
 Périphériques technologiques
IA
Balayez 99 sous-missions avec le MoE ! L'Université du Zhejiang et d'autres ont proposé une nouvelle stratégie générale en matière de robots GeRM
Périphériques technologiques
IA
Balayez 99 sous-missions avec le MoE ! L'Université du Zhejiang et d'autres ont proposé une nouvelle stratégie générale en matière de robots GeRM
Balayez 99 sous-missions avec le MoE ! L'Université du Zhejiang et d'autres ont proposé une nouvelle stratégie générale en matière de robots GeRM

L'apprentissage robotique multitâche est d'une grande importance pour faire face à des scénarios divers et complexes. Cependant, les méthodes actuelles sont limitées par des problèmes de performances et des difficultés de collecte d'ensembles de données de formation.
Cet article propose GeRM (Generic Robot Model), dans lequel les chercheurs exploitent l'apprentissage par renforcement hors ligne pour optimiser les stratégies d'utilisation des données, en apprenant à partir de démonstrations et de données sous-optimales, transcendant ainsi les limites des démonstrations humaines.

Auteurs : Song Wenxuan, Zhao Han, Ding Pengxiang, Cui Can, Lu Shangke, Fan Yaning, Wang Donglin
Auteur : West Lake University, Zhejiang University
Adresse papier : https : //arxiv.org/abs/2403.13358
Adresse du projet : https://songwxuan.github.io/GeRM/
Ensuite, un modèle vision-langage-action basé sur Transformer est utilisé pour traiter le multimodal. actions d’entrée et de sortie.
En introduisant une structure hybride experte, GeRM atteint une vitesse d'inférence plus rapide et une capacité globale de modèle plus élevée, résolvant ainsi le problème du volume limité des paramètres d'apprentissage par renforcement, améliorant les performances du modèle dans l'apprentissage multitâche, tout en contrôlant le calcul du coût.
Il est prouvé à travers une série d'expériences que GeRM surpasse les autres méthodes dans toutes les tâches, tout en vérifiant son efficacité dans les processus de formation et d'inférence.
De plus, les chercheurs ont également fourni l'ensemble de données QUARD-Auto pour soutenir la formation. La construction de cet ensemble de données suit le nouveau paradigme de collecte d'automatisation des données proposé dans l'article. Cette méthode peut réduire le coût de collecte des données des robots. et promouvoir l’apprentissage multitâche.
Principales contributions :
1 Proposé pour la première fois un modèle expert hybride pour l'apprentissage par renforcement à quatre pattes, qui est formé sur des données de qualité mixte et a le potentiel d'apprendre des stratégies optimales.
2. Par rapport aux méthodes existantes, GeRM affiche un taux de réussite plus élevé lorsqu'il n'active que la moitié de ses propres paramètres, active les capacités d'émergence et démontre une meilleure utilisation des données pendant le processus de formation.
3. Proposition d'un paradigme pour la collecte entièrement automatique d'ensembles de données de robots et collecte d'un ensemble de données open source à grande échelle.
Méthode
La structure du réseau GeRM est illustrée à la figure 1. L'entrée visuo-linguistique comprenant les données de démonstration et les données d'échec est entrée dans le décodeur de la structure experte hybride à 8 couches après être passée respectivement par l'encodeur et le tokenizer, et génère des jetons d'action, puis convertis en données d'action discrètes du robot et déployés sur le robot via la stratégie sous-jacente. De plus, nous utilisons l'apprentissage par renforcement pour la formation.
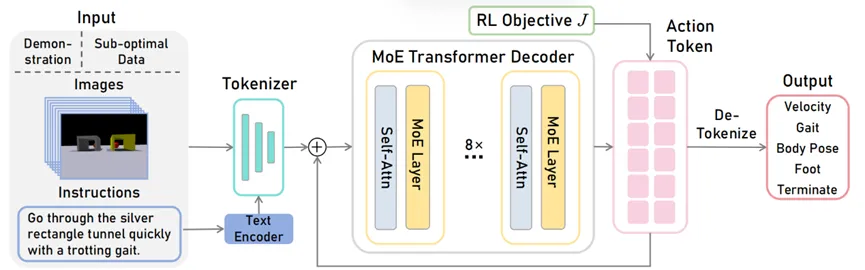
Figure 1 Diagramme de structure du réseau GeRM
GeRM Decoder est un modèle d'architecture Transformer Decoder, dans lequel le réseau à action directe (FFN) est sélectionné parmi un ensemble de 8 réseaux experts différents.
