


La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com.
Des GPT-4 128K et Claude 200K de premier ordre international au Kimi Chat national "Red Fried Chicken" qui prend en charge plus de 2 millions de mots de texte, les grands modèles de langage (LLM) se sont invariablement déroulés dans un contexte long. technologie. Lorsque les esprits les plus intelligents du monde travaillent sur quelque chose, l’importance et la difficulté du sujet sautent aux yeux.
Des contextes extrêmement longs peuvent augmenter considérablement la valeur de productivité des grands modèles. Avec la popularité de l'IA, les utilisateurs ne se contentent plus de jouer avec de grands modèles et de faire quelques casse-tête. Les utilisateurs commencent à souhaiter utiliser de grands modèles pour réellement améliorer leur productivité. Après tout, le PPT qui prenait auparavant une semaine à créer peut désormais être généré en quelques minutes en fournissant simplement au grand modèle une chaîne de mots d'invite et quelques documents de référence. Qui ne l'aimerait pas en tant que travailleur ?
Certaines nouvelles méthodes efficaces de modélisation de séquences ont récemment émergé, telles que Lightning Attention (TransNormerLLM), State Space Modeling (Mamba), Linear RNN (RWKV, HGRN, Griffin), etc., qui sont devenues une direction de recherche brûlante. Les chercheurs sont impatients de transformer l'architecture Transformer, déjà mature, vieille de 7 ans, pour obtenir une nouvelle architecture offrant des performances comparables mais une complexité linéaire seulement. Ce type d'approche se concentre sur la conception de l'architecture du modèle et fournit une implémentation matérielle basée sur CUDA ou Triton, lui permettant d'être calculé efficacement dans un GPU à carte unique comme FlashAttention.
