
 Périphériques technologiques
IA
Al Agent--Une orientation de mise en œuvre importante à l'ère des grands modèles
Périphériques technologiques
IA
Al Agent--Une orientation de mise en œuvre importante à l'ère des grands modèles
Al Agent--Une orientation de mise en œuvre importante à l'ère des grands modèles

1. L'architecture globale de l'Agent basé sur LLM
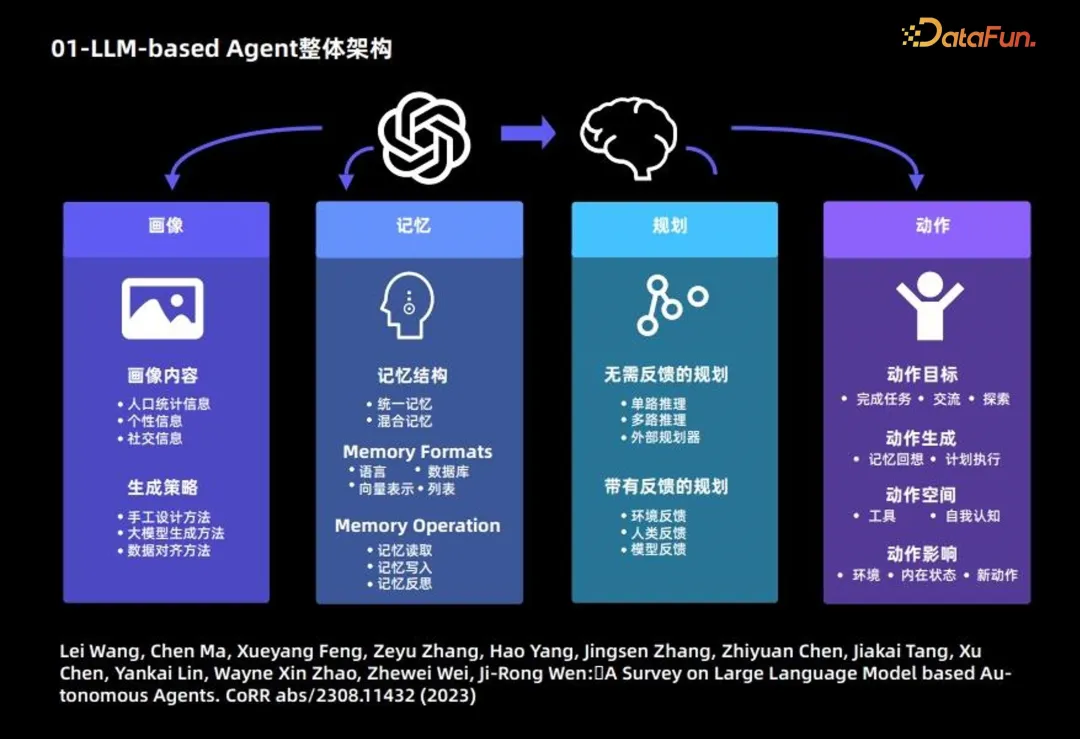
La composition du grand modèle de langage Agent est principalement divisée en 4 modules suivants :
1. informations de l'Agent
Ce qui suit présente le contenu principal et la stratégie de génération du module portrait.
Le contenu du portrait repose principalement sur 3 types d'informations : les informations démographiques, les informations de personnalité et les informations sociales.
Stratégie de génération : 3 stratégies sont principalement utilisées pour générer le contenu du portrait :
- Méthode de conception manuelle : Écrivez le contenu du portrait de l'utilisateur dans l'invite du grand modèle d'une manière spécifiée applicable au numéro ; d'agents Relativement peu de situations ;
- Méthode de génération de grands modèles : spécifiez d'abord un petit nombre de portraits et utilisez-les comme exemples, puis utilisez un grand modèle de langage pour générer plus de portraits adaptés aux situations avec un grand nombre de ; Agents ;
- Méthode d'alignement des données : il est nécessaire d'utiliser les informations de base des caractères dans l'ensemble de données prédéfinies comme invite du grand modèle de langage, puis de faire les prédictions correspondantes.
