
 Périphériques technologiques
IA
GPT Store ne peut même pas ouvrir ses portes. Comment cette plateforme nationale ose-t-elle emprunter cette voie ? ?
Périphériques technologiques
IA
GPT Store ne peut même pas ouvrir ses portes. Comment cette plateforme nationale ose-t-elle emprunter cette voie ? ?
GPT Store ne peut même pas ouvrir ses portes. Comment cette plateforme nationale ose-t-elle emprunter cette voie ? ?

Faites attention, cet homme a connecté plus de 1 000 grands modèles, vous permettant de brancher et de commuter en toute transparence.
Le workflow Visual AI a également été lancé récemment :
vous offre une interface intuitive de glisser-déposer. Faites glisser, tirez et faites glisser pour organiser votre propre flux de travail sur un canevas infini.
Comme le dit le vieil adage, la guerre coûte cher, et Qubit a appris que dans les 48 heures suivant la mise en ligne de ce workflow d'IA, les utilisateurs avaient déjà configuré des workflows personnels avec plus de 100 nœuds.
Sans être trop prétentieux, je souhaite aujourd'hui parler de la société LLMOps Dify et de son PDG Zhang Luyu.
Zhang Luyu est également le fondateur de Dify.
Avant de démarrer une entreprise, il avait 11 ans d'expérience dans l'industrie Internet. Je suis engagé dans la conception de produits, je comprends la gestion de projet et j'ai des connaissances uniques sur le SaaS.
Plus tard, il a également été responsable de la gestion des produits et des opérations au sein de l'équipe Tencent Cloud CODING DevOps, au service des produits de plateforme pour plus d'un million d'utilisateurs développeurs.
Après avoir démarré son entreprise, Dify a rapidement travaillé avec lui et son équipe pour devenir le leader absolu dans le domaine de la « plateforme de développement d'applications open source LLM », avec plus de 22 000 étoiles sur GitHub à ce jour.

Cette fois, avec l'aide de la nouvelle fonction AI Workflow, nous avons spécifiquement trouvé Zhang Luyu et discuté avec l'homme qui a aidé 200 000 applications d'IA à se connecter à de grands modèles.
Il a déclaré :
L'avenir de la programmation pourrait être la programmation de flux.
Glissez-déposez pour compléter les paramètres du flux de travail