Dans le même temps, un autre contrôleur d'entraînement en séquences longues a également adopté une stratégie différente : le parallélisme des séquences retient de plus en plus l'attention. En divisant la séquence longue en de multiples séquences courtes également divisées dans la dimension de séquence, et en dispersant les séquences courtes sur différentes cartes GPU pour un entraînement parallèle, et en les complétant par une communication inter-cartes, l'effet d'un entraînement parallèle de séquence est obtenu. Du premier parallélisme de séquence Colossal-AI au parallélisme de séquence Megatron, en passant par DeepSpeed Ulysses et plus récemment, Ring Attention, les chercheurs ont continué à concevoir des mécanismes de communication plus élégants et plus efficaces pour améliorer l'efficacité de la formation au parallélisme de séquence. Bien entendu, ces méthodes connues sont toutes conçues pour les mécanismes d’attention traditionnels, que nous appelons Softmax Attention dans cet article. Ces méthodes ont déjà été analysées par divers experts, cet article ne les abordera donc pas en détail.

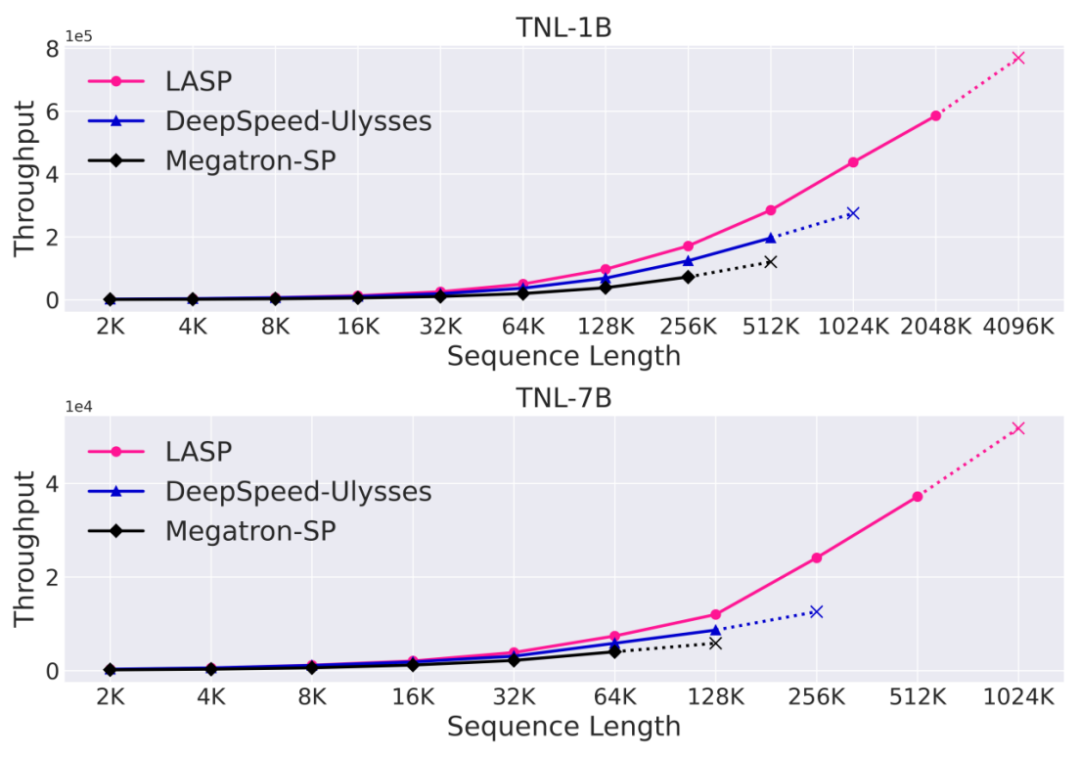
Le LASP qui sera présenté dans cet article a vu le jour. Des chercheurs du laboratoire d'intelligence artificielle de Shanghai ont proposé la méthode LASP (Linear Attention Sequence Parallelism) pour utiliser pleinement la propriété de multiplication linéaire à droite de l'attention linéaire afin d'obtenir un calcul parallèle de séquence efficace. Sous la configuration d'un GPU A100 80G à 128 cartes, du modèle TransNormerLLM 1B et du backend FSDP, LASP peut étendre la longueur de la séquence jusqu'à 4 096 Ko, soit 4 Mo. Par rapport aux méthodes parallèles de séquence matures, la longueur de séquence entraînable la plus longue de LASP est 8 fois celle de Megatron-SP et 4 fois celle de DeepSpeed Ulysses, et la vitesse est respectivement 136 % et 38 % plus rapide.
Il convient de noter que le nom de la méthode de traitement du langage naturel inclut l'attention linéaire, mais elle ne se limite pas à la méthode de l'attention linéaire, mais peut être largement utilisée, notamment Lightning Attention (TransNormerLLM), State Space Modeling (Mamba), RNN linéaire (RWKV, HGRN, Griffin) et autres méthodes de modélisation de séquences linéaires.
Introduction à la méthode LASP
