
 Périphériques technologiques
IA
Article très bien noté CVPR 2024 : Nouveau cadre d'édition générative GenN2N, unifiant les tâches de conversion NeRF
Périphériques technologiques
IA
Article très bien noté CVPR 2024 : Nouveau cadre d'édition générative GenN2N, unifiant les tâches de conversion NeRF
Article très bien noté CVPR 2024 : Nouveau cadre d'édition générative GenN2N, unifiant les tâches de conversion NeRF


La rubrique AIxiv de notre site Web est une rubrique sur le contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de notre site Web a reçu plus de 2 000 contenus, couvrant les meilleurs laboratoires de grandes universités et entreprises du monde entier, contribuant ainsi à promouvoir les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. L'adresse e-mail de soumission est liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com.


Adresse papier : https://arxiv.org/abs/2404.02788 Page d'accueil papier : https://xiangyueliu.github.io/GenN2N/ Git Adresse du hub : https://github.com/Lxiangyue/GenN2N Titre de l'article : GenN2N : Generative NeRF2NeRF Translation
Dans la partie centrale de GenN2N, 1) le cadre génératif de 3D VAE-GAN est introduit, en utilisant VAE pour représenter l'ensemble de l'espace d'édition afin d'apprendre toutes les distributions d'édition NeRF 3D possibles correspondant à un ensemble d'images d'édition 2D d'entrée , et utilisez GAN pour fournir une supervision raisonnable pour l'édition de différentes vues de NeRF afin de garantir l'authenticité des résultats de l'édition 2) Utiliser l'apprentissage contrastif pour découpler le contenu d'édition et les perspectives afin de garantir la cohérence de l'édition du contenu entre les différentes perspectives 3) Pendant l'inférence. , l'utilisateur échantillonne simplement au hasard plusieurs codes d'édition à partir du modèle de génération conditionnelle peut générer divers résultats d'édition 3D correspondant à la cible d'édition.
Par rapport aux méthodes SOTA pour diverses tâches d'édition NeRF (ICCV2023 Oral, etc.), GenN2N est supérieure aux méthodes existantes en termes de qualité d'édition, de diversité, d'efficacité, etc.
Nous effectuons d'abord l'édition d'images 2D, puis mettons à niveau ces modifications 2D vers NeRF 3D pour obtenir une conversion générative NeRF en NeRF.
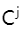 (échantillon négatif) ou l'image modifiée
(échantillon négatif) ou l'image modifiée 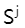 (échantillon positif) dans les données d'entraînement, nous sélectionnons une image modifiée
(échantillon positif) dans les données d'entraînement, nous sélectionnons une image modifiée 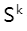 de la même perspective à partir des données d'entraînement comme condition, ce qui empêche le Le discriminateur n'est pas gêné par des facteurs de perspective lors de la distinction des échantillons positifs et négatifs.
de la même perspective à partir des données d'entraînement comme condition, ce qui empêche le Le discriminateur n'est pas gêné par des facteurs de perspective lors de la distinction des échantillons positifs et négatifs.  B
B  Expériences de comparaison
Expériences de comparaison  Notre méthode est comparée qualitativement et quantitativement à SO. Méthodes TA pour diverses tâches NeRF spécifiques ( y compris l'édition basée sur le texte, la colorisation, la super-résolution et l'inpainting, etc.). Les résultats montrent que GenN2N, en tant que cadre général, fonctionne aussi bien ou mieux que SOTA spécifique à une tâche, tandis que les résultats d'édition ont une plus grande diversité (ce qui suit est une comparaison entre GenN2N et Instruct-NeRF2NeRF sur la tâche d'édition NeRF basée sur du texte. ).
