
 Périphériques technologiques
IA
Réflexions et pratiques sur la génération assistée de code frontal B-end sous de grands modèles
Périphériques technologiques
IA
Réflexions et pratiques sur la génération assistée de code frontal B-end sous de grands modèles
Réflexions et pratiques sur la génération assistée de code frontal B-end sous de grands modèles

1.Contexte
Pendant le travail de refactoring, spécifications du code : pendant le processus de développement front-end B-end, les développeurs seront toujours confrontés au problème du développement répété. Les modules d'éléments de nombreuses pages CRUD sont fondamentalement similaires, mais ils. doivent toujours être développés manuellement, passer du temps sur la construction d'éléments simples réduit l'efficacité du développement des exigences commerciales. Dans le même temps, parce que les styles de codage des différents développeurs sont incohérents, il est plus coûteux pour les autres de démarrer pendant les itérations.
L'IA remplace la simple intelligence : avec le développement continu de grands modèles d'IA, elle possède déjà des capacités de compréhension simples et peut convertir le langage en instructions. Les instructions générales pour la création de pages de base peuvent répondre aux besoins quotidiens de création de pages de base et améliorer l'efficacité du développement commercial dans des scénarios généraux.
2. Aperçu des liens générés
Les listes, formulaires et détails des pages côté B. Tous les liens de support peuvent être grossièrement divisés en les étapes suivantes.
 Images
Images
- Saisie en langage naturel
- Combiné avec le grand modèle pour extraire les informations de construction correspondantes selon les règles spécifiées
- Les informations de construction sont combinées avec le modèle de code et AST pour sortir le code frontal
Trois. Exigences expresses
Graphiquement La première étape de la configuration
est de lui indiquer quel type d'interface développer. À ce sujet, la première chose à laquelle nous pensons est la configuration des pages, qui est la forme courante actuelle des produits low-code. Les utilisateurs créent des pages à travers une série de configurations graphiques, comme indiqué ci-dessous :
 Images
Images
. Destiné à des scénarios généraux (tels que Il a un bon effet sur l'amélioration de l'efficacité des pages CURD avec une gestion d'arrière-plan relativement simple) ou à des scénarios commerciaux spécifiques (tels que la construction de sites). Pour les exigences relativement complexes qui nécessitent une itération continue de la logique, puisque la configuration se fait via des opérations graphiques, les exigences en matière de conception interactive sont plus élevées et il y a un certain coût de démarrage. En même temps, à mesure que la complexité des exigences devient plus élevée. et plus, la configuration des interactions entre formulaires devient de plus en plus complexe et les coûts de maintenance sont de plus en plus élevés. Par conséquent, l’utilisation de champs front-end dans la configuration des pages est relativement restreinte.
L'IA génère directement du code
Le code généré par l'IA est plus couramment utilisé dans les scénarios de fonctions d'outils, mais pour les besoins de scénarios commerciaux spécifiques au sein de l'entreprise, les points suivants peuvent devoir être pris en compte :
- Personnalisation de la génération : équipe de l'entreprise Il dispose de sa propre pile technologique et de composants généraux robustes en interne, et ces connaissances doivent être pré-formées. Actuellement, seule l'injection en une seule session est prise en charge pour le contenu de pré-formation de texte long, et la consommation de jetons est élevée. ;
- Précision : la précision du code généré par l'IA Le défi est relativement important. De plus, la pré-formation contient une grande section d'invites. Parce que la sortie du code contient trop de détails et d'hallucinations de modèle, le taux d'échec des codes métier. est actuellement relativement élevé et la précision est une considération du codage auxiliaire. Si cela ne peut pas être résolu, l'effet du codage auxiliaire sera considérablement réduit
- Contenu généré incomplet : en raison des limitations d'une seule session GPT, pour des exigences complexes, il y a des problèmes. Il y a une certaine chance que la génération de code soit tronquée, affectant le taux de réussite de la génération.