A chaque couche, pour chaque jeton, le réseau fermé sélectionne deux experts pour traiter le jeton et combiner leurs sorties de manière pondérée.
Différents experts sont bons dans différentes tâches/différentes dimensions d'action pour résoudre des problèmes dans différents scénarios, apprenant ainsi un modèle commun pour plusieurs tâches. Cette architecture augmente la quantité de paramètres de réseau tout en gardant le coût de calcul essentiellement inchangé.
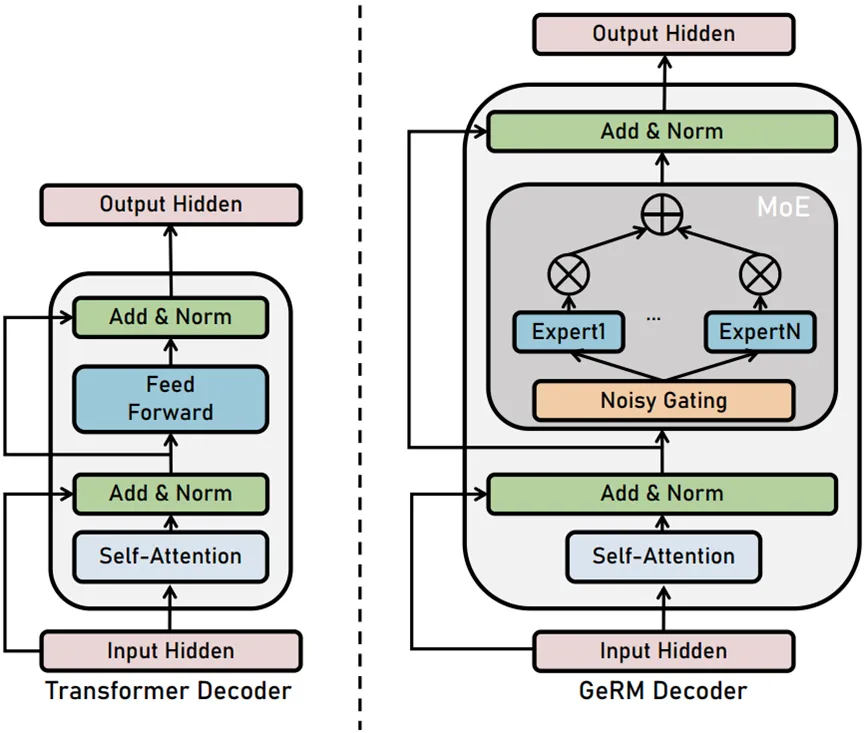
Figure 2 Schéma de structure du décodeur
Nous proposons un paradigme automatique pour collecter des données multimodales de robots. De cette manière, nous avons construit QUARD-Auto, un ensemble de données robotiques à grande échelle contenant une combinaison de données de démonstration et de données sous-optimales. Il comprend 5 tâches et 99 sous-tâches, avec un total de 257 000 trajectoires. Nous allons ouvrir la source pour promouvoir le développement de la communauté robotique.

