
 Périphériques technologiques
IA
Ant Group et l'Université du Zhejiang lancent conjointement OneKE, un cadre d'extraction de connaissances open source à grande échelle
Périphériques technologiques
IA
Ant Group et l'Université du Zhejiang lancent conjointement OneKE, un cadre d'extraction de connaissances open source à grande échelle
Ant Group et l'Université du Zhejiang lancent conjointement OneKE, un cadre d'extraction de connaissances open source à grande échelle

Récemment, OneKE, un cadre d'extraction de connaissances à grande échelle développé conjointement par Ant Group et l'Université du Zhejiang, a été annoncé comme open source et offert à la communauté des graphes de connaissances ouverts OpenKG.
Le graphe de connaissances est l'une des technologies clés pour assurer la fiabilité et la contrôlabilité des grands modèles. L'extraction de connaissances peut aider à créer des graphiques de connaissances de domaine. OneKE s'engage à aider les chercheurs et les développeurs à mieux gérer des problèmes tels que l'extraction d'informations, la structuration des données textuelles et la construction de graphiques de connaissances.
L'extraction d'événements à risque, d'entités personnelles, d'entités institutionnelles, etc. via OneKE peut présenter clairement le contexte de l'événement, les tendances de développement des événements et les relations entre les entités. Le graphique construit peut aider les grands modèles à réaliser un raisonnement complexe entre les entités et les documents. OneKE est bilingue chinois et anglais, prend en charge les frameworks open source OpenSPG et DeepKE et peut être utilisé immédiatement.
Les grands modèles linguistiques ont considérablement amélioré la capacité des systèmes d’intelligence artificielle à traiter les connaissances du monde. Cependant, les informations du monde réel sont très fragmentées et non structurées, de sorte que lorsque de grands modèles de langage gèrent des tâches d'extraction d'informations, ils auront toujours des résultats médiocres en raison de l'énorme différence entre le contenu extrait et les expressions en langage naturel, en plus des informations textuelles en langage naturel ; Il existe de nombreuses ambiguïtés, polysémies, métaphores, etc., qui posent de plus grands défis à la tâche d'extraction des connaissances. Cela conduit également au fait que l'intelligence artificielle générative représentée par les grands modèles de langage présente toujours des problèmes tels qu'une capacité de raisonnement insuffisante, un manque de connaissances factuelles et des résultats de génération instables, ce qui entrave grandement l'industrialisation des grands modèles de langage.
Le cadre unifié d'extraction de connaissances peut réduire considérablement le coût de création de graphiques de connaissances de domaine et propose un large éventail de scénarios d'application. Cela signifie qu'en extrayant des connaissances structurées à partir de données massives, en créant des graphiques de connaissances de haute qualité et en établissant des connexions logiques entre les éléments de connaissances, des décisions de raisonnement explicables peuvent être prises, et cela peut également être utilisé pour améliorer de grands modèles afin d'atténuer les illusions et d'améliorer la stabilité. accélérer l’application de grands modèles dans les domaines verticaux.
Dans le domaine médical, la gestion des connaissances de l'expérience des médecins est réalisée grâce à l'extraction de connaissances, et des diagnostics et traitements auxiliaires contrôlables ainsi que des questions et réponses médicales sont construits. Dans le domaine financier, le service d'extraction de connaissances est utilisé pour les indicateurs financiers, les événements à risque, les relations causales, les chaînes industrielles, etc. afin de réaliser la génération automatique de rapports de recherche financière, la prévision des risques, l'analyse de la chaîne industrielle, etc. Dans les scénarios d'affaires gouvernementales, la connaissance des réglementations des affaires gouvernementales peut être réalisée pour améliorer l'efficacité et la prise de décision précise des services des affaires gouvernementales.
Pour accélérer la mise en œuvre industrielle de l'intelligence artificielle basée sur la production, Ant Group et l'Université du Zhejiang ont créé un laboratoire commun de graphes de connaissances pour se concentrer sur des sujets tels que la construction de graphes de connaissances améliorés à grande échelle, les fonctions de génération fiables et contrôlables améliorées par les connaissances, et cartes du monde des connaissances du domaine. Mener une coopération globale en vue d'établir un paradigme fonctionnel de génération contrôlable avec une amélioration bidirectionnelle des grands modèles de langage et des graphiques de connaissances grâce à des recherches techniques conjointes.
