
 Périphériques technologiques
IA
Comment construire un système de gouvernance des données orienté IA ?
Périphériques technologiques
IA
Comment construire un système de gouvernance des données orienté IA ?
Comment construire un système de gouvernance des données orienté IA ?


Ces dernières années, avec l'émergence de nouveaux modèles technologiques, le perfectionnement de la valeur des scénarios d'application dans diverses industries et l'amélioration des effets des produits grâce à l'accumulation de données massives, les applications d'intelligence artificielle se sont développées de la consommation , Internet et d'autres domaines rayonnent dans l'industrie manufacturière, l'énergie et l'électricité et d'autres industries traditionnelles. La maturité de la technologie de l'intelligence artificielle et son application dans les entreprises de divers secteurs dans les principaux maillons des activités de production économique telles que la conception, l'approvisionnement, la production, la gestion et les ventes s'améliorent constamment, accélérant la mise en œuvre et la couverture de l'intelligence artificielle dans tous les maillons, et l'intégrer progressivement à l'activité principale, afin d'améliorer le statut industriel ou d'optimiser l'efficacité opérationnelle, et d'étendre davantage ses propres avantages.
La mise en œuvre à grande échelle d'applications innovantes de la technologie de l'intelligence artificielle a favorisé le développement vigoureux du marché de l'intelligence Big Data et a également injecté une vitalité au marché dans les services sous-jacents de gouvernance des données.
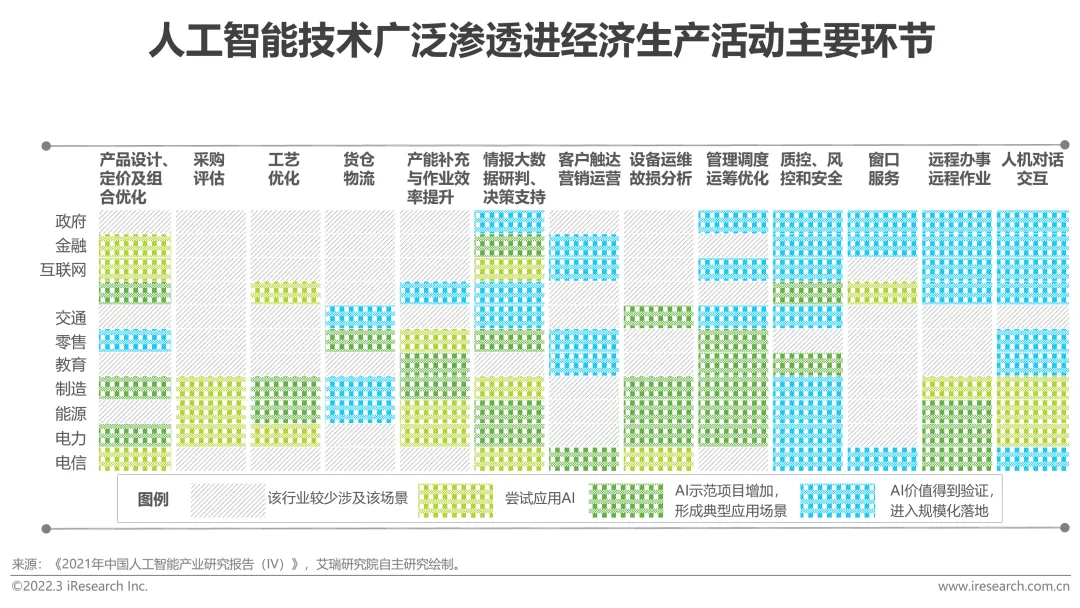
Avec le développement du big data, du cloud computing et des algorithmes, l'engouement pour l'intelligence artificielle s'est poursuivi il y a quelques années jusqu'à aujourd'hui, et est largement utilisée dans de nombreuses industries et domaines, devenant un technologie actuelle en cours Une technologie leader de la révolution. Et comment l’intelligence artificielle peut-elle être absente du domaine en plein essor de la gouvernance des données ? Gouvernance des données et intelligence artificielle sont deux mots apparemment sans rapport. Une fois réunis, quelle histoire se produira-t-il ?
