
 Périphériques technologiques
IA
CVPR\'24 | LightDiff : Modèle de diffusion dans les scènes de faible luminosité, éclairant directement la nuit !
Périphériques technologiques
IA
CVPR\'24 | LightDiff : Modèle de diffusion dans les scènes de faible luminosité, éclairant directement la nuit !
CVPR\'24 | LightDiff : Modèle de diffusion dans les scènes de faible luminosité, éclairant directement la nuit !

Titre original : Light the Night : A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving
Lien papier : https://arxiv.org/pdf/2404.04804.pdf
Affiliation de l'auteur : Cleveland State University Université du Texas à Austin A*STAR New York University, Université de Californie, Los Angeles

Idée de thèse :
LightDiff est une technologie qui améliore l'efficacité et l'évolutivité du système de perception du centre visuel de la conduite autonome. Les systèmes LiDAR ont récemment reçu une attention considérable. Cependant, ces systèmes rencontrent souvent des difficultés dans des conditions de faible luminosité, ce qui peut affecter leurs performances et leur sécurité. Pour résoudre ce problème, cet article présente LightDiff, un framework automatisé conçu pour améliorer la qualité des images en basse lumière dans les applications de conduite autonome. Plus précisément, cet article adopte un modèle de diffusion contrôlée multi-conditions. LightDiff élimine le besoin de données par paires collectées manuellement et exploite à la place un processus dynamique de dégradation des données. Il intègre un nouvel adaptateur multiconditions capable de contrôler de manière adaptative les poids d'entrée à partir de différentes modalités, notamment les cartes de profondeur, les images RVB et les légendes de texte, afin de maintenir simultanément la cohérence du contenu dans des conditions de faible luminosité et de faible luminosité. De plus, pour faire correspondre les images augmentées avec la connaissance du modèle de détection, LightDiff utilise des scores spécifiques au perceptron comme récompenses pour guider le processus de formation à la diffusion via un apprentissage par renforcement. Des expériences approfondies sur l'ensemble de données nuScenes montrent que LightDiff peut améliorer considérablement les performances de plusieurs détecteurs 3D de pointe dans des conditions nocturnes tout en obtenant des scores de qualité visuelle élevés, soulignant son potentiel pour garantir la sécurité de la conduite autonome.
Principales contributions :
Cet article propose le modèle de diffusion d'éclairage (LightDiff) pour améliorer les images des caméras en basse lumière lors de la conduite autonome, réduisant ainsi le besoin d'une collecte approfondie de données nocturnes et maintenant les capacités de performances diurnes.
Cet article intègre plusieurs modes de saisie, notamment des cartes de profondeur et des légendes d'images, et propose un adaptateur multi-conditions pour garantir l'intégrité sémantique dans la conversion d'images tout en conservant une qualité visuelle élevée. Cet article adopte un processus pratique pour générer des paires d'images de jour et de nuit à partir de données diurnes afin d'obtenir une formation de modèle efficace.
Cet article présente un mécanisme de réglage fin utilisant l'apprentissage par renforcement, combiné à une connaissance du domaine perceptuellement personnalisée (lidar crédible et cohérence des distributions statistiques) pour garantir que le processus de diffusion a une force propice à la perception visuelle humaine et exploite les performances perceptuelles du modèle. modélisation perceptuelle. Cette méthode présente des avantages significatifs dans la perception visuelle humaine et présente également les avantages des modèles perceptuels.
Des expériences approfondies sur l'ensemble de données nuScenes montrent que LightDiff améliore considérablement les performances de détection de véhicules 3D la nuit et surpasse les autres modèles génératifs sur plusieurs mesures d'angle de vue.