Il n'y a pas si longtemps, le gourou de l'IA Andrew Ng a exprimé une opinion qui a suscité de nombreuses discussions. Il a affirmé que le flux de travail des agents IA entraînerait d'énormes progrès dans le domaine de l'intelligence artificielle cette année, dépassant peut-être même la prochaine génération de modèles de base.
Andrew Ng considère le workflow comme une tendance importante et appelle toutes les personnes travaillant dans le domaine de l'IA à y prêter attention.
Donc, Dify a profité du fer chaud et a lancé le workflow de l'IA. (Mais en fait, Dify a vu cette opportunité il y a six mois, dont nous parlerons plus tard.)
Après son lancement officiel, il appartient à tante Jiang :
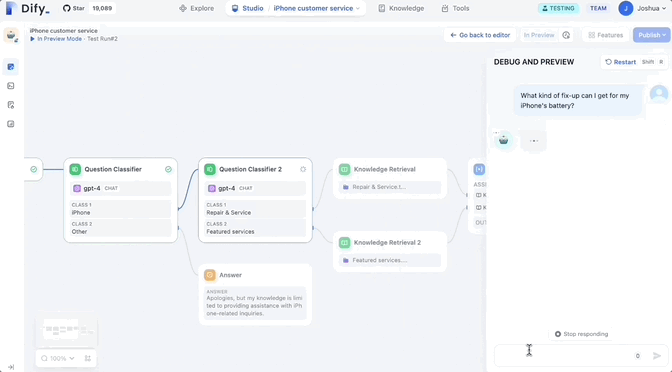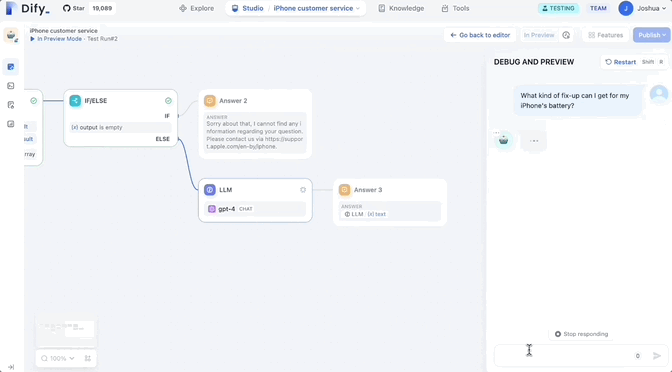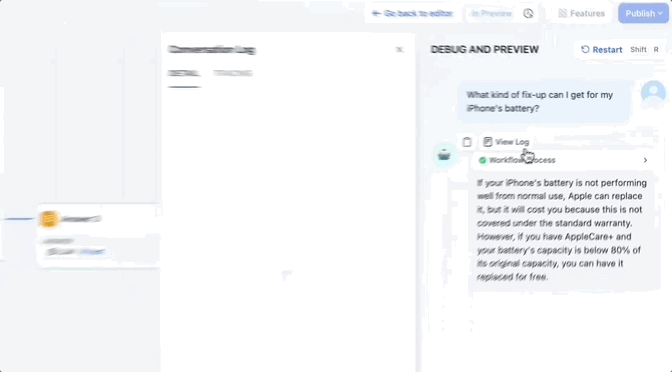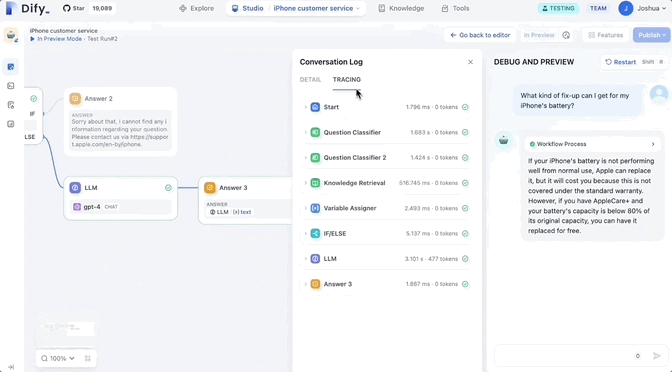
Le cœur est une interface intuitive par glisser-déposer.

Les utilisateurs peuvent créer leur propre workflow sur un canevas infini en connectant différents nœuds.
C'est vrai, c'est un "canevas infini" - la version actuelle permet l'expansion continue des types de nœuds disponibles, et chaque nœud est configurable. Les utilisateurs peuvent définir l'entrée et la sortie pour chaque nœud afin de garantir que la logique de travail et le flux de travail. le flux de données est conforme aux attentes.
En d’autres termes, vous pouvez tester vos Workflows de bout en bout, ou vous pouvez tester chaque nœud individuellement pour localiser rapidement le problème.
Il convient de noter que certains nœuds principaux sont pris en charge en premier, notamment :
- LLM : choisissez n'importe quel modèle de langage grand public à grande échelle et définissez ses entrées et sorties
- Outils : utilisez la définition intégrée et automatique des outils pour étendre les capacités de votre flux de travail.
- Intent Classifier : laissez LLM classer automatiquement les entrées de l'utilisateur et effectuer le flux de travail selon différentes catégories.
- Récupération de connaissances : attachez des données contextuelles à partir de bases de connaissances existantes à vos LLM.
- Code : Exécutez du code Python ou Node.js personnalisé.
- If/Else Block : définissez une logique conditionnelle pour créer des workflows ramifiés.