2. Module de mémoire : L'objectif principal est d'enregistrer le comportement de l'agent et de fournir un support pour les décisions futures de l'agent
Structure de la mémoire :
- Mémoire unifiée : seule la mémoire à court terme est prise en compte, pas de mémoire à long terme.
- Mémoire hybride : Mémoire à long terme et mémoire à court terme combinées.
Forme mémoire : Principalement basée sur les 4 formes suivantes.
- Langue
- Base de données
- Représentation vectorielle
- Liste
Contenu de la mémoire : Les 3 opérations courantes suivantes sont :
- Lecture de mémoire
- Écriture de mémoire
- Réflexion de mémoire
3. en cours d'inférence Aucun retour de l’environnement extérieur est requis. Ce type de planification est subdivisé en trois types : le raisonnement basé sur un seul canal, qui utilise un grand modèle de langage une seule fois pour produire complètement les étapes du raisonnement ; le raisonnement basé sur plusieurs canaux, s'appuyant sur l'idée du crowdsourcing, permettre au grand modèle de langage de générer plusieurs raisons du chemin et de déterminer le meilleur chemin ; emprunter à un planificateur externe ;
- Planification avec retour d'information : Cette méthode de planification nécessite un retour d'information de l'environnement externe, tandis que le grand modèle de langage nécessite un retour d'information de l'environnement pour l'étape suivante et la planification ultérieure. Les fournisseurs de ce type de retour d’information sur la planification proviennent de trois sources : le retour d’information environnemental, le retour d’information humain et le retour d’information du modèle.
- 4. Module d'action
Objectifs d'action : certains objectifs de l'agent sont d'accomplir une tâche, d'autres de communiquer et d'autres d'explorer.
- Génération d'actions : certains agents s'appuient sur le rappel de mémoire pour générer des actions, et certains effectuent des actions spécifiques selon le plan d'origine.