Ant Group et l'Université du Zhejiang ont établi et amélioré conjointement les capacités du grand modèle Ant Bailing dans le domaine de l'extraction de connaissances, et ont publié OneKE, un cadre d'extraction de connaissances sur grand modèle bilingue chinois-anglais, et ont open source une version basée sur LLaMA2 complète. -mise au point des paramètres. Les indicateurs de test montrent que OneKE a obtenu des résultats relativement bons sur plusieurs tâches d’extraction d’entités/relations/événements entièrement supervisées et sans échantillon.
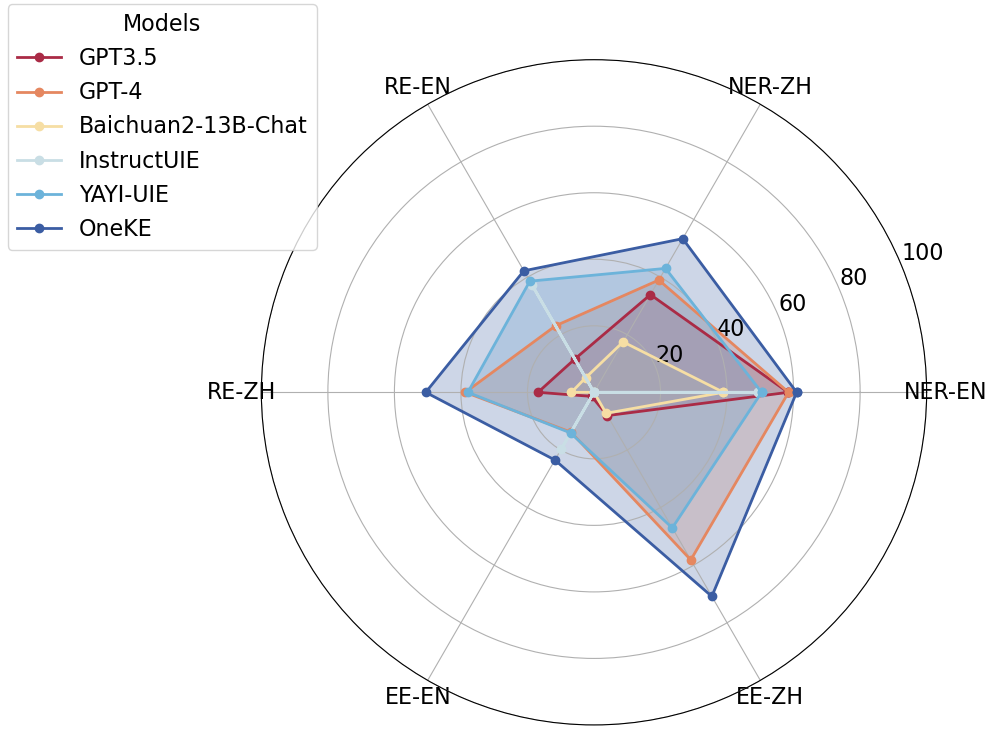
OneKE est un excellent outil d'extraction de connaissances généralisables bilingue chinois-anglais. Il a obtenu des résultats relativement bons dans les tâches de reconnaissance d'entités nommées NER chinois, les tâches d'extraction de relations RE et les tâches d'extraction d'événements EE.
Liang Lei, responsable du graphe de connaissances chez Ant Group, a déclaré qu'Ant continuera d'optimiser les performances de l'extraction des connaissances pour répondre aux besoins contrôlables et fiables des grands modèles dans différents scénarios. À l'avenir, nous travaillerons avec des partenaires industriels pour appliquer les systèmes techniques pertinents à divers domaines verticaux tels que la finance, les soins médicaux et les affaires gouvernementales, et favoriserons la mise en œuvre industrielle d'une technologie de génération contrôlable, pilotée par des graphiques de connaissances et de grands modèles de langage.
Page d'accueil officielle de OneKE : http://oneke.openkg.cn/
OpenSPG GitHub : https://github.com/OpenSPG/openspg
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
L'exécution du projet H5 nécessite les étapes suivantes: Installation des outils nécessaires tels que le serveur Web, Node.js, les outils de développement, etc. Créez un environnement de développement, créez des dossiers de projet, initialisez les projets et écrivez du code. Démarrez le serveur de développement et exécutez la commande à l'aide de la ligne de commande. Aperçu du projet dans votre navigateur et entrez l'URL du serveur de développement. Publier des projets, optimiser le code, déployer des projets et configurer la configuration du serveur Web.
 La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La page H5 doit être maintenue en continu, en raison de facteurs tels que les vulnérabilités du code, la compatibilité des navigateurs, l'optimisation des performances, les mises à jour de sécurité et les améliorations de l'expérience utilisateur. Des méthodes de maintenance efficaces comprennent l'établissement d'un système de test complet, à l'aide d'outils de contrôle de version, de surveiller régulièrement les performances de la page, de collecter les commentaires des utilisateurs et de formuler des plans de maintenance.