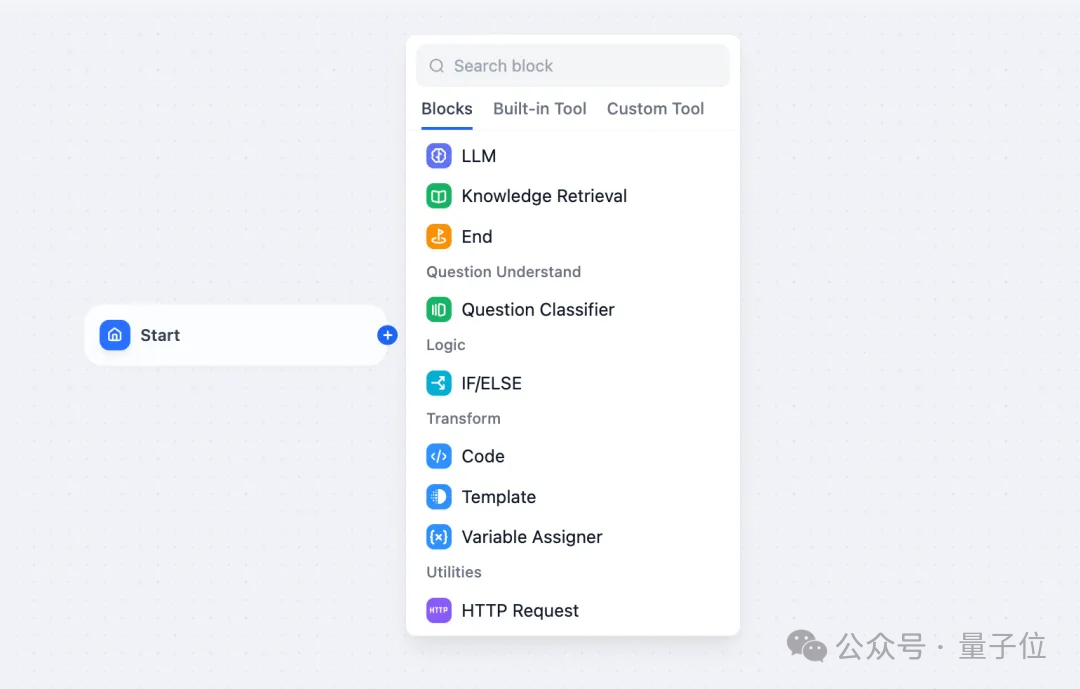
De plus, le flux de travail de l'IA prend en charge l'importation et l'exportation DSL, que Zhang Luyu a qualifié de « l'une des fonctionnalités les plus intéressantes ».
En termes simples, les utilisateurs peuvent exporter leurs propres flux de travail, puis les importer dans d'autres espaces de travail, laissant les flux de travail aller et venir librement, tout en les personnalisant à nouveau si nécessaire.
Cette fonctionnalité ouvre une fenêtre de collaboration, de partage et de développement du travail des autres au sein de la communauté.
Et toutes les capacités de la plateforme Dify peuvent être utilisées dans le workflow. L'utilisateur a mis en place une base de connaissances de solutions de recherche, d'outils riches de première partie fournis par la plateforme, d'outils personnalisés, etc., qui peut être orchestré comme l'une des capacités du nœud.
On peut dire qu'il s'adapte parfaitement à l'écosystème Dify.
Le seuil ne sera pas abaissé à un niveau infiniment bas
Après le lancement d'AI Workflow, Dify dispose de deux modes d'application.
L’un est Workflow et l’autre est Chatflow traditionnel.
"La grande majorité des utilisateurs utiliseront le type Chatbot traditionnel, qui n'a aucune logique complexe et repose essentiellement sur l'auto-fonctionnement du grand modèle connecté. Zhang Luyu a expliqué qu'en comparaison, le Workflow sera bien plus." puissant, mais cela ne signifie pas que vous ne pouvez pas utiliser Workflow pour créer un chatbot. Il est désormais clair que bien que « workflow » soit traduit par workflow, il représente en réalité le mécanisme de fonctionnement derrière Dify.
La raison pour laquelle Dify a évolué dans une telle direction est que l'équipe a sa propre « croyance ».
Nous pensons que la programmation du futur pourrait être un(travail)flow.
Il est entendu que le prochain plan de Dify est de lancer le pipeline de RAG et le paradigme collaboratif de l'invite.
Alors, quels groupes Dify, qui se corrige constamment, considère-t-il comme ses utilisateurs et utilisateurs potentiels ?
« En supposant qu'il y ait 10 millions de développeurs en Chine, 500 000 d'entre eux ont désormais la capacité de créer et d'influencer les autres. Les grands modèles ont un attrait naturel pour eux ; sont précieux, conservables, peuvent être entièrement produits et possèdent de riches compétences dans leur propre secteur ou compétences - Zhang Luyu "définit" le principal groupe d'utilisateurs du service Dify et le qualifie de "réel". Nous considérons les développeurs professionnels comme des innovateurs créatifs. "
Ce groupe ne représente pas plus de 10 % de la population totale.
Ainsi, Zhang Luyu a également avoué que ce que DIfy a fait, c'est d'abaisser le seuil d'utilisation des outils, mais le seuil ne sera pas si bas qu'il sera inexistant.
Dify ne réduira pas le seuil d'utilisation à zéro.
Nous avons également parlé du choix de l'heure de lancement de la fonction.
Dify a lancé AI Workflow pas trop tôt Depuis le second semestre de l'année dernière, profitant de la popularité du concept Agent, de nombreuses startups ont déjà lancé des fonctions similaires.
