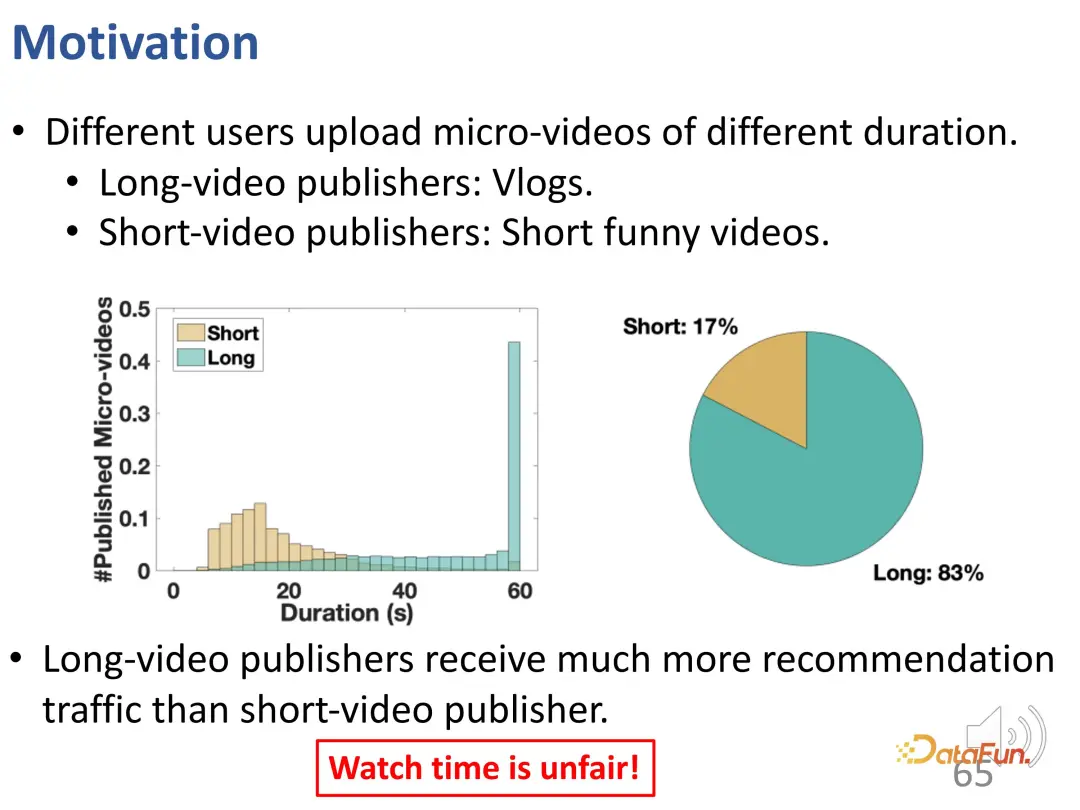
Comme vous pouvez le voir, il y a deux formulaires dans la courte vidéo. L’une est constituée de vidéos plus longues comme les vlogs, tandis que l’autre est constituée de vidéos de divertissement plus courtes. Après avoir analysé le trafic réel, nous avons constaté que les utilisateurs qui publient de longues vidéos obtiennent généralement plus de trafic recommandé, et ce ratio est très différent. Utiliser uniquement la durée de visionnage pour évaluer non seulement ne répond pas aux intérêts des utilisateurs, mais peut également être injuste.
Dans ce travail, nous espérons résoudre deux problèmes :
- Comment mieux évaluer la satisfaction des utilisateurs sans parti pris.
- Comment connaître cet intérêt impartial des utilisateurs pour fournir de bonnes recommandations.
En fait, le principal défi est que de courtes vidéos de différentes longueurs ne peuvent pas être directement comparées. Étant donné que ce problème est naturel et omniprésent dans les différents systèmes de recommandation, et que les structures des différents systèmes de recommandation varient considérablement, la méthode conçue doit être indépendante du modèle.
Tout d'abord, plusieurs méthodes représentatives ont été sélectionnées et une formation simulée a été réalisée en utilisant la durée de visionnage.

Vous pouvez voir sur la courbe que l'écart de durée est amélioré : par rapport à la courbe de vérité terrain, le modèle de recommandation est nettement plus élevé dans les résultats de prédiction d'une longue durée de visionnage de vidéos. Dans les modèles prédictifs, la surrecommandation de vidéos longues pose problème.
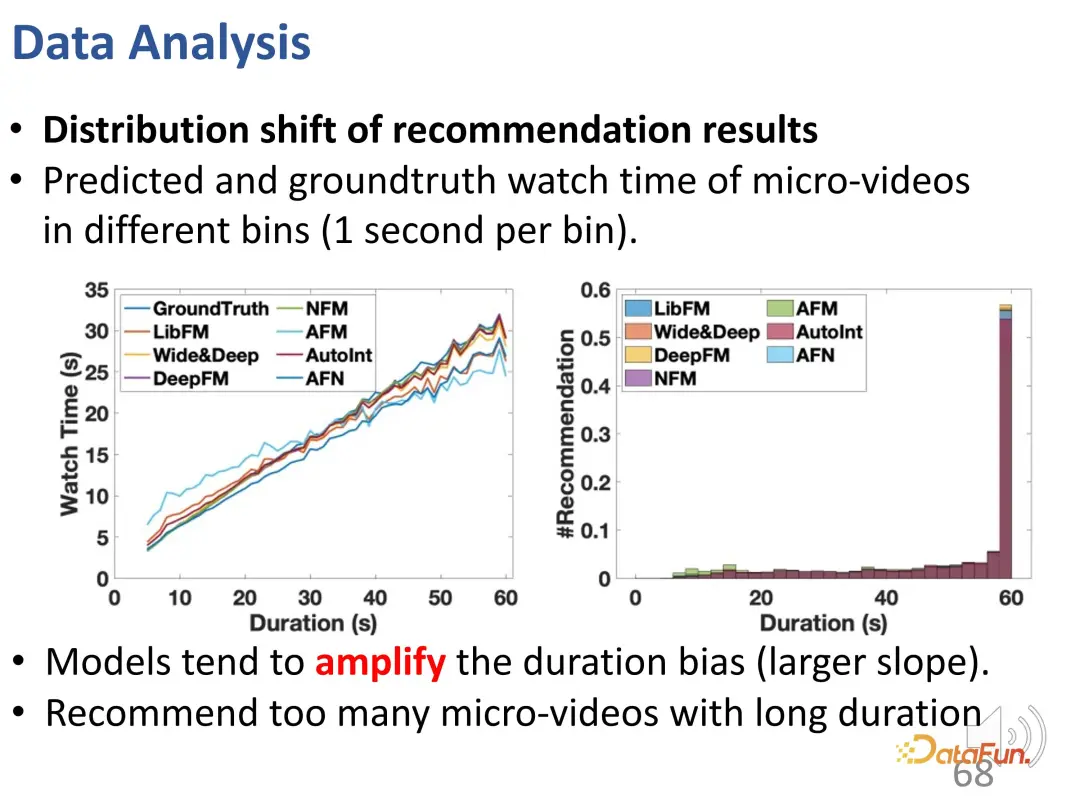
De plus, il a également été constaté qu'il y avait de nombreuses recommandations inexactes dans les résultats des recommandations (#BC).
