
 Périphériques technologiques
IA
Les performances d'exécution locale du service Embedding dépassent celles d'OpenAI Text-Embedding-Ada-002, ce qui est très pratique !
Périphériques technologiques
IA
Les performances d'exécution locale du service Embedding dépassent celles d'OpenAI Text-Embedding-Ada-002, ce qui est très pratique !
Les performances d'exécution locale du service Embedding dépassent celles d'OpenAI Text-Embedding-Ada-002, ce qui est très pratique !

Ollama est un outil super pratique qui vous permet d'exécuter facilement des modèles open source tels que Llama 2, Mistral et Gemma localement. Dans cet article, je vais vous présenter comment utiliser Ollama pour vectoriser du texte. Si Ollama n’est pas installé localement, vous pouvez lire cet article.
Dans cet article, nous utiliserons le modèle nomic-embed-text[2]. Il s'agit d'un encodeur de texte qui surpasse OpenAI text-embedding-ada-002 et text-embedding-3-small sur les tâches à contexte court et à contexte long.
Démarrez le service nomic-embed-text
Après avoir installé avec succès ollama, utilisez la commande suivante pour extraire le modèle nomic-embed-text :
ollama pull nomic-embed-text
Après avoir réussi à extraire le modèle, entrez la commande suivante dans le terminal , démarrez le service ollama :
ollama serve
Après cela, nous pouvons utiliser curl pour vérifier si le service d'intégration fonctionne normalement :
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text","prompt": "The sky is blue because of Rayleigh scattering"}'Utilisez le service nomic-embed-text
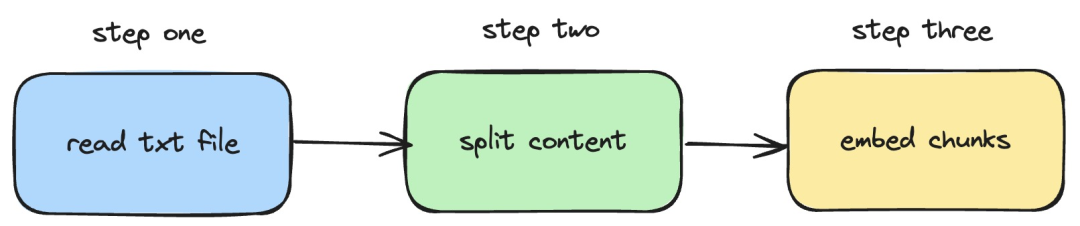
Ensuite, nous présenterons comment pour utiliser langchainjs et le service nomic -embed-text, qui implémente les opérations d'intégration sur les documents txt locaux. Le processus correspondant est illustré dans la figure ci-dessous :
 Pictures
Pictures
1. Lisez le fichier txt local
import { TextLoader } from "langchain/document_loaders/fs/text";async function load(path: string) {const loader = new TextLoader(path);const docs = await loader.load();return docs;}Dans le code ci-dessus, nous avons défini une fonction de chargement, qui utilise en interne le TextLoader fourni par langchainjs pour lire Obtenir le document txt local.
2. Divisez le contenu txt en blocs de texte
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";import { Document } from "langchain/document";function split(documents: Document[]) {const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500,chunkOverlap: 20,});return splitter.splitDocuments(documents);}Dans le code ci-dessus, nous utilisons RecursiveCharacterTextSplitter pour couper le texte txt lu et définir la taille de chaque bloc de texte à 500.
