
 Périphériques technologiques
IA
Synthèse EEG de la parole naturelle ! LeCun transmet les nouveaux résultats de la sous-revue Nature, et le code est open source
Périphériques technologiques
IA
Synthèse EEG de la parole naturelle ! LeCun transmet les nouveaux résultats de la sous-revue Nature, et le code est open source
Synthèse EEG de la parole naturelle ! LeCun transmet les nouveaux résultats de la sous-revue Nature, et le code est open source

Les derniers progrès dans les interfaces cerveau-ordinateur ont été publiés dans la revue Nature, et LeCun, l'un des trois géants du deep learning, est venu les présenter.
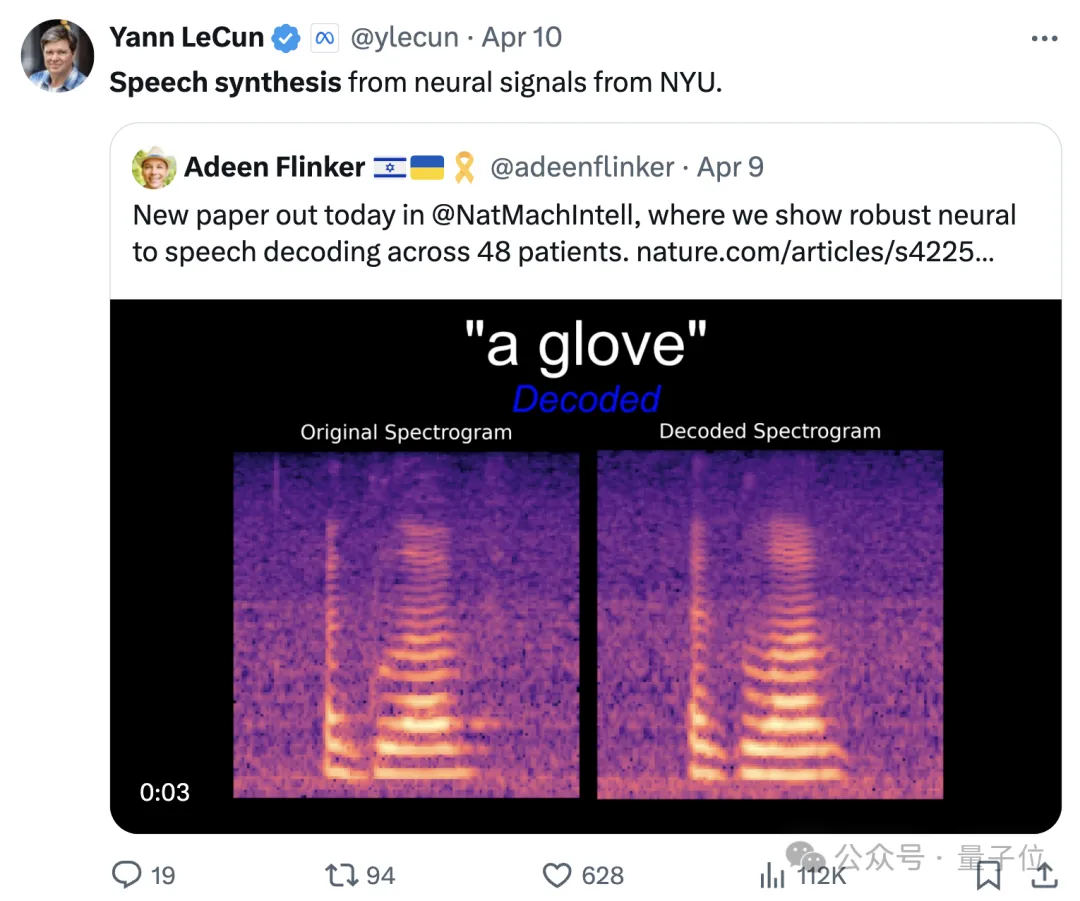
Cette fois, les signaux neuronaux sont utilisés pour la synthèse vocale afin d'aider les personnes aphasiques dues à des défauts neurologiques à retrouver la capacité de communiquer.
Il a été rapporté qu'une équipe de recherche de l'Université de New York a développé un nouveau type de synthétiseur vocal différenciable qui peut utiliser un réseau neuronal convolutionnel léger pour coder la parole en une série de paramètres vocaux interprétables (tels que la hauteur, le volume, la fréquence des formants, etc.) et resynthétiser la parole via un synthétiseur vocal différentiable.
En mappant les signaux neuronaux sur ces paramètres de parole, les chercheurs ont construit un système de décodage de la parole neuronale hautement interprétable et applicable à des situations de faible volume de données, et capable de générer une parole à consonance naturelle.
