

JSP抓取网页代码的程序_MySQL

String sCurrentLine;
String sTotalString;
sCurrentLine="";
sTotalString="";
java.io.InputStream l_urlStream;
java.net.URL l_url = new java.net.URL("http://www.163.net/");
java.net.HttpURLConnection l_connection = (java.net.HttpURLConnection) l_url.openConnection();
l_connection.connect();
l_urlStream = l_connection.getInputStream();
java.io.BufferedReader l_reader = new java.io.BufferedReader(new java.io.InputStreamReader(l_urlStream));
while ((sCurrentLine = l_reader.readLine()) != null)
{
sTotalString+=sCurrentLine;
}
out.println(sTotalString);
%>
后记
虽然代码比较简单,但是,我认为根据这个,可以实现“网络爬虫”的功能,比如从页面找href连接,然后再得到那个连接,然后再“抓”,不停止地(当然可以限定层数),这样,可以实现“网页搜索”功能。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment faire de Google Maps la carte par défaut sur iPhone
Apr 17, 2024 pm 07:34 PM
Comment faire de Google Maps la carte par défaut sur iPhone
Apr 17, 2024 pm 07:34 PM
La carte par défaut sur l'iPhone est Maps, le fournisseur de géolocalisation propriétaire d'Apple. Même si la carte s’améliore, elle ne fonctionne pas bien en dehors des États-Unis. Il n'a rien à offrir par rapport à Google Maps. Dans cet article, nous discutons des étapes réalisables pour utiliser Google Maps afin de devenir la carte par défaut sur votre iPhone. Comment faire de Google Maps la carte par défaut sur iPhone Définir Google Maps comme application cartographique par défaut sur votre téléphone est plus facile que vous ne le pensez. Suivez les étapes ci-dessous – Étapes préalables – Vous devez avoir Gmail installé sur votre téléphone. Étape 1 – Ouvrez l'AppStore. Étape 2 – Recherchez « Gmail ». Étape 3 – Cliquez à côté de l'application Gmail
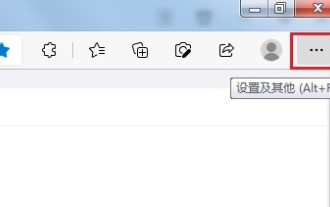 Comment envoyer des pages Web sur le bureau comme raccourci dans le navigateur Edge ?
Mar 14, 2024 pm 05:22 PM
Comment envoyer des pages Web sur le bureau comme raccourci dans le navigateur Edge ?
Mar 14, 2024 pm 05:22 PM
Comment envoyer des pages Web sur le bureau sous forme de raccourci dans le navigateur Edge ? Beaucoup de nos utilisateurs souhaitent afficher les pages Web fréquemment utilisées sur le bureau sous forme de raccourcis pour faciliter l'ouverture directe des pages d'accès, mais ils ne savent pas comment procéder. En réponse à ce problème, l'éditeur de ce numéro partagera le. solution avec la majorité des utilisateurs, jetons un coup d’œil au contenu partagé dans le didacticiel du logiciel d’aujourd’hui. La méthode de raccourci pour envoyer des pages Web au bureau dans le navigateur Edge : 1. Ouvrez le logiciel et cliquez sur le bouton "..." sur la page. 2. Sélectionnez « Installer ce site en tant qu'application » dans « Application » dans l'option du menu déroulant. 3. Enfin, cliquez dessus dans la fenêtre pop-up
 Que faire si le code d'écran bleu 0x0000001 apparaît
Feb 23, 2024 am 08:09 AM
Que faire si le code d'écran bleu 0x0000001 apparaît
Feb 23, 2024 am 08:09 AM
Que faire avec le code d'écran bleu 0x0000001. L'erreur d'écran bleu est un mécanisme d'avertissement en cas de problème avec le système informatique ou le matériel. Le code 0x0000001 indique généralement une panne de matériel ou de pilote. Lorsque les utilisateurs rencontrent soudainement une erreur d’écran bleu lors de l’utilisation de leur ordinateur, ils peuvent se sentir paniqués et perdus. Heureusement, la plupart des erreurs d’écran bleu peuvent être dépannées et traitées en quelques étapes simples. Cet article présentera aux lecteurs certaines méthodes pour résoudre le code d'erreur d'écran bleu 0x0000001. Tout d'abord, lorsque nous rencontrons une erreur d'écran bleu, nous pouvons essayer de redémarrer
 Raisons possibles pour lesquelles la connexion réseau est normale mais le navigateur ne peut pas accéder à la page Web
Feb 19, 2024 pm 03:45 PM
Raisons possibles pour lesquelles la connexion réseau est normale mais le navigateur ne peut pas accéder à la page Web
Feb 19, 2024 pm 03:45 PM
Le navigateur ne peut pas ouvrir la page Web mais le réseau fonctionne normalement. Il existe de nombreuses raisons possibles. Lorsque ce problème survient, nous devons enquêter étape par étape pour déterminer la cause spécifique et résoudre le problème. Tout d’abord, déterminez si la page Web ne peut pas être ouverte est limitée à un navigateur spécifique ou si tous les navigateurs ne peuvent pas ouvrir la page Web. Si un seul navigateur ne parvient pas à ouvrir la page Web, vous pouvez essayer d'utiliser d'autres navigateurs, tels que Google Chrome, Firefox, etc., à des fins de test. Si d'autres navigateurs parviennent à ouvrir la page correctement, le problème vient probablement de ce navigateur spécifique, peut-être
