
 Périphériques technologiques
IA
Google se mobilise pour remédier à « l'amnésie » des grands modèles ! Le mécanisme d'attention et de feedback vous aide à « mettre à jour » le contexte, et l'ère de la mémoire illimitée pour les grands modèles arrive.
Périphériques technologiques
IA
Google se mobilise pour remédier à « l'amnésie » des grands modèles ! Le mécanisme d'attention et de feedback vous aide à « mettre à jour » le contexte, et l'ère de la mémoire illimitée pour les grands modèles arrive.
Google se mobilise pour remédier à « l'amnésie » des grands modèles ! Le mécanisme d'attention et de feedback vous aide à « mettre à jour » le contexte, et l'ère de la mémoire illimitée pour les grands modèles arrive.

Éditeur | Yi Feng
Produit par 51CTO Technology Stack (WeChat ID : blog51cto)
Google passe enfin à l'action ! Nous ne souffrirons plus de « l’amnésie » des grands modèles.
TransformerFAM est né, promettant de donner aux grands modèles une mémoire illimitée !
Sans plus tard, jetons un coup d'œil à « l'efficacité » de TransformerFAM :
 Photos
Photos
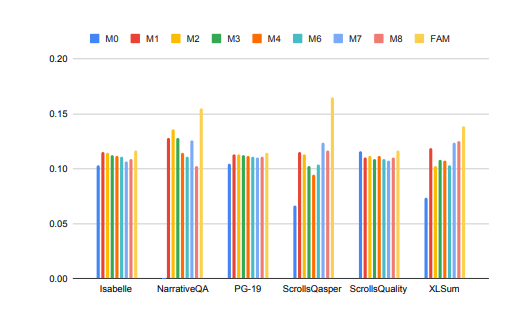
Les performances des grands modèles dans le traitement des tâches à contexte long ont été considérablement améliorées !
Dans l'image ci-dessus, des tâches telles que Isabelle et NarrativeQA nécessitent que le modèle comprenne et traite une grande quantité d'informations contextuelles et donne des réponses ou des résumés précis à des questions spécifiques. Dans toutes les tâches, le modèle configuré avec FAM surpasse toutes les autres configurations BSWA, et on constate qu'au-delà d'un certain point, l'augmentation du nombre de segments de mémoire BSWA ne peut pas continuer à améliorer ses capacités de mémoire.
Il paraît que sur la route des longs textes et des longues conversations, l'"inoubliable" de FAM, grand mannequin, a quelque chose à dire.
Les chercheurs de Google ont présenté FAM, une nouvelle architecture Transformer - Feedback Attention Memory. Il utilise des boucles de rétroaction pour permettre au réseau de prêter attention à ses propres performances de dérive, favoriser l'émergence de la mémoire de travail interne du Transformer et lui permettre de gérer des séquences infiniment longues.
Pour faire simple, cette stratégie est un peu comme notre stratégie pour combattre artificiellement « l'amnésie » des grands modèles : saisir à nouveau l'invite avant chaque conversation avec le grand modèle. C'est juste que l'approche de FAM est plus avancée. Lorsque le modèle traite un nouveau bloc de données, il utilise les informations précédemment traitées (c'est-à-dire FAM) comme contexte mis à jour dynamiquement et les intègre à nouveau dans le processus de traitement en cours.
De cette façon, vous pouvez bien résoudre le problème de « l'oubli des choses ». Mieux encore, malgré l'introduction de mécanismes de rétroaction pour maintenir la mémoire de travail à long terme, FAM est conçu pour maintenir la compatibilité avec les modèles pré-entraînés sans nécessiter de poids supplémentaires. Ainsi, en théorie, la mémoire puissante d’un grand modèle ne le rend pas ennuyeux et ne consomme pas plus de ressources informatiques.
Alors, comment un si merveilleux TransformerFAM a-t-il été découvert ? Quelles sont les technologies associées ?