- Espace d'action : certains espaces d'action sont un ensemble d'outils, et d'autres sont basés sur les connaissances propres du grand modèle de langage, considérant l'ensemble de l'espace d'action du point de vue de la conscience de soi.
- Impact de l'action : y compris l'impact sur l'environnement, l'impact sur l'état interne et l'impact sur les nouvelles actions dans le futur.
- Ce qui précède est le cadre général d'Agent. Pour plus d'informations, veuillez vous référer aux articles suivants :
.
2. Problèmes clés et difficiles de l'agent basé sur LLM
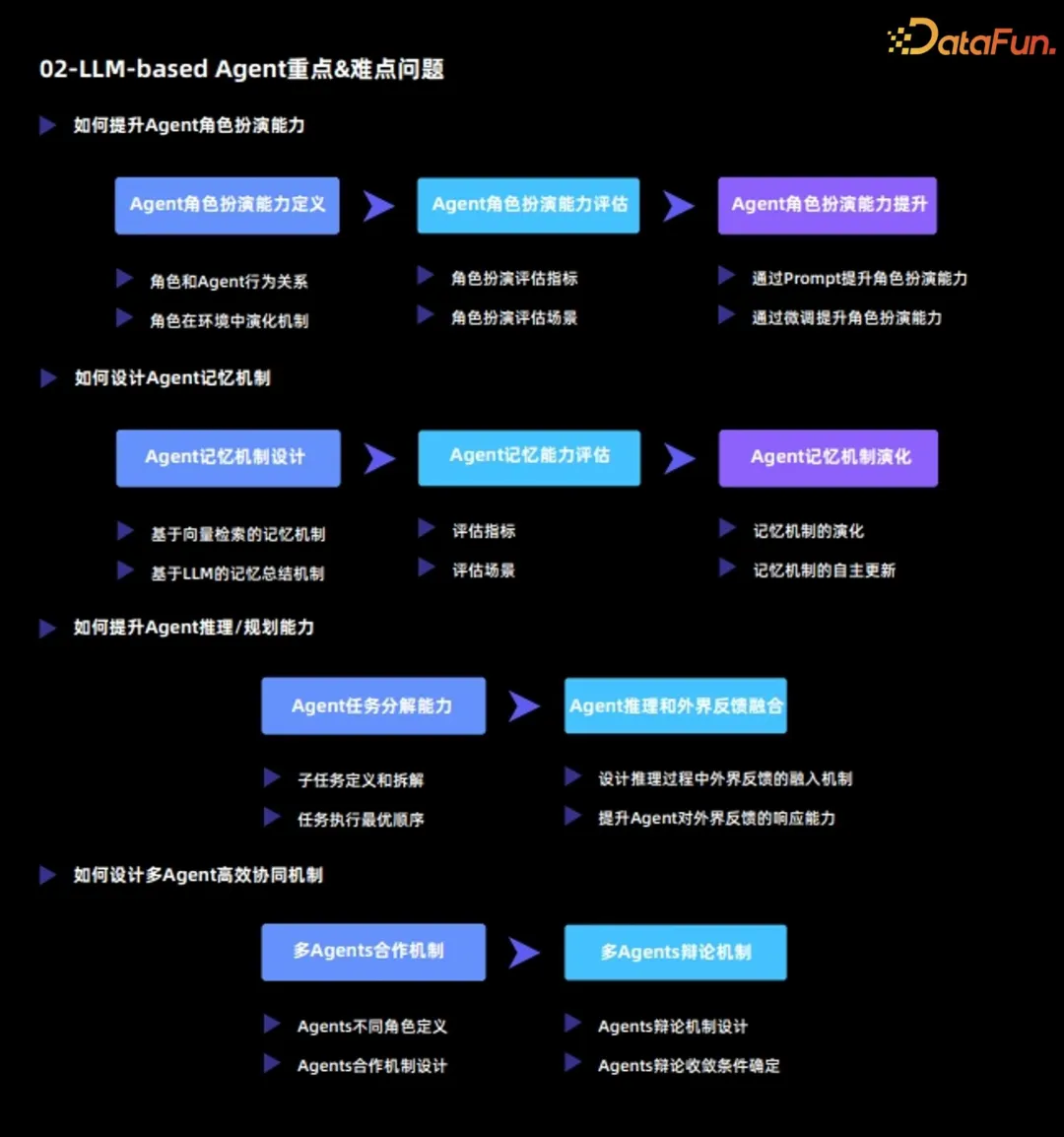
Les problèmes clés et difficiles de l'agent actuel du grand modèle de langage comprennent principalement :
1.
Agent La fonction la plus importante est d'accomplir des tâches spécifiques ou de réaliser diverses simulations en jouant un certain rôle, la capacité de jeu de rôle de l'Agent est donc cruciale.
(1) Définition de la capacité de jeu de rôle d'un agent
La capacité de jeu de rôle d'un agent est divisée en deux dimensions :
- Relation comportementale entre le personnage et l'agent
- Mécanisme d'évolution du personnage dans le environnement
(2) Évaluation de la capacité de jeu de rôle de l'agent
Après avoir défini la capacité de jeu de rôle, l'étape suivante consiste à évaluer la capacité de jeu de rôle de l'agent sous les deux aspects suivants :
- Indicateurs d'évaluation du jeu de rôle
- Scénario d'évaluation du jeu de rôle
(3) Amélioration de la capacité de jeu de rôle de l'agent
Sur la base de l'évaluation, la capacité de jeu de rôle de l'agent doit être encore amélioré. Il en existe deux types : Méthode :
- Améliorer les capacités de jeu de rôle grâce aux invites : L'essence de cette méthode est de stimuler la capacité du grand modèle de langage original en concevant des invites ; Améliorez les capacités de jeu de rôle grâce à un réglage fin : cette méthode est généralement basée sur l'utilisation de données externes, affinez à nouveau le grand modèle de langage pour améliorer les capacités de jeu de rôle.