 Application d'horloge manquante sur iPhone : comment y remédier
May 03, 2024 pm 09:19 PM
Application d'horloge manquante sur iPhone : comment y remédier
May 03, 2024 pm 09:19 PM
L'application horloge est-elle absente de votre téléphone ? La date et l'heure apparaîtront toujours sur la barre d'état de votre iPhone. Cependant, sans l'application Horloge, vous ne pourrez pas utiliser l'horloge mondiale, le chronomètre, le réveil et bien d'autres fonctionnalités. Par conséquent, réparer l’application d’horloge manquante devrait figurer en haut de votre liste de tâches. Ces solutions peuvent vous aider à résoudre ce problème. Correctif 1 – Placer l’application Horloge Si vous avez supprimé par erreur l’application Horloge de votre écran d’accueil, vous pouvez remettre l’application Horloge à sa place. Étape 1 – Déverrouillez votre iPhone et commencez à faire glisser votre doigt vers la gauche jusqu'à atteindre la page Bibliothèque d'applications. Étape 2 – Ensuite, recherchez « horloge » dans le champ de recherche. Étape 3 – Lorsque vous voyez « Horloge » ci-dessous dans les résultats de recherche, maintenez-la enfoncée et
 Que faire si la page Web ne peut pas être ouverte
Feb 21, 2024 am 10:24 AM
Que faire si la page Web ne peut pas être ouverte
Feb 21, 2024 am 10:24 AM
Comment résoudre le problème des pages Web qui ne s'ouvrent pas Avec le développement rapide d'Internet, les gens comptent de plus en plus sur Internet pour obtenir des informations, communiquer et se divertir. Cependant, nous rencontrons parfois le problème que la page Web ne peut pas être ouverte, ce qui nous pose beaucoup de problèmes. Cet article vous présentera quelques méthodes courantes pour vous aider à résoudre le problème des pages Web qui ne s'ouvrent pas. Tout d’abord, nous devons déterminer pourquoi la page Web ne peut pas être ouverte. Les raisons possibles incluent des problèmes de réseau, des problèmes de serveur, des problèmes de paramètres du navigateur, etc. Voici quelques solutions : Vérifiez la connexion réseau : Tout d'abord, nous avons besoin
 Résoudre l'erreur du code 0xc000007b
Feb 18, 2024 pm 07:34 PM
Résoudre l'erreur du code 0xc000007b
Feb 18, 2024 pm 07:34 PM
Code de terminaison 0xc000007b Lors de l'utilisation de votre ordinateur, vous rencontrez parfois divers problèmes et codes d'erreur. Parmi eux, le code de terminaison est le plus inquiétant, notamment le code de terminaison 0xc000007b. Ce code indique qu'une application ne peut pas démarrer correctement, provoquant des désagréments pour l'utilisateur. Tout d’abord, comprenons la signification du code de terminaison 0xc000007b. Ce code est un code d'erreur du système d'exploitation Windows qui se produit généralement lorsqu'une application 32 bits tente de s'exécuter sur un système d'exploitation 64 bits. Cela signifie que ça devrait
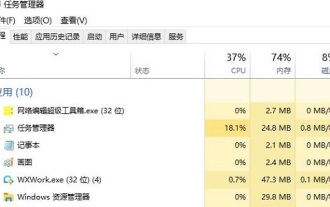 Que dois-je faire si les images de la page Web ne peuvent pas être chargées ? 6 solutions
Mar 15, 2024 am 10:30 AM
Que dois-je faire si les images de la page Web ne peuvent pas être chargées ? 6 solutions
Mar 15, 2024 am 10:30 AM
Certains internautes ont constaté que lorsqu'ils ouvraient la page Web du navigateur, les images de la page Web ne pouvaient pas être chargées pendant une longue période. Que s'est-il passé ? J'ai vérifié que le réseau est normal, alors quel est le problème ? L'éditeur ci-dessous vous présentera six solutions au problème de l'impossibilité de charger les images de pages Web. Les images de la page Web ne peuvent pas être chargées : 1. Problème de vitesse Internet La page Web ne peut pas afficher les images. Cela peut être dû au fait que la vitesse Internet de l'ordinateur est relativement lente et qu'il y a davantage de logiciels ouverts sur l'ordinateur et que les images auxquelles nous accédons sont relativement volumineuses. peut être dû à un délai de chargement. Par conséquent, l'image ne peut pas être affichée. Vous pouvez désactiver le logiciel qui utilise la vitesse du réseau et le vérifier dans le gestionnaire de tâches. 2. Trop de visiteurs Si la page Web ne peut pas afficher d'images, c'est peut-être parce que les pages Web que nous avons visitées ont été visitées en même temps.
