
 Périphériques technologiques
IA
Au-delà de BEVFusion ! DifFUSER : Le modèle Diffusion entre dans la conduite autonome multi-tâches (segmentation BEV + détection double SOTA)
Périphériques technologiques
IA
Au-delà de BEVFusion ! DifFUSER : Le modèle Diffusion entre dans la conduite autonome multi-tâches (segmentation BEV + détection double SOTA)
Au-delà de BEVFusion ! DifFUSER : Le modèle Diffusion entre dans la conduite autonome multi-tâches (segmentation BEV + détection double SOTA)

Écrit devant et compréhension personnelle de l'auteur
Actuellement, à mesure que la technologie de conduite autonome devient plus mature et que la demande de tâches de perception de conduite autonome augmente, l'industrie et le monde universitaire espèrent beaucoup un modèle d'algorithme de perception idéal qui puisse simultanément compléter tâches de détection de cibles tridimensionnelles et de segmentation sémantique basées sur l'espace BEV. Pour un véhicule capable de conduire de manière autonome, il est généralement équipé de capteurs de caméra à vision panoramique, de capteurs lidar et de capteurs radar à ondes millimétriques pour collecter des données selon différentes modalités. De cette manière, les avantages complémentaires entre les différentes données modales peuvent être pleinement exploités, de sorte que les avantages complémentaires des données entre les différentes modalités puissent être obtenus. Par exemple, les données de nuages de points 3D peuvent fournir des informations pour les tâches de détection de cibles 3D, tandis que les données d'images couleur. peut fournir plus d'informations pour les tâches de segmentation sémantique. Compte tenu des avantages complémentaires entre différentes données modales, en convertissant les informations efficaces de différentes données modales dans le même système de coordonnées, un traitement et une prise de décision conjoints ultérieurs sont facilités. Par exemple, les données de nuages de points 3D peuvent être converties en données de nuages de points basées sur l'espace BEV, et les données d'image des caméras à vision panoramique peuvent être projetées dans l'espace 3D grâce à l'étalonnage des paramètres internes et externes de la caméra, permettant ainsi un traitement unifié des données modales différentes. En tirant parti de différentes données modales, des résultats de perception plus précis peuvent être obtenus que des données modales uniques. Désormais, nous pouvons déjà déployer le modèle d'algorithme de perception multimodale sur la voiture pour produire des résultats de perception spatiale plus robustes et plus précis. Grâce à des résultats de perception spatiale précis, nous pouvons fournir une garantie plus fiable et plus sûre pour la réalisation des fonctions de conduite autonome.
Bien que de nombreux algorithmes de perception 3D pour la fusion de données multisensorielles et multimodales basés sur le cadre de réseau Transformer aient été récemment proposés dans le monde universitaire et l'industrie, ils utilisent tous le mécanisme d'attention croisée de Transformer pour réaliser l'intégration de données multimodales. fusion entre eux pour obtenir des résultats de détection de cible 3D idéaux. Cependant, ce type de méthode de fusion de fonctionnalités multimodale n’est pas totalement adapté aux tâches de segmentation sémantique basées sur l’espace BEV. De plus, en plus d'utiliser le mécanisme d'attention croisée pour compléter la fusion d'informations entre différentes modalités, de nombreux algorithmes utilisent la conversion vectorielle directe dans LSA pour construire des fonctionnalités fusionnées, mais il existe également certains problèmes comme suit : (Limitation du nombre de mots, une description détaillée suit ).
- En raison de l'algorithme de détection 3D actuellement proposé lié à la fusion multimodale, la méthode de fusion de différentes caractéristiques de données modales n'est pas suffisamment conçue, ce qui fait que le modèle d'algorithme de perception est incapable de capturer avec précision les relations de connexion complexes entre les données du capteur, et affecte ainsi la performance finale perçue du modèle.
- Dans le processus de collecte de données provenant de différents capteurs, des informations sur le bruit non pertinentes seront inévitablement introduites. Ce bruit inhérent entre les différentes modalités entraînera également le mélange du bruit dans le processus de fusion de différentes caractéristiques modales, entraînant une fusion de caractéristiques multimodales. L'imprécision affecte les tâches de perception ultérieures.