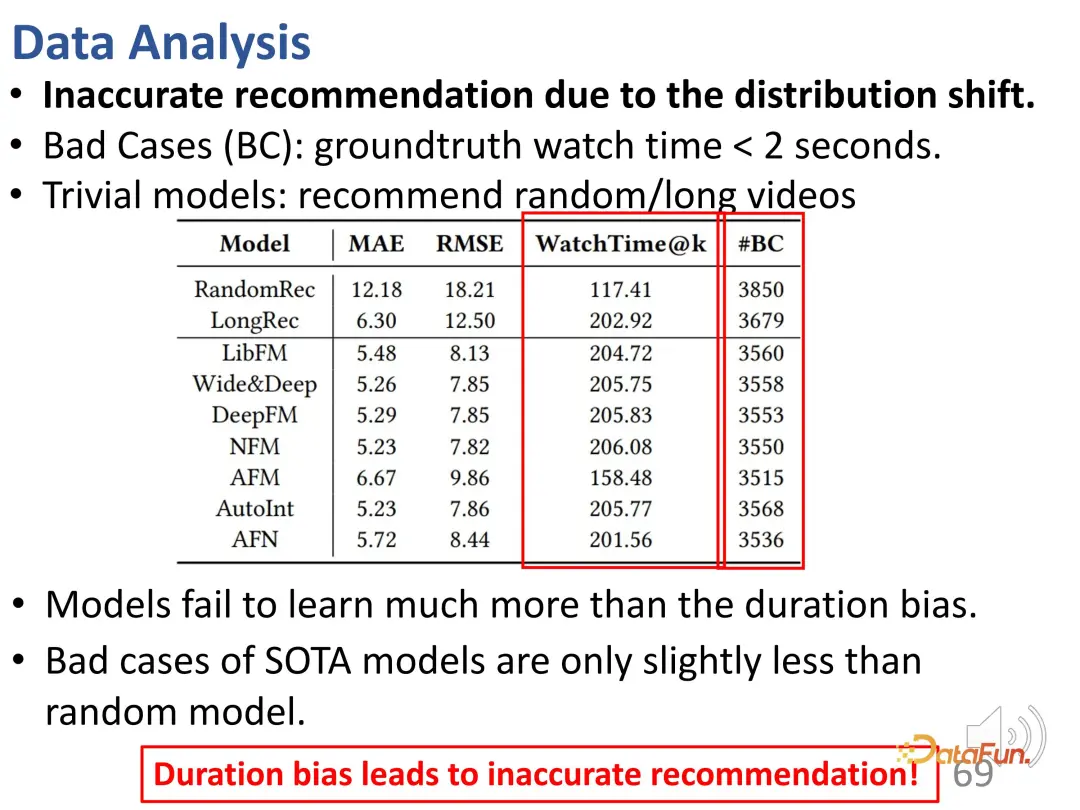
Nous pouvons voir certains mauvais cas, c'est-à-dire des vidéos qui sont regardées pendant moins de 2 secondes et qui ne sont pas appréciées par les utilisateurs. Cependant, en raison de préjugés, ces vidéos sont recommandées à tort. En d’autres termes, le modèle a uniquement appris la différence de durée des vidéos recommandées et n’a pu distinguer que la durée des vidéos. Car le résultat de prédiction souhaité est de recommander des vidéos plus longues pour augmenter la durée de visionnage de l’utilisateur. Ainsi, le modèle sélectionne de longues vidéos au lieu des vidéos que l'utilisateur aime. On peut voir que ces modèles ont même le même nombre de mauvais cas que les recommandations aléatoires, ce biais conduit donc à des recommandations très inexactes.