1. Du défi, pourquoi TransformerFAM peut-il aider les grands modèles à « se souvenir davantage » ?
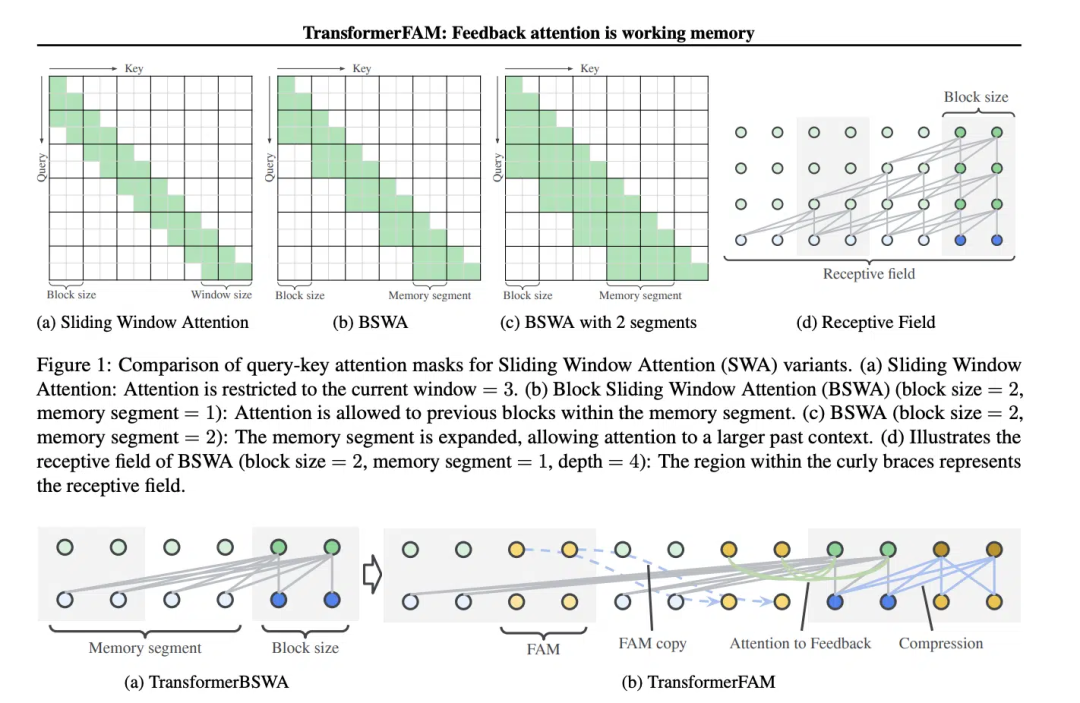
Le concept de Sliding Window Attention (SWA) est crucial dans la conception de TransformerFAM.
Dans le modèle Transformer traditionnel, la complexité de l'attention personnelle augmente quadratiquement à mesure que la longueur de la séquence augmente, ce qui limite la capacité du modèle à gérer de longues séquences.
« Dans le film Memento (2000), le personnage principal souffre d'amnésie antérograde, ce qui signifie qu'il ne peut pas se souvenir de ce qui s'est passé au cours des 10 dernières minutes, mais sa mémoire à long terme est intacte et il doit tatouer des informations importantes sur son corps. les mémoriser est similaire à l'état actuel des grands modèles de langage (LLM)", lit-on dans le journal.
 Captures d'écran du film "Memento", les images proviennent d'Internet
Captures d'écran du film "Memento", les images proviennent d'Internet
Sliding Window Attention (Sliding Window Attention), c'est un mécanisme d'attention amélioré pour le traitement des données de longue séquence. Il s’inspire de la technique des fenêtres coulissantes en informatique. Lorsqu'il s'agit de tâches de traitement du langage naturel (NLP), SWA permet au modèle de se concentrer uniquement sur une fenêtre de taille fixe de la séquence d'entrée à chaque pas de temps, plutôt que sur la séquence entière. Par conséquent, l’avantage de SWA est qu’il peut réduire considérablement l’effort de calcul.
 Images
Images
Mais SWA a des limites car sa capacité d'attention est limitée par la taille de la fenêtre, ce qui empêche le modèle de prendre en compte les informations importantes en dehors de la fenêtre.
TransformerFAM réalise une attention intégrée, des mises à jour au niveau des blocs, une compression des informations et un stockage de contexte global en ajoutant l'activation du feedback pour ré-saisir la représentation du contexte dans chaque bloc d'attention de fenêtre coulissante.
Dans TransformerFAM, les améliorations sont obtenues grâce à des boucles de rétroaction. Plus précisément, lors du traitement du bloc de séquence actuel, le modèle se concentre non seulement sur les éléments de la fenêtre actuelle, mais réintroduit également des informations contextuelles précédemment traitées (c'est-à-dire « l'activation de rétroaction ») précédente comme entrée supplémentaire dans le mécanisme d'attention. De cette façon, même si la fenêtre d'attention du modèle glisse sur la séquence, il est capable de conserver la mémoire et la compréhension des informations précédentes.
Ainsi, après ces améliorations, TransformerFAM donne aux LLM le potentiel de gérer des séquences de longueur infinie !
Deuxièmement, avec un grand modèle de mémoire de travail, continuer à évoluer vers AGI
TransformerFAM a montré des perspectives positives dans la recherche, ce qui améliorera sans aucun doute les performances de l'IA dans la compréhension et la génération de tâches de texte longues, telles que le traitement de documents Résumé, génération d'histoires , questions-réponses et autres travaux.
 Images
Images
En même temps, qu'il s'agisse d'un assistant intelligent ou d'un compagnon émotionnel, une IA avec une mémoire illimitée semble plus attrayante.
Fait intéressant, la conception de TransformerFAM s'inspire du mécanisme de mémoire en biologie, qui coïncide avec la simulation de l'intelligence naturelle poursuivie par AGI. Cet article tente d’intégrer un concept issu des neurosciences – la mémoire de travail basée sur l’attention – dans le domaine de l’apprentissage profond.
TransformerFAM introduit la mémoire de travail dans les grands modèles via des boucles de rétroaction, permettant au modèle non seulement de mémoriser des informations à court terme, mais également de maintenir la mémoire d'informations clés dans des séquences à long terme.