Afin de mieux comprendre l'idée de LASP, passons d'abord en revue la formule de calcul traditionnelle de Softmax Attention : O=softmax((QK^T)⊙M)V, où Q, K, V, M et O sont des matrices de requête, de clé, de valeur, de masque et de sortie, M est ici une matrice triangulaire inférieure tout-1 dans les tâches unidirectionnelles (telles que GPT), et peut être ignorée dans les tâches bidirectionnelles (telles que BERT), c'est-à-dire , il n'y a pas de matrice de masque pour les tâches bidirectionnelles. Nous diviserons le LASP en quatre points pour l'explication ci-dessous :
Principe de l'attention linéaire
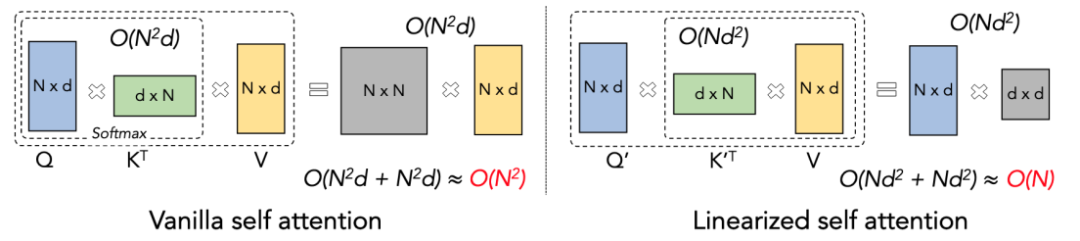
L'attention linéaire peut être considérée comme une variante de l'attention Softmax. L'attention linéaire supprime l'opérateur Softmax coûteux en calcul, et la formule de calcul de l'attention peut être écrite sous la forme concise de O=((QK^T)⊙M) V. Cependant, en raison de l'existence de la matrice de masque M dans la tâche unidirectionnelle, ce formulaire ne peut toujours effectuer qu'un calcul de multiplication à gauche (c'est-à-dire calculer d'abord QK^T), de sorte que la complexité linéaire de O (N) ne peut pas être obtenue. . Mais pour les tâches bidirectionnelles, puisqu'il n'y a pas de matrice de masque, la formule de calcul peut être encore simplifiée à O=(QK^T) V. La chose intelligente à propos de l'attention linéaire est qu'en utilisant simplement la loi associative de multiplication matricielle, sa formule de calcul peut être transformée en : O=Q (K^T V). Cette forme de calcul est appelée multiplication droite. L'attention est tentante. La complexité O (N) peut être obtenue dans cette tâche bidirectionnelle !
Distribution de données LASP
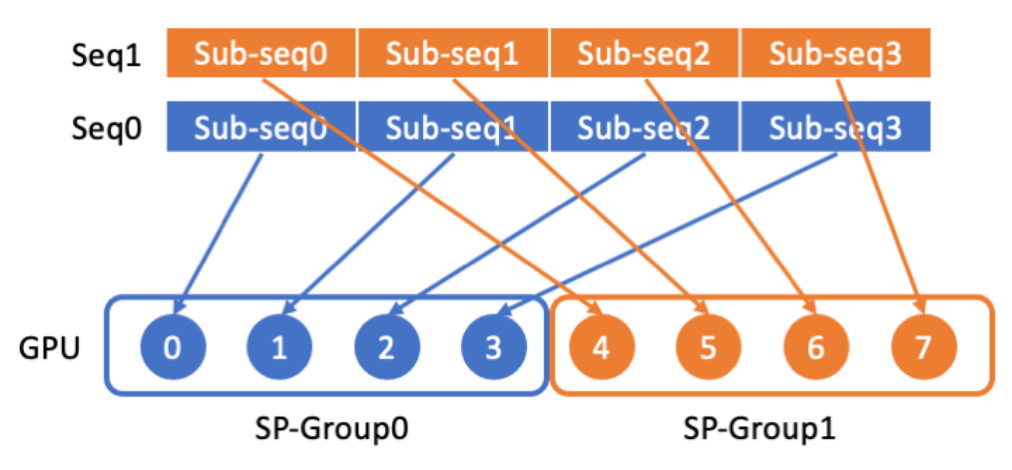
LASP divise d'abord les données de séquence longue en plusieurs sous-séquences également divisées à partir de la dimension de séquence, puis distribue les sous-séquences à tous les GPU du groupe de communication parallèle de séquence, de sorte que chaque GPU ait une sous-séquence pour le calcul parallèle des séquences suivantes.