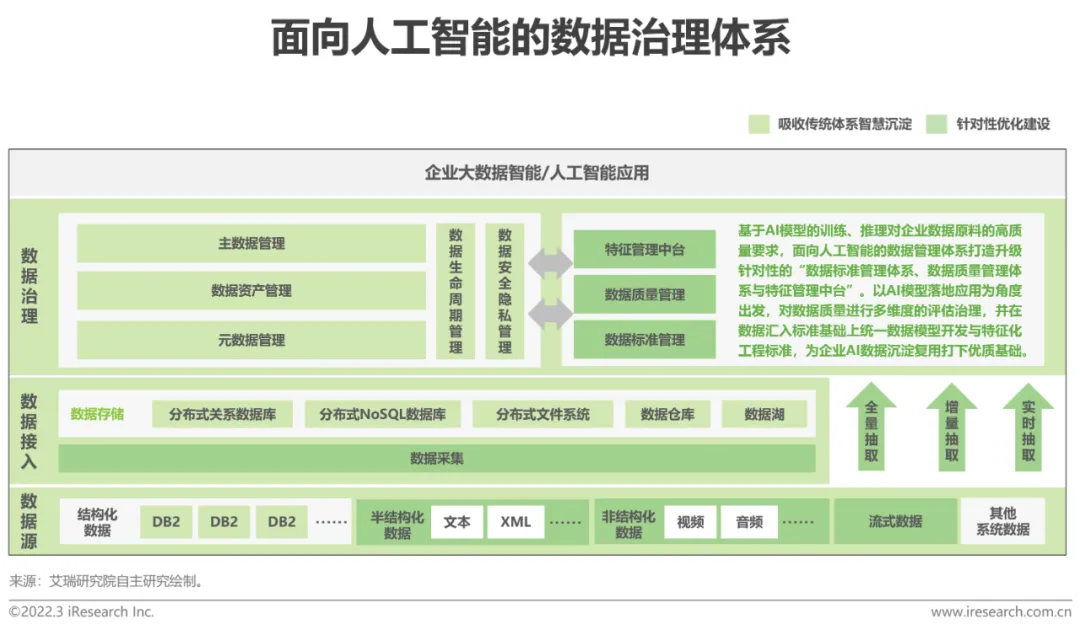
1. La gouvernance des données jette les bases de l'intelligence artificielle
Le Big data est l'accumulation, le nettoyage, la conversion, la classification, etc. continus de données, tandis que la gouvernance des données fournit un modèle de gestion plus standardisé pour la présentation du big data. données . La plupart des formes actuelles d’intelligence artificielle nécessitant une grande quantité de calculs de données, elles sont indissociables du support du big data et de la gouvernance des données. L’intelligence artificielle doit s’appuyer sur des plateformes et des technologies Big Data pour contribuer à achever l’évolution du deep learning.

1. La gouvernance des données fournit des données de haute qualité pour l'intelligence artificielle
La plupart des intelligences artificielles sont divisées en deux maillons : la formation et la prédiction. L'effet des algorithmes de formation automatique dépend de la qualité des données d'entrée. Si les données d'entrée sont biaisées, l'algorithme de sortie sera également biaisé, ce qui peut directement conduire à l'inutilisabilité des résultats obtenus. La gouvernance des données joue un rôle important dans l’amélioration de la qualité des données. En triant les exigences en matière de qualité des données, en définissant les règles d'inspection de la qualité des données, en formulant des plans d'amélioration de la qualité des données, en concevant et en mettant en œuvre des outils de gestion de la qualité des données et en surveillant les procédures opérationnelles et les performances de gestion de la qualité des données, les entreprises peuvent obtenir des données propres et clairement structurées, fournissant des données fiables. contribution aux technologies d’intelligence artificielle telles que l’apprentissage profond.
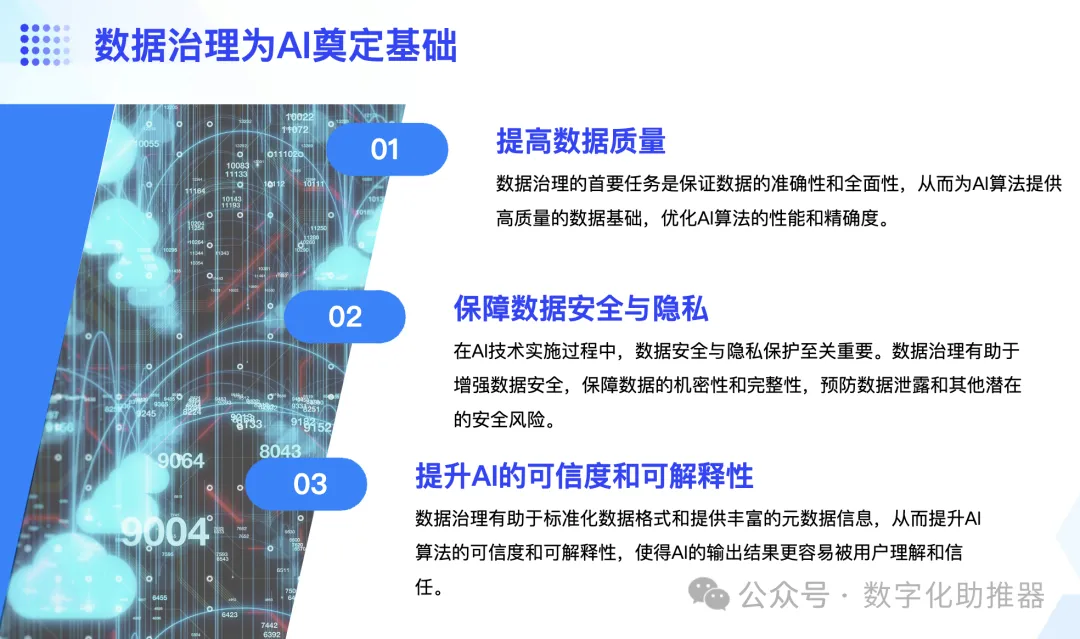
2. La gouvernance des données garantit la confidentialité des données pour l'intelligence artificielle