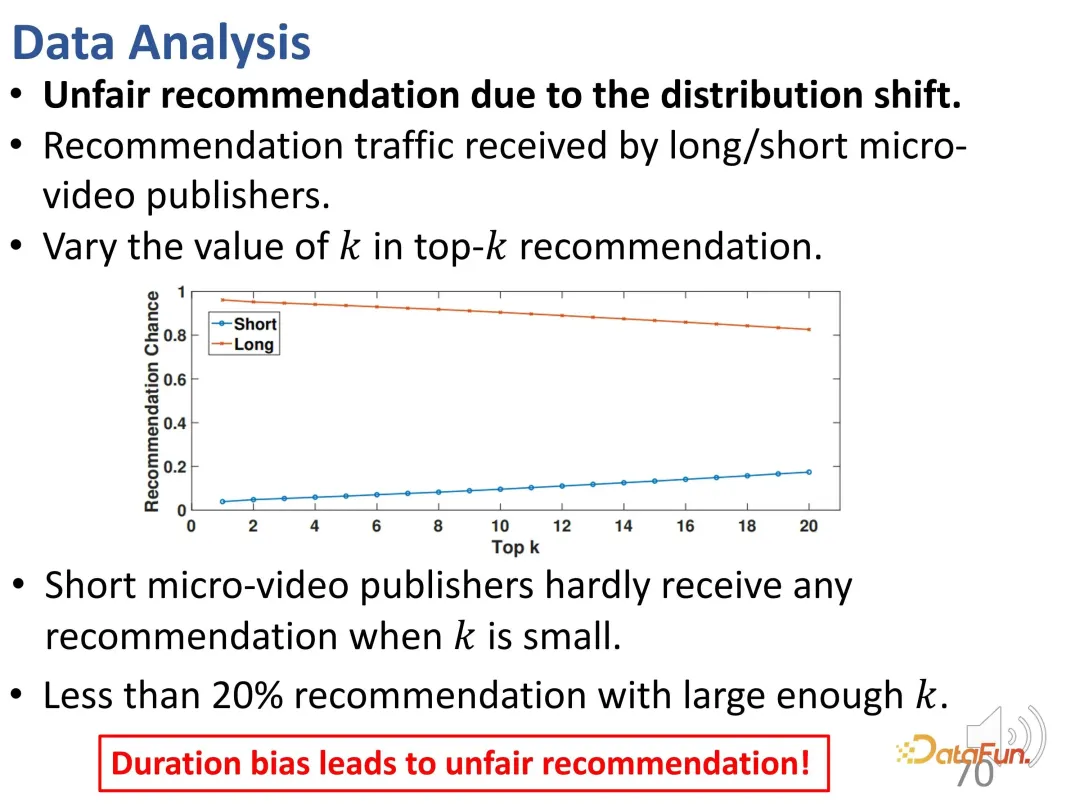
De plus, il y a ici un problème d’injustice. Lorsque la valeur k supérieure du contrôle est faible, les éditeurs de vidéos plus courtes sont difficiles à recommander ; même si la valeur k est suffisamment grande, la proportion de ces recommandations est inférieure à 20 %.
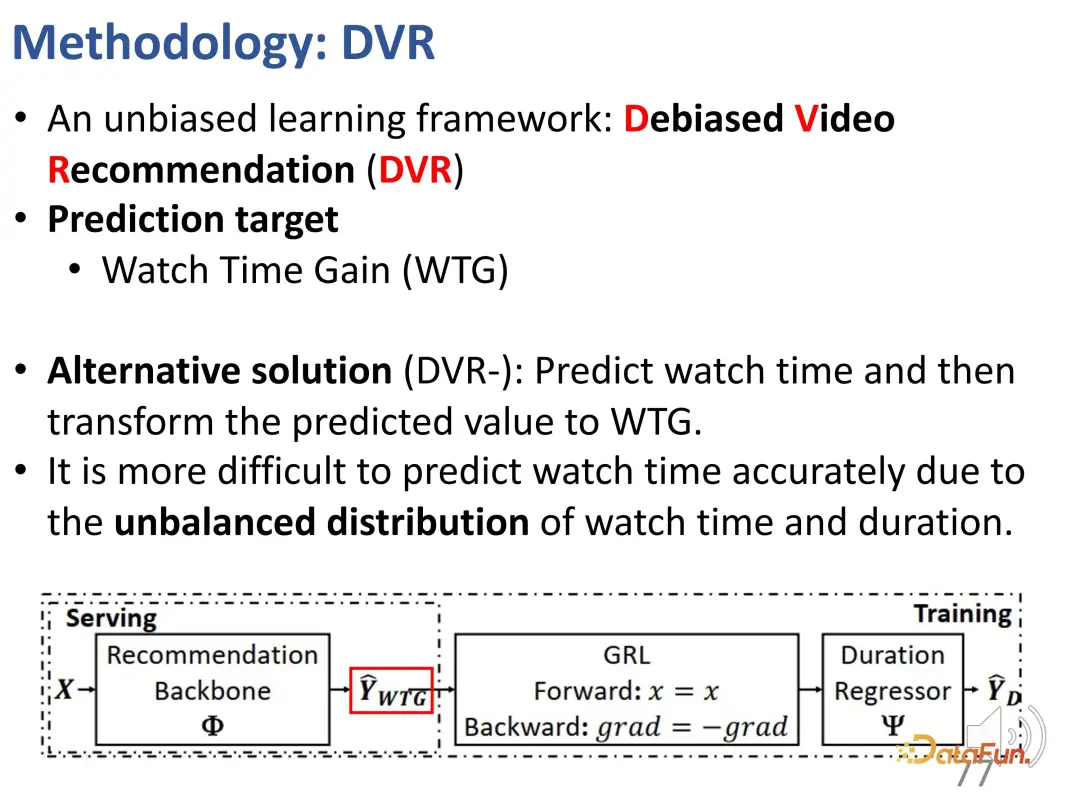
1. Indicateur WTG
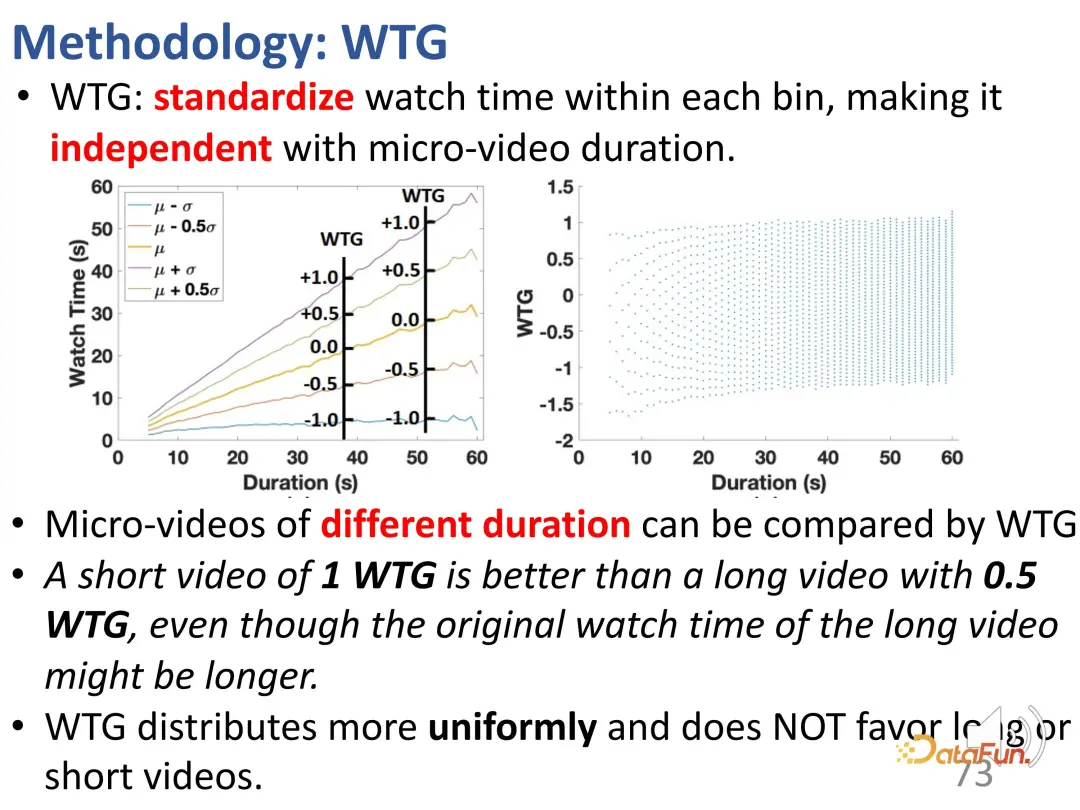
Afin de résoudre ce problème, nous avons d'abord proposé un nouvel indicateur appelé WTG (Watch Time Gain), qui prend en compte le temps de visionnage pour tenter d'être impartial. Par exemple, un utilisateur a regardé une vidéo de 60 secondes pendant 50 secondes ; une autre vidéo durait également 60 secondes, mais n'a été regardée que pendant 5 secondes. Évidemment, si l’on contrôle une vidéo de 60 secondes, la différence d’intérêt entre les deux vidéos est flagrante. C'est une idée simple mais efficace. La durée de visionnage n'a de sens que lorsque d'autres données vidéo ont une durée similaire.
Divisez d'abord toutes les vidéos en différents groupes de durée à intervalles égaux, puis comparez l'intensité de l'intérêt de l'utilisateur dans chaque groupe de durée. Dans le groupe à durée fixe, les intérêts de l'utilisateur peuvent être représentés par la durée. Après l'introduction du WTG, le WTG est en fait utilisé directement pour exprimer l'intensité de l'intérêt de l'utilisateur, sans prêter attention à la durée initiale. Sous les cotes WTG, la répartition est plus uniforme.

Sur la base du WTG, l'importance de la position de tri est examinée plus en détail. Étant donné que WTG ne prend en compte qu’une seule métrique (un seul point), cet effet cumulatif est davantage pris en compte. Autrement dit, lors du calcul de l'index de chaque élément dans la liste triée, la position relative de chaque point de données doit également être prise en compte. Cette idée est similaire à NDCG. C’est donc sur cette base que le DCWTG a été défini.