Au total, 48 chercheurs ont collecté des données sur des sujets et mené des expériences pour vérifier le décodage de la parole afin d'évaluer les futures interfaces cerveau-ordinateur de haute précision.
Les résultats montrent que le cadre peut gérer des densités d'échantillonnage spatial élevées et faibles et peut traiter les signaux EEG des hémisphères gauche et droit, montrant de fortes capacités de décodage de la parole.

Le décodage vocal des signaux neuronaux est difficile !
Auparavant, la société Neuralink de Musk a implanté avec succès des électrodes dans le cerveau d'un sujet, qui peuvent effectuer des opérations simples avec le curseur pour réaliser des fonctions telles que la saisie au clavier.
Cependant, le décodage neuronal de la parole est généralement considéré comme plus complexe.
La plupart des tentatives visant à développer des décodeurs neuro-vocaux et d'autres modèles d'interface cerveau-ordinateur de haute précision reposent sur un type particulier de données : les données enregistrées par électrocorticographie (ECoG), généralement provenant de patients épileptiques en cours de traitement.
Utilisez des électrodes implantées chez des patients épileptiques pour collecter des données sur le cortex cérébral pendant la parole. Ces données ont une haute résolution spatiale et temporelle et ont aidé les chercheurs à obtenir une série de résultats remarquables dans le domaine du décodage de la parole.
Cependant, le décodage vocal des signaux neuronaux se heurte encore à deux défis majeurs.
- Les données utilisées pour entraîner des modèles personnalisés de décodage neuronal à la parole sont très limitées dans le temps, généralement seulement une dizaine de minutes, tandis que les modèles d'apprentissage en profondeur nécessitent souvent une grande quantité de données d'entraînement pour être pilotés.
- La prononciation humaine est très diversifiée. Même si la même personne prononce le même mot à plusieurs reprises, la vitesse, l'intonation et la hauteur de la parole changeront, ce qui ajoute de la complexité à l'espace de représentation construit par le modèle.
Les premières tentatives de décodage des signaux neuronaux en parole reposaient principalement sur des modèles linéaires. Les modèles ne nécessitaient généralement pas d'énormes ensembles de données d'entraînement et étaient hautement interprétables, mais la précision était très faible.
Récemment basées sur les réseaux de neurones profonds, notamment l'utilisation d'architectures de réseaux de neurones convolutifs et récurrents, de nombreuses tentatives ont été faites dans les deux dimensions clés de la simulation de la représentation latente intermédiaire de la parole et de la qualité de la parole synthétisée. Par exemple, certaines études décodent l'activité du cortex cérébral en espace de mouvement de la bouche, puis la convertissent en parole. Bien que les performances de décodage soient puissantes, la voix reconstruite ne semble pas naturelle.
D'un autre côté, certaines méthodes réussissent à reconstruire une parole naturelle en utilisant le vocodeur wavenet, le réseau contradictoire génératif (GAN) , etc., mais la précision est limitée.
Une étude récente publiée dans Nature a obtenu à la fois précision et exactitude en utilisant les caractéristiques HuBERT quantifiées comme espace de représentation intermédiaire et un synthétiseur vocal pré-entraîné pour convertir ces caractéristiques en parole chez un patient doté d'un dispositif implanté.
Cependant, les fonctionnalités HuBERT ne peuvent pas représenter des informations acoustiques spécifiques au locuteur et peuvent uniquement générer des sons de haut-parleur fixes et unifiés. Des modèles supplémentaires sont donc nécessaires pour convertir ce son universel en la voix d'un patient spécifique. De plus, cette étude et la plupart des tentatives précédentes ont adopté une architecture non causale, ce qui peut limiter son utilisation dans les applications pratiques d'interface cerveau-ordinateur nécessitant des opérations causales temporelles. Création d'un synthétiseur vocal différenciableL'équipe de recherche du NYU Video Lab et du Flinker Lab a introduit un nouveau cadre de décodage de l'électroencéphalogramme
(ECoG)du signal à la parole, construisant une représentation intermédiaire de faible dimension
(représentation latente de faible dimension), qui est généré par un modèle de codage et de décodage de la parole utilisant uniquement des signaux vocaux.