Conception Web :
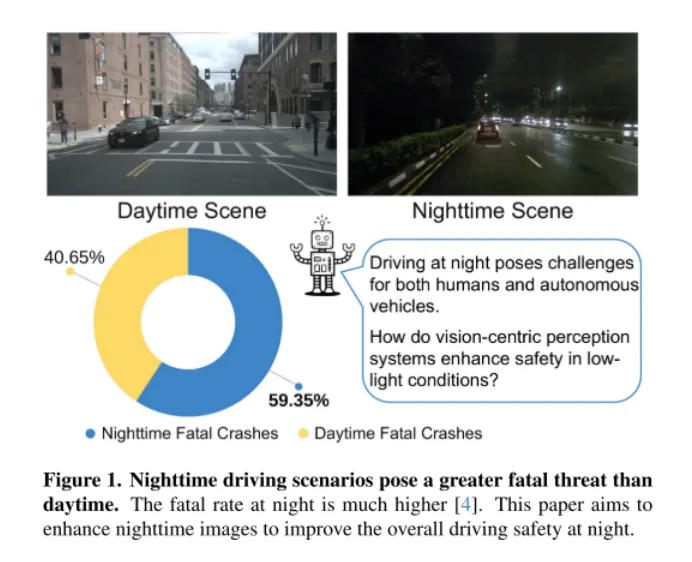
Figure 1. Les scénarios de conduite de nuit sont plus meurtriers que de jour. Le taux de mortalité est beaucoup plus élevé la nuit [4]. Cet article vise à améliorer les images nocturnes pour améliorer la sécurité globale de la conduite nocturne.
Comme le montre la figure 1, la conduite de nuit est un défi pour les humains, en particulier pour les voitures autonomes. Ce défi a été mis en évidence par un incident catastrophique survenu le 18 mars 2018, lorsqu'une voiture autonome du groupe Uber Advanced Technologies a heurté et tué un piéton en Arizona [37]. L'incident, provoqué par l'incapacité du véhicule à détecter avec précision un piéton dans des conditions de faible luminosité, a mis au premier plan les problèmes de sécurité des véhicules autonomes, en particulier dans des environnements aussi exigeants. Alors que les systèmes de conduite autonome axés sur la vision s'appuient de plus en plus sur des capteurs de caméra, il est devenu de plus en plus essentiel de répondre aux problèmes de sécurité dans des conditions de faible luminosité pour garantir la sécurité globale de ces véhicules.
Une solution intuitive consiste à collecter de grandes quantités de données de conduite de nuit. Cependant, cette méthode est non seulement laborieuse et coûteuse, mais peut également nuire aux performances du modèle de jour en raison de la différence de distribution des images entre la nuit et le jour. Pour relever ces défis, cet article propose le modèle Lighting Diffusion (LightDiff), une nouvelle approche qui élimine le besoin de collecte manuelle de données et maintient les performances du modèle de jour.
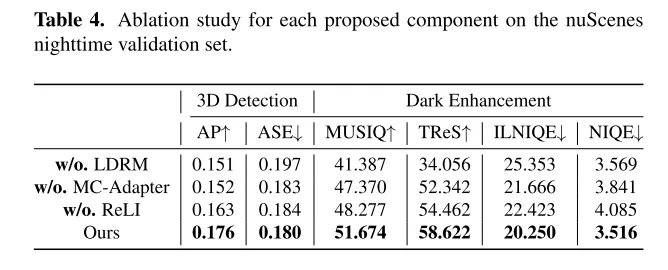
L'objectif deLightDiff est d'améliorer les images des caméras en basse lumière et d'améliorer les performances des modèles perceptuels. En utilisant un processus dynamique d'atténuation de faible luminosité, LightDiff génère des paires d'images synthétiques jour-nuit pour l'entraînement à partir des données diurnes existantes. Ensuite, cet article adopte la technologie Stable Diffusion [44] en raison de sa capacité à produire des effets visuels de haute qualité qui transforment efficacement les scènes nocturnes en équivalents diurnes. Cependant, le maintien de la cohérence sémantique est crucial dans la conduite autonome, ce qui constituait un défi rencontré par le modèle original de diffusion stable. Pour surmonter ce problème, LightDiff combine plusieurs modalités d'entrée, telles que des cartes de profondeur estimées et des légendes d'images de caméra, avec un adaptateur multi-conditions. Cet adaptateur détermine intelligemment le poids de chaque modalité d'entrée, garantissant l'intégrité sémantique de l'image convertie tout en conservant une qualité visuelle élevée. Afin de guider le processus de diffusion non seulement vers une plus grande luminosité pour la vision humaine, mais également pour les modèles de perception, cet article utilise en outre l'apprentissage par renforcement pour affiner le LightDiff de cet article, en ajoutant dans la boucle des connaissances de domaine adaptées à la perception. Cet article mène des expériences approfondies sur l'ensemble de données de conduite autonome nuScenes [7] et démontre que notre LightDiff peut améliorer considérablement la précision moyenne (AP) de la détection nocturne des véhicules 3D pour deux modèles de pointe, BEVDepth [32] et BEVStereo. . [31] amélioré de 4,2% et 4,6%.