Les plus grandes contraintes auxquelles est actuellement confronté le développement de l'intelligence artificielle sont les problèmes de propriété des données et de protection de la vie privée. Les données personnelles doivent être protégées. L’utilisation abusive de ces données peut entraîner d’énormes pertes matérielles, voire des blessures corporelles. La soi-disant protection de la vie privée est en réalité la protection des données privées, en dernière analyse, la protection de la vie privée des utilisateurs de données. Les outils de gouvernance des données conçoivent de nombreux aspects de la protection des données privées à un niveau technique, en fournissant une fuzzification des données, une désensibilisation des données et un cryptage des données, qui peuvent jeter les bases de la protection des données personnelles de l'entreprise, assurant ainsi la conformité des données pour les applications d'intelligence artificielle.
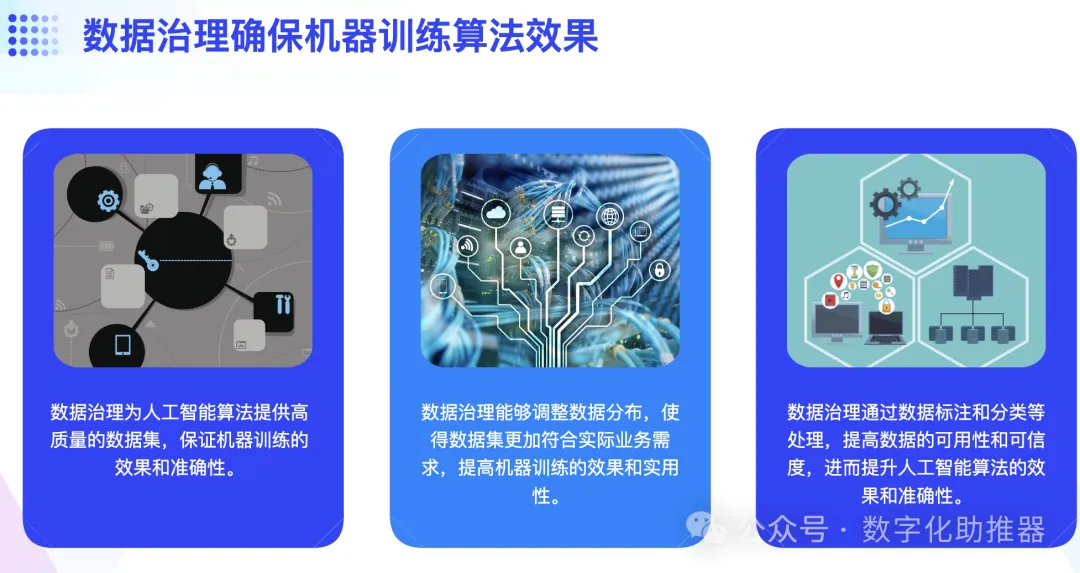
2. L'intelligence artificielle améliore le niveau d'intelligence de la gouvernance des données
1. Gestion des métadonnées

Dans la gestion traditionnelle des métadonnées, pour les données non structurées la collecte est généralement effectuée en créant un index de recherche de données non structurées. Les technologies d'intelligence artificielle telles que la reconnaissance vocale, la reconnaissance d'images et l'analyse de texte peuvent aider à construire le vocabulaire commercial initial des métadonnées et devenir un pool de ressources pour extraire diverses métadonnées non structurées précieuses.
2. Gestion des normes de données

Au début de la mise en œuvre des normes de données, il est nécessaire de mener une enquête approfondie sur les champs de base de données du système existant et d'identifier les champs métiers communs et réutilisés comme la base de l’établissement de normes de données. Si tout cela est fait manuellement, cela nécessitera la coordination d’un grand nombre de personnes provenant de différents départements commerciaux, ce qui entraînera une charge de travail énorme et sera sujette aux erreurs. Grâce à l'apprentissage automatique et à la technologie de traitement du langage naturel, les racines à haute fréquence peuvent être rapidement triées en fonction des noms d'entreprises sur le terrain, et un travail qui peut prendre des mois peut être achevé en quelques jours.
