
 Java
javaDidacticiel
Comment fonctionnent les fonctions Java dans le domaine du traitement du Big Data ?
Java
javaDidacticiel
Comment fonctionnent les fonctions Java dans le domaine du traitement du Big Data ?
Comment fonctionnent les fonctions Java dans le domaine du traitement du Big Data ?

Les fonctions Java constituent un excellent choix pour le traitement du Big Data, avec des avantages tels qu'une exécution efficace, une optimisation de la mémoire, un traitement simultané et une prise en charge riche de bibliothèques. Des cas pratiques démontrent l'utilisation d'expressions Java Lambda pour accélérer le filtrage des données, améliorant ainsi les performances grâce à une exécution parallèle et une logique de filtrage simplifiée.

Excellentes performances des fonctions Java dans le domaine du traitement du Big Data
Dans le domaine du traitement du Big Data, les fonctions Java sont très respectées pour leurs fonctions puissantes et leurs excellentes performances. Les algorithmes avancés de récupération de place, le compilateur JIT et le riche écosystème de bibliothèques de la machine virtuelle Java (JVM) la rendent idéale pour traiter des ensembles de données volumineux.
Avantages des fonctions Java
- Exécution efficace : Le compilateur JIT de JVM compile le bytecode Java en code machine spécifique à la plate-forme, augmentant ainsi la vitesse d'exécution.
- Optimisation de la mémoire : Le mécanisme efficace de collecte des déchets de JVM permet de gérer de grands ensembles de données et d'éviter les fuites de mémoire.
- Traitement simultané : La fonctionnalité de simultanéité de Java permet d'exécuter des fonctions en parallèle, améliorant considérablement la vitesse de traitement.
- Prise en charge riche des bibliothèques : Java propose une large gamme de bibliothèques et de frameworks open source spécifiquement pour le traitement du Big Data, tels qu'Apache Hadoop et Spark.
Cas pratique : Utiliser des expressions Java Lambda pour accélérer le filtrage des données
Ce qui suit est un cas pratique utilisant des expressions Java Lambda pour accélérer le filtrage des données :
import java.util.List;
import java.util.stream.Collectors;
public class DataFilter {
public static void main(String[] args) {
// 原始数据
List<Integer> numbers = List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 使用 Lambda 表达式过滤奇数
List<Integer> oddNumbers = numbers.stream()
.filter(number -> number % 2 == 1)
.collect(Collectors.toList());
// 打印过滤后的结果
System.out.println(oddNumbers);
}
}Dans cet exemple, nous utilisons des expressions Java Lambdanumber -> number % 2 == 1 来过滤奇数。stream() 方法允许我们对数据并行执行操作,而 filter() La méthode spécifie les conditions de filtre. En utilisant des expressions Lambda, nous avons simplifié la logique de filtrage et tiré parti des capacités de concurrence de Java pour améliorer les performances.
Conclusion
Les fonctions Java ont d'excellentes performances dans le domaine du traitement du Big Data, grâce à leur exécution efficace, leur optimisation de la mémoire, leur traitement simultané et leur riche support de bibliothèque. En tirant parti de la puissance de Java, nous pouvons traiter efficacement des ensembles de données massifs et réaliser des applications Big Data réussies.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Java Made Simple : un guide du débutant sur la puissance de programmation
Oct 11, 2024 pm 06:30 PM
Java Made Simple : un guide du débutant sur la puissance de programmation
Oct 11, 2024 pm 06:30 PM
Java Made Simple : Guide du débutant sur la puissance de programmation Introduction Java est un langage de programmation puissant utilisé dans tout, des applications mobiles aux systèmes d'entreprise. Pour les débutants, la syntaxe de Java est simple et facile à comprendre, ce qui en fait un choix idéal pour apprendre la programmation. Syntaxe de base Java utilise un paradigme de programmation orienté objet basé sur les classes. Les classes sont des modèles qui organisent ensemble les données et les comportements associés. Voici un exemple simple de classe Java : publicclassPerson{privateStringname;privateintage;
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
 Comment intégrer efficacement les services Node.js ou Python sous l'architecture LAMP?
Apr 01, 2025 pm 02:48 PM
Comment intégrer efficacement les services Node.js ou Python sous l'architecture LAMP?
Apr 01, 2025 pm 02:48 PM
De nombreux développeurs de sites Web sont confrontés au problème de l'intégration de Node.js ou des services Python sous l'architecture de lampe: la lampe existante (Linux Apache MySQL PHP) a besoin d'un site Web ...
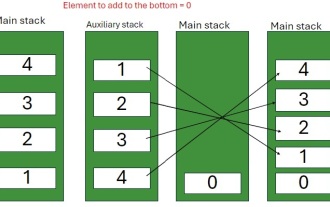 Programme Java pour insérer un élément au bas d'une pile
Feb 07, 2025 am 11:59 AM
Programme Java pour insérer un élément au bas d'une pile
Feb 07, 2025 am 11:59 AM
Une pile est une structure de données qui suit le principe LIFO (dernier dans, premier sorti). En d'autres termes, le dernier élément que nous ajoutons à une pile est le premier à être supprimé. Lorsque nous ajoutons (ou poussons) des éléments à une pile, ils sont placés sur le dessus; c'est-à-dire surtout
 Comment exécuter votre première application de démarrage de printemps dans Intellij?
Feb 07, 2025 am 11:40 AM
Comment exécuter votre première application de démarrage de printemps dans Intellij?
Feb 07, 2025 am 11:40 AM
Intellij Idea simplifie le développement de Boot Spring, ce qui en fait un favori parmi les développeurs Java. Son approche de configuration de la convention minimise le code passe-partout, permettant aux développeurs de se concentrer sur la logique métier. Ce tutoriel montre deux métho