Compte tenu des nombreux problèmes mentionnés ci-dessus dans le processus de fusion multimodale qui peuvent affecter la capacité de perception du modèle final, et compte tenu des performances puissantes récemment démontrées par le modèle génératif, nous avons exploré le modèle génératif en utilisant Il est utilisé pour réaliser des tâches de fusion multimodale et de débruitage entre plusieurs capteurs. Sur cette base, nous proposons un algorithme de perception de modèle génératif DifFUSER basé sur la diffusion conditionnelle pour implémenter des tâches de perception multimodales. Comme le montre la figure ci-dessous, l'algorithme de fusion de données multimodales DifFUSER que nous avons proposé peut réaliser un processus de fusion multimodale plus efficace.  L'algorithme de fusion de données multimodales DifFUSER peut réaliser un processus de fusion multimodale plus efficace. La méthode comprend principalement deux étapes. Premièrement, nous utilisons des modèles génératifs pour débruiter et améliorer les données d’entrée, générant ainsi des données multimodales propres et riches. Ensuite, les données générées par le modèle génératif sont utilisées pour une fusion multimodale afin d'obtenir de meilleurs effets de perception. Les résultats expérimentaux de l'algorithme DifFUSER montrent que l'algorithme de fusion de données multimodal que nous avons proposé peut réaliser un processus de fusion multimodale plus efficace. Lors de la mise en œuvre de tâches de perception multimodale, cet algorithme peut réaliser un processus de fusion multimodale plus efficace et améliorer les capacités de perception du modèle. De plus, l'algorithme de fusion de données multimodales de l'algorithme peut réaliser un processus de fusion multimodale plus efficace. Dans l'ensemble
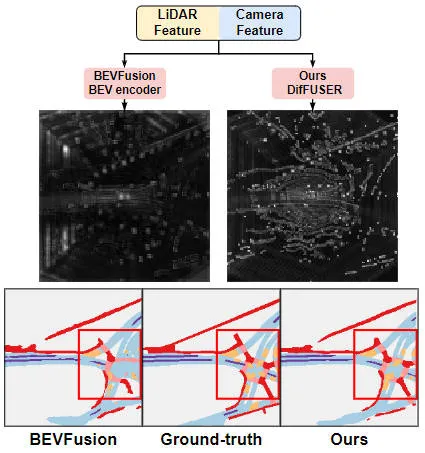
Tableau de comparaison visuel des résultats du modèle d'algorithme proposé et d'autres modèles d'algorithme
Lien papier : https://arxiv.org/pdf/2404.04629.pdf
Architecture globale et détails du modèle de réseau
"Détails du module de l'algorithme DifFUSER, algorithme de perception multitâche basé sur un modèle de diffusion conditionnelle" est un algorithme utilisé pour résoudre les problèmes de perception des tâches. La figure ci-dessous montre la structure globale du réseau de notre algorithme DifFUSER proposé. Dans ce module, nous proposons un algorithme de perception multitâche basé sur le modèle de diffusion conditionnelle pour résoudre le problème de perception des tâches. L'objectif de cet algorithme est d'améliorer les performances de l'apprentissage multitâche en diffusant et en agrégeant des informations spécifiques à une tâche dans le réseau. Intégration de l'algorithme DifFUSER
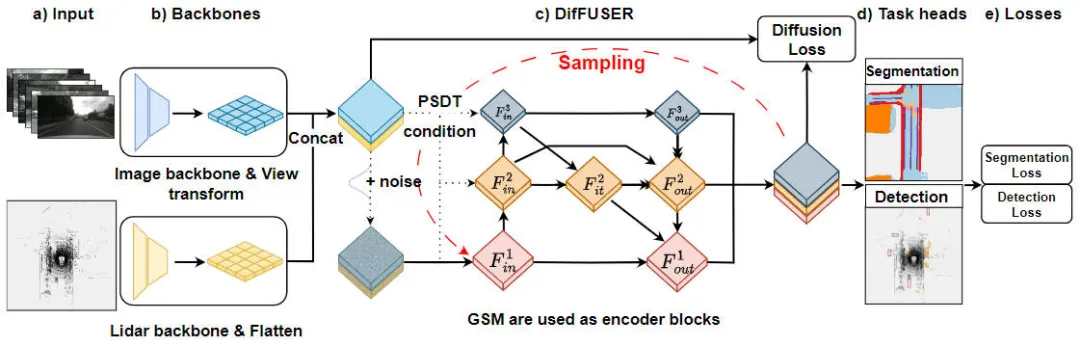 Schéma de structure de réseau du modèle d'algorithme de perception DifFUSER proposé
Schéma de structure de réseau du modèle d'algorithme de perception DifFUSER proposé
Comme le montre la figure ci-dessus, la structure de réseau DifFUSER que nous avons proposée comprend principalement trois sous-réseaux, à savoir la partie réseau fédérateur, la partie fusion de données multimodales de DifFUSER et la dernière partie BEV Head de la tâche de segmentation sémantique. Responsable d'une tâche de perception de détection d'objets 3D. Dans la partie réseau fédérateur, nous utilisons des architectures de réseau d'apprentissage en profondeur existantes, telles que ResNet ou VGG, pour extraire des fonctionnalités de haut niveau des données d'entrée. La partie fusion de données multimodales de DifFUSER utilise plusieurs branches parallèles, chaque branche est utilisée pour traiter différents types de données de capteurs (tels que les images, le lidar et le radar, etc.). Chaque branche possède sa propre partie de réseau fédérateur
- : Cette partie effectue principalement l'extraction de caractéristiques sur les données d'image 2D entrées par le modèle de réseau et les données de nuage de points lidar 3D pour générer les caractéristiques sémantiques BEV correspondantes. Pour le réseau fédérateur qui extrait les caractéristiques de l'image, il comprend principalement un réseau fédérateur d'image 2D et un module de conversion de perspective. Pour le réseau fédérateur qui extrait les caractéristiques du nuage de points lidar 3D, il comprend principalement le réseau fédérateur du nuage de points 3D et le module Flatten.