Un autre aspect important de la gestion des normes de données est la cartographie des normes et des métadonnées. Dans de nombreux systèmes d'entreprise, mapper les normes de données aux métadonnées des systèmes d'entreprise est souvent un cauchemar pour les ingénieurs d'implémentation, et il est facile de commettre des erreurs si vous n'y faites pas attention. Grâce à la technologie d'intelligence artificielle, nous pouvons effectuer un traitement du langage naturel sur les noms de domaines d'activité, segmenter avec précision les mots et cartographier automatiquement les normes de données et les métadonnées en fonction de la similarité des racines.
3. Gestion de la qualité des données
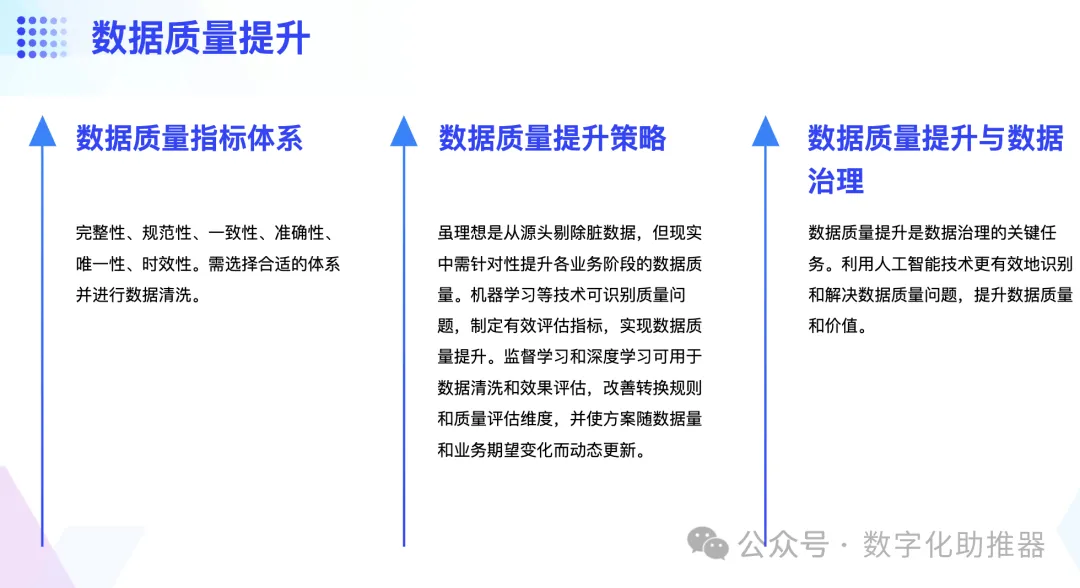
La qualité des données est la base pour garantir une application efficace des données. Le système d'index pour mesurer la qualité des données comprend l'exhaustivité, la normalisation, la cohérence, l'exactitude, l'unicité et l'actualité. Avant de mettre en œuvre le plan d'amélioration de la qualité des données, il est nécessaire de sélectionner un système d'indicateurs de qualité des données approprié, basé sur différentes règles commerciales et attentes commerciales, et de nettoyer les données.
Généralement, le modèle idéal pour améliorer la qualité des données consiste à supprimer les données sales de la source de données, mais cela n'est pas réalisable dans la réalité. Par conséquent, selon les attentes des entreprises, la qualité des données à chaque étape de l’activité doit être améliorée de manière ciblée. L'apprentissage automatique (tel que l'apprentissage de classification, le regroupement, la régression, etc.) peut extraire et identifier les problèmes de qualité existants, formulant ainsi des indicateurs efficaces d'évaluation de la qualité des données et maximisant l'amélioration de la qualité des données sous cet indicateur. Dans le même temps, l'apprentissage supervisé et l'apprentissage profond permettront également d'évaluer les effets du nettoyage et de la qualité des données, améliorant ainsi les règles de conversion et les dimensions d'évaluation de la qualité des données, et mettant à jour dynamiquement les plans d'amélioration de la qualité des données à mesure que le volume de données et les attentes commerciales changent progressivement.