Le langage naturel pour les instructions
GPT a en fait une capacité très importante, c'est-à-dire que le langage naturel pour les instructions, les instructions sont des actions. Par exemple : nous supposons qu'une méthode de fonction est implémentée et que la saisie est naturelle. En combinant GPT avec l'invite intégrée et en lui permettant d'afficher de manière stable certains mots, pouvons-nous prendre d'autres mesures en affichant ces mots ? Cela présente les avantages suivants par rapport à la configuration graphique :
- Faible seuil d'apprentissage : le langage naturel lui-même étant la langue maternelle des êtres humains, il vous suffit de décrire la page selon vos idées. Bien entendu, le contenu de la description doit le faire. suivre certaines spécifications Oui, mais l'efficacité est considérablement améliorée par rapport à la configuration graphique ;
- Boîte noire de complexité : la complexité de la configuration graphique augmentera à mesure que la complexité de la page de configuration augmente, et cette complexité sera visible en un coup d'œil Affiché devant d'utilisateurs, les utilisateurs peuvent se perdre dans des interactions complexes avec les pages de configuration, et les coûts de configuration augmentent progressivement
- Itération agile : si vous souhaitez ajouter une fonction de configuration de page côté utilisateur, la méthode d'interaction basée sur le grand modèle peut nécessiter seulement de nouveaux Ajoutez quelques invites, mais la configuration graphique nécessite le développement de formulaires complexes pour faciliter une saisie rapide.