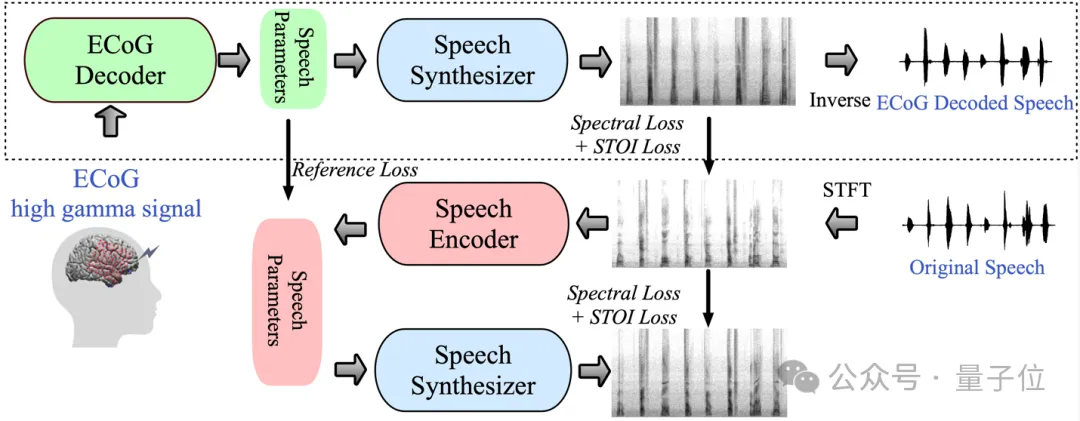
△Cadre de décodage de la parole neuronale
 Plus précisément, le cadre se compose de deux parties :
Plus précisément, le cadre se compose de deux parties :
 Plus précisément, le cadre se compose de deux parties :
Plus précisément, le cadre se compose de deux parties : Une partie est le décodeur ECoG, qui convertit le signal ECoG en paramètres de parole acoustique que nous pouvons comprendre (tels que la hauteur, si le son production, volume et fréquence des formants, etc.);
L'autre partie est le synthétiseur vocal, qui convertit ces paramètres vocaux en spectrogramme.
Les chercheurs ont construit un synthétiseur vocal différentiable, qui permet au synthétiseur vocal de participer également à la formation lors de la formation du décodeur ECoG et d'optimiser conjointement pour réduire l'erreur de reconstruction du spectrogramme.
Cet espace latent de faible dimension a une forte interprétabilité, et l'encodeur vocal léger pré-entraîné génère des paramètres vocaux de référence, aidant les chercheurs à construire un cadre de décodage neuronal efficace et à surmonter le problème des données très rares dans le domaine de. décodage de la parole.
Ce cadre peut générer une parole naturelle très proche de la voix du locuteur, et la partie décodeur ECoG peut être connectée à différentes architectures de modèles d'apprentissage en profondeur et prend également en charge les opérations causales.
Les chercheurs ont collecté et traité les données ECoG de 48 patients en neurochirurgie, en utilisant plusieurs architectures d'apprentissage profond (y compris la convolution, le réseau neuronal récurrent et le transformateur) comme décodeurs ECoG.
Le framework a démontré une grande précision sur différents modèles, avec les meilleures performances obtenues avec l'architecture convolutive (ResNet). Le cadre proposé par les chercheurs dans cet article ne peut atteindre une grande précision que grâce à des opérations causales et un taux d'échantillonnage relativement faible (faible densité, espacement de 10 mm). Ils ont également démontré la capacité d’effectuer un décodage efficace de la parole à partir des hémisphères gauche et droit du cerveau, étendant ainsi l’application du décodage neuronal de la parole à l’hémisphère droit.
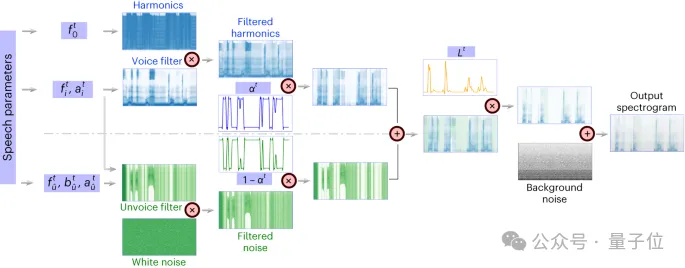
△ Architecture du synthétiseur vocal différenciable
 △ Architecture du synthétiseur vocal différenciable
△ Architecture du synthétiseur vocal différenciable Le synthétiseur vocal différenciable
(synthétiseur vocal)rend la tâche de resynthèse vocale très efficace et peut utiliser une très petite synthèse vocale pour faire correspondre le son original avec un audio haute fidélité. Le principe du synthétiseur vocal différenciable s'inspire du principe du système génératif humain et divise la parole en deux parties : Voice
(pour modéliser les voyelles)et Unvoice (pour modéliser les consonnes) . La partie Voix peut d'abord utiliser le signal de fréquence fondamentale pour générer des harmoniques, et le filtrer avec un filtre composé des pics formants de F1-F6 pour obtenir les caractéristiques spectrales de la partie voyelle.