4. Sécurité des données

La sécurité des données fait référence au processus ou à l'état de protection des informations ou des systèmes d'information contre tout accès, utilisation, dommage, modification et destruction non autorisés. La technologie de l'intelligence artificielle peut classer et classer les données sensibles. L'application de l'apprentissage automatique, du traitement du langage naturel et de la technologie de classification par regroupement de textes permet de classer et de classer avec précision les données en temps réel en fonction du contenu. La classification et la classification des données sont le maillon central de la gouvernance de la sécurité des données. Par exemple, l'utilisation de moteurs de classification des données a considérablement amélioré la sécurité dans des domaines tels que le filtrage du contenu des e-mails, la gestion des fichiers confidentiels, l'analyse des renseignements, la lutte contre la fraude et la prévention des fuites de données.
5. Gestion des données de référence

Les données de référence font référence aux données des entités commerciales principales de l'entreprise, également appelées données d'or, qui sont répétées et partagées sur l'ensemble de la chaîne de valeur et appliquées. À plusieurs processus métiers, les données de base partagées entre chaque département métier et chaque système constituent la base de l'interaction des informations entre chaque application métier et chaque système. Cependant, dans le processus de gestion des données de base, les entreprises peuvent être confrontées à des problèmes tels que la manière d'identifier les données de base parmi un grand nombre d'éléments de données et la manière d'établir des normes unifiées en matière de données de base.
La détermination des données de référence dépend de la compréhension par l'entreprise des besoins métiers et de la définition des « données en or » correspondantes. D'une manière générale, chaque domaine de données de base dispose de son propre système d'enregistrement dédié et est dispersé dans différents systèmes d'entreprise. Les technologies liées à l'intelligence artificielle peuvent nous aider à filtrer les données qui apparaissent ou circulent fréquemment de toutes les données, tout en déterminant rapidement les sources de données fiables et dignes de confiance des données de référence et en créant une vue complète des données de référence.
6. L'intelligence artificielle aide à dupliquer les données pour faire correspondre et fusionner automatiquement les données

L'un des défis auxquels est confrontée la gestion des dramatiques numériques est de faire correspondre et de fusionner les mêmes éléments de données ou de dupliquer des éléments de données dans de nombreux systèmes de l'entreprise. Une façon de résoudre ce défi consiste à élaborer des règles de mise en correspondance des données, y compris l'acceptation de correspondance à différents niveaux de confiance. . Certaines correspondances nécessitent un niveau de confiance très élevé et peuvent être basées sur une correspondance précise des données dans plusieurs champs ; certaines correspondances peuvent être obtenues avec un niveau de confiance inférieur simplement en raison de valeurs de données contradictoires. L'apprentissage automatique et le traitement du langage naturel peuvent aider à établir des règles de correspondance pour l'identification des données en double. Après avoir identifié les données de base avec des champs en double, la fusion automatique ne sera pas effectuée et les enregistrements liés aux données de base pourront être déterminés et les relations de références croisées établies.
3. Intelligentisation de la plateforme de gouvernance des données
Abaisser le seuil de la gouvernance des données grâce à la technologie de l'intelligence artificielle deviendra une direction importante pour le développement de la gouvernance des données. Prenant pleinement en compte la grande complexité de la gouvernance des données, la plateforme de gouvernance des données continue d'intégrer de nouvelles technologies d'IA, s'efforçant de simplifier le processus de mise en œuvre de la gouvernance des données grâce à une gestion intelligente, libérant considérablement le personnel technique et aidant les entreprises à parvenir à une gouvernance des données plus efficace et à rester à l'écart. du "trou noir des données".

1. Service de métadonnées intelligent. La plate-forme Ruizhi prend en charge la collecte et l'association de métadonnées entièrement automatiques, réalise une application intelligente des métamodèles et fournit des vues graphiques d'analyse des métadonnées.
2. Exploration intelligente de la qualité des données. La plate-forme Ruizhi intègre des algorithmes statistiques mathématiques et des algorithmes d'apprentissage automatique liés pour détecter automatiquement la qualité des données et prendre en charge une réparation intelligente.
3. Construction intelligente de normes de données. La plateforme Ruizhi prend en charge la cartographie et le marquage intelligents, l'élaboration de normes de données et l'évaluation bidirectionnelle des données commerciales.
4. Identification intelligente des données de base. La plateforme Ruizhi identifie automatiquement les données de base, permet de dupliquer les données automatiquement et de les fusionner, et crée une vue complète des données de base.
Avec le développement rapide des deux domaines de la gouvernance des données et de l'intelligence artificielle, l'intégration des deux aura plus de scénarios et de modèles économiques.