 Pouvez-vous apprendre à faire des pages H5 par vous-même?
Apr 06, 2025 am 06:36 AM
Pouvez-vous apprendre à faire des pages H5 par vous-même?
Apr 06, 2025 am 06:36 AM
Il est possible de l'auto-étude de la production de pages H5, mais ce n'est pas un succès rapide. Il nécessite la maîtrise de HTML, CSS et JavaScript, impliquant la conception, le développement frontal et la logique d'interaction arrière. La pratique est la clé et apprenez en terminant des tutoriels, en examinant le matériel et en participant à des projets open source. L'optimisation des performances est également importante, nécessitant une optimisation des images, la réduction des demandes HTTP et l'utilisation de cadres appropriés. La route vers l'auto-apprentissage est longue et nécessite un apprentissage et une communication continus.
 Comment afficher les résultats après le bootstrap
Apr 07, 2025 am 10:03 AM
Comment afficher les résultats après le bootstrap
Apr 07, 2025 am 10:03 AM
Étapes pour afficher les résultats de bootstrap modifiés: ouvrez le fichier HTML directement dans le navigateur pour vous assurer que le fichier bootstrap est référencé correctement. Effacer le cache du navigateur (Ctrl Shift R). Si vous utilisez CDN, vous pouvez modifier directement CSS dans l'outil de développement pour afficher les effets en temps réel. Si vous modifiez le code source bootstrap, téléchargez et remplacez le fichier local ou réacheminez la commande build à l'aide d'un outil de build tel que WebPack.
 Comment utiliser la pagination Vue
Apr 08, 2025 am 06:45 AM
Comment utiliser la pagination Vue
Apr 08, 2025 am 06:45 AM
La pagination est une technologie qui divise de grands ensembles de données en petites pages pour améliorer les performances et l'expérience utilisateur. Dans Vue, vous pouvez utiliser la méthode intégrée suivante pour la pagination: Calculez le nombre total de pages: TotalPages () Numéro de page de traversée: Directive V-FOR pour définir la page actuelle: CurrentPage Obtenez les données de la page actuelle: CurrentPagedata ()
 HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: une base de données légère et évolutive horizontalement dans Python
Apr 08, 2025 pm 06:12 PM
HaDIDB: Une base de données Python évolutive de haut niveau légère HaDIDB (HaDIDB) est une base de données légère écrite en Python, avec un niveau élevé d'évolutivité. Installez HaDIDB à l'aide de l'installation PIP: PiPinStallHaDIDB User Management Créer un utilisateur: CreateUser () pour créer un nouvel utilisateur. La méthode Authentication () authentifie l'identité de l'utilisateur. FromHadidb.OperationMportUserUser_OBJ = User ("Admin", "Admin") User_OBJ.
 Surveillez les gouttelettes MySQL et MariaDB avec Exportateur de Prometheus Mysql
Apr 08, 2025 pm 02:42 PM
Surveillez les gouttelettes MySQL et MariaDB avec Exportateur de Prometheus Mysql
Apr 08, 2025 pm 02:42 PM
Une surveillance efficace des bases de données MySQL et MARIADB est essentielle pour maintenir des performances optimales, identifier les goulots d'étranglement potentiels et assurer la fiabilité globale du système. Prometheus Mysql Exportateur est un outil puissant qui fournit des informations détaillées sur les mesures de base de données qui sont essentielles pour la gestion et le dépannage proactifs.
 Comment afficher le comportement javascript de Bootstrap
Apr 07, 2025 am 10:33 AM
Comment afficher le comportement javascript de Bootstrap
Apr 07, 2025 am 10:33 AM
La section JavaScript de Bootstrap fournit des composants interactifs qui donnent une vitalité des pages statiques. En regardant le code open source, vous pouvez comprendre comment cela fonctionne: la liaison des événements déclenche les opérations DOM et les modifications de style. L'utilisation de base comprend l'introduction de fichiers JavaScript et l'utilisation d'API, et l'utilisation avancée implique des événements personnalisés et des capacités d'extension. Les questions fréquemment posées incluent les conflits de version et les conflits de style CSS, qui peuvent être résolus en vérifiant le code. Les conseils d'optimisation des performances incluent le chargement à la demande et la compression de code. La clé pour maîtriser Bootstrap JavaScript est de comprendre ses concepts de conception, de combiner des applications pratiques et d'utiliser des outils de développement pour déboguer et explorer.