Vous avez peut-être une question ici :
Les informations de commande générées ne montreraient-elles pas également l'illusion d'un grand modèle ? Comment s’assurer que les informations de commande générées à chaque fois sont stables et cohérentes ?
Traduire le langage naturel en instructions est réalisable pour les raisons suivantes :
- La conversion d'un texte long en informations clés appartient au contenu récapitulatif. La précision des grands modèles dans les scénarios récapitulatifs est bien supérieure à celle des scénarios de diffusion
- Étant donné que les informations d'instruction extraient uniquement les informations clés dans les exigences, il n'est pas nécessaire de le faire ; effectuez une pré-production sur la formation de la pile technologique de code, il y a donc beaucoup de place pour l'optimisation des invites. En optimisant et en améliorant le contenu des invites, la précision de la sortie peut être efficacement améliorée.
- La précision est vérifiable pour chaque scénario. exigences d'expression, l'exactitude peut être vérifiée via une seule sortie de prédiction de test. Lorsqu'un badCase se produit, nous accéderons au test unique du badCase après l'optimisation. Assurez-vous que la précision continue de s’améliorer.
Regardons les résultats finaux de la conversion des informations :
Pour l'assistance au code, basée sur la description de la demande de l'utilisateur, ces informations peuvent être obtenues via le traitement PROMPT. Fournissez des informations de base pour la génération de code.
 Images
Images
4. Convertir les informations en code
Après avoir obtenu les informations codables correspondant au langage naturel via le grand modèle (c'est-à-dire JSON dans l'exemple ci-dessus), nous pouvons convertir le code en fonction de ces informations. Pour une page avec un scénario clair, elle peut généralement être divisée en modèle de code principal (liste, formulaire, cadre de description) + composants métier.
Processus de conversion
 Photos
Photos
Comment développons-nous du code ?
En fait, cette étape est très similaire au développement du code nous-mêmes. Une fois que nous aurons obtenu les exigences, notre cerveau extraira les informations clés, c'est-à-dire les instructions de conversion en langage naturel mentionnées ci-dessus, puis nous créerons un fichier. dans vscode, puis les opérations suivantes seront effectuées :
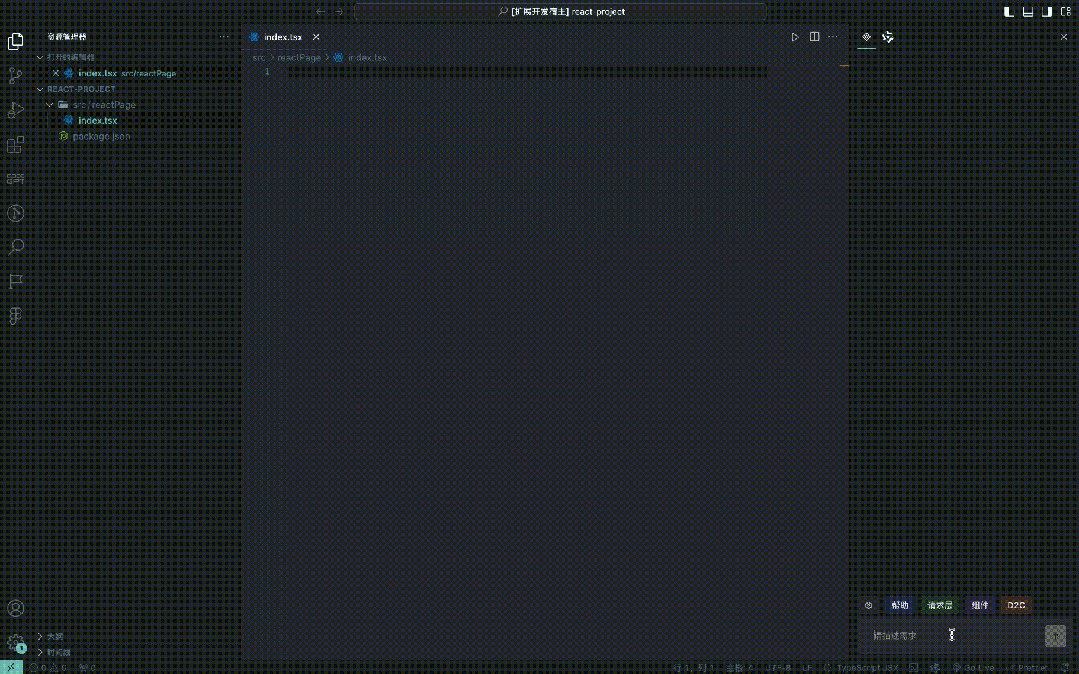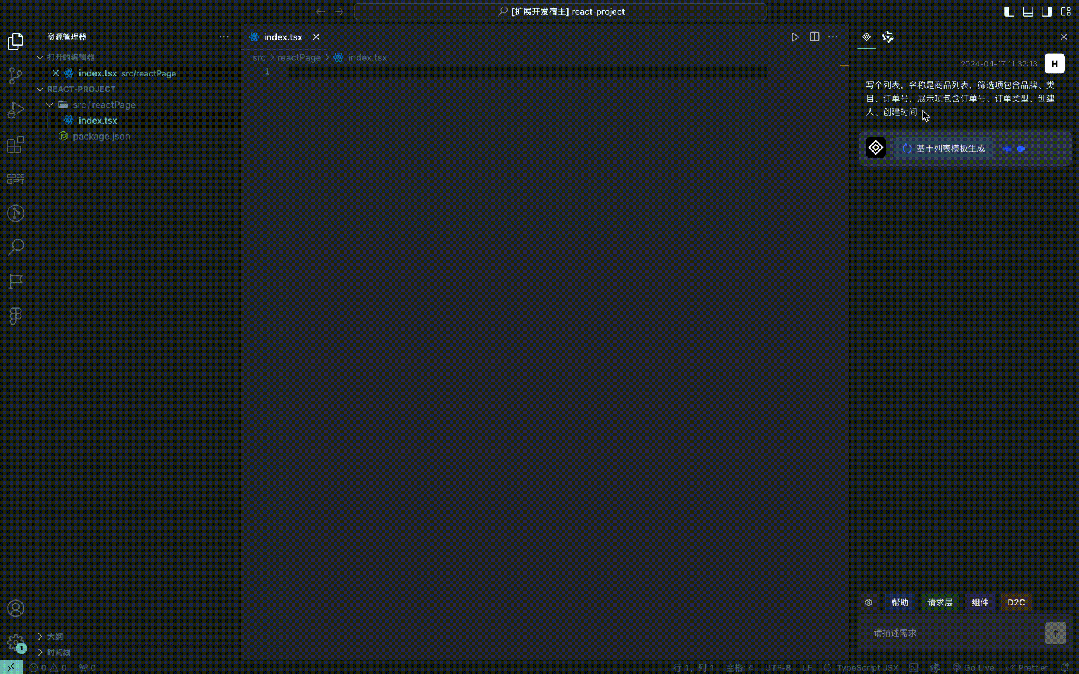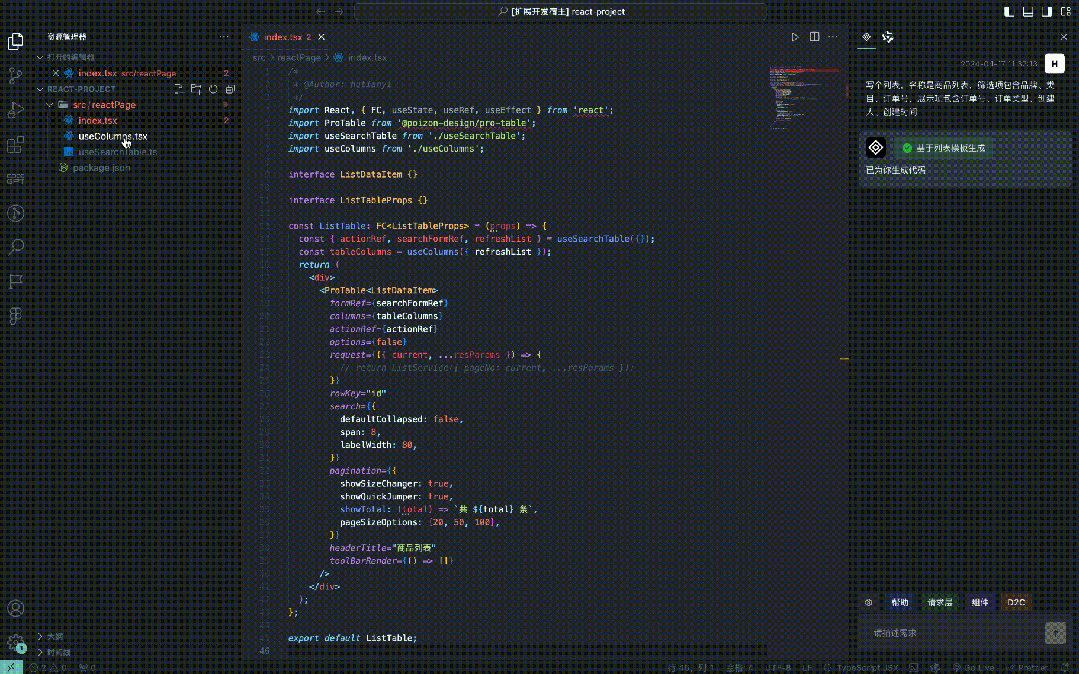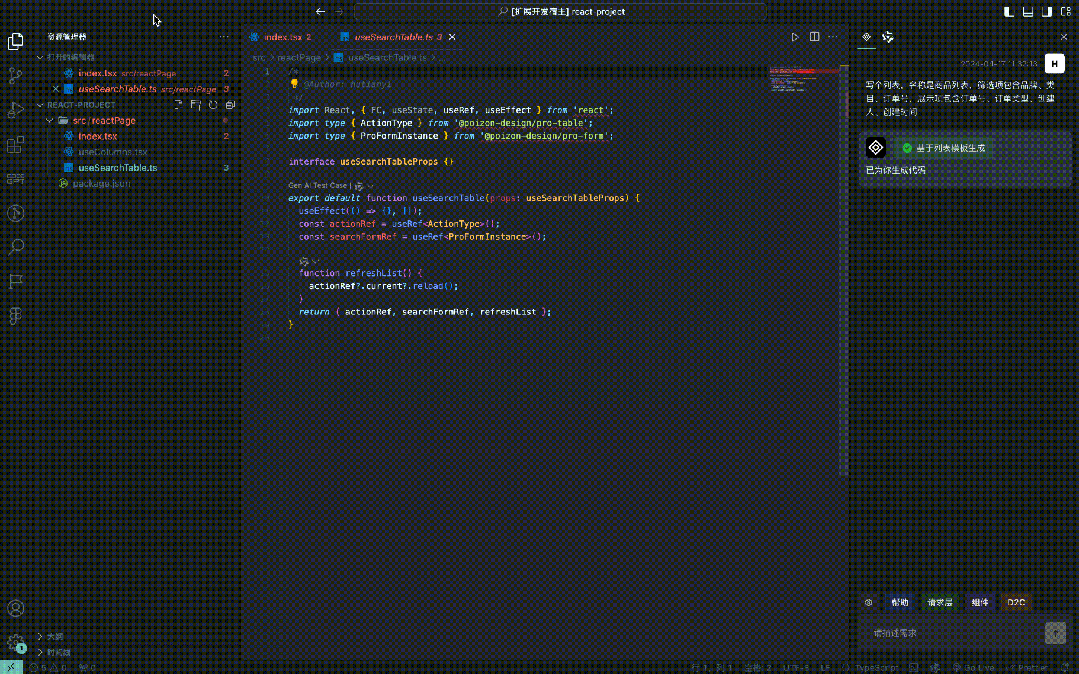
Tout d'abord, vous devez créer un modèle de code, puis introduire les composants lourds correspondants selon le scénario. Par exemple, ProTable est introduit pour les listes et ProForm est introduit pour. formes.