- Partie de fusion de données multimodales DifFUSER : Les modules DifFUSER que nous avons proposés sont reliés entre eux sous la forme d'un réseau pyramidal de fonctionnalités bidirectionnel hiérarchique que nous appelons cette structure cMini-BiFPN. Cette structure fournit une structure alternative pour une diffusion potentielle et peut mieux gérer les informations détaillées sur les caractéristiques multi-échelles et largeur-hauteur provenant de différentes données de capteurs.
- Segmentation sémantique BEV, partie tête de tâche de perception de détection de cible 3D : Étant donné que notre modèle d'algorithme peut produire simultanément des résultats de détection de cible 3D et des résultats de segmentation sémantique dans l'espace BEV, la tête de tâche de perception 3D comprend une tête de détection 3D et une tête de segmentation sémantique . De plus, les pertes impliquées dans le modèle d'algorithme que nous proposons incluent la perte de diffusion, la perte de détection et la perte de segmentation sémantique. En additionnant toutes les pertes, les paramètres du modèle de réseau sont mis à jour par rétropropagation.
Ensuite, nous présenterons soigneusement les détails de mise en œuvre de chaque sous-partie principale du modèle.
Conception d'architecture de fusion (Conditional-Mini-BiFPN, cMini-BiFPN)
Pour les tâches de perception dans le système de conduite autonome, il est crucial que le modèle d'algorithme puisse percevoir l'environnement externe actuel en temps réel, il est donc très important pour garantir les performances et l’efficacité du module de diffusion. Par conséquent, nous nous inspirons du réseau pyramidal de fonctionnalités bidirectionnel et introduisons une architecture de diffusion BiFPN avec des conditions similaires, que nous appelons Conditional-Mini-BiFPN. Sa structure de réseau spécifique est illustrée dans la figure ci-dessus.


Progressive Sensor Dropout Training (PSDT)
Pour un véhicule autonome, les performances du capteur d'acquisition de conduite autonome sont cruciales Lors de la conduite quotidienne du véhicule autonome, il est très probable que le. Le capteur de caméra ou le capteur lidar sera bloqué ou fonctionnera mal, ce qui affectera la sécurité et l'efficacité de fonctionnement du système de conduite autonome final. Sur la base de cette considération, nous avons proposé un paradigme de formation progressive à l'abandon du capteur pour améliorer la robustesse et l'adaptabilité du modèle d'algorithme proposé dans les situations où le capteur peut être bloqué.
Grâce à notre paradigme de formation à l'abandon progressif des capteurs proposé, le modèle d'algorithme peut reconstruire les caractéristiques manquantes en utilisant la distribution de deux données modales collectées par les capteurs de caméra et les capteurs lidar, obtenant ainsi une excellente adaptation dans des conditions difficiles, en termes de performances et de robustesse. Plus précisément, nous exploitons les fonctionnalités des données d'image et des données de nuages de points lidar de trois manières différentes, en tant que cibles d'entraînement, entrée de bruit dans le module de diffusion et pour simuler les conditions dans lesquelles un capteur est perdu ou défectueux. Pour simuler des conditions de perte ou de défaillance du capteur. nous augmentons progressivement le taux de perte d'entrée du capteur de caméra ou du capteur lidar de 0 à une valeur maximale prédéfinie a = 25 pendant l'entraînement. L'ensemble du processus peut être exprimé par la formule suivante :
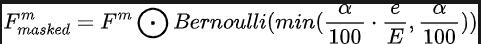
Parmi eux, représente le nombre de cycles de formation dans lesquels se trouve le modèle actuel et définit la probabilité d'abandon pour représenter la probabilité que chaque fonctionnalité soit abandonnée. Grâce à ce processus de formation progressif, le modèle est non seulement entraîné à débruiter efficacement et à générer des caractéristiques plus expressives, mais minimise également sa dépendance à l'égard d'un seul capteur, améliorant ainsi sa gestion des capteurs incomplets avec une plus grande résilience des données.