2. Méthode recommandée pour éliminer les biais
Nous avons préalablement défini des indicateurs qui peuvent refléter les intérêts des utilisateurs quelle que soit la durée, à savoir WTG et NDWTG. Ensuite, concevez une méthode de recommandation capable d’éliminer les biais, indépendante du modèle spécifique et applicable à différents backbones. La méthode DVR (Debiased Video Recommendation) est proposée. L'idée principale est que dans le modèle de recommandation, si les caractéristiques liées à la durée peuvent être supprimées, même si les caractéristiques d'entrée sont complexes et peuvent contenir des informations liées à la durée, à condition qu'elles soient supprimées. peut être utilisé pendant le processus d'apprentissage. Si la sortie du modèle ignore ces caractéristiques de durée, elle peut être considérée comme impartiale, ce qui signifie que le modèle peut filtrer les caractéristiques liées à la durée pour obtenir des recommandations impartiales. Cela implique une sorte d'idée conflictuelle, qui nécessite qu'un autre modèle prédise la durée sur la base des résultats du modèle de recommandation. S'il ne peut pas prédire avec précision la durée, alors on considère que les résultats du modèle précédent ne contiennent pas la caractéristique de durée. . Par conséquent, une méthode d’apprentissage contradictoire est utilisée pour ajouter une couche de régression au modèle de recommandation, qui prédit la durée initiale en fonction du WTG prévu. Si le modèle de base peut effectivement obtenir des résultats impartiaux, alors la couche de régression ne sera pas en mesure de reprédire et de restaurer la durée d'origine.