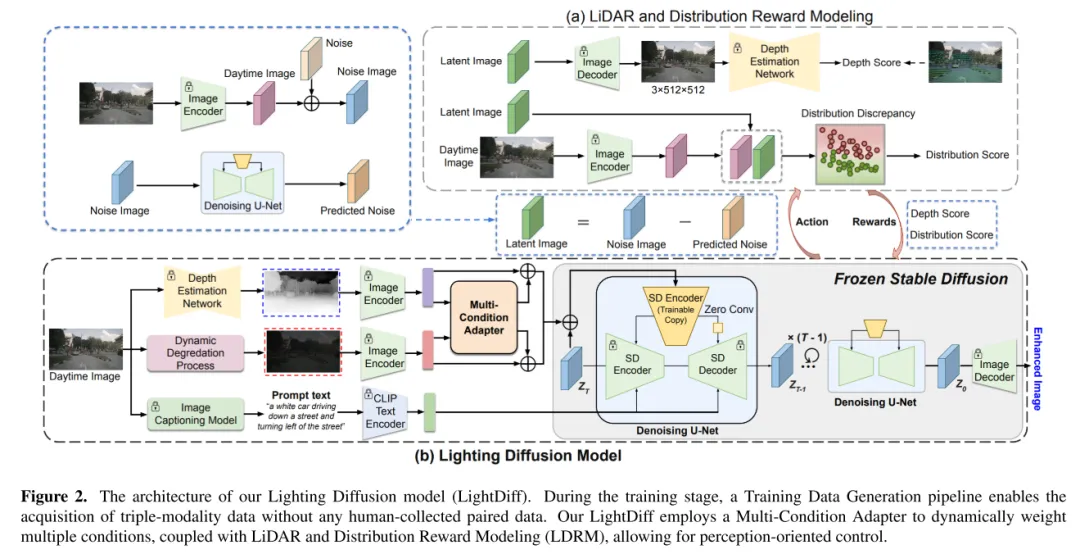
Figure 2. L'architecture du modèle Lighting Diffusion (LightDiff) dans cet article. Pendant la phase de formation, un processus de génération de données de formation permet l'acquisition de données trimodales sans aucune collecte manuelle de données appariées. LightDiff de cet article utilise un adaptateur multi-conditions pour pondérer dynamiquement plusieurs conditions, combiné au lidar et à la modélisation de récompense distribuée (LDRM), permettant un contrôle orienté perception.
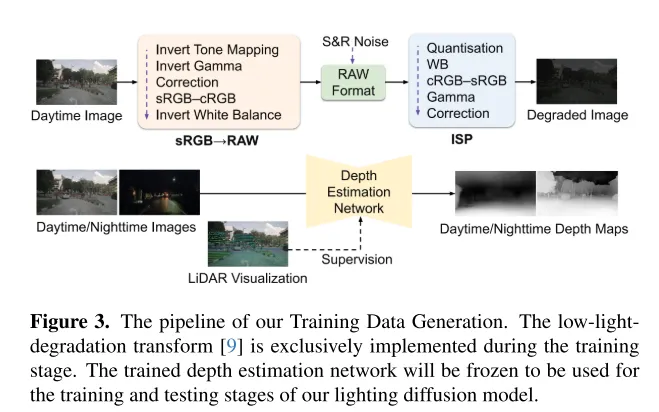
Figure 3. Le processus de génération de données d'entraînement de cet article. La transformation de dégradation par faible luminosité [9] n'est mise en œuvre que pendant la phase d'entraînement. Le réseau d'estimation de profondeur formé sera gelé et utilisé pour les phases de formation et de test du modèle Lighting Diffusion dans cet article.