Basé sur des composants robustes tels que ProTable et en y ajoutant certaines propriétés, telles que headerTitle, pageSize et d'autres informations liées à la liste.
Introduisez des composants en fonction de la description de la demande. Par exemple, s'il est reconnu qu'il existe une sélection de catégorie dans l'élément de filtre, un nouveau composant métier sera ajouté dans useColumns. dans la description de la demande, un nouveau composant commercial d'importation et d'exportation sera ajouté à l'emplacement spécifié sur la page.
Obtenez le lien fictif, ajoutez une couche de requête et introduisez-la à l'emplacement spécifié sur la page.
Les scénarios d'insertion de code courants ci-dessus peuvent être encapsulés dans JSON, puis le code correspondant est généré via des modèles de code combinés avec une insertion AST ou un remplacement de modèle de chaîne.
5. Génération de code source
Positionnement
L'assistance au code source aide principalement les développeurs à réduire le travail répétitif et à améliorer l'efficacité du codage. Il s'agit d'une piste complètement différente de la construction de pages low-code. scénarios spécifiques. La page est complète et le nombre de fonctions de page est énumérable. Il existe également d'excellentes pratiques en matière de construction low-code dans l'industrie. L'outil auxiliaire de code source est conçu pour aider les utilisateurs à initialiser autant de code d'exigences commerciales que possible, et les modifications et maintenances ultérieures sont confiées aux utilisateurs au niveau du code pour améliorer l'efficacité du développement de nouvelles pages.
Voir l'architecture fonctionnelle spécifique ci-dessous :
 Images
Images
6. Recherche et intégration de vecteurs de composants
Pour le développement front-end, l'essence de l'amélioration de l'efficacité est de développer moins de code, et une génération de pages plus rapide est un aspect Une bonne extraction des composants est un élément très important. Nous avons combiné des vecteurs pour optimiser les liens d'introduction des composants, et recherché et positionné rapidement les composants dans les modèles d'initialisation et les codes de stock. Lien d'introduction du vecteur de composant données vectorielles pour le stockage Base de données vectorielles.
Images
Recherche de vecteurs de composants
Une fois que l'utilisateur a saisi la description, la description sera convertie en vecteur et comparée à la liste de composants basée sur la similarité cosinus pour trouver les composants TOP N avec le similarité la plus élevée.
Photos
Insertion rapide des composants
Les utilisateurs peuvent rechercher rapidement le composant avec le degré de correspondance le plus élevé dans le code de stock via la description et appuyer sur Entrée pour l'insérer.
 Images
Images
VII. Perspectives futures
- Modèles d'intégration de composants : actuellement, les composants prennent en charge la recherche vectorielle, générée en combinant des pages de code source, prenant en charge la correspondance dynamique des composants et des modèles d'intégration ;
- Modification et génération de code stock : actuellement uniquement ; pris en charge La génération de code source de nouvelles pages sera prise en charge à l'avenir, et l'ajout partiel de code de pages existantes sera pris en charge à l'avenir
- Pipeline de modèles de code : les outils d'exploitation de code d'AST connectent davantage le langage naturel et l'écriture de code, améliorant ainsi la fonctionnalité. efficacité de l'expansion de la scène.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment définir VScode
Apr 15, 2025 pm 10:45 PM
Comment définir VScode
Apr 15, 2025 pm 10:45 PM
Pour activer et définir VScode, suivez ces étapes: installer et démarrer VScode. Préférences personnalisées, y compris les thèmes, les polices, les espaces et le formatage de code. Installez des extensions pour améliorer les fonctionnalités telles que les plugins, les thèmes et les outils. Créer un projet ou ouvrir un projet existant. Utilisez Intellisense pour obtenir des invites de code et des achèvements. Déboguez le code pour parcourir le code, définir des points d'arrêt et vérifier les variables. Connectez le système de contrôle de version pour gérer les modifications et commettre du code.