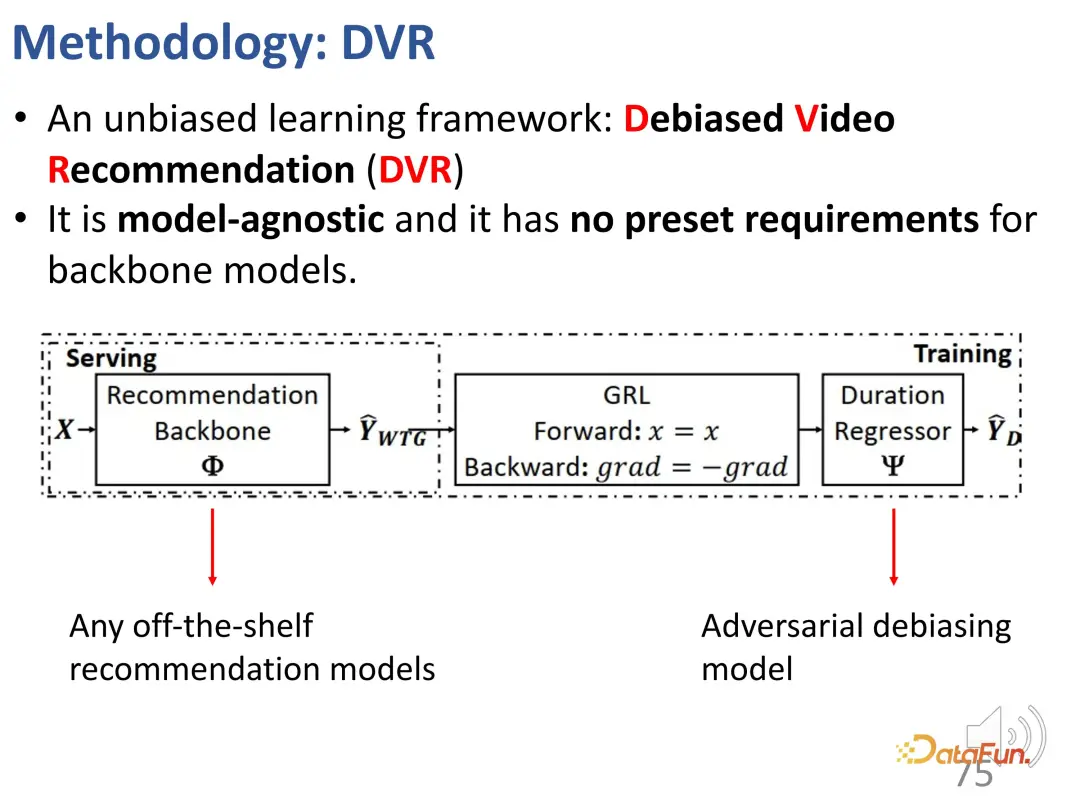


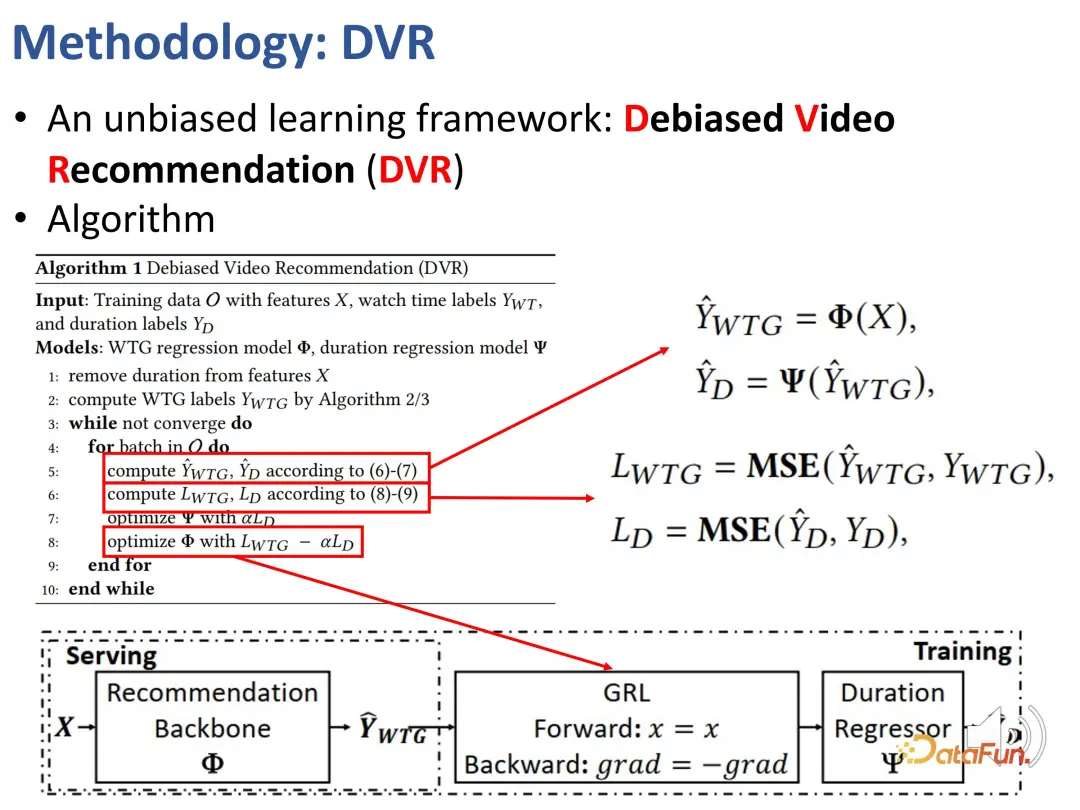
Ce qui précède sont les détails de la méthode utilisée pour mettre en œuvre l'apprentissage contradictoire.
3. Résultats expérimentaux
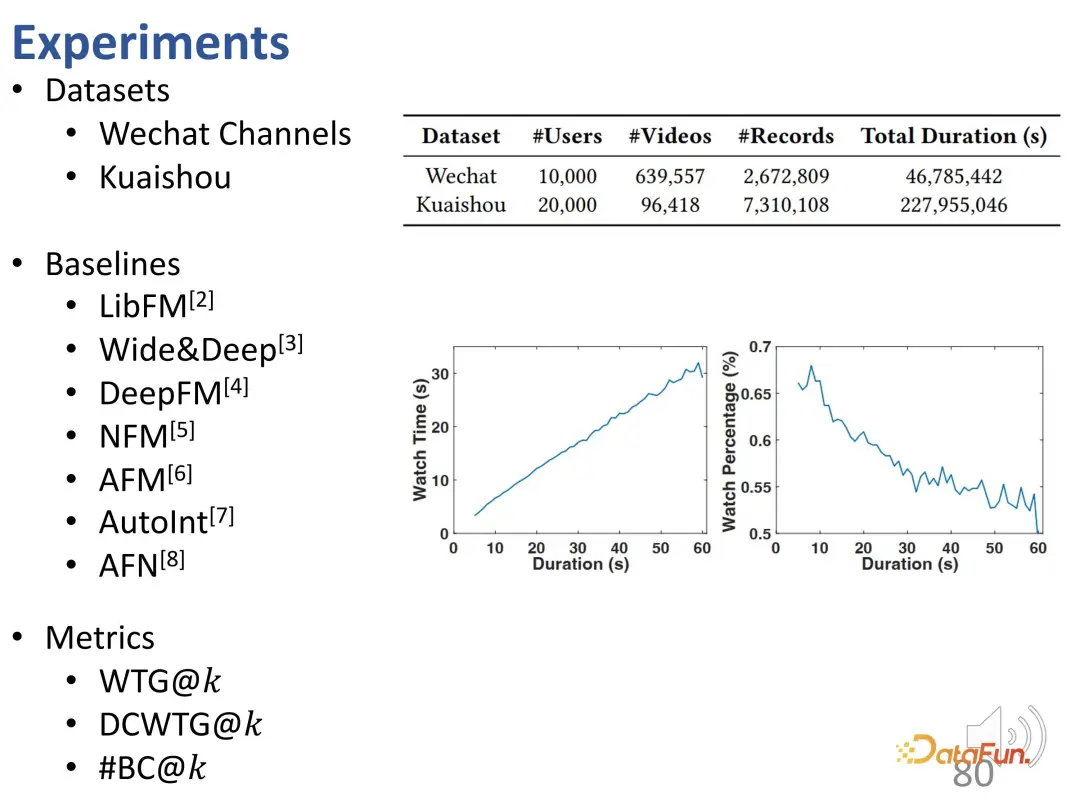
Des expériences ont été menées sur deux ensembles de données de WeChat et Kuaishou. Le premier est WTG par rapport au temps de visionnage. On constate que les deux objectifs d'optimisation sont utilisés séparément et comparés à la durée de visualisation dans la vérité terrain. Après avoir utilisé WTG comme cible, l'effet de recommandation du modèle est meilleur sur les vidéos courtes et longues, et la courbe WTG est stablement située au-dessus de la courbe du temps de visionnage.