Tableau 1 Introduction à l'ensemble de données
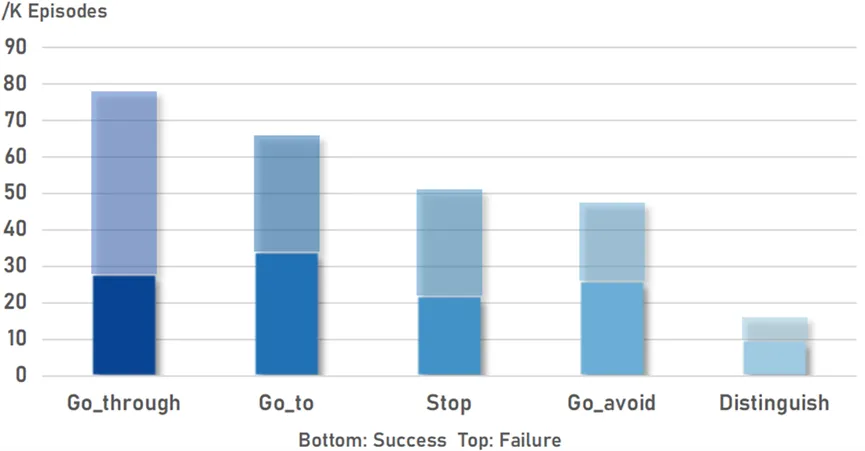
Figure 3 Statistiques sur le volume de données
Expériences
Nous avons mené une série complète et robuste d'expériences couvrant les 99 sous-tâches, dont chacune a été soigneusement testée sur 400 trajectoires.
Comme le montre le tableau 1, GeRM a le taux de réussite le plus élevé parmi toutes les tâches. Comparé au RT-1 et à d’autres variantes de GeRM, il apprend efficacement à partir de données de qualité mixte, surpasse les autres méthodes et présente des capacités supérieures dans plusieurs tâches. Dans le même temps, le module MoE équilibre le coût et les performances de calcul en activant certains paramètres lors de l'inférence.
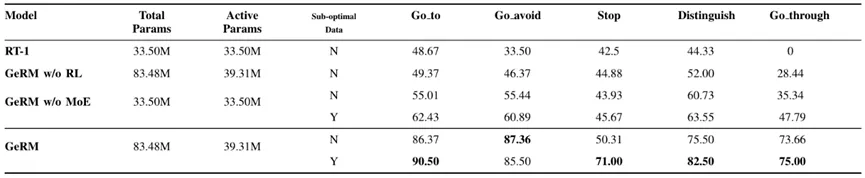
Tableau 2 Expérience de comparaison multi-tâches
GeRM montre une efficacité de formation louable. Comparé à d'autres méthodes, GeRM atteint des pertes extrêmement faibles et un taux de réussite élevé avec seulement quelques lots, soulignant la capacité de GeRM à optimiser les stratégies d'utilisation des données.
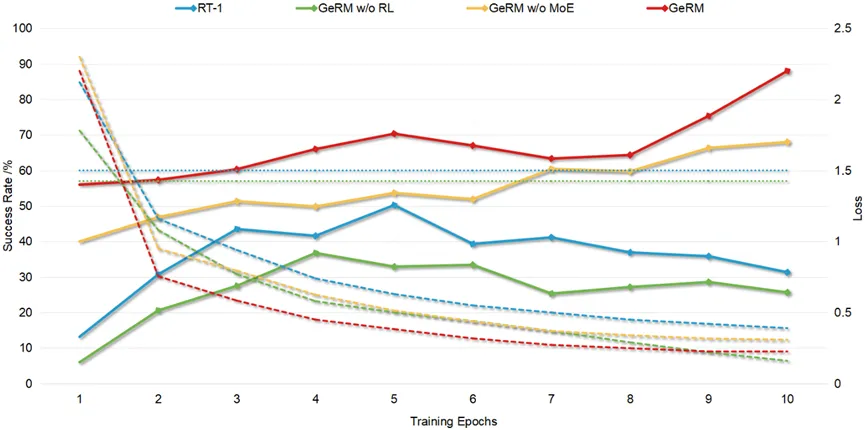
Figure 4 Taux de réussite/Courbe de changement de perte
GeRM a démontré des capacités émergentes en matière de planification dynamique de parcours adaptatifs. Comme le montre la vidéo, le robot quadrupède a un champ de vision limité dans la position initiale et il est difficile de déterminer la direction du mouvement. Pour éviter l’obstacle, il choisit au hasard de tourner à gauche.