Grâce à leur imagination audacieuse, les chercheurs créent des ponts entre le monde réel et les concepts abstraits. À mesure que des réalisations innovantes telles que TransformerFAM continuent d’émerger, les goulots d’étranglement technologiques seront sans cesse surmontés et un avenir plus intelligent et interconnecté se dévoile lentement vers nous.
Pour en savoir plus sur l'AIGC, veuillez visiter :
Communauté 51CTO AI.x
https://www.51cto.com/aigc/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment commenter Deepseek
Feb 19, 2025 pm 05:42 PM
Comment commenter Deepseek
Feb 19, 2025 pm 05:42 PM
Deepseek est un puissant outil de récupération d'informations. .
 Comment rechercher Deepseek
Feb 19, 2025 pm 05:39 PM
Comment rechercher Deepseek
Feb 19, 2025 pm 05:39 PM
Deepseek est un moteur de recherche propriétaire qui ne recherche que dans une base de données ou un système spécifique, plus rapide et plus précis. Lorsque vous l'utilisez, il est conseillé aux utilisateurs de lire le document, d'essayer différentes stratégies de recherche, de demander de l'aide et des commentaires sur l'expérience utilisateur afin de tirer le meilleur parti de leurs avantages.
 Sesame Open Door Exchange Page d'enregistrement de page Enregistrement Gate Trading App The Registration Site Web
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Page d'enregistrement de page Enregistrement Gate Trading App The Registration Site Web
Feb 28, 2025 am 11:06 AM
Cet article présente le processus d'enregistrement de la version Web de Sesame Open Exchange (GATE.IO) et l'application Gate Trading en détail. Qu'il s'agisse de l'enregistrement Web ou de l'enregistrement de l'application, vous devez visiter le site Web officiel ou l'App Store pour télécharger l'application authentique, puis remplir le nom d'utilisateur, le mot de passe, l'e-mail, le numéro de téléphone mobile et d'autres informations et terminer la vérification des e-mails ou du téléphone mobile.
 Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé?
Feb 21, 2025 pm 10:57 PM
Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé?
Feb 21, 2025 pm 10:57 PM
Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé? Bybit est un échange de crypto-monnaie qui fournit des services de trading aux utilisateurs. Les applications mobiles de l'échange ne peuvent pas être téléchargées directement via AppStore ou GooglePlay pour les raisons suivantes: 1. La politique de l'App Store empêche Apple et Google d'avoir des exigences strictes sur les types d'applications autorisées dans l'App Store. Les demandes d'échange de crypto-monnaie ne répondent souvent pas à ces exigences car elles impliquent des services financiers et nécessitent des réglementations et des normes de sécurité spécifiques. 2. Conformité des lois et réglementations Dans de nombreux pays, les activités liées aux transactions de crypto-monnaie sont réglementées ou restreintes. Pour se conformer à ces réglementations, l'application ByBit ne peut être utilisée que via des sites Web officiels ou d'autres canaux autorisés
 Sesame Open Door Trading Platform Download Version mobile Gateio Trading Plateforme de téléchargement Adresse de téléchargement
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Version mobile Gateio Trading Plateforme de téléchargement Adresse de téléchargement
Feb 28, 2025 am 10:51 AM
Il est crucial de choisir un canal formel pour télécharger l'application et d'assurer la sécurité de votre compte.
 Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Cet article recommande les dix principales plates-formes de trading de crypto-monnaie qui méritent d'être prêtées, notamment Binance, Okx, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, Bydfi et Xbit décentralisées. Ces plateformes ont leurs propres avantages en termes de quantité de devises de transaction, de type de transaction, de sécurité, de conformité et de fonctionnalités spéciales. Le choix d'une plate-forme appropriée nécessite une considération complète en fonction de votre propre expérience de trading, de votre tolérance au risque et de vos préférences d'investissement. J'espère que cet article vous aide à trouver le meilleur costume pour vous-même
 Binance Binance Site officiel Dernière version Portail de connexion
Feb 21, 2025 pm 05:42 PM
Binance Binance Site officiel Dernière version Portail de connexion
Feb 21, 2025 pm 05:42 PM
Pour accéder à la dernière version du portail de connexion du site Web de Binance, suivez simplement ces étapes simples. Accédez au site officiel et cliquez sur le bouton "Connectez-vous" dans le coin supérieur droit. Sélectionnez votre méthode de connexion existante. Entrez votre numéro de mobile ou votre mot de passe enregistré et votre mot de passe et complétez l'authentification (telles que le code de vérification mobile ou Google Authenticator). Après une vérification réussie, vous pouvez accéder à la dernière version du portail de connexion du site Web officiel de Binance.
 Sesame Open Door Exchange Page Web Login Dernière version GATEIO Entrée du site officiel
Mar 04, 2025 pm 11:48 PM
Sesame Open Door Exchange Page Web Login Dernière version GATEIO Entrée du site officiel
Mar 04, 2025 pm 11:48 PM
Une introduction détaillée à l'opération de connexion de la version Web Sesame Open Exchange, y compris les étapes de connexion et le processus de récupération de mot de passe.