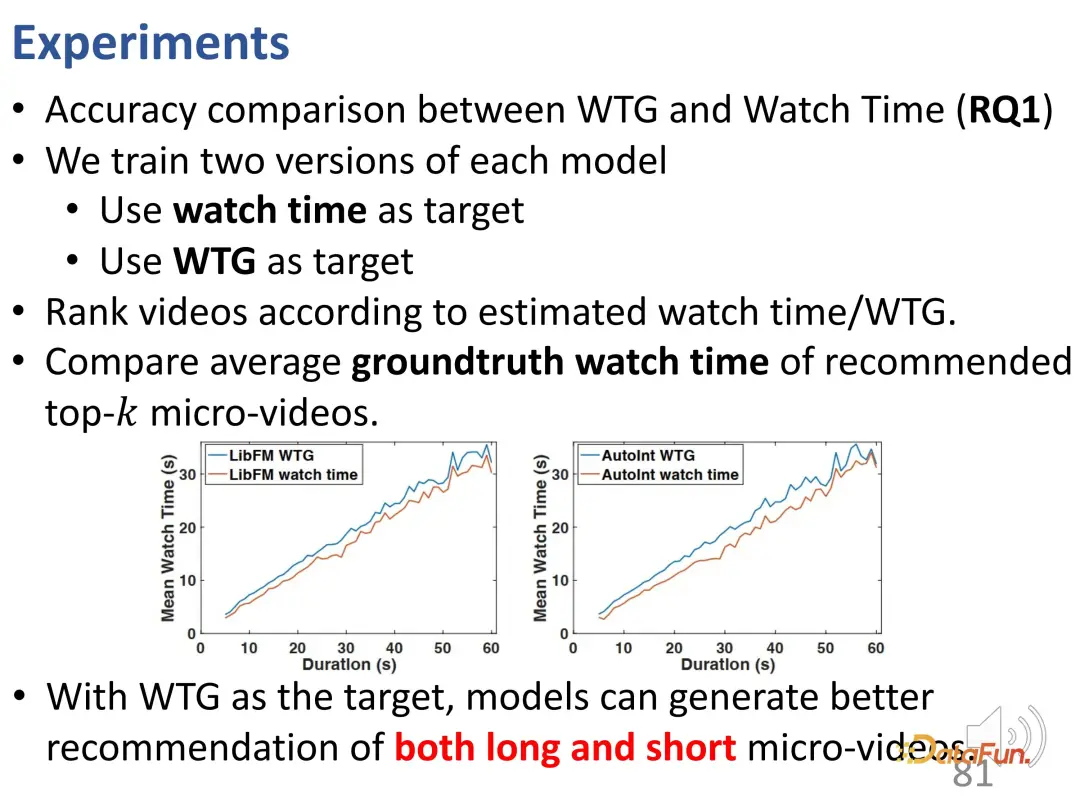
De plus, utiliser WTG comme cible apporte un trafic de recommandations de vidéos longues et courtes plus équilibré (la part de recommandation des vidéos longues est évidemment plus dans le modèle traditionnel).

La méthode DVR proposée convient à différents modèles de backbone : 7 modèles de backbone courants ont été testés, et les résultats ont montré que les performances sans utiliser la méthode de débiasing étaient médiocres, tandis que le DVR fonctionnait bien sur tous les modèles de backbone et tous indicateurs. Il y a eu une certaine amélioration.