Mais Dify a déclaré qu'il s'agissait cette fois d'un choix proactif. Avant le lancement de GPT, l'équipe avait un aperçu des opportunités de Workflow.
Nous voulons observer la dynamique du côté modèle et du côté produit, mais aussi fournir des capacités complètes et ne pas mener des batailles non préparées. "En fait, nous avons
délibérément ralenti le rythme
Etant issu d'un grand." fabricant, "Mais je suis un rebelle."Dify a son propre rythme, qui a probablement quelque chose à voir avec l'évaluation par l'équipe de ses propres compétences.
Quand on lui a demandé s'il s'inquiétait du sort des grands fabricants qui pressaient l'espace du marché, la réponse qu'il a obtenue a été trois mots positifs : pas peur.
Leurs raisons sont les suivantes :
Une fois arrivés
, la concurrence sur le marché ne semble pas si urgente et féroce. Lors de la création de Dify en mai de l'année dernière, l'équipe fondatrice de base craignait d'entrer sur le marché trop tard et craignait qu'une équipe ne prenne le dessus. "Mais le fait est qu'aucune autre équipe ne l'a fait."
Deuxièmement
, les grands fabricants choisissent souvent de parier parce qu'ils voient une telle opportunité sur le marché et sont motivés par l'offre ; Dify stimule la R&D parce qu'il voit une réelle demande. Non seulement il n'a pas peur des grands constructeurs, mais Dify n'a pas non plus peur de la puissance des startups similaires. Zhang Luyu a déclaré que même s'il y a de nombreux entrepreneurs dans la vague actuelle, la plupart d'entre eux appartiennent encore à la vague d'entrepreneurs d'il y a dix ans. Les étiquettes apposées sur ce groupe de personnes indiquent qu'ils ont pratiqué à Dachang.
"Tout en étant étiquetés comme ayant de l'expérience dans une grande usine, le processus d'écriture compliqué entre les départements d'une grande usine est également devenu un modèle de réflexion inhérent pour ces personnes."
Zhang Luyu, qui a également passé du temps dans une grande usine, se qualifie de "grande usine" "Rebelle", affichant sa déviance -
Je n'appartiens pas à la catégorie(contraint par la pensée)
. Mon premier emploi était comme ingénieur dans une grande société de jeux vidéo quand j'avais 21 ans. À cette époque, tant que je jugeais que ce que je faisais était précieux et que le produit était très bon, j'ignorais tous les processus et mettais le produit en ligne, ce qu'on appelle le lancement clandestin.C'est illégal dans de nombreuses entreprises, mais je dois le faire. pourquoi ? Si je suis le processus, cela ne fonctionnera peut-être pas ; mais lorsque je le mets en ligne, la valeur apportée par l'expérience utilisateur est significative.C'est la même chose que démarrer une entreprise, il faut accepter les risques.
Démarrer une entreprise est risqué et vous devez être prudent de votre côté. Heureusement, il y a certaines choses qui rendent Zhang Luyu heureux.
Il a déclaré que la chose la plus excitante de l'année écoulée est que tant de jeunes affluent dans cette industrie et qu'il existe d'innombrables nouveaux diplômés des meilleures écoles qui sont prêts à rejoindre l'industrie.
Ce groupe de personnes ne manque pas de bonnes opportunités. Après avoir obtenu leur diplôme, ils peuvent facilement obtenir des postes de haut niveau dans des entreprises Fortune 500 ou dans de grandes usines, mais ils sont désormais prêts à dépenser très peu d'argent pour faire des choses liées aux grands modèles.
"Dans le passé, il était difficile pour nous de recruter de telles personnes. Nous ne savions même pas où trouver de tels CV, encore moins les persuader de nous rejoindre
"Il y a de telles personnes dans notre entreprise A." " "Déjà au moins 1/3 ? Mais je pense que ce ratio n'est pas assez élevé. Ces personnes devraient devenir notre force principale.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Cet article expliquera comment améliorer les performances du site Web en analysant les journaux Apache dans le système Debian. 1. Bases de l'analyse du journal APACH LOG enregistre les informations détaillées de toutes les demandes HTTP, y compris l'adresse IP, l'horodatage, l'URL de la demande, la méthode HTTP et le code de réponse. Dans Debian Systems, ces journaux sont généralement situés dans les répertoires /var/log/apache2/access.log et /var/log/apache2/error.log. Comprendre la structure du journal est la première étape d'une analyse efficace. 2.
 Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python: jeux, GUIS, et plus
Apr 13, 2025 am 12:14 AM
Python excelle dans les jeux et le développement de l'interface graphique. 1) Le développement de jeux utilise Pygame, fournissant des fonctions de dessin, audio et d'autres fonctions, qui conviennent à la création de jeux 2D. 2) Le développement de l'interface graphique peut choisir Tkinter ou Pyqt. Tkinter est simple et facile à utiliser, PYQT a des fonctions riches et convient au développement professionnel.
 Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Comment configurer le format de journal debian Apache
Apr 12, 2025 pm 11:30 PM
Cet article décrit comment personnaliser le format de journal d'Apache sur les systèmes Debian. Les étapes suivantes vous guideront à travers le processus de configuration: Étape 1: Accédez au fichier de configuration Apache Le fichier de configuration apache principal du système Debian est généralement situé dans /etc/apache2/apache2.conf ou /etc/apache2/httpd.conf. Ouvrez le fichier de configuration avec les autorisations racinaires à l'aide de la commande suivante: sudonano / etc / apache2 / apache2.conf ou sudonano / etc / apache2 / httpd.conf Étape 2: définir les formats de journal personnalisés à trouver ou
 Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Comment les journaux Tomcat aident à dépanner les fuites de mémoire
Apr 12, 2025 pm 11:42 PM
Les journaux TomCat sont la clé pour diagnostiquer les problèmes de fuite de mémoire. En analysant les journaux TomCat, vous pouvez avoir un aperçu de l'utilisation de la mémoire et du comportement de collecte des ordures (GC), localiser et résoudre efficacement les fuites de mémoire. Voici comment dépanner les fuites de mémoire à l'aide des journaux Tomcat: 1. Analyse des journaux GC d'abord, activez d'abord la journalisation GC détaillée. Ajoutez les options JVM suivantes aux paramètres de démarrage TomCat: -xx: printgcdetails-xx: printgcdatestamps-xloggc: gc.log Ces paramètres généreront un journal GC détaillé (GC.Log), y compris des informations telles que le type GC, la taille et le temps des objets de recyclage. Analyse GC.Log
 Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Le rôle de Debian Sniffer dans la détection des attaques DDOS
Apr 12, 2025 pm 10:42 PM
Cet article traite de la méthode de détection d'attaque DDOS. Bien qu'aucun cas d'application directe de "Debiansniffer" n'ait été trouvé, les méthodes suivantes ne peuvent être utilisées pour la détection des attaques DDOS: technologie de détection d'attaque DDOS efficace: détection basée sur l'analyse du trafic: identification des attaques DDOS en surveillant des modèles anormaux de trafic réseau, tels que la croissance soudaine du trafic, une surtension dans des connexions sur des ports spécifiques, etc. Par exemple, les scripts Python combinés avec les bibliothèques Pyshark et Colorama peuvent surveiller le trafic réseau en temps réel et émettre des alertes. Détection basée sur l'analyse statistique: en analysant les caractéristiques statistiques du trafic réseau, telles que les données
 Certificat NGINX SSL Mise à jour du tutoriel Debian
Apr 13, 2025 am 07:21 AM
Certificat NGINX SSL Mise à jour du tutoriel Debian
Apr 13, 2025 am 07:21 AM
Cet article vous guidera sur la façon de mettre à jour votre certificat NGINXSSL sur votre système Debian. Étape 1: Installez d'abord CERTBOT, assurez-vous que votre système a des packages CERTBOT et Python3-CERTBOT-NGINX installés. Si ce n'est pas installé, veuillez exécuter la commande suivante: Sudoapt-getUpDaSuDoapt-GetInstallCertBotpyThon3-Certerbot-Nginx Étape 2: Obtenez et configurez le certificat Utilisez la commande Certbot pour obtenir le certificat LETSCRYPT et configure
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Comment surveiller les performances de Nginx SSL sur Debian
Apr 12, 2025 pm 10:18 PM
Cet article décrit comment surveiller efficacement les performances SSL des serveurs Nginx sur les systèmes Debian. Nous utiliserons NginxExporter pour exporter des données d'état NGINX à Prometheus, puis l'afficher visuellement via Grafana. Étape 1: Configuration de Nginx Tout d'abord, nous devons activer le module Stub_Status dans le fichier de configuration NGINX pour obtenir les informations d'état de Nginx. Ajoutez l'extrait suivant dans votre fichier de configuration Nginx (généralement situé dans /etc/nginx/nginx.conf ou son fichier incluant): emplacement / nginx_status {Stub_status