Pour la partie Unvoice, les chercheurs ont filtré le bruit blanc avec les filtres correspondants pour obtenir le spectre correspondant. Un paramètre apprenable peut contrôler le rapport de mélange des deux parties à chaque instant, le signal d'intensité est amplifié et un bruit de fond ajouté. pour obtenir le spectre final de la parole.
△ Encodeur vocal et décodeur ECoG
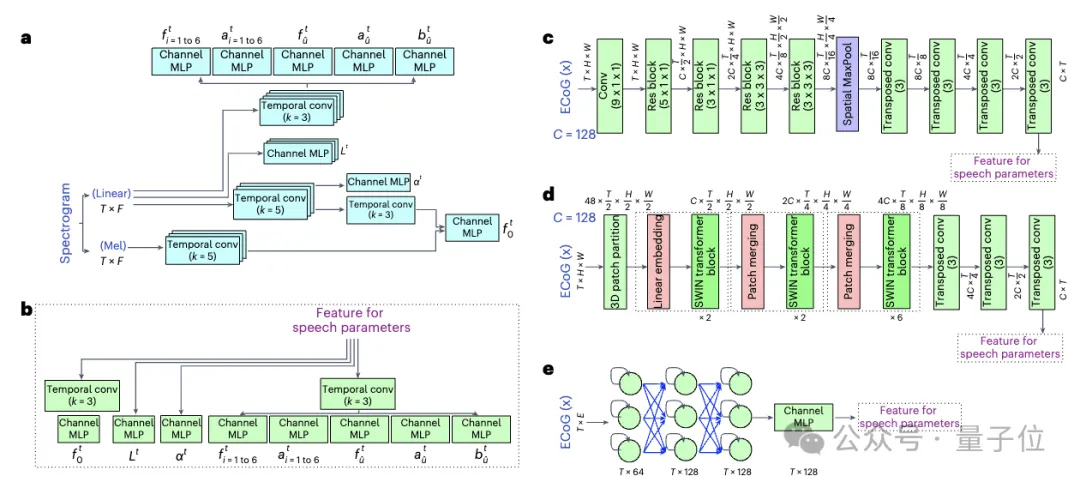 △ Encodeur vocal et décodeur ECoG
△ Encodeur vocal et décodeur ECoG Résultats de la recherche
1. Résultats du décodage vocal avec causalité temporelle
Tout d'abord, les chercheurs ont comparé directement différentes architectures de modèles convolution
(ResNet)et boucle La différence dans le décodage vocal performances entre (LSTM) et Transformer (3D Swin) . Il convient de noter que ces modèles peuvent effectuer des opérations non causales
(non causales)ou causales dans le temps. La causalité des modèles de décodage a de grandes implications pour les interfaces cerveau-ordinateur
(BCI)applications : les modèles causals utilisent uniquement les signaux neuronaux passés et actuels pour générer la parole, tandis que les modèles acausaux utilisent également les signaux neuronaux futurs, ce qui en temps réel n'est pas réalisable en application. Par conséquent, ils se sont concentrés sur la comparaison des performances du même modèle lors de l'exécution d'opérations causales et causales.