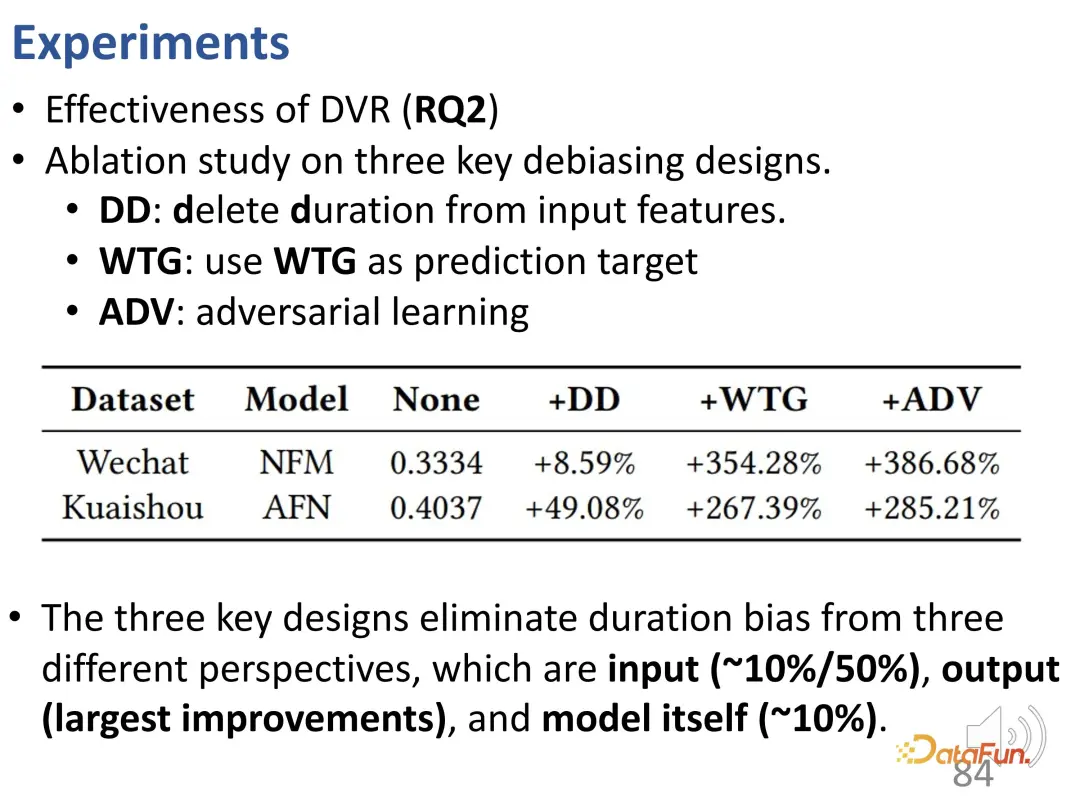
a fait d'autres expériences d'ablation. Comme mentionné dans l’article précédent, cette méthode comporte trois parties de conception, et ces trois parties ont été supprimées respectivement. La première consiste à supprimer la durée en tant que fonctionnalité d'entrée, la seconde consiste à supprimer WTG en tant qu'objectif de prédiction et la troisième consiste à supprimer la méthode d'apprentissage contradictoire. Vous pouvez voir que la suppression de chaque partie entraînera une dégradation des performances. Par conséquent, les trois modèles sont cruciaux.
Pour résumer notre travail : étudier la recommandation de courtes vidéos dans l'optique de réduire les écarts et faire attention à l'écart de durée. Tout d’abord, un nouvel indicateur est proposé : WTG. Il fait un bon travail en éliminant les biais dans le comportement réel (intérêts des utilisateurs et durée). Deuxièmement, une méthode générale est proposée afin que le modèle ne soit plus affecté par la durée de la vidéo, produisant ainsi des recommandations impartiales.

Résumez enfin ce partage. Tout d’abord, comprenez l’apprentissage par intrication sur les intérêts et la conformité des utilisateurs. Ensuite, la séparation des intérêts à long terme et à court terme est étudiée en termes de modélisation séquentielle du comportement. Enfin, une méthode d'apprentissage débiaisant est proposée pour résoudre le problème d'optimisation de la durée de visionnage dans la recommandation de vidéos courtes.
Ce qui précède est le contenu partagé cette fois, merci à tous.
Littérature connexe :
[1] Gao et al. Inférence causale dans les systèmes de recommandation : une enquête et des orientations futures, TOIS 2024
[2] Zheng et al. , WWW 2021.
[3] Zheng et al. DVR : Recommandation micro-vidéo optimisant le gain de temps de visionnage sous biais de durée, MM 2022
[4] Zheng et al. .
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment implémenter un système de recommandation en utilisant le langage Go et Redis
Oct 27, 2023 pm 12:54 PM
Comment implémenter un système de recommandation en utilisant le langage Go et Redis
Oct 27, 2023 pm 12:54 PM
Comment utiliser le langage Go et Redis pour mettre en œuvre un système de recommandation. Le système de recommandation est un élément important de la plate-forme Internet moderne. Il aide les utilisateurs à découvrir et à obtenir des informations intéressantes. Le langage Go et Redis sont deux outils très populaires qui peuvent jouer un rôle important dans le processus de mise en œuvre de systèmes de recommandation. Cet article expliquera comment utiliser le langage Go et Redis pour implémenter un système de recommandation simple et fournira des exemples de code spécifiques. Redis est une base de données open source en mémoire qui fournit une interface de stockage de paires clé-valeur et prend en charge une variété de données
 Algorithmes et applications du système de recommandation implémentés en Java
Jun 19, 2023 am 09:06 AM
Algorithmes et applications du système de recommandation implémentés en Java
Jun 19, 2023 am 09:06 AM
Avec le développement et la vulgarisation continus de la technologie Internet, les systèmes de recommandation, en tant que technologie importante de filtrage des informations, sont de plus en plus largement utilisés et pris en compte. En termes de mise en œuvre d'algorithmes de système de recommandation, Java, en tant que langage de programmation rapide et fiable, a été largement utilisé. Cet article présentera les algorithmes et les applications du système de recommandation implémentés en Java, et se concentrera sur trois algorithmes de système de recommandation courants : l'algorithme de filtrage collaboratif basé sur l'utilisateur, l'algorithme de filtrage collaboratif basé sur les éléments et l'algorithme de recommandation basé sur le contenu. L'algorithme de filtrage collaboratif basé sur l'utilisateur est basé sur le filtrage collaboratif basé sur l'utilisateur
 Exemple d'application : utilisez go-micro pour créer un système de recommandation de microservices
Jun 18, 2023 pm 12:43 PM
Exemple d'application : utilisez go-micro pour créer un système de recommandation de microservices
Jun 18, 2023 pm 12:43 PM
Avec la popularité des applications Internet, l’architecture des microservices est devenue une méthode d’architecture populaire. Parmi eux, la clé de l'architecture des microservices est de diviser l'application en différents services et de communiquer via RPC pour obtenir une architecture de services faiblement couplée. Dans cet article, nous présenterons comment utiliser go-micro pour créer un système de recommandation de microservices basé sur des cas réels. 1. Qu'est-ce qu'un système de recommandation de microservices ? Un système de recommandation de microservices est un système de recommandation basé sur une architecture de microservices qui intègre différents modules dans le système de recommandation (tels que l'ingénierie des fonctionnalités, la classification).