 VSCODE Précédent la touche de raccourci suivante
Apr 15, 2025 pm 10:51 PM
VSCODE Précédent la touche de raccourci suivante
Apr 15, 2025 pm 10:51 PM
VS CODE Utilisation de la clé de raccourci en une étape / prochaine: une étape (arrière): Windows / Linux: Ctrl ←; macOS: cmd ← Étape suivante (vers l'avant): Windows / Linux: Ctrl →; macOS: CMD →
 Quelle langue VScode est utilisée
Apr 15, 2025 pm 11:03 PM
Quelle langue VScode est utilisée
Apr 15, 2025 pm 11:03 PM
Visual Studio Code (VSCOD) est développé par Microsoft, construit à l'aide du cadre Electron, et est principalement écrit en JavaScript. Il prend en charge un large éventail de langages de programmation, notamment JavaScript, Python, C, Java, HTML, CSS, etc., et peut ajouter une prise en charge d'autres langues à travers des extensions.
 Quelle langue est écrite dans vscode
Apr 15, 2025 pm 11:51 PM
Quelle langue est écrite dans vscode
Apr 15, 2025 pm 11:51 PM
VScode est écrit en dactylographie et javascript. Tout d'abord, sa base de code principale est écrite en TypeScript, un langage de programmation open source qui étend JavaScript et ajoute des capacités de vérification de type. Deuxièmement, certaines extensions et plug-ins de VScode sont écrits en JavaScript. Cette combinaison fait de VScode un éditeur de code flexible et extensible.
 Tutoriel chinois de réglage VScode
Apr 15, 2025 pm 11:45 PM
Tutoriel chinois de réglage VScode
Apr 15, 2025 pm 11:45 PM
VS Code prend en charge les paramètres chinois, qui peuvent être complétés en suivant les étapes: ouvrez le panneau des paramètres et recherchez "Locale". Définissez "Langale.Language" sur "ZH-CN" (chinois simplifié) ou "ZH-TW" (chinois traditionnel). Enregistrer les paramètres et redémarrer le code. Le menu des paramètres, la barre d'outils, les invites de code et les documents seront affichés en chinois. D'autres paramètres linguistiques peuvent également être personnalisés, tels que le format de balise de fichier, la description de l'entrée et le langage du processus de diagnostic.
 Comment changer le mode chinois avec VScode
Apr 15, 2025 pm 11:39 PM
Comment changer le mode chinois avec VScode
Apr 15, 2025 pm 11:39 PM
VS Code pour changer le mode chinois: ouvrez l'interface des paramètres (Windows / Linux: Ctrl, macOS: CMD,) Recherchez des paramètres "Editor: Language" Sélectionnez "Chine
 Quelle est la différence entre VScode et PyCharm
Apr 15, 2025 pm 11:54 PM
Quelle est la différence entre VScode et PyCharm
Apr 15, 2025 pm 11:54 PM
Les principales différences entre le code VS et PyCharm sont: 1. Extensibilité: le code vs est très évolutif et dispose d'un riche marché de plug-in, tandis que PyCharm a des fonctions plus larges par défaut; 2. Prix: VS Code est gratuit et open source, et PyCharm est payé pour la version professionnelle; 3. Interface utilisateur: le code vs est moderne et convivial, et PyCharm est plus complexe; 4. Navigation du code: VS Code convient aux petits projets, et PyCharm convient plus aux grands projets; 5. Débogage: VS Code est basique et PyCharm est plus puissant; 6. Refactorisation de code: VS Code est basique et PyCharm est plus riche; 7. Code
 Comment taper plusieurs lignes de commentaires dans VSCODE
Apr 15, 2025 pm 11:57 PM
Comment taper plusieurs lignes de commentaires dans VSCODE
Apr 15, 2025 pm 11:57 PM
VS Code Les méthodes de commentaires multi-lignes sont: 1. Clés de raccourci (CTRL K C ou CMD K C); 2. Ajouter manuellement les symboles de commentaires (/ /); 3. Sélectionnez le menu ("Block de commentaire"); 4. Utiliser les extensions; 5. Commentaires récursifs (/ * /) et bloquer les commentaires ({/ et /}). Les commentaires multi-lignes aident à améliorer la lisibilité et la maintenabilité du code, mais la surutilisation doit être évitée.