Par la suite, lorsqu'il rencontre une entrée visuelle erronée, le robot effectue une réorientation drastique pour s'aligner sur la bonne cible en dehors du champ de vision d'origine. Il continue ensuite vers sa destination, accomplissant finalement sa mission.
Il convient de noter que de telles trajectoires ne relèvent pas de la distribution de notre ensemble de données d'entraînement. Cela démontre les capacités émergentes de GeRM en matière de planification dynamique et adaptative de trajectoires dans le contexte d'une scène, c'est-à-dire sa capacité à prendre des décisions basées sur la perception visuelle, à planifier les trajectoires futures et à modifier les prochaines étapes si nécessaire.

Figure 5 Capacité émergente
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Sony confirme la possibilité d'utiliser des GPU spéciaux sur PS5 Pro pour développer une IA avec AMD
Apr 13, 2025 pm 11:45 PM
Sony confirme la possibilité d'utiliser des GPU spéciaux sur PS5 Pro pour développer une IA avec AMD
Apr 13, 2025 pm 11:45 PM
Mark Cerny, architecte en chef de SonyInterActiveTeretment (SIE, Sony Interactive Entertainment), a publié plus de détails matériels de l'hôte de nouvelle génération PlayStation5Pro (PS5PRO), y compris un GPU AMDRDNA2.x architecture amélioré sur les performances, et un programme d'apprentissage de l'intelligence machine / artificielle "AmethylSt" avec AMD. L'amélioration des performances de PS5PRO est toujours sur trois piliers, y compris un GPU plus puissant, un traçage avancé des rayons et une fonction de super-résolution PSSR alimentée par AI. GPU adopte une architecture AMDRDNA2 personnalisée, que Sony a nommé RDNA2.x, et il a une architecture RDNA3.
 Enfin changé! La fonction de recherche Microsoft Windows inaugurera une nouvelle mise à jour
Apr 13, 2025 pm 11:42 PM
Enfin changé! La fonction de recherche Microsoft Windows inaugurera une nouvelle mise à jour
Apr 13, 2025 pm 11:42 PM
Les améliorations de Microsoft aux fonctions de recherche Windows ont été testées sur certains canaux d'initiés Windows dans l'UE. Auparavant, la fonction de recherche Windows intégrée a été critiquée par les utilisateurs et avait une mauvaise expérience. Cette mise à jour divise la fonction de recherche en deux parties: recherche locale et recherche Web basée sur Bing pour améliorer l'expérience utilisateur. La nouvelle version de l'interface de recherche effectue la recherche de fichiers locale par défaut. Si vous devez rechercher en ligne, vous devez cliquer sur l'onglet "Microsoft Bingwebsearch" pour changer. Après le changement, la barre de recherche affichera "Microsoft BingWebsearch:", où les utilisateurs peuvent entrer des mots clés. Ce mouvement évite efficacement le mélange des résultats de recherche locaux avec les résultats de recherche Bing
 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Quelles sont les méthodes de réglage des performances de Zookeeper sur Centos
Apr 14, 2025 pm 03:18 PM
Le réglage des performances de Zookeeper sur CentOS peut commencer à partir de plusieurs aspects, notamment la configuration du matériel, l'optimisation du système d'exploitation, le réglage des paramètres de configuration, la surveillance et la maintenance, etc. Assez de mémoire: allouez suffisamment de ressources de mémoire à Zookeeper pour éviter la lecture et l'écriture de disques fréquents. CPU multi-core: utilisez un processeur multi-core pour vous assurer que Zookeeper peut le traiter en parallèle.
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Une formation efficace des modèles Pytorch sur les systèmes CentOS nécessite des étapes, et cet article fournira des guides détaillés. 1. Préparation de l'environnement: Installation de Python et de dépendance: le système CentOS préinstalle généralement Python, mais la version peut être plus ancienne. Il est recommandé d'utiliser YUM ou DNF pour installer Python 3 et Mettez PIP: sudoyuMupDatePython3 (ou sudodnfupdatepython3), pip3install-upradepip. CUDA et CUDNN (accélération GPU): Si vous utilisez Nvidiagpu, vous devez installer Cudatool
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