 Le secret d'une recommandation précise : explication détaillée du modèle de rappel impartial d'adaptation de domaine découplé d'Alibaba
Jun 05, 2023 am 08:55 AM
Le secret d'une recommandation précise : explication détaillée du modèle de rappel impartial d'adaptation de domaine découplé d'Alibaba
Jun 05, 2023 am 08:55 AM
1. Introduction au scénario Tout d’abord, introduisons le scénario impliqué dans cet article : le scénario « de bons produits sont disponibles ». Son emplacement se trouve dans la grille à quatre carrés de la page d'accueil de Taobao, qui est divisée en une page de sélection à un saut et une page d'acceptation à deux sauts. Il existe deux formes principales de pages d'hébergement, l'une est une page d'hébergement de graphiques et de textes, et l'autre est une courte page d'hébergement de vidéos. L’objectif de ce scénario est principalement de fournir aux utilisateurs des biens satisfaisants et de stimuler la croissance du GMV, exploitant ainsi davantage l’offre d’experts. 2. Qu'est-ce que le biais de popularité et pourquoi nous abordons ensuite le sujet de cet article, le biais de popularité. Qu’est-ce que le biais de popularité ? Pourquoi un biais de popularité se produit-il ? 1. Qu'est-ce que le biais de popularité ? Le biais de popularité a de nombreux alias, tels que l'effet Matthew et le cocon d'information. Intuitivement, il s'agit d'un carnaval de produits hautement explosifs. Cela entraînera
 Résumé des principales idées techniques et méthodes d'inférence causale
Apr 12, 2023 am 08:10 AM
Résumé des principales idées techniques et méthodes d'inférence causale
Apr 12, 2023 am 08:10 AM
Introduction : L'inférence causale est une branche importante de la science des données. Elle joue un rôle important dans l'évaluation des itérations de produits, des algorithmes et des stratégies d'incitation sur Internet et dans l'industrie. Elle combine des données, des expériences ou des modèles économétriques statistiques pour calculer l'impact de nouveaux changements. les avantages sont la base de la prise de décision. Cependant, l’inférence causale n’est pas une question simple. Tout d’abord, dans la vie quotidienne, les gens confondent souvent corrélation et causalité. La corrélation signifie souvent que deux variables ont tendance à augmenter ou à diminuer en même temps, mais la causalité signifie que nous voulons savoir ce qui se passera lorsque nous modifions une variable, ou que nous nous attendons à obtenir un résultat contrefactuel si nous l'avons fait dans le même temps. passé Si nous prenons des mesures différentes, y aura-t-il des changements dans le futur ? La difficulté, cependant, est que les données contrefactuelles sont souvent
 Comment le langage Go implémente-t-il les systèmes de recherche et de recommandation dans le cloud ?
May 16, 2023 pm 11:21 PM
Comment le langage Go implémente-t-il les systèmes de recherche et de recommandation dans le cloud ?
May 16, 2023 pm 11:21 PM
Avec le développement et la vulgarisation continus de la technologie du cloud computing, les systèmes de recherche et de recommandation dans le cloud deviennent de plus en plus populaires. En réponse à cette demande, le langage Go apporte également une bonne solution. Dans le langage Go, nous pouvons utiliser ses capacités de traitement simultané à grande vitesse et ses riches bibliothèques standard pour mettre en œuvre un système efficace de recherche et de recommandation dans le cloud. Ce qui suit présentera comment le langage Go implémente un tel système. 1. Recherche sur le cloud Tout d'abord, nous devons comprendre la posture et les principes de la recherche. La posture de recherche fait référence aux pages correspondantes du moteur de recherche en fonction des mots-clés saisis par l'utilisateur.
 Système de recommandation pour la technologie de démarrage à froid NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
Système de recommandation pour la technologie de démarrage à froid NetEase Cloud Music
Nov 14, 2023 am 08:14 AM
1. Contexte du problème : la nécessité et l'importance de la modélisation du démarrage à froid. En tant que plate-forme de contenu, Cloud Music propose chaque jour une grande quantité de nouveaux contenus. Bien que la quantité de nouveau contenu sur la plate-forme musicale cloud soit relativement faible par rapport à d'autres plates-formes telles que les courtes vidéos, la quantité réelle peut dépasser de loin l'imagination de chacun. Dans le même temps, le contenu musical est très différent des courtes vidéos, des actualités et des recommandations de produits. Le cycle de vie de la musique s’étend sur des périodes extrêmement longues, souvent mesurées en années. Certaines chansons peuvent exploser après avoir été inactives pendant des mois ou des années, et les chansons classiques peuvent encore avoir une forte vitalité même après plus de dix ans. Par conséquent, pour le système de recommandation des plateformes musicales, il est plus important de découvrir des contenus impopulaires et de longue traîne de haute qualité et de les recommander aux bons utilisateurs que de recommander d'autres catégories.
 Application de la méthode de correction de cause à effet dans le scénario de recommandation Ant Marketing
Jan 13, 2024 pm 12:15 PM
Application de la méthode de correction de cause à effet dans le scénario de recommandation Ant Marketing
Jan 13, 2024 pm 12:15 PM
1. Contexte de la correction de cause à effet 1. Un écart se produit dans le système de recommandation. Des données sont collectées pour entraîner le modèle de recommandation à recommander les éléments appropriés aux utilisateurs. Lorsque les utilisateurs interagissent avec les éléments recommandés, les données collectées sont utilisées pour entraîner davantage le modèle, formant ainsi une boucle fermée. Cependant, il peut y avoir divers facteurs d'influence dans cette boucle fermée, entraînant des erreurs. La principale raison de l'erreur est que la plupart des données utilisées pour entraîner le modèle sont des données d'observation plutôt que des données d'entraînement idéales, qui sont affectées par des facteurs tels que la stratégie d'exposition et la sélection des utilisateurs. L’essence de ce biais réside dans la différence entre les attentes des estimations empiriques du risque et les attentes des véritables estimations du risque idéal. 2. Biais courants Il existe trois principaux types de biais courants dans les systèmes de marketing de recommandation : Biais sélectif : il est dû à la racine de l'utilisateur.