- 2. Comment concevoir le mécanisme de mémoire de l'agent
La plus grande différence entre l'agent et le grand modèle de langage est que l'agent peut continuellement évoluer et s'auto-apprendre dans l'environnement, le mécanisme de mémoire joue un rôle très important ; personnage de rôle important de. Analysez le mécanisme de mémoire de l'agent à partir de 3 dimensions :
(1) Conception du mécanisme de mémoire de l'agent
Il existe deux mécanismes de mémoire courants :
Mécanisme de mémoire basé sur la récupération vectorielle
- Mécanisme de mémoire basé sur le résumé du LLM
- (2) Évaluation de la capacité de mémoire de l'agent
Pour évaluer la capacité de mémoire de l'agent, il faut principalement déterminer les deux points suivants :
Indicateurs d'évaluation
- Scénario d'évaluation
- (3) Evolution du mécanisme de mémoire de l'agent
Enfin, l'évolution du mécanisme de mémoire de l'agent doit être analysée, notamment :
- Évolution du mécanisme de mémoire
- Mise à jour autonome du mécanisme de mémoire
3. Comment améliorer la capacité de raisonnement/planification de l'agent
(1) Capacité de décomposition des tâches de l'agent
- Définition et démantèlement des sous-tâches
- Ordre optimal d'exécution des tâches
(2) Intégration du raisonnement de l'agent et du feedback externe
- Concevoir le mécanisme d'intégration du feedback externe dans le processus de raisonnement : laissez l'agent et l'environnement former un tout interactif ; d'un autre côté, l'Agent doit être capable de poser des questions et de rechercher des solutions à l'environnement externe.
- 4. Comment concevoir un mécanisme de collaboration multi-agents efficace
Définition des rôles différents des agents
- Mécanisme de coopération des agents conception (2) Mécanisme de débat multi-agents
- 3. basé sur de grands modèles de langage Agent de simulation de comportement
Voici quelques cas réels d'Agent. Le premier est un agent de simulation du comportement des utilisateurs basé sur un grand modèle de langage. Cet agent est également l'un des premiers travaux combinant de grands agents de modèles de langage avec l'analyse du comportement des utilisateurs. Dans ce travail, chaque Agent est divisé en trois modules :