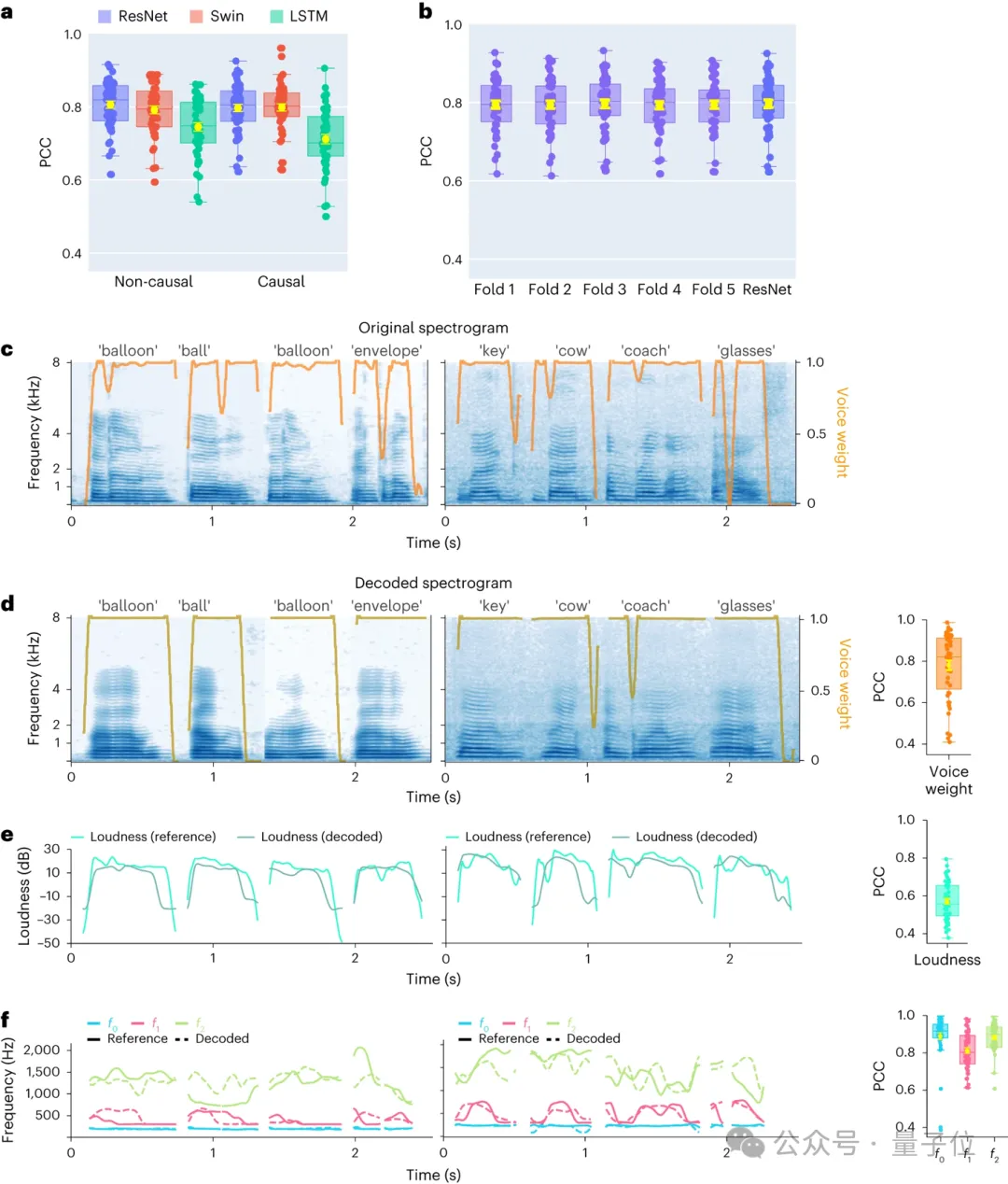 Il a été constaté que même la version causale du modèle ResNet est comparable à la version non causale, sans différence significative entre les deux. De même, les performances des versions causales et non causales du modèle Swin sont similaires, mais les performances de la version causale du modèle LSTM sont nettement inférieures à celles de la version non causale.
Il a été constaté que même la version causale du modèle ResNet est comparable à la version non causale, sans différence significative entre les deux. De même, les performances des versions causales et non causales du modèle Swin sont similaires, mais les performances de la version causale du modèle LSTM sont nettement inférieures à celles de la version non causale.
Les chercheurs démontrent une précision de décodage moyenne (N = 48) pour plusieurs paramètres clés de la parole, notamment le poids du son (utilisé pour distinguer les voyelles des consonnes), l'intensité sonore, la hauteur f0, le premier formant f1 et le deuxième formant Peak f2. Une reconstruction précise de ces paramètres vocaux, en particulier la hauteur, le poids du son et les deux premiers formants, est essentielle pour obtenir un décodage et une reconstruction précis de la parole qui imite naturellement la voix du participant.
Les résultats montrent que les modèles non causals et causals peuvent obtenir des résultats de décodage raisonnables, ce qui fournit des orientations positives pour les recherches et applications futures.
2. Recherche sur le décodage de la parole et le taux d'échantillonnage spatial des signaux neuronaux des cerveaux gauche et droit
Les chercheurs ont ensuite comparé les résultats du décodage de la parole des hémisphères cérébraux gauche et droit. La plupart des études se sont concentrées sur l’hémisphère gauche, qui domine les fonctions de la parole et du langage, tandis que moins d’attention a été accordée au décodage des informations linguistiques provenant de l’hémisphère droit.
Dans cette perspective, ils ont comparé les performances de décodage des hémisphères cérébraux gauche et droit des participants pour vérifier la possibilité d’utiliser l’hémisphère cérébral droit pour la récupération de la parole.
Parmi les 48 sujets collectés dans l'étude, les signaux ECoG de 16 sujets ont été collectés à partir du cerveau droit.