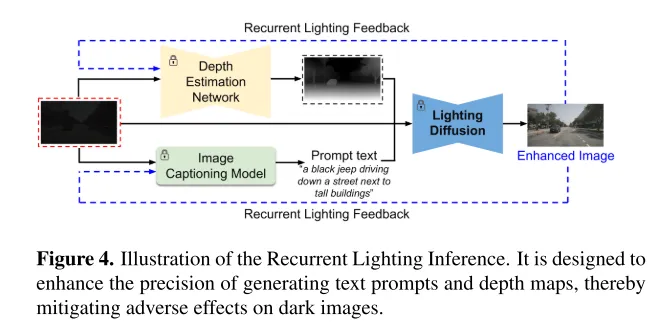
Figure 4. Diagramme schématique de l'inférence d'éclairage récurrent. Il est conçu pour améliorer la précision de la génération d'indices de texte et de cartes de profondeur, atténuant ainsi les effets néfastes des images sombres.
Résultats expérimentaux :

Figure 5. Comparaison visuelle sur un échantillon d'images nocturnes dans l'ensemble de validation nuScenes.

Figure 6. Visualisation des résultats de détection 3D sur un exemple d'image nocturne dans l'ensemble de validation nuScenes. Cet article utilise BEVDepth [32] comme détecteur tridimensionnel et visualise la vue de face et la vue à vol d'oiseau de la caméra.

Figure 7. Montre l'effet visuel du LightDiff de cet article avec ou sans l'adaptateur MultiCondition. L'entrée dans ControlNet [55] reste cohérente, y compris les mêmes indices textuels et cartes de profondeur. Les adaptateurs multi-conditions permettent un meilleur contraste des couleurs et des détails plus riches lors de l'amélioration.
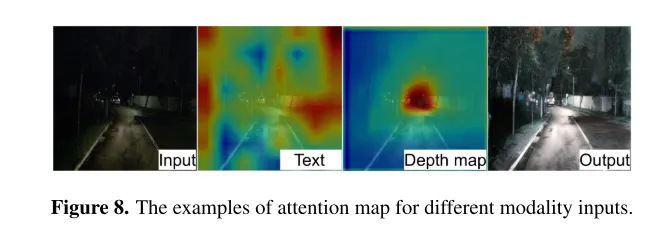
Figure 8. Exemples de cartes d'attention pour différentes entrées modales.

Figure 9. Diagramme schématique de la génération multimodale améliorée grâce à l'inférence d'éclairage récurrente (ReLI). En appelant ReLI une fois, la précision des astuces textuelles et des prédictions des cartes de profondeur est améliorée.
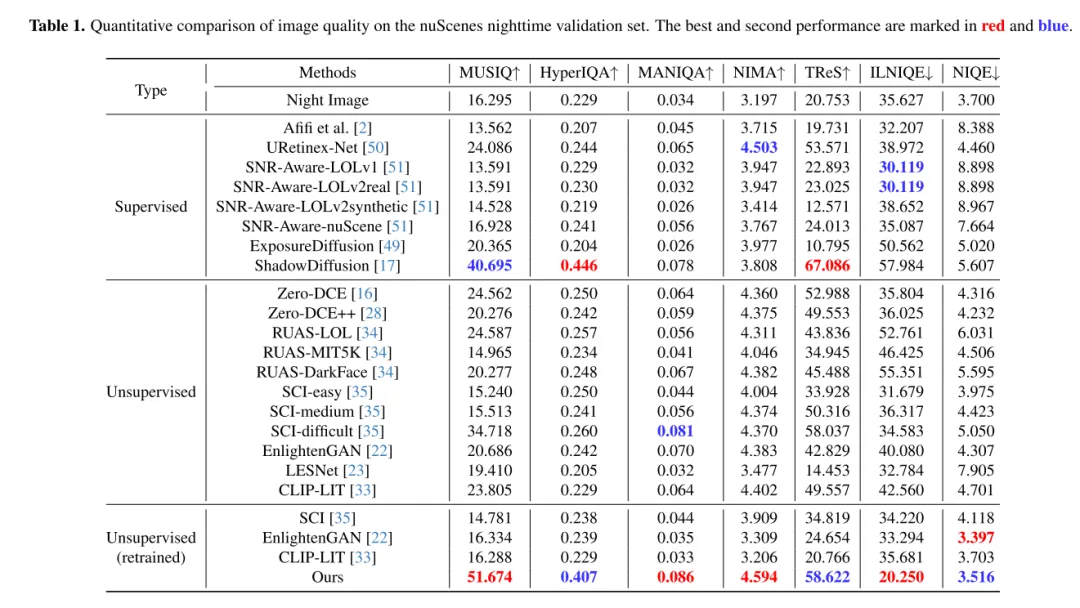