Mécanisme de base LASP
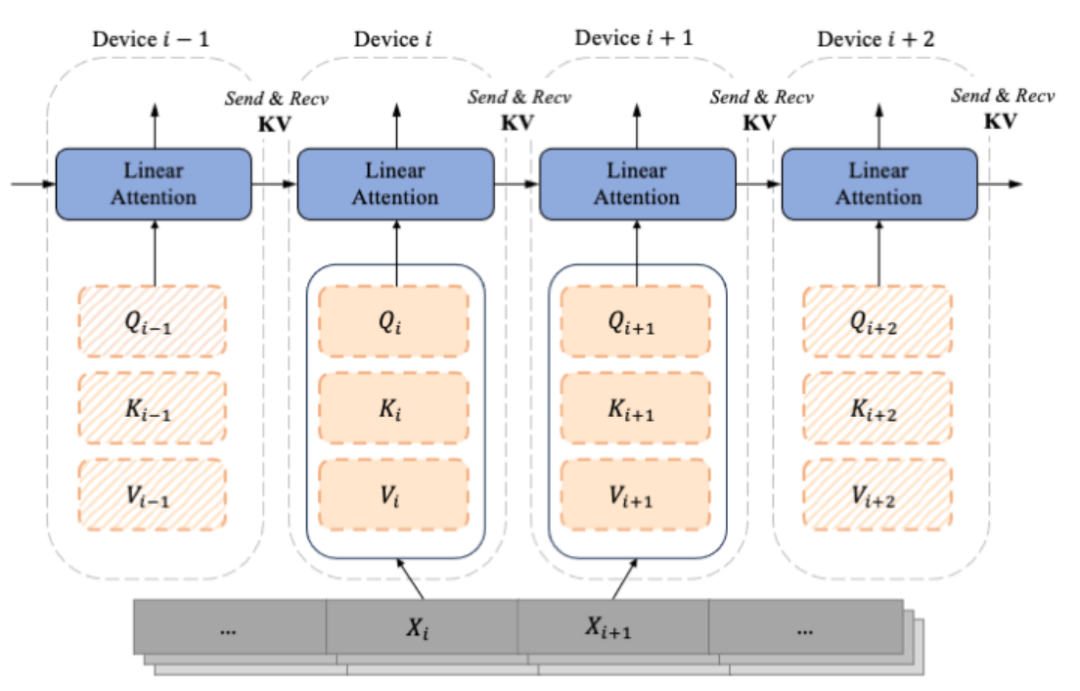
Alors que les modèles de type GPT avec décodeur uniquement deviennent progressivement la norme de facto pour LLM, LASP est conçu en tenant pleinement compte du scénario de tâche occasionnelle à sens unique. Calculés à partir de la sous-séquence segmentée Xi, Qi, Ki et Vi sont segmentés en fonction des dimensions de la séquence. Chaque index i correspond à un morceau et à un périphérique (c'est-à-dire un GPU). En raison de l’existence de la matrice Mask, l’auteur du LASP distingue astucieusement le Qi, le Ki et le Vi correspondant à chaque Chunk en deux types, à savoir : Intra-Chunk et Inter-Chunk. Parmi eux, Intra-Chunk est le Chunk sur la diagonale après que la matrice Mask soit divisée en blocs. On peut considérer que la matrice Mask existe toujours et que la multiplication à gauche doit toujours être utilisée. la ligne hors diagonale de la matrice Masque, qui peut être considérée comme non. Avec l'existence de la matrice Masque, la multiplication droite peut être utilisée évidemment, lorsque plus de Chunks sont divisés, la proportion de Chunks sur la diagonale sera plus petite, et la proportion de morceaux sur la diagonale sera plus grande. La multiplication correcte peut être utilisée pour obtenir une complexité linéaire, plus l'attention calcule. Parmi eux, pour le calcul de l'Inter-Chunk multiplié à droite, lors du calcul direct, chaque appareil doit utiliser une communication point à point pour recevoir le KV de l'appareil précédent et envoyer son propre KV mis à jour à l'appareil suivant. Lors d'un calcul inverse, c'est tout le contraire, sauf que les objets de Send et Recive deviennent le gradient dKV de KV. Le processus de calcul avancé est illustré dans la figure ci-dessous :
Implémentation du code LASP
Afin d'améliorer l'efficacité de calcul de LASP sur le GPU, l'auteur a effectué Kernel Fusion sur les calculs d'Intra-Chunk et Inter -Chunk respectivement, et Les calculs de mise à jour de KV et dKV sont également intégrés aux calculs Intra-Chunk et Inter-Chunk. De plus, afin d'éviter de recalculer le KV d'activation lors de la rétro-propagation, les auteurs ont choisi de le stocker dans le HBM du GPU immédiatement après le calcul de la propagation vers l'avant. Lors de la rétropropagation ultérieure, LASP accède directement au KV pour l'utiliser. Il convient de noter que la taille KV stockée dans HBM est d x d et n'est absolument pas affectée par la longueur de séquence N. Lorsque la longueur de séquence d'entrée N est grande, l'empreinte mémoire de KV devient insignifiante. À l'intérieur d'un seul GPU, l'auteur a implémenté Lightning Attention implémenté par Triton pour réduire la surcharge d'E/S entre HBM et SRAM, accélérant ainsi les calculs d'attention linéaire sur une seule carte.