3. Effectuer une opération d'intégration sur des blocs de texte
const EMBEDDINGS_URL = "http://127.0.0.1:11434/api/embeddings";async function embedding(path: string) {const docs = await load(path);const splittedDocs = await split(docs);for (let doc of splittedDocs) {const embedding = await sendRequest(EMBEDDINGS_URL, {model: "nomic-embed-text",prompt: doc.pageContent,});console.dir(embedding.embedding);}}Dans le code ci-dessus, nous définissons une fonction d'intégration, dans laquelle les fonctions de chargement et de fractionnement précédemment définies sont appelées. Parcourez ensuite le bloc de texte généré et appelez le service d'intégration nomic-embed-text démarré localement. La fonction sendRequest est utilisée pour envoyer des requêtes d'intégration. Son code d'implémentation est très simple, qui consiste à utiliser l'API fetch pour appeler l'API REST existante.
async function sendRequest(url: string, data: Record<string, any>) {try {const response = await fetch(url, {method: "POST",body: JSON.stringify(data),headers: {"Content-Type": "application/json",},});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const responseData = await response.json();return responseData;} catch (error) {console.error("Error:", error);}}Ensuite, nous continuons à définir une fonction embedTxtFile, appelons directement la fonction d'intégration existante à l'intérieur de la fonction et ajoutons la gestion des exceptions correspondante.
async function embedTxtFile(path: string) {try {embedding(path);} catch (error) {console.dir(error);}}embedTxtFile("langchain.txt")Enfin, nous utilisons la commande npx esno src/index.ts pour exécuter rapidement le fichier ts local. Si le code dans index.ts est exécuté avec succès, les résultats suivants seront affichés dans le terminal :
 Pictures
Pictures
En fait, en plus d'utiliser la méthode ci-dessus, nous pouvons également utiliser directement [OllamaEmbeddings dans le @ langchain/community module ](https://js.langchain.com/docs/integrations/text_embedding/ollama "OllamaEmbeddings") objet, qui encapsule en interne la logique d'appel du service d'intégration ollama :
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";const embeddings = new OllamaEmbeddings({model: "nomic-embed-text", baseUrl: "http://127.0.0.1:11434",requestOptions: {useMMap: true,numThread: 6,numGpu: 1,},});const documents = ["Hello World!", "Bye Bye"];const documentEmbeddings = await embeddings.embedDocuments(documents);console.log(documentEmbeddings);Le contenu introduit dans cet article implique le développement du système RAG, le processus d'établissement d'un index de contenu d'une base de connaissances. Si vous ne connaissez pas le système RAG, vous pouvez lire des articles connexes.
Références
[1]Ollama : https://ollama.com/
[2]nomic-embed-text : https://ollama.com/library/nomic-embed-text
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct. Cette réalisation innovante a permis une percée significative dans les tâches de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code. Le caractère unique de StarCoder2-15B-Instruct réside dans sa stratégie d'auto-alignement pur. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable. Le modèle génère des milliers d'instructions via StarCoder2-15B en réponse au réglage fin du modèle de base StarCoder-15B sans recourir à des annotations manuelles coûteuses.
 Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
1. Introduction Au cours des dernières années, les YOLO sont devenus le paradigme dominant dans le domaine de la détection d'objets en temps réel en raison de leur équilibre efficace entre le coût de calcul et les performances de détection. Les chercheurs ont exploré la conception architecturale de YOLO, les objectifs d'optimisation, les stratégies d'expansion des données, etc., et ont réalisé des progrès significatifs. Dans le même temps, le recours à la suppression non maximale (NMS) pour le post-traitement entrave le déploiement de bout en bout de YOLO et affecte négativement la latence d'inférence. Dans les YOLO, la conception de divers composants manque d’une inspection complète et approfondie, ce qui entraîne une redondance informatique importante et limite les capacités du modèle. Il offre une efficacité sous-optimale et un potentiel d’amélioration des performances relativement important. Dans ce travail, l'objectif est d'améliorer encore les limites d'efficacité des performances de YOLO à la fois en post-traitement et en architecture de modèle. à cette fin
 Comparaison des performances de différents frameworks Java
Jun 05, 2024 pm 07:14 PM
Comparaison des performances de différents frameworks Java
Jun 05, 2024 pm 07:14 PM
Comparaison des performances de différents frameworks Java : Traitement des requêtes API REST : Vert.x est le meilleur, avec un taux de requêtes de 2 fois SpringBoot et 3 fois Dropwizard. Requête de base de données : HibernateORM de SpringBoot est meilleur que l'ORM de Vert.x et Dropwizard. Opérations de mise en cache : le client Hazelcast de Vert.x est supérieur aux mécanismes de mise en cache de SpringBoot et Dropwizard. Cadre approprié : choisissez en fonction des exigences de l'application. Vert.x convient aux services Web hautes performances, SpringBoot convient aux applications gourmandes en données et Dropwizard convient à l'architecture de microservices.