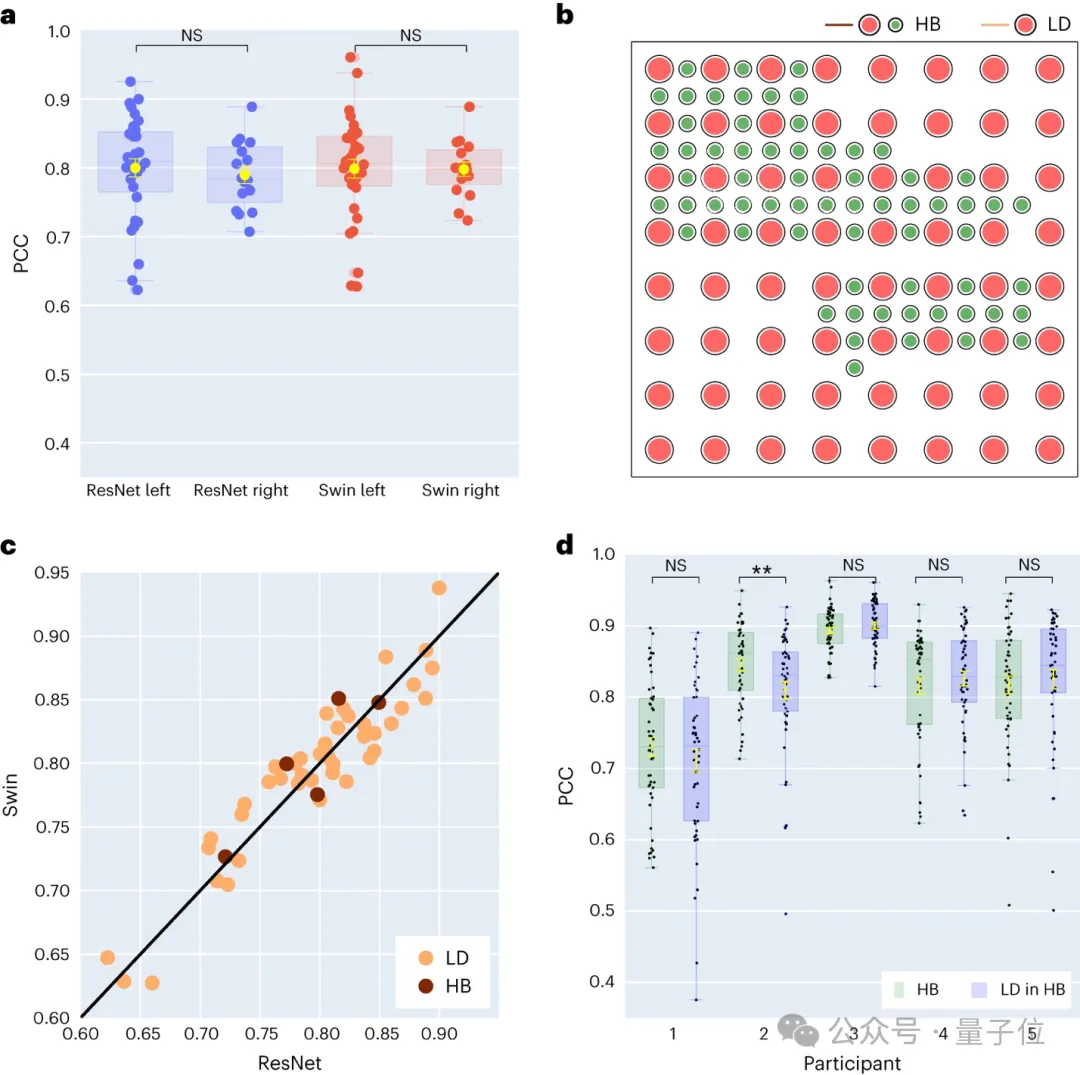
En comparant les performances des décodeurs ResNet et Swin, nous avons constaté que l'hémisphère droit du cerveau peut également effectuer un décodage de la parole de manière stable et que l'effet de décodage est inférieur à celui de l'hémisphère gauche du cerveau.
Cela signifie que pour les patients présentant des lésions de l'hémisphère gauche et une perte de la capacité de langage, l'utilisation de signaux neuronaux de l'hémisphère droit pour restaurer le langage peut être une solution réalisable.
Ensuite, ils ont également exploré l’impact de la densité d’échantillonnage des électrodes sur l’effet de décodage de la parole.