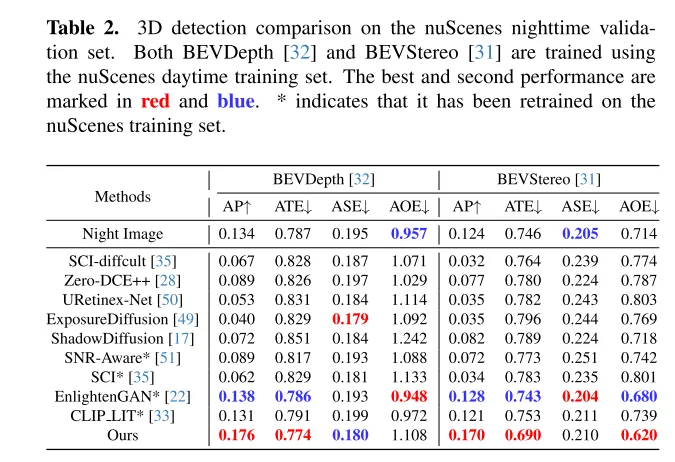
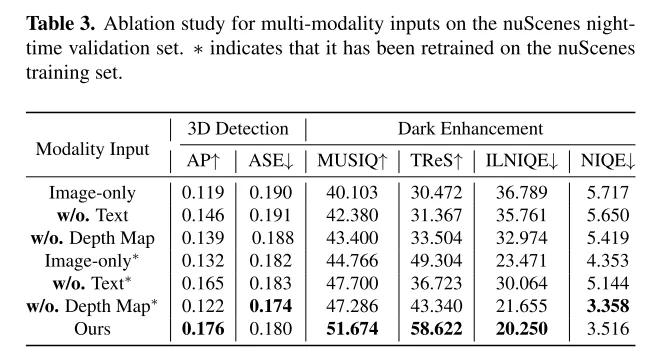
Résumé :
Cet article présente LightDiff, un cadre spécifique à un domaine conçu pour les applications de conduite autonome, visant à améliorer la qualité des images dans des environnements à faible luminosité et à atténuer les défis centrés sur la vision rencontrés par la perception. systèmes. En tirant parti d'un processus dynamique de dégradation des données, d'adaptateurs multi-conditions pour différentes modalités d'entrée et d'une modélisation de récompense guidée par des scores spécifiques à la perception utilisant l'apprentissage par renforcement, LightDiff améliore considérablement la qualité des images nocturnes et les performances 3D sur l'ensemble de données nuScenes. Performances de détection des véhicules. Cette innovation élimine non seulement le besoin de grandes quantités de données nocturnes, mais garantit également l'intégrité sémantique dans la transformation des images, démontrant ainsi son potentiel pour améliorer la sécurité et la fiabilité dans les scénarios de conduite autonome. En l’absence d’images jour-nuit réalistes, il est assez difficile de synthétiser des images de conduite dans des conditions sombres avec les phares des voitures, ce qui limite la recherche dans ce domaine. Les recherches futures pourraient se concentrer sur une meilleure collecte ou génération de données de formation de haute qualité.