4. Intégration industrielle de la gouvernance des données + IA
La mise en œuvre à grande échelle d'applications technologiques innovantes d'IA a stimulé le développement fulgurant du marché de l'intelligence Big Data
Quand les entreprises déploient des applications d'IA , l'optimisation des ressources de données Les avantages déterminent grandement l'effet de mise en œuvre des applications d'IA. Par conséquent, afin de promouvoir une mise en œuvre de haute qualité des applications d’IA, la réalisation d’un travail ciblé de gouvernance des données est la première et nécessaire étape. Quant au système traditionnel de gouvernance des données que l'entreprise elle-même a construit, il se concentre actuellement sur l'optimisation de la gouvernance des données structurées. Il est encore difficile de répondre aux besoins des applications d'IA en matière de données dans les dimensions de la qualité des données, de la richesse des champs de données, des données. distribution et données en temps réel. Exigences de qualité élevées. Afin de garantir une mise en œuvre de haute qualité des applications d'IA, les entreprises doivent encore mettre en œuvre une gouvernance des données secondaires pour les applications d'intelligence artificielle. 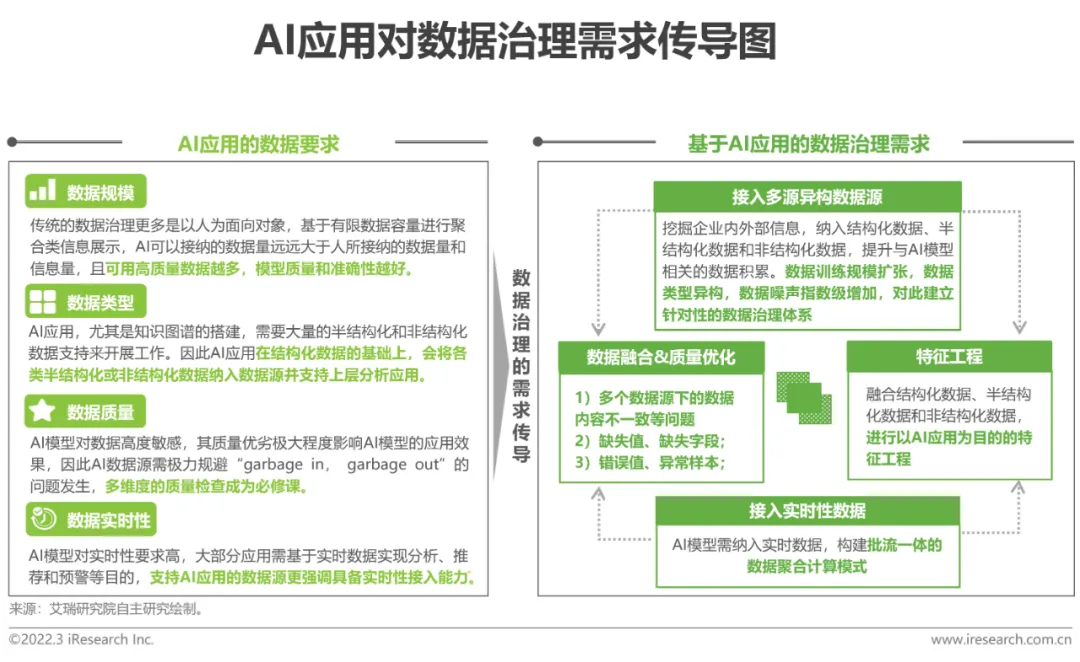
La gouvernance des données pour l'intelligence artificielle est une « mise à niveau » du système de gouvernance des données traditionnel guidée par la mise en œuvre d'applications d'IA.
Du point de vue de la gestion des données, le système de gouvernance des données pour l'intelligence artificielle s'adaptera toujours à la mise en place de la gestion des métadonnées, de la gestion des actifs de données et de la gestion des données de référence basées sur un flux structuré de données, les besoins de gestion des actifs de données et la sécurité des données. besoins, etc., gestion du cycle de vie des données et gestion de la confidentialité de la sécurité des données et d'autres modules de composants. Dans le processus de gouvernance des données , l'accent sera davantage mis sur la couche inférieure pour parvenir à la fusion de données multi-sources, à la fréquence de collecte des données, à l'établissement de normes de données et à la gestion de la qualité des données afin de répondre à l'échelle, à la qualité et à l'actualité des données requises pour l'IA. modèles et répondre aux besoins en données des applications d'IA. En tant que noyau, optimiser la construction du système des modules correspondants.
Le pilote d'application IA est devenu le point d'appui principal des services de gouvernance des données axés sur l'intelligence artificielle
Les services de gouvernance des données orientés vers l'intelligence artificielle sont souvent inclus dans trois types de formulaires d'approvisionnement : les services de données, les capacités de la plateforme et les produits de données. La première catégorie, les services de données, apparaît sous la forme de produits de gouvernance des données distincts ; la deuxième catégorie, les plateformes de données, comprend principalement les plateformes de big data, les plateformes de data middle, les entrepôts de données et les plateformes de capacités d'IA et d'autres projets ; portée Les produits de données limités à l'application d'algorithmes d'IA peuvent être divisés en trois types de produits d'IA : les produits d'apprentissage automatique, les produits de compréhension du langage naturel et les graphiques de connaissances.