 L'Université Tsinghua a pris le relais et YOLOv10 est sorti : les performances ont été grandement améliorées et il figurait sur la hot list de GitHub
Jun 06, 2024 pm 12:20 PM
L'Université Tsinghua a pris le relais et YOLOv10 est sorti : les performances ont été grandement améliorées et il figurait sur la hot list de GitHub
Jun 06, 2024 pm 12:20 PM
La série de référence YOLO de systèmes de détection de cibles a une fois de plus reçu une mise à niveau majeure. Depuis la sortie de YOLOv9 en février de cette année, le relais de la série YOLO (YouOnlyLookOnce) a été passé entre les mains de chercheurs de l'Université Tsinghua. Le week-end dernier, la nouvelle du lancement de YOLOv10 a attiré l'attention de la communauté IA. Il est considéré comme un cadre révolutionnaire dans le domaine de la vision par ordinateur et est connu pour ses capacités de détection d'objets de bout en bout en temps réel, poursuivant l'héritage de la série YOLO en fournissant une solution puissante alliant efficacité et précision. Adresse de l'article : https://arxiv.org/pdf/2405.14458 Adresse du projet : https://github.com/THU-MIG/yo
 Rapport technique Google Gemini 1.5 : prouvez facilement les questions de l'Olympiade mathématique, la version Flash est 5 fois plus rapide que GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Rapport technique Google Gemini 1.5 : prouvez facilement les questions de l'Olympiade mathématique, la version Flash est 5 fois plus rapide que GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
En février de cette année, Google a lancé le grand modèle multimodal Gemini 1.5, qui a considérablement amélioré les performances et la vitesse grâce à l'ingénierie et à l'optimisation de l'infrastructure, à l'architecture MoE et à d'autres stratégies. Avec un contexte plus long, des capacités de raisonnement plus fortes et une meilleure gestion du contenu multimodal. Ce vendredi, Google DeepMind a officiellement publié le rapport technique de Gemini 1.5, qui couvre la version Flash et d'autres mises à jour récentes. Le document fait 153 pages. Lien du rapport technique : https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf Dans ce rapport, Google présente Gemini1
 Comment optimiser les performances des programmes multi-thread en C++ ?
Jun 05, 2024 pm 02:04 PM
Comment optimiser les performances des programmes multi-thread en C++ ?
Jun 05, 2024 pm 02:04 PM
Les techniques efficaces pour optimiser les performances multithread C++ incluent la limitation du nombre de threads pour éviter les conflits de ressources. Utilisez des verrous mutex légers pour réduire les conflits. Optimisez la portée du verrou et minimisez le temps d’attente. Utilisez des structures de données sans verrouillage pour améliorer la simultanéité. Évitez les attentes occupées et informez les threads de la disponibilité des ressources via des événements.
 ChatGPT est désormais disponible pour macOS avec la sortie d'une application dédiée
Jun 27, 2024 am 10:05 AM
ChatGPT est désormais disponible pour macOS avec la sortie d'une application dédiée
Jun 27, 2024 am 10:05 AM
L'application ChatGPT Mac d'Open AI est désormais accessible à tous, après avoir été limitée aux seuls utilisateurs disposant d'un abonnement ChatGPT Plus au cours des derniers mois. L'application s'installe comme n'importe quelle autre application Mac native, à condition que vous disposiez d'un Apple S à jour.