Citation :
@ARTICLE{2024arXiv240404804L,
author = {{Li}, Jinlong et {Li}, Baolu et {Tu}, Zhengzhong et {Liu}, Xinyu et {Guo}, Qing et {Juefei- Xu}, Felix et {Xu}, Runsheng et {Yu}, Hongkai},
title = "{Éclairez la nuit : un cadre de diffusion multi-conditions pour une amélioration non appariée des faibles luminosités dans la conduite autonome}",
journal = {arXiv e-prints},
mots-clés = {Informatique - Vision par ordinateur et reconnaissance de formes},
année = 2024,
mois = avril,
eid = {arXiv:2404.04804},
pages = {arXiv:2404.04804},
doi = {10.48550/arXiv.2404.04804},
archivePrefix = {arXiv},
eprint = {2404.04804},
primaryClass = {cs.CV},
adsurl = {https://ui.adsabs.harvard.edu/abs/2024arXiv240404804L },
adsnote = {Fourni par le système de données astrophysiques SAO/NASA}
}
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Vers la « boucle fermée » | PlanAgent : nouveau SOTA pour la planification en boucle fermée de la conduite autonome basée sur MLLM !
Jun 08, 2024 pm 09:30 PM
Vers la « boucle fermée » | PlanAgent : nouveau SOTA pour la planification en boucle fermée de la conduite autonome basée sur MLLM !
Jun 08, 2024 pm 09:30 PM
L'équipe d'apprentissage par renforcement profond de l'Institut d'automatisation de l'Académie chinoise des sciences, en collaboration avec Li Auto et d'autres, a proposé un nouveau cadre de planification en boucle fermée pour la conduite autonome basé sur le modèle multimodal à grand langage MLLM - PlanAgent. Cette méthode prend une vue d'ensemble de la scène et des invites de texte basées sur des graphiques comme entrée, et utilise la compréhension multimodale et les capacités de raisonnement de bon sens du grand modèle de langage multimodal pour effectuer un raisonnement hiérarchique depuis la compréhension de la scène jusqu'à la génération. d'instructions de mouvement horizontal et vertical, et générer en outre les instructions requises par le planificateur. La méthode est testée sur le benchmark nuPlan à grande échelle et exigeant, et les expériences montrent que PlanAgent atteint des performances de pointe (SOTA) dans les scénarios réguliers et à longue traîne. Par rapport aux méthodes conventionnelles de grand modèle de langage (LLM), PlanAgent
 Comment évaluer la rentabilité du support commercial des frameworks Java
Jun 05, 2024 pm 05:25 PM
Comment évaluer la rentabilité du support commercial des frameworks Java
Jun 05, 2024 pm 05:25 PM
L'évaluation du rapport coût/performance du support commercial pour un framework Java implique les étapes suivantes : Déterminer le niveau d'assurance requis et les garanties de l'accord de niveau de service (SLA). L’expérience et l’expertise de l’équipe d’appui à la recherche. Envisagez des services supplémentaires tels que les mises à niveau, le dépannage et l'optimisation des performances. Évaluez les coûts de support commercial par rapport à l’atténuation des risques et à une efficacité accrue.
 Revoir! Résumer de manière exhaustive le rôle important des modèles de base dans la promotion de la conduite autonome
Jun 11, 2024 pm 05:29 PM
Revoir! Résumer de manière exhaustive le rôle important des modèles de base dans la promotion de la conduite autonome
Jun 11, 2024 pm 05:29 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : Récemment, avec le développement et les percées de la technologie d'apprentissage profond, les modèles de base à grande échelle (Foundation Models) ont obtenu des résultats significatifs dans les domaines du traitement du langage naturel et de la vision par ordinateur. L’application de modèles de base à la conduite autonome présente également de grandes perspectives de développement, susceptibles d’améliorer la compréhension et le raisonnement des scénarios. Grâce à une pré-formation sur un langage riche et des données visuelles, le modèle de base peut comprendre et interpréter divers éléments des scénarios de conduite autonome et effectuer un raisonnement, fournissant ainsi un langage et des commandes d'action pour piloter la prise de décision et la planification. Le modèle de base peut être constitué de données enrichies d'une compréhension du scénario de conduite afin de fournir les rares caractéristiques réalisables dans les distributions à longue traîne qui sont peu susceptibles d'être rencontrées lors d'une conduite de routine et d'une collecte de données.
