
 développement back-end
C++
Comment optimiser les performances des fonctions en programmation C++ ?
développement back-end
C++
Comment optimiser les performances des fonctions en programmation C++ ?
Comment optimiser les performances des fonctions en programmation C++ ?

Les performances des fonctions peuvent être optimisées grâce à diverses technologies, notamment : 1. Gestion de la mémoire, en utilisant des pools de mémoire et des pointeurs intelligents pour gérer les cycles de vie des objets ; 2. Sélection des types de conteneurs appropriés pour optimiser le temps d'accès à la mémoire ; temps d'exécution ; 4. L'optimisation du code évite les boucles et branches inutiles et extrait le code en double ; 5. Utilisez le code d'assemblage en ligne pour optimiser les éléments clés ;

Optimisation des performances des fonctions dans la programmation C++
Dans la programmation C++, l'optimisation des performances des fonctions peut améliorer considérablement les performances globales de l'application. Les fonctions peuvent être optimisées grâce à diverses techniques, notamment :
Gestion de la mémoire
- Utilisez un pool de mémoire pour allouer et libérer des objets de mémoire afin d'éviter des opérations fréquentes d'allocation et de désallocation de tas.
- Utilisez des pointeurs intelligents (par exemple std::unique_ptr, std::shared_ptr) pour gérer le cycle de vie des objets et garantir qu'ils sont automatiquement libérés lorsqu'ils ne sont plus nécessaires.
Structures de données
- Choisissez les types de conteneurs appropriés (par exemple, vecteur, liste chaînée, ensemble) pour optimiser le temps d'accès à la mémoire en fonction des modèles d'accès aux données.
- Utilisez des blocs de mémoire pré-alloués pour éviter les problèmes de performances causés par des réallocations fréquentes.
Algorithme
- Utilisez des algorithmes efficaces, tels que le tri rapide et la recherche binaire, pour réduire le temps d'exécution des fonctions.
- Envisagez d'utiliser la mise en cache ou d'autres stratégies d'optimisation pour accélérer l'accès aux données fréquemment consultées.
Optimisation du code
- Évitez les boucles et les branches inutiles.
- Extraire le code en double pour la même fonctionnalité dans des fonctions distinctes.
- Utilisez le code d'assemblage en ligne pour optimiser les pièces critiques.
Exemple pratique
Considérons la fonction C++ suivante, qui est utilisée pour calculer la somme d'une liste de nombres :
1 2 3 4 5 6 7 |
|
Pour optimiser cette fonction, nous pouvons utiliser des pools de mémoire et des caches :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
|
Cette version optimisée utilise un pool de mémoire pour allouer la somme. Libère la liste des nombres, réduisant ainsi la surcharge d'allocation et de désallocation du tas. Il utilise également un cache pour stocker la liste des nombres, évitant ainsi d'avoir à parcourir la liste entière à chaque fois qu'elle est additionnée. Avec ces optimisations, les performances de cette fonction peuvent être considérablement améliorées.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.
Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment implémenter le Strategy Design Pattern en C++ ?
Jun 06, 2024 pm 04:16 PM
Comment implémenter le Strategy Design Pattern en C++ ?
Jun 06, 2024 pm 04:16 PM
Les étapes pour implémenter le modèle de stratégie en C++ sont les suivantes : définir l'interface de stratégie et déclarer les méthodes qui doivent être exécutées. Créez des classes de stratégie spécifiques, implémentez l'interface respectivement et fournissez différents algorithmes. Utilisez une classe de contexte pour contenir une référence à une classe de stratégie concrète et effectuer des opérations via celle-ci.
 Comment implémenter la gestion des exceptions imbriquées en C++ ?
Jun 05, 2024 pm 09:15 PM
Comment implémenter la gestion des exceptions imbriquées en C++ ?
Jun 05, 2024 pm 09:15 PM
La gestion des exceptions imbriquées est implémentée en C++ via des blocs try-catch imbriqués, permettant de déclencher de nouvelles exceptions dans le gestionnaire d'exceptions. Les étapes try-catch imbriquées sont les suivantes : 1. Le bloc try-catch externe gère toutes les exceptions, y compris celles levées par le gestionnaire d'exceptions interne. 2. Le bloc try-catch interne gère des types spécifiques d'exceptions, et si une exception hors de portée se produit, le contrôle est confié au gestionnaire d'exceptions externe.
 Comment utiliser l'héritage de modèles C++ ?
Jun 06, 2024 am 10:33 AM
Comment utiliser l'héritage de modèles C++ ?
Jun 06, 2024 am 10:33 AM
L'héritage de modèle C++ permet aux classes dérivées d'un modèle de réutiliser le code et les fonctionnalités du modèle de classe de base, ce qui convient à la création de classes avec la même logique de base mais des comportements spécifiques différents. La syntaxe d'héritage du modèle est : templateclassDerived:publicBase{}. Exemple : templateclassBase{};templateclassDerived:publicBase{};. Cas pratique : création de la classe dérivée Derived, héritage de la fonction de comptage de la classe de base Base et ajout de la méthode printCount pour imprimer le décompte actuel.