Les études précédentes utilisaient principalement des grilles d'électrodes de densité plus élevée (0,4 mm) , tandis que la densité des grilles d'électrodes couramment utilisées en pratique clinique est plus faible (LD 1 cm) . Cinq participants ont utilisé des grilles d'électrodes de type hybride (HB) , qui sont principalement des échantillonnages à faible densité mais intègrent des électrodes supplémentaires. Les quarante-trois participants restants ont été échantillonnés à faible densité. Les performances de décodage de ces échantillons hybrides (HB) sont similaires aux échantillons traditionnels à faible densité (LD) .
Cela montre que le modèle peut apprendre des informations vocales du cortex cérébral avec différentes densités d'échantillonnage spatial, ce qui implique également que la densité d'échantillonnage couramment utilisée dans la pratique clinique pourrait être suffisante pour les futures applications d'interface cerveau-ordinateur.
3. Recherche sur la contribution de différentes zones cérébrales du cerveau gauche et droit au décodage de la parole
Les chercheurs ont également examiné la contribution des zones du cerveau liées à la parole dans le processus de décodage de la parole, ce qui sera utile à l'avenir. l'implantation de la parole dans les hémisphères gauche et droit du cerveau constitue une référence importante.
Utilise la technologie d'occlusion(analyse d'occlusion) pour évaluer la contribution de différentes zones cérébrales au décodage de la parole.
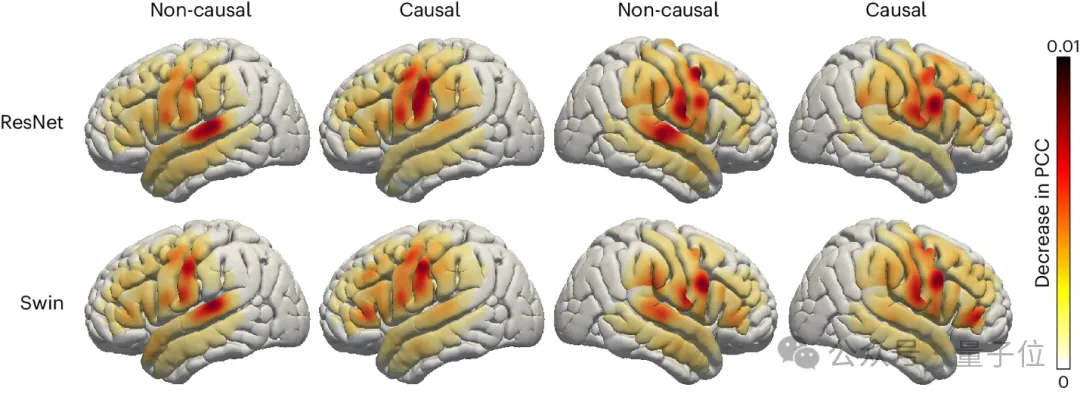
En comparant les modèles causals et non causals des décodeurs ResNet et Swin, il s'avère que le cortex auditif contribue davantage au modèle non causal. Cela confirme que dans les applications de décodage vocal en temps réel, les modèles causals doivent être utilisés. être utilisé, car dans le décodage de la parole en temps réel, nous ne pouvons pas tirer parti des signaux de neurofeedback.
De plus, que ce soit dans l'hémisphère droit ou gauche, l'apport du cortex sensorimoteur, notamment de la zone abdominale, est similaire, ce qui laisse penser que l'implantation de prothèses neurales dans l'hémisphère droit pourrait être une solution réalisable.
En conclusion, cette recherche a fait une série de progrès dans l'interface cerveau-ordinateur, mais les chercheurs ont également mentionné certaines limites du modèle actuel. Par exemple, le processus de décodage nécessite des données d'entraînement à la parole associées à des enregistrements ECoG, ce qui est très important. pour l'aphasie. Les patients peuvent ne pas être éligibles.
À l'avenir, ils espèrent développer une architecture modèle capable de gérer des données hors grille et de mieux utiliser les données EEG multi-patients et multimodales.
Dans le domaine de l'interface cerveau-ordinateur, la recherche actuelle en est encore à ses débuts. Avec l'itération de la technologie matérielle et les progrès rapides de la technologie d'apprentissage profond, les idées d'interface cerveau-ordinateur apparaissant dans les films de science-fiction vont se développer. se rapprocher de la réalité.
Lien papier : https://www.nature.com/articles/s42256-024-00824-8.
Lien GitHub : https://github.com/flinkerlab/neural_speech_decoding.