- 1. Le module portrait précise différents attributs pour différents Agents, tels que l'identité, le nom, la profession, l'âge, les intérêts, les caractéristiques, etc.
- 2. Module mémoire
Le module mémoire comprend trois sous-modules (1) Mémoire ressentie
(2) Mémoire à court terme
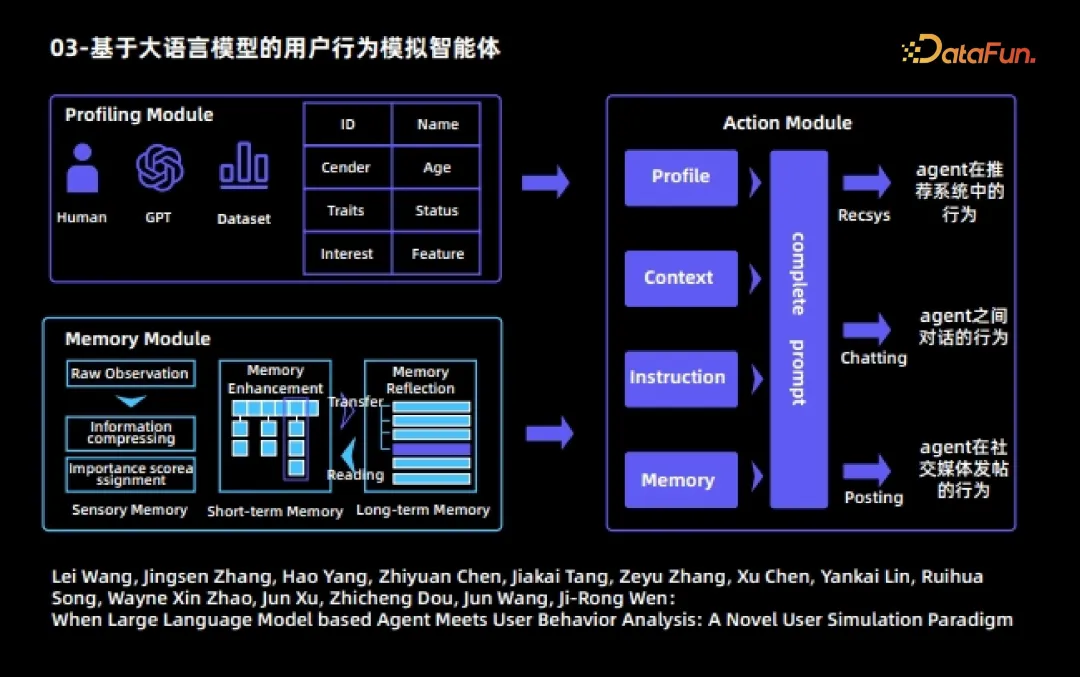
Réaliser objectivement observé observations brutes Après traitement, les observations avec un contenu d'informations plus élevé sont générées et stockées dans la mémoire à court terme
La durée de stockage du contenu de la mémoire à court terme est relativement courte
(3) À long terme ; mémoire
Après des déclenchements et des activations répétés, le contenu de la mémoire à court terme sera automatiquement transféré vers la mémoire à long terme. La durée de stockage du contenu de la mémoire à long terme est relativement longue. Effectuez une réflexion et une sublimation indépendantes. raffinement.
3. Module d'action
- Chaque agent peut effectuer trois actions :
- Le comportement de l'agent dans le système de recommandation, notamment regarder des films, trouver la page suivante et quitter le système de recommandation, etc. . ;
- Comportement de publication de l'agent sur les réseaux sociaux.
- Pendant tout le processus de simulation, un agent peut choisir librement trois actions dans chaque série d'actions sans intervention extérieure. Nous pouvons voir que différents agents se parleront et auront également divers comportements générés de manière autonome dans les médias sociaux ; ou des systèmes de recommandation ; après plusieurs séries de simulations, certains phénomènes sociaux intéressants peuvent être observés, ainsi que les règles de comportement des utilisateurs sur Internet. Pour plus d'informations, veuillez vous référer aux documents suivants :
-