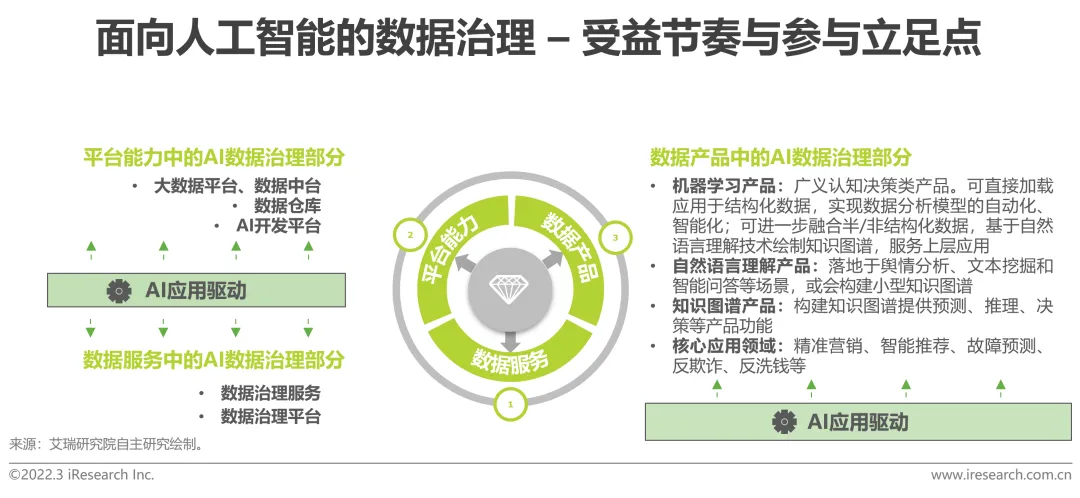
De nos jours, la demande de produits d'IA est forte, et la plateforme de développement d'IA a successivement favorisé la mise en œuvre à grande échelle de produits d'IA, et l'effet de la gouvernance des données d'IA est étroitement lié à effet de livraison du produit de plateforme final.
De manière générale, l'application d'une technologie de pointe peut rendre le travail de gouvernance des données plus rationalisé, automatisé et intelligent, tout en rendant les données évolutives, plus responsables, traçables et plus fiables, ce qui est devenu l'avenir de la gestion des données. seule façon de se développer.
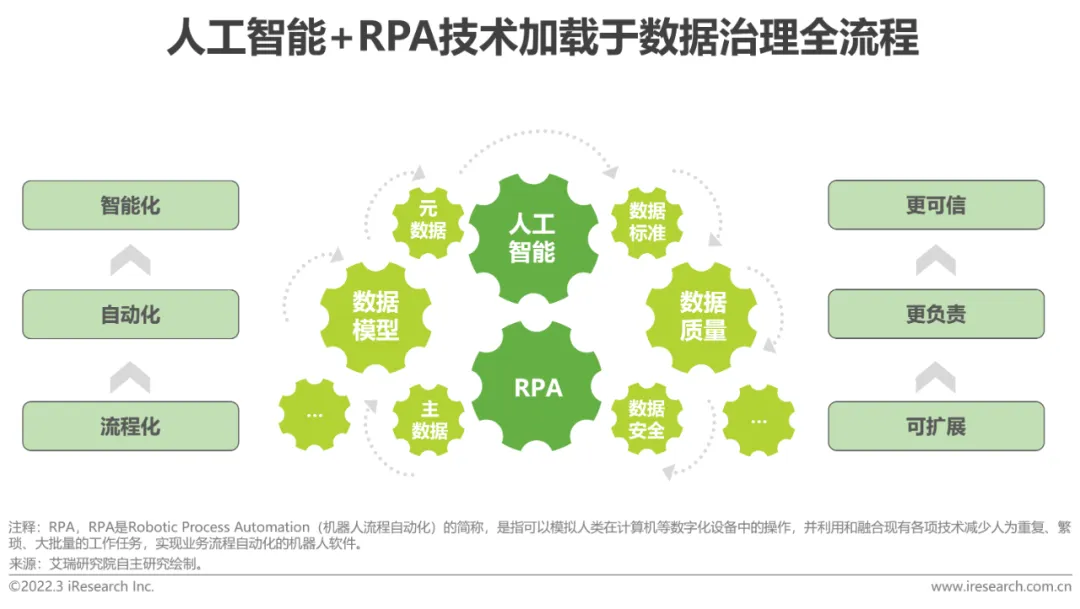
Créer un cycle vertueux de système « gouvernance + IA »
Interdépendants et mutuellement dépendants, promouvant conjointement le développement interne et externe d'applications d'intelligence artificielle
Gouvernance adéquate des données pour les applications d'intelligence artificielle Intelligence L'utilisation de la technologie d'apprentissage automatique pour automatiser et intelligentiser le processus de gouvernance des données peut améliorer considérablement l'efficacité de la gouvernance des données. En même temps, elle peut exploiter la valeur applicative des données non structurées associées sur la base de la compréhension du langage naturel et des graphiques de connaissances, et résoudre les problèmes traditionnels de. gestion de la qualité des données et rendre la gouvernance plus efficace. Les données résultantes sont plus conformes aux exigences des applications d'IA, favorisant la mise en œuvre de modèles d'IA à la fois en termes d'efficacité et de qualité.
