
 Périphériques technologiques
IA
S'étendant directement à l'infini, Google Infini-Transformer met fin au débat sur la longueur du contexte
Périphériques technologiques
IA
S'étendant directement à l'infini, Google Infini-Transformer met fin au débat sur la longueur du contexte
S'étendant directement à l'infini, Google Infini-Transformer met fin au débat sur la longueur du contexte

Je ne sais pas si Gemini 1.5 Pro utilise cette technologie.
Google a fait un autre grand pas et a lancé le modèle Transformer de nouvelle génération, Infini-Transformer.
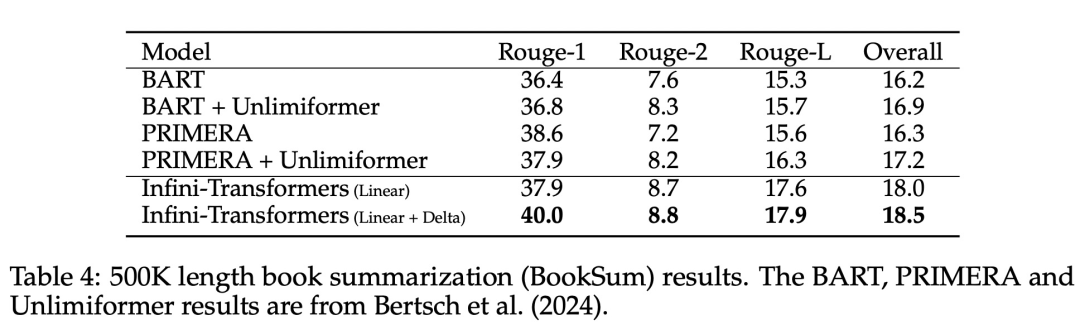
Présente un mécanisme d'attention pratique et puissant Infini-attention - avec une mémoire compressée à long terme et une attention causale locale, qui peut être utilisée efficacement pour modéliser les dépendances contextuelles à long terme et à court terme ; Infini-attention apporte des modifications minimes à l'attention des produits ponctuels à l'échelle standard et est conçu pour prendre en charge la pré-formation continue plug-and-play et l'auto-apprentissage en contexte long. Adaptation ; Cette méthode permet à Transformer LLM de traiter des entrées extrêmement longues via des flux, en s'adaptant à des contextes infiniment longs avec une mémoire et des ressources informatiques limitées. Lien vers l'article H : https://arxiv.org/pdf/2404.07143.pdf

- Introduction à la méthode
Infini-attention permet à Transformer LLM de gérer efficacement des entrées infiniment longues avec une empreinte mémoire et un calcul limités. Comme le montre la figure 1 ci-dessous, Infini-attention intègre une mémoire compressée dans le mécanisme d'attention ordinaire et crée des mécanismes d'attention locale masquée et d'attention linéaire à long terme dans un seul bloc Transformer.