Lei Wang, Jingsen Zhang, Hao Yang, Zhiyuan Chen, Jiakai Tang, Zeyu Zhang, Xu Chen, Yankai Lin, Ruihua Song, Wayne Xin Zhao, Jun Xu, Zhicheng Dou, Jun Wang, Ji-Rong Wen:Quand grand langage L'agent basé sur un modèle rencontre l'analyse du comportement de l'utilisateur : un nouveau paradigme de simulation d'utilisateur
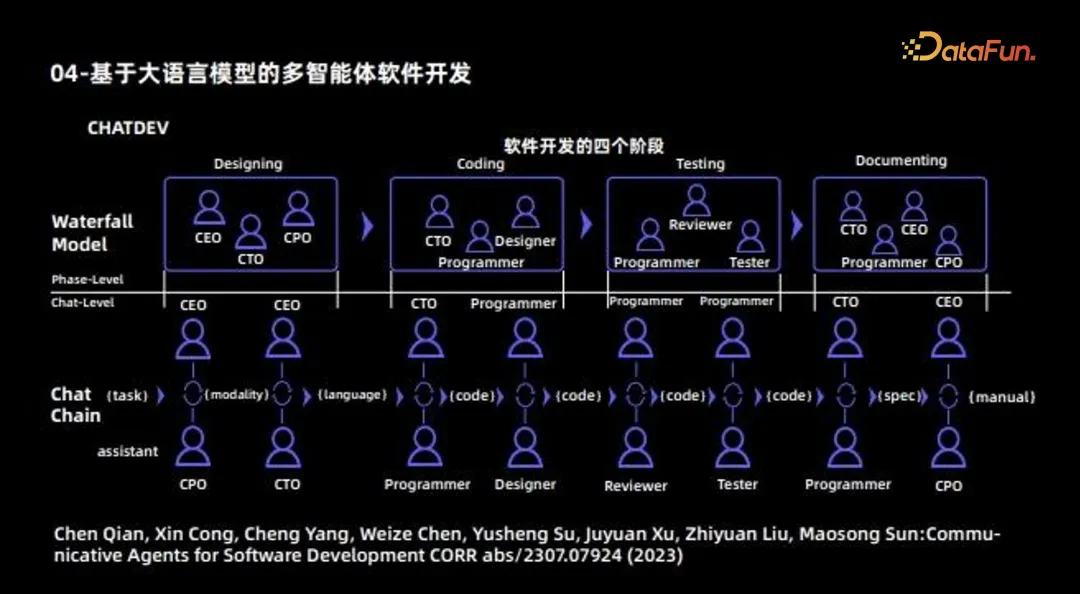
IV. Développement de logiciels multi-agents basé sur un grand modèle de langage

L'exemple suivant d'Agent est d'utiliser plusieurs agents effectuent le développement de logiciels. Ce travail est également un des premiers travaux de coopération multi-agents, et son objectif principal est d'utiliser différents agents pour développer un logiciel complet. Par conséquent, elle peut être considérée comme une entreprise de logiciels, et différents agents joueront différents rôles : certains agents sont responsables de la conception, notamment le PDG, le CTO, le CPO et d'autres rôles sont responsables du codage, et certains agents sont principalement responsables du codage ; des tests seront effectués en plus. Certains agents sont responsables de la rédaction des documents. De cette manière, différents agents sont responsables de différentes tâches ; enfin, le mécanisme de coopération entre les agents est coordonné et mis à jour par la communication, et un processus complet de développement logiciel est enfin achevé.
5. Orientations futures de l'agent basé sur le LLM
Les agents de grands modèles de langage peuvent actuellement être divisés en deux directions principales :
- Résoudre des tâches spécifiques, telles que MetaGPT, ChatDev , Ghost, DESP, etc.
Ce type d'Agent devrait à terme être un « surhomme » aligné sur les bonnes valeurs humaines, avec deux « qualificatifs » :
Aligné sur les bonnes valeurs humaines ;
Au-delà des capacités humaines ordinaires. Simulez le monde réel, comme l'agent génératif, la simulation sociale, le RecAgent, etc. -
Les capacités requises par ce type d'agent sont complètement opposées au premier type.
Permettez aux agents de présenter des valeurs diverses
J'espère que les agents devraient faire de leur mieux pour se conformer aux gens ordinaires au lieu d'aller au-delà des gens ordinaires.