Notre méthode est comparée qualitativement et quantitativement à SO. Méthodes TA pour diverses tâches NeRF spécifiques ( y compris l'édition basée sur le texte, la colorisation, la super-résolution et l'inpainting, etc.). Les résultats montrent que GenN2N, en tant que cadre général, fonctionne aussi bien ou mieux que SOTA spécifique à une tâche, tandis que les résultats d'édition ont une plus grande diversité (ce qui suit est une comparaison entre GenN2N et Instruct-NeRF2NeRF sur la tâche d'édition NeRF basée sur du texte. ).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment se connecter au réseau public du serveur GIT
Apr 17, 2025 pm 02:27 PM
Comment se connecter au réseau public du serveur GIT
Apr 17, 2025 pm 02:27 PM
La connexion d'un serveur GIT au réseau public comprend cinq étapes: 1. Configurer l'adresse IP publique; 2. Ouvrez le port de pare-feu (22, 9418, 80/443); 3. Configurer l'accès SSH (générer des paires de clés, créer des utilisateurs); 4. Configurer l'accès HTTP / HTTPS (installer les serveurs, configurer les autorisations); 5. Testez la connexion (en utilisant les commandes SSH Client ou GIT).
 Comment ajouter des clés publiques au compte GIT
Apr 17, 2025 pm 02:42 PM
Comment ajouter des clés publiques au compte GIT
Apr 17, 2025 pm 02:42 PM
Comment ajouter une clé publique à un compte GIT? Étape: générer une paire de clés SSH. Copiez la clé publique. Ajoutez une clé publique dans Gitlab ou GitHub. Testez la connexion SSH.
 Comment détecter SSH par Git
Apr 17, 2025 pm 02:33 PM
Comment détecter SSH par Git
Apr 17, 2025 pm 02:33 PM
Pour détecter SSH via GIT, vous devez effectuer les étapes suivantes: générer une paire de clés SSH. Ajoutez la clé publique au serveur GIT. Configurez Git pour utiliser SSH. Testez la connexion SSH. Résoudre les problèmes possibles en fonction des conditions réelles.
 Comment séparer Git Commit
Apr 17, 2025 pm 02:36 PM
Comment séparer Git Commit
Apr 17, 2025 pm 02:36 PM
Utilisez GIT pour soumettre le code séparément, en fournissant un suivi granulaire des changements et une capacité de travail indépendante. Les étapes sont les suivantes: 1. Ajouter les fichiers modifiés; 2. Soumettre des modifications spécifiques; 3. Répétez les étapes ci-dessus; 4. Pousser la soumission au référentiel distant.
 Comment gérer le conflit du code GIT
Apr 17, 2025 pm 02:51 PM
Comment gérer le conflit du code GIT
Apr 17, 2025 pm 02:51 PM
Le conflit de code fait référence à un conflit qui se produit lorsque plusieurs développeurs modifient le même morceau de code et provoquent la fusion de Git sans sélectionner automatiquement les modifications. Les étapes de résolution incluent: ouvrez le fichier contradictoire et découvrez le code contradictoire. Furiez le code manuellement et copiez les modifications que vous souhaitez maintenir dans le marqueur de conflit. Supprimer la marque de conflit. Enregistrer et soumettre des modifications.
 Comment construire un serveur GIT
Apr 17, 2025 pm 12:57 PM
Comment construire un serveur GIT
Apr 17, 2025 pm 12:57 PM
La construction d'un serveur GIT comprend: l'installation de GIT sur le serveur. Créer des utilisateurs et des groupes qui exécutent le serveur. Créez un répertoire de référentiel GIT. Initialisez le référentiel nu. Configurer les paramètres de contrôle d'accès. Démarrez le service SSH. Accorder l'accès à l'utilisateur. Tester la connexion.
 Que faire si Git soumet une branche échelonnée
Apr 17, 2025 pm 02:24 PM
Que faire si Git soumet une branche échelonnée
Apr 17, 2025 pm 02:24 PM
Après vous être engagé dans la mauvaise branche, vous pouvez le résoudre par: déterminer que la mauvaise branche crée une nouvelle branche, pointant vers la bonne branche, appliquez la validation à la nouvelle branche pousse la nouvelle branche vers le référentiel distant pour supprimer la mauvaise branche. Force Met à jour la branche distante
 Comment ajouter des variables d'environnement à Git
Apr 17, 2025 pm 02:39 PM
Comment ajouter des variables d'environnement à Git
Apr 17, 2025 pm 02:39 PM
Comment ajouter des variables d'environnement à GIT: modifiez le fichier .gitconfig. Ajouter Env = key = valeur dans le bloc [core]. Enregistrer et quitter le fichier. Recharger la configuration GIT (configuration git --reload). Vérifiez les variables d'environnement (Git Config --get Core.env.my_env_var).