 Pourquoi Bittensor est-il le 'Bitcoin' sur la piste AI?
Mar 04, 2025 pm 04:06 PM
Pourquoi Bittensor est-il le 'Bitcoin' sur la piste AI?
Mar 04, 2025 pm 04:06 PM
Titre original: Bittensor = Aibitcoin? Bittensor adopte un modèle de sous-réseau qui permet l'émergence de différentes solutions d'IA et inspire l'innovation à travers les jetons Tao. Bien que le marché de l'IA soit mûr, Bittensor fait face à des risques concurrentiels et peut être soumis à d'autres open source
 Comment gérer les exceptions C++ cross-thread ?
Jun 06, 2024 am 10:44 AM
Comment gérer les exceptions C++ cross-thread ?
Jun 06, 2024 am 10:44 AM
En C++ multithread, la gestion des exceptions est implémentée via les mécanismes std::promise et std::future : utilisez l'objet promise pour enregistrer l'exception dans le thread qui lève l'exception. Utilisez un objet futur pour rechercher des exceptions dans le thread qui reçoit l'exception. Des cas pratiques montrent comment utiliser les promesses et les contrats à terme pour détecter et gérer les exceptions dans différents threads.
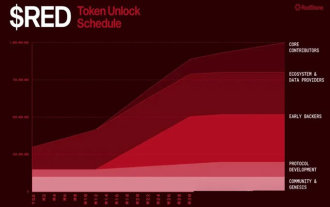 64e numéro LaunchPool Modular Oracle: Red Project Analysis & amp;
Mar 04, 2025 am 08:12 AM
64e numéro LaunchPool Modular Oracle: Red Project Analysis & amp;
Mar 04, 2025 am 08:12 AM
Analyse approfondie du 64e numéro de Launchpool Project Red: Modular Oracle Prospects and Currency Prix Prédictions Cet article analyse profondément le 64e numéro de Launchpool Project Red - un projet oracle multi-chaîne à travers les chaînes EVM et non EVM, et fait des estimations raisonnables des principes fondamentaux du projet et des prix des devises. Le projet Red a été lancé pendant seulement 2 jours, le volume total de LaunchPool étant de 40 000 000 (représentant 4% de l'offre maximale de jetons), et la circulation initiale était de 280 000 000 (représentant 28% de l'offre totale de jetons). Présentation du projet: Redstone est une blockchain modulaire oracle fondée en 2020 et incubée par la chaîne Arweave avec l'équipe d'Estonie. Prend actuellement en charge 70 chaînes
 Rapport de recherche en binance: Des défis aux opportunités, comment Desci réinvente-t-il la science?
Mar 05, 2025 pm 07:42 PM
Rapport de recherche en binance: Des défis aux opportunités, comment Desci réinvente-t-il la science?
Mar 05, 2025 pm 07:42 PM
La montée en puissance de la science décentralisée (DESCI) a apporté un nouvel espoir à la recherche scientifique. Il utilise la technologie Web3 pour résoudre de nombreux défis dans la recherche scientifique traditionnelle, en particulier le phénomène "Gao of Death" - c'est-à-dire le problème que les résultats de recherche fondamentale sont difficiles à transformer en applications pratiques. L'investissement de Pfizer à Vitadao marque la reconnaissance de la desci par les géants pharmaceutiques traditionnels. Cela nous incite à réfléchir à la façon d'utiliser desci pour remodeler le modèle commercial de la santé numérique. Le rapport de BinanceReSearch "des défis aux opportunités: comment Desci réinvente la science" explore comment Desci résout le problème "de la rattrapage de la mort". Le rapport a souligné que la recherche scientifique traditionnelle est confrontée à un financement insuffisant, à une coopération réduite entre les chercheurs et les cliniciens, et le développement scientifique
 Tendances de développement futures et technologies de pointe en programmation simultanée C++ ?
Jun 05, 2024 pm 07:02 PM
Tendances de développement futures et technologies de pointe en programmation simultanée C++ ?
Jun 05, 2024 pm 07:02 PM
Les tendances futures de la programmation simultanée C++ incluent des modèles de mémoire distribuée, qui permettent de partager la mémoire sur différentes machines ; des bibliothèques d'algorithmes parallèles, qui fournissent des algorithmes parallèles efficaces, et un calcul hétérogène, qui utilise différents types d'unités de traitement pour améliorer les performances. Plus précisément, C++20 introduit les bibliothèques std::execution et std::experimental::distributed pour prendre en charge la programmation de mémoire distribuée, C++23 devrait inclure la bibliothèque std::parallel pour fournir des algorithmes parallèles de base, et C++ Les bibliothèques AMP sont disponibles pour le calcul hétérogène. En combat réel, le cas de parallélisation de la multiplication matricielle démontre l'application de la programmation parallèle.