Les lecteurs qui souhaitent en savoir plus peuvent lire l'algorithme 2 (processus direct LASP) et l'algorithme 3 (processus inverse LASP) dans l'article, ainsi que le processus de dérivation détaillé dans l'article.
Analyse du trafic
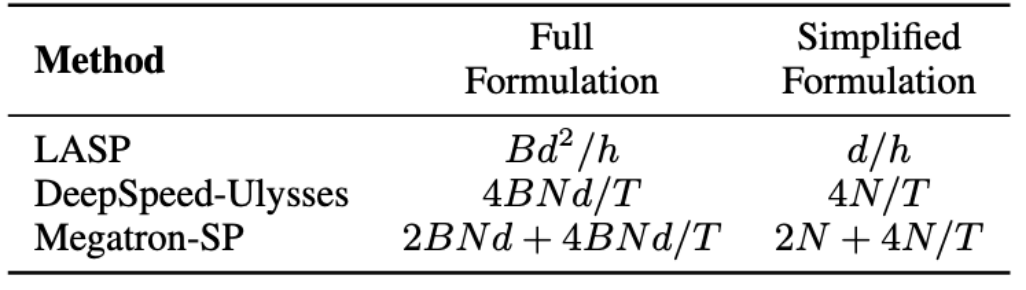
Dans l'algorithme LASP, il convient de noter que la propagation vers l'avant nécessite une communication d'activation KV au niveau de chaque couche du module d'attention linéaire. Le trafic est de Bd^2/h, où B est la taille du lot et h le nombre de têtes. En revanche, Megatron-SP utilise une opération All-Gather après les deux couches Layer Norm dans chaque couche Transformer, et une opération Reduction-Scatter après les couches Attention et FFN, ce qui provoque sa communication. La quantité est 2BNd + 4BNd/T, où T est la dimension parallèle de la séquence. DeepSpeed-Ulysses utilise une opération de communication définie All-to-All pour traiter les entrées Q, K, V et la sortie O de chaque couche du module Attention, ce qui donne un volume de communication de 4BNd/T. La comparaison du volume de communication entre les trois est présentée dans le tableau ci-dessous. où d/h est la dimension de la tête, généralement définie sur 128. Dans les applications pratiques, LASP peut atteindre le volume de communication théorique le plus bas lorsque N/T>=32. De plus, le volume de communication de LASP n'est pas affecté par la longueur de séquence N ou la longueur de sous-séquence C, ce qui constitue un énorme avantage pour le calcul parallèle de séquences extrêmement longues sur de grands clusters GPU.
Data-Sequence Hybrid Parallel
Le parallélisme des données (c'est-à-dire la segmentation des données au niveau des lots) est une opération de routine pour la formation distribuée. Il a évolué sur la base du parallélisme des données d'origine (PyTorch DDP). obtenir un parallélisme de données de tranche plus économe en mémoire, de la série originale DeepSpeed ZeRO au FSDP officiellement pris en charge par PyTorch, le parallélisme de données de tranche est devenu suffisamment mature et est utilisé par de plus en plus d'utilisateurs. En tant que méthode de segmentation de données au niveau séquence, LASP est compatible avec diverses méthodes parallèles de données, notamment PyTorch DDP, Zero-1/2/3 et FSDP. C’est sans aucun doute une bonne nouvelle pour les utilisateurs de LASP.