 Comment la courbe d'apprentissage des frameworks PHP se compare-t-elle à celle d'autres frameworks de langage ?
Jun 06, 2024 pm 12:41 PM
Comment la courbe d'apprentissage des frameworks PHP se compare-t-elle à celle d'autres frameworks de langage ?
Jun 06, 2024 pm 12:41 PM
La courbe d'apprentissage d'un framework PHP dépend de la maîtrise du langage, de la complexité du framework, de la qualité de la documentation et du support de la communauté. La courbe d'apprentissage des frameworks PHP est plus élevée par rapport aux frameworks Python et inférieure par rapport aux frameworks Ruby. Par rapport aux frameworks Java, les frameworks PHP ont une courbe d'apprentissage modérée mais un temps de démarrage plus court.
 Comment les options légères des frameworks PHP affectent-elles les performances des applications ?
Jun 06, 2024 am 10:53 AM
Comment les options légères des frameworks PHP affectent-elles les performances des applications ?
Jun 06, 2024 am 10:53 AM
Le framework PHP léger améliore les performances des applications grâce à une petite taille et une faible consommation de ressources. Ses fonctionnalités incluent : une petite taille, un démarrage rapide, une faible utilisation de la mémoire, une vitesse de réponse et un débit améliorés et une consommation de ressources réduite. Cas pratique : SlimFramework crée une API REST, seulement 500 Ko, une réactivité élevée et un débit élevé.
 Bonnes pratiques en matière de documentation du framework Golang
Jun 04, 2024 pm 05:00 PM
Bonnes pratiques en matière de documentation du framework Golang
Jun 04, 2024 pm 05:00 PM
La rédaction d'une documentation claire et complète est cruciale pour le framework Golang. Les meilleures pratiques incluent le respect d'un style de documentation établi, tel que le Go Coding Style Guide de Google. Utilisez une structure organisationnelle claire, comprenant des titres, des sous-titres et des listes, et fournissez la navigation. Fournit des informations complètes et précises, notamment des guides de démarrage, des références API et des concepts. Utilisez des exemples de code pour illustrer les concepts et l'utilisation. Maintenez la documentation à jour, suivez les modifications et documentez les nouvelles fonctionnalités. Fournir une assistance et des ressources communautaires telles que des problèmes et des forums GitHub. Créez des exemples pratiques, tels que la documentation API.
 Comment choisir le meilleur framework Golang pour différents scénarios d'application
Jun 05, 2024 pm 04:05 PM
Comment choisir le meilleur framework Golang pour différents scénarios d'application
Jun 05, 2024 pm 04:05 PM
Choisissez le meilleur framework Go en fonction des scénarios d'application : tenez compte du type d'application, des fonctionnalités du langage, des exigences de performances et de l'écosystème. Frameworks Go courants : Gin (application Web), Echo (service Web), Fibre (haut débit), gorm (ORM), fasthttp (vitesse). Cas pratique : construction de l'API REST (Fiber) et interaction avec la base de données (gorm). Choisissez un framework : choisissez fasthttp pour les performances clés, Gin/Echo pour les applications Web flexibles et gorm pour l'interaction avec la base de données.
 Explication pratique détaillée du développement du framework Golang : questions et réponses
Jun 06, 2024 am 10:57 AM
Explication pratique détaillée du développement du framework Golang : questions et réponses
Jun 06, 2024 am 10:57 AM
Dans le développement du framework Go, les défis courants et leurs solutions sont les suivants : Gestion des erreurs : utilisez le package d'erreurs pour la gestion et utilisez un middleware pour gérer les erreurs de manière centralisée. Authentification et autorisation : intégrez des bibliothèques tierces et créez un middleware personnalisé pour vérifier les informations d'identification. Traitement simultané : utilisez des goroutines, des mutex et des canaux pour contrôler l'accès aux ressources. Tests unitaires : utilisez les packages, les simulations et les stubs gotest pour l'isolation, ainsi que les outils de couverture de code pour garantir la suffisance. Déploiement et surveillance : utilisez les conteneurs Docker pour regrouper les déploiements, configurer les sauvegardes de données et suivre les performances et les erreurs avec des outils de journalisation et de surveillance.