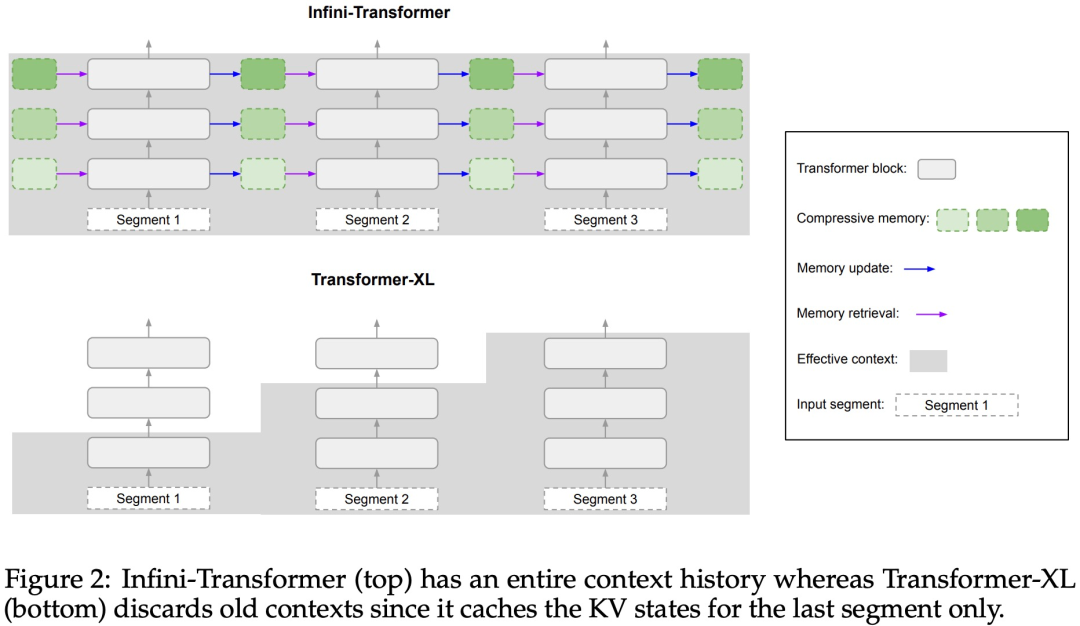

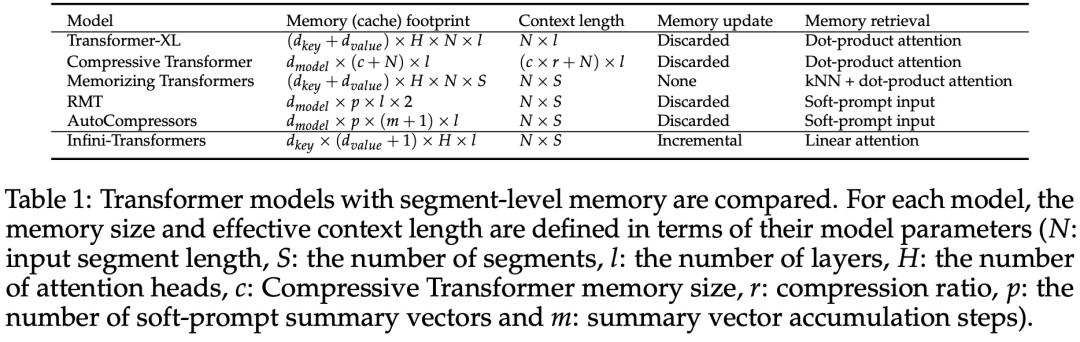
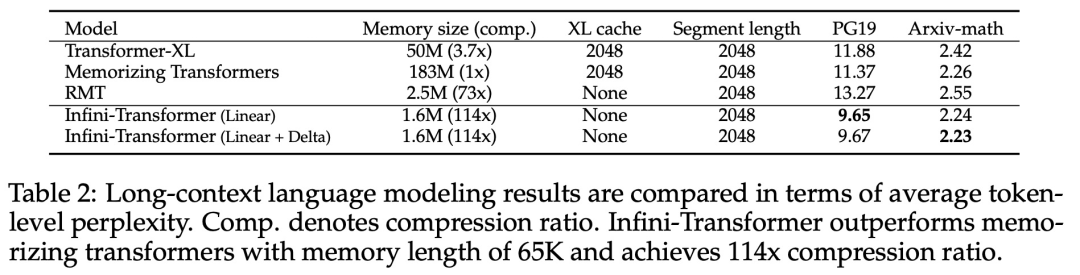
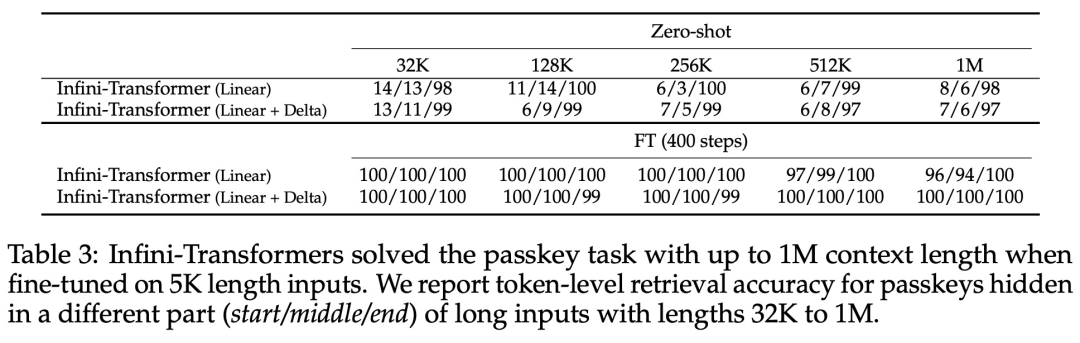

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Sesame Open Door Exchange Page d'enregistrement de page Enregistrement Gate Trading App The Registration Site Web
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Page d'enregistrement de page Enregistrement Gate Trading App The Registration Site Web
Feb 28, 2025 am 11:06 AM
Cet article présente le processus d'enregistrement de la version Web de Sesame Open Exchange (GATE.IO) et l'application Gate Trading en détail. Qu'il s'agisse de l'enregistrement Web ou de l'enregistrement de l'application, vous devez visiter le site Web officiel ou l'App Store pour télécharger l'application authentique, puis remplir le nom d'utilisateur, le mot de passe, l'e-mail, le numéro de téléphone mobile et d'autres informations et terminer la vérification des e-mails ou du téléphone mobile.
 Sesame Open Door Exchange Page Web Login Dernière version GATEIO Entrée du site officiel
Mar 04, 2025 pm 11:48 PM
Sesame Open Door Exchange Page Web Login Dernière version GATEIO Entrée du site officiel
Mar 04, 2025 pm 11:48 PM
Une introduction détaillée à l'opération de connexion de la version Web Sesame Open Exchange, y compris les étapes de connexion et le processus de récupération de mot de passe.
 Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Cet article recommande les dix principales plates-formes de trading de crypto-monnaie qui méritent d'être prêtées, notamment Binance, Okx, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, Bydfi et Xbit décentralisées. Ces plateformes ont leurs propres avantages en termes de quantité de devises de transaction, de type de transaction, de sécurité, de conformité et de fonctionnalités spéciales. Le choix d'une plate-forme appropriée nécessite une considération complète en fonction de votre propre expérience de trading, de votre tolérance au risque et de vos préférences d'investissement. J'espère que cet article vous aide à trouver le meilleur costume pour vous-même
 Pourquoi Bittensor est-il le 'Bitcoin' sur la piste AI?
Mar 04, 2025 pm 04:06 PM
Pourquoi Bittensor est-il le 'Bitcoin' sur la piste AI?
Mar 04, 2025 pm 04:06 PM
Titre original: Bittensor = Aibitcoin? Bittensor adopte un modèle de sous-réseau qui permet l'émergence de différentes solutions d'IA et inspire l'innovation à travers les jetons Tao. Bien que le marché de l'IA soit mûr, Bittensor fait face à des risques concurrentiels et peut être soumis à d'autres open source
 Comment s'inscrire et télécharger la dernière application sur le site officiel de Bitget
Mar 05, 2025 am 07:54 AM
Comment s'inscrire et télécharger la dernière application sur le site officiel de Bitget
Mar 05, 2025 am 07:54 AM
Ce guide fournit des étapes de téléchargement et d'installation détaillées pour l'application officielle Bitget Exchange, adaptée aux systèmes Android et iOS. Le guide intègre les informations de plusieurs sources faisant autorité, y compris le site officiel, l'App Store et Google Play, et met l'accent sur les considérations pendant le téléchargement et la gestion des comptes. Les utilisateurs peuvent télécharger l'application à partir des chaînes officielles, y compris l'App Store, le téléchargement officiel du site Web APK et le saut de site Web officiel, ainsi que des paramètres d'enregistrement, de vérification d'identité et de sécurité. De plus, le guide couvre les questions et considérations fréquemment posées, telles que
 Ouyi okx version officielle télécharger l'entrée de l'application
Mar 04, 2025 pm 11:24 PM
Ouyi okx version officielle télécharger l'entrée de l'application
Mar 04, 2025 pm 11:24 PM
Cet article fournit les dernières informations de téléchargement sur la version officielle d'Ouyi OKX. Cet article guidera les lecteurs sur la façon d'accéder en toute sécurité et facilement aux applications Android et iOS de l'échange. Cet article contient des instructions étape par étape et des conseils importants conçus pour aider les lecteurs à télécharger facilement et à installer l'application OUYI OKX.
 Tutoriel sur la façon de vous inscrire, d'utiliser et d'annuler le compte Okex
Mar 31, 2025 pm 04:21 PM
Tutoriel sur la façon de vous inscrire, d'utiliser et d'annuler le compte Okex
Mar 31, 2025 pm 04:21 PM
Cet article présente en détail les procédures d'enregistrement, d'utilisation et d'annulation du compte OUYI OKEX. Pour vous inscrire, vous devez télécharger l'application, entrez votre numéro de téléphone mobile ou votre adresse e-mail pour vous inscrire et terminer l'authentification réelle. L'utilisation couvre les étapes de fonctionnement telles que les paramètres de connexion, de recharge et de retrait, de transaction et de sécurité. Pour annuler un compte, vous devez contacter le service client OKE OKEX, fournir les informations nécessaires et attendre le traitement, et enfin obtenir la confirmation d'annulation du compte. Grâce à cet article, les utilisateurs peuvent facilement maîtriser la gestion complète du cycle de vie du compte OUYI OKEX et effectuer des transactions d'actifs numériques en toute sécurité et pratiquement.
 Bitget Exchange Portal: Guide officiel de téléchargement de l'application
Mar 05, 2025 am 07:51 AM
Bitget Exchange Portal: Guide officiel de téléchargement de l'application
Mar 05, 2025 am 07:51 AM
Ce guide fournit des étapes de téléchargement et d'installation détaillées pour l'application officielle Bitget Exchange, adaptée aux systèmes Android et iOS. Le guide intègre les informations de plusieurs sources faisant autorité, y compris le site officiel, l'App Store et Google Play, et met l'accent sur les considérations pendant le téléchargement et la gestion des comptes. Les utilisateurs peuvent télécharger l'application à partir des chaînes officielles, y compris l'App Store, le téléchargement officiel du site Web APK et le saut de site Web officiel, ainsi que des paramètres d'enregistrement, de vérification d'identité et de sécurité. De plus, le guide couvre les questions et considérations fréquemment posées, telles que