De plus, l'agent actuel de grand modèle de langage présente les deux points faibles suivants :
- Problème d'illusion
-
Étant donné que l'agent doit interagir en permanence avec l'environnement, l'illusion de chaque étape sera accumulée , c'est-à-dire qu'il y aura L'effet cumulatif rend le problème plus grave, par conséquent, l'illusion des grands modèles nécessite une attention particulière ici. Les solutions comprennent :
Concevoir un cadre de collaboration homme-machine efficace ;
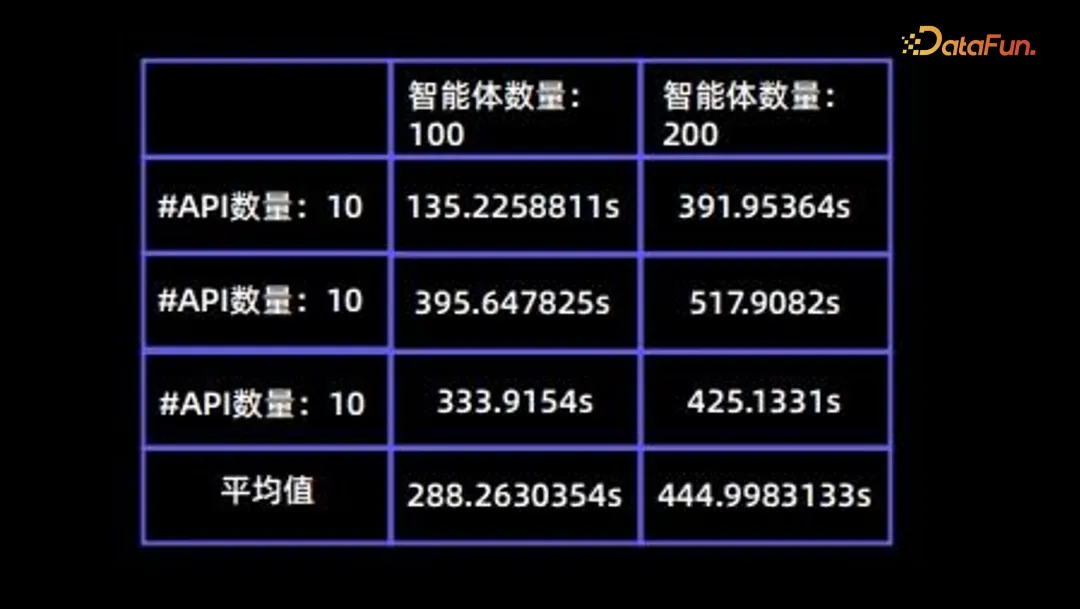
Concevoir un mécanisme d'intervention humaine efficace. Problème d'efficacité -
Dans le processus de simulation, l'efficacité est un problème très important ; le tableau suivant résume le temps nécessaire aux différents agents avec différents numéros d'API.
Ce qui précède est le contenu partagé cette fois, merci à tous.
- Résoudre des tâches spécifiques, telles que MetaGPT, ChatDev , Ghost, DESP, etc.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Traducteur | Bugatti Review | Chonglou Cet article décrit comment utiliser le moteur d'inférence GroqLPU pour générer des réponses ultra-rapides dans JanAI et VSCode. Tout le monde travaille à la création de meilleurs grands modèles de langage (LLM), tels que Groq, qui se concentre sur le côté infrastructure de l'IA. Une réponse rapide de ces grands modèles est essentielle pour garantir que ces grands modèles réagissent plus rapidement. Ce didacticiel présentera le moteur d'analyse GroqLPU et comment y accéder localement sur votre ordinateur portable à l'aide de l'API et de JanAI. Cet article l'intégrera également dans VSCode pour nous aider à générer du code, à refactoriser le code, à saisir la documentation et à générer des unités de test. Cet article créera gratuitement notre propre assistant de programmation d’intelligence artificielle. Introduction au moteur d'inférence GroqLPU Groq
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Déployer de grands modèles de langage localement dans OpenHarmony
Jun 07, 2024 am 10:02 AM
Déployer de grands modèles de langage localement dans OpenHarmony
Jun 07, 2024 am 10:02 AM
Cet article ouvrira en source les résultats du « Déploiement local de grands modèles de langage dans OpenHarmony » démontrés lors de la 2e conférence technologique OpenHarmony. Adresse : https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/. InferLLM/docs/hap_integrate.md. Les idées et les étapes de mise en œuvre consistent à transplanter le cadre d'inférence de modèle LLM léger InferLLM vers le système standard OpenHarmony et à compiler un produit binaire pouvant s'exécuter sur OpenHarmony. InferLLM est un L simple et efficace
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