Dans le même temps, l'optimisation significative de l'effet de mise en œuvre des applications d'IA apportera également plus de confiance aux entreprises dans la transformation intelligente, leur permettant d'augmenter les investissements budgétaires dans les projets d'IA connexes, et de promouvoir davantage la construction d'une gouvernance pertinente. systèmes, et créer "Un cycle vertueux de "gouvernance + IA"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Selon les informations de ce site Web du 5 juillet, GlobalFoundries a publié un communiqué de presse le 1er juillet de cette année, annonçant l'acquisition de la technologie de nitrure de gallium (GaN) et du portefeuille de propriété intellectuelle de Tagore Technology, dans l'espoir d'élargir sa part de marché dans l'automobile et Internet. des objets et des domaines d'application des centres de données d'intelligence artificielle pour explorer une efficacité plus élevée et de meilleures performances. Alors que des technologies telles que l’intelligence artificielle générative (GenerativeAI) continuent de se développer dans le monde numérique, le nitrure de gallium (GaN) est devenu une solution clé pour une gestion durable et efficace de l’énergie, notamment dans les centres de données. Ce site Web citait l'annonce officielle selon laquelle, lors de cette acquisition, l'équipe d'ingénierie de Tagore Technology rejoindrait GF pour développer davantage la technologie du nitrure de gallium. g
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 Une nouvelle ère de développement front-end VSCode : 12 assistants de code IA hautement recommandés
Jun 11, 2024 pm 07:47 PM
Une nouvelle ère de développement front-end VSCode : 12 assistants de code IA hautement recommandés
Jun 11, 2024 pm 07:47 PM
Dans le monde du développement front-end, VSCode est devenu l'outil de choix pour d'innombrables développeurs grâce à ses fonctions puissantes et son riche écosystème de plug-ins. Ces dernières années, avec le développement rapide de la technologie de l'intelligence artificielle, des assistants de code IA sur VSCode ont vu le jour, améliorant considérablement l'efficacité du codage des développeurs. Les assistants de code IA sur VSCode ont poussé comme des champignons après la pluie, améliorant considérablement l'efficacité du codage des développeurs. Il utilise la technologie de l'intelligence artificielle pour analyser intelligemment le code et fournir une complétion précise du code, une correction automatique des erreurs, une vérification grammaticale et d'autres fonctions, ce qui réduit considérablement les erreurs des développeurs et le travail manuel fastidieux pendant le processus de codage. Aujourd'hui, je recommanderai 12 assistants de code d'IA de développement frontal VSCode pour vous aider dans votre parcours de programmation.
 Iyo One : en partie casque, en partie ordinateur audio
Aug 08, 2024 am 01:03 AM
Iyo One : en partie casque, en partie ordinateur audio
Aug 08, 2024 am 01:03 AM
A tout moment, la concentration est une vertu. Auteur | Editeur Tang Yitao | Jing Yu La résurgence de l'intelligence artificielle a donné naissance à une nouvelle vague d'innovation matérielle. L’AIPin le plus populaire a rencontré des critiques négatives sans précédent. Marques Brownlee (MKBHD) l'a qualifié de pire produit qu'il ait jamais examiné ; David Pierce, rédacteur en chef de The Verge, a déclaré qu'il ne recommanderait à personne d'acheter cet appareil. Son concurrent, le RabbitR1, n'est guère mieux. Le plus grand doute à propos de cet appareil d'IA est qu'il ne s'agit évidemment que d'une application, mais Rabbit a construit un matériel de 200 $. De nombreuses personnes voient l’innovation matérielle en matière d’IA comme une opportunité de renverser l’ère des smartphones et de s’y consacrer.