Plus d'exemples de discours générés : https://xc1490.github.io/nsd/.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment générer des clés SSH dans Git
Apr 17, 2025 pm 01:36 PM
Comment générer des clés SSH dans Git
Apr 17, 2025 pm 01:36 PM
Afin de se connecter en toute sécurité à un serveur GIT distant, une clé SSH contenant des clés publiques et privées doit être générée. Les étapes pour générer une touche SSH sont les suivantes: Ouvrez le terminal et entrez la commande ssh-keygen -t rsa -b 4096. Sélectionnez l'emplacement d'enregistrement de la clé. Entrez une phrase de mot de passe pour protéger la clé privée. Copiez la clé publique sur le serveur distant. Enregistrez correctement la clé privée car ce sont les informations d'identification pour accéder au compte.
 Comment supprimer un référentiel par git
Apr 17, 2025 pm 04:03 PM
Comment supprimer un référentiel par git
Apr 17, 2025 pm 04:03 PM
Pour supprimer un référentiel GIT, suivez ces étapes: Confirmez le référentiel que vous souhaitez supprimer. Suppression locale du référentiel: utilisez la commande RM -RF pour supprimer son dossier. Supprimer à distance un entrepôt: accédez à l'entrepôt, trouvez l'option "Supprimer l'entrepôt" et confirmez l'opération.
 Comment se connecter au réseau public du serveur GIT
Apr 17, 2025 pm 02:27 PM
Comment se connecter au réseau public du serveur GIT
Apr 17, 2025 pm 02:27 PM
La connexion d'un serveur GIT au réseau public comprend cinq étapes: 1. Configurer l'adresse IP publique; 2. Ouvrez le port de pare-feu (22, 9418, 80/443); 3. Configurer l'accès SSH (générer des paires de clés, créer des utilisateurs); 4. Configurer l'accès HTTP / HTTPS (installer les serveurs, configurer les autorisations); 5. Testez la connexion (en utilisant les commandes SSH Client ou GIT).
 Comment détecter SSH par Git
Apr 17, 2025 pm 02:33 PM
Comment détecter SSH par Git
Apr 17, 2025 pm 02:33 PM
Pour détecter SSH via GIT, vous devez effectuer les étapes suivantes: générer une paire de clés SSH. Ajoutez la clé publique au serveur GIT. Configurez Git pour utiliser SSH. Testez la connexion SSH. Résoudre les problèmes possibles en fonction des conditions réelles.
 Comment ajouter des clés publiques au compte GIT
Apr 17, 2025 pm 02:42 PM
Comment ajouter des clés publiques au compte GIT
Apr 17, 2025 pm 02:42 PM
Comment ajouter une clé publique à un compte GIT? Étape: générer une paire de clés SSH. Copiez la clé publique. Ajoutez une clé publique dans Gitlab ou GitHub. Testez la connexion SSH.
 Que faire si le téléchargement git n'est pas actif
Apr 17, 2025 pm 04:54 PM
Que faire si le téléchargement git n'est pas actif
Apr 17, 2025 pm 04:54 PM
Résolve: lorsque la vitesse de téléchargement GIT est lente, vous pouvez prendre les étapes suivantes: Vérifiez la connexion réseau et essayez de changer la méthode de connexion. Optimiser la configuration GIT: augmenter la taille du tampon post (Git Config - Global Http.PostBuffer 524288000) et réduire la limite à basse vitesse (Git Config - Global Http.LowspeedLimit 1000). Utilisez un proxy GIT (comme Git-Proxy ou Git-LFS-Proxy). Essayez d'utiliser un client GIT différent (comme SourceTree ou GitHub Desktop). Vérifiez la protection contre les incendies
 Comment résoudre le problème de recherche efficace dans les projets PHP? Typesense vous aide à y parvenir!
Apr 17, 2025 pm 08:15 PM
Comment résoudre le problème de recherche efficace dans les projets PHP? Typesense vous aide à y parvenir!
Apr 17, 2025 pm 08:15 PM
Lors du développement d'un site Web de commerce électronique, j'ai rencontré un problème difficile: comment atteindre des fonctions de recherche efficaces en grande quantité de données de produit? Les recherches traditionnelles de base de données sont inefficaces et ont une mauvaise expérience utilisateur. Après quelques recherches, j'ai découvert le moteur de recherche TypeSense et résolu ce problème grâce à son client PHP officiel TypeSense / TypeSen-PHP, ce qui a considérablement amélioré les performances de recherche.
 Comment revenir après la soumission GIT
Apr 17, 2025 pm 01:06 PM
Comment revenir après la soumission GIT
Apr 17, 2025 pm 01:06 PM
Pour retomber un engagement Git, vous pouvez utiliser la commande git reset - hard ~ n, où n représente le nombre de validations à se replier. Les étapes détaillées comprennent: déterminer le nombre de validations à faire reculer. Utilisez l'option - dure pour forcer une secours. Exécutez la commande pour retomber à l'engagement spécifié.