Expérience de précision
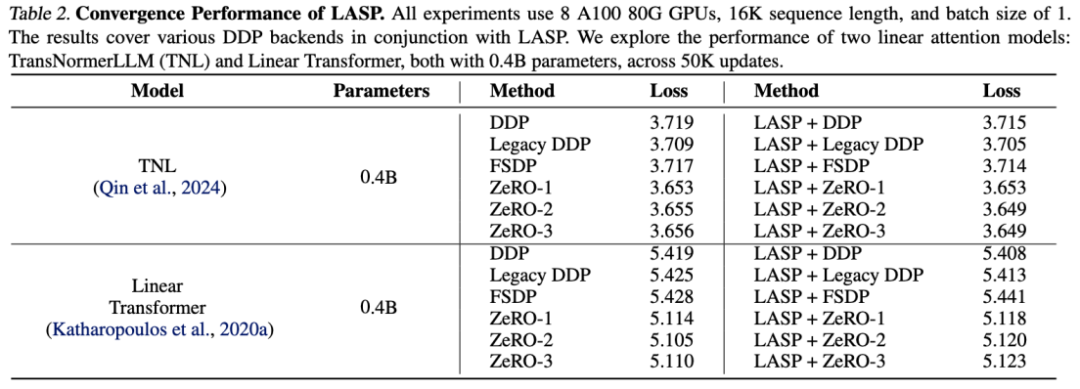
Les résultats expérimentaux sur TransNormerLLM (TNL) et Linear Transformer montrent que LASP, en tant que méthode d'optimisation du système, peut être combiné avec divers backends DDP et atteindre des performances comparables à celles de Baseline.
Expérience d'évolutivité
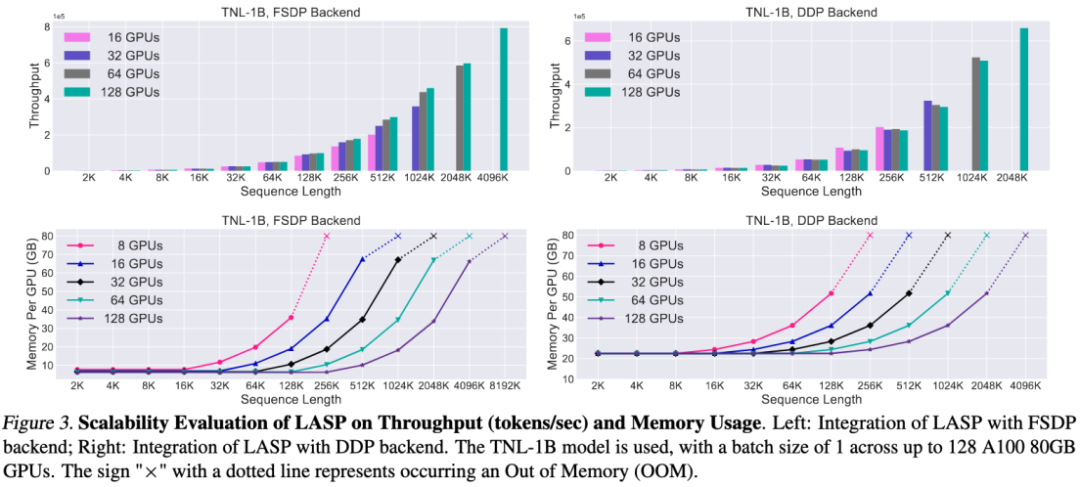
Grâce à la conception efficace du mécanisme de communication, LASP peut être facilement étendu à des centaines de cartes GPU et maintient une bonne évolutivité.
Expérience de comparaison de vitesse
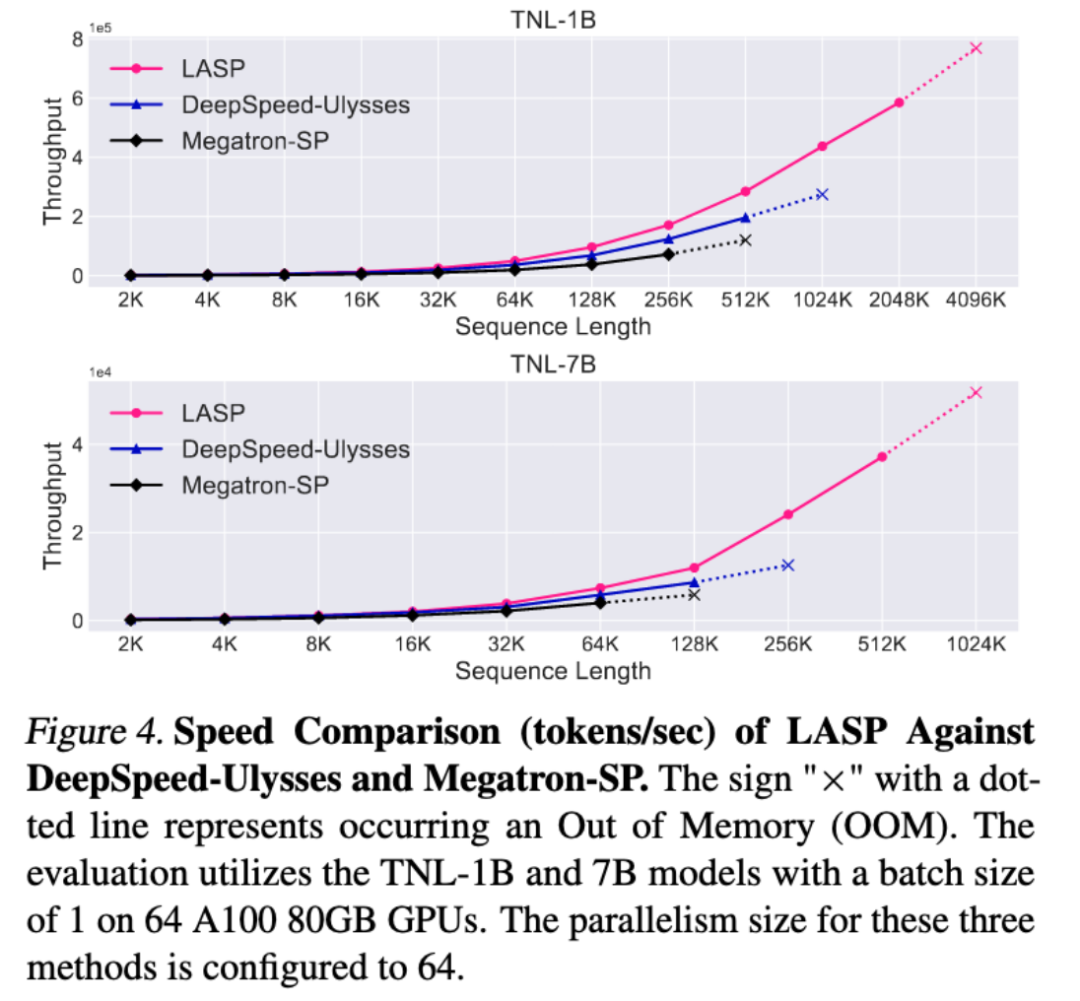
Par rapport aux méthodes parallèles de séquence matures Megatron-SP et DeepSpeed-Ulysses, la longueur de séquence entraînable la plus longue de LASP est 8 fois celle de Megatron-SP et 4 fois celle de DeepSpeed- Ulysse La vitesse est respectivement 136% et 38% plus rapide.
Conclusion
Pour faciliter l'essai de chacun, l'auteur a fourni une implémentation de code LASP prête à l'emploi. Il n'est pas nécessaire de télécharger des ensembles de données et des modèles. Vous avez seulement besoin de PyTorch pour expérimenter le LASP extrêmement long et. parallélisme de séquence extrêmement rapide en quelques minutes.
Portail de codes : https://github.com/OpenNLPLab/LASP
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Construisez votre propre serveur git
Construisez votre propre serveur git
 La différence entre git et svn
La différence entre git et svn
 git annuler le commit soumis
git annuler le commit soumis
 Comment annuler l'erreur de commit git
Comment annuler l'erreur de commit git
 Comment comparer le contenu des fichiers de deux versions dans git
Comment comparer le contenu des fichiers de deux versions dans git
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 Erreur interne du serveur
Erreur interne du serveur
 Utilisation de la fonction accepter
Utilisation de la fonction accepter








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