Module de diffusion de modulation auto-conditionné à grille (module de diffusion GSM)

Plus précisément, la structure du réseau du module de diffusion de modulation à auto-conditionnement à grille est illustrée dans la figure ci-dessous
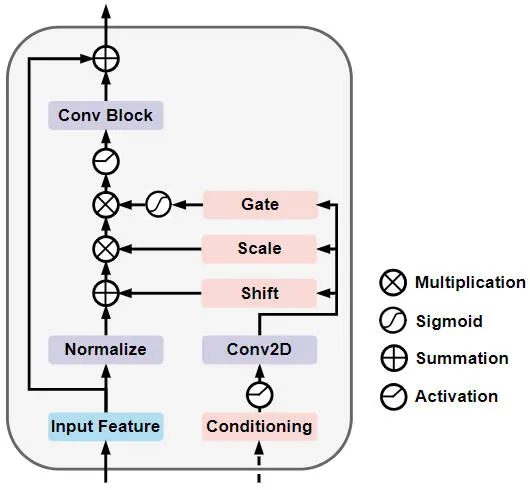
Auto-conditionné à grille Modulation Diffusion Diagramme schématique de la structure du réseau de modules

Résultats expérimentaux et indicateurs d'évaluation
Partie analyse quantitative
Afin de vérifier les résultats perceptuels de notre modèle d'algorithme proposé DifFUSER sur des tâches multi-tâches, nous avons principalement effectué sur l'ensemble de données nuScenes, expériences de détection de cibles 3D et de segmentation sémantique basées sur l'espace BEV.
Tout d'abord, nous avons comparé les performances du modèle d'algorithme proposé DifFUSER avec d'autres algorithmes de fusion multimodaux sur des tâches de segmentation sémantique. Les résultats expérimentaux spécifiques sont présentés dans le tableau suivant :
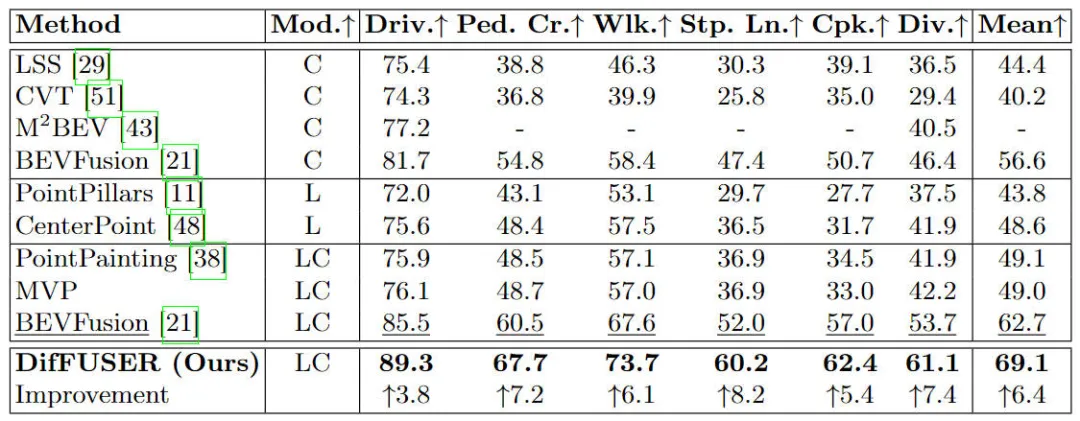 Différents modèles d'algorithmes sur l'ensemble de données nuScenes Comparaison de. résultats expérimentaux des tâches de segmentation sémantique basées sur l'espace BEV
Différents modèles d'algorithmes sur l'ensemble de données nuScenes Comparaison de. résultats expérimentaux des tâches de segmentation sémantique basées sur l'espace BEV
Les résultats expérimentaux montrent que le modèle d'algorithme que nous avons proposé a considérablement amélioré les performances par rapport au modèle de base. Plus précisément, la valeur mIoU du modèle BEVFusion n'est que de 62,7 %, tandis que le modèle d'algorithme que nous avons proposé a atteint 69,1 %, avec une amélioration de 6,4 %, ce qui montre que l'algorithme que nous avons proposé présente plus d'avantages dans différentes catégories. De plus, la figure ci-dessous illustre également de manière plus intuitive les avantages du modèle d'algorithme que nous avons proposé. Plus précisément, l'algorithme BEVFusion produira de mauvais résultats de segmentation, en particulier dans les scénarios longue distance, où le désalignement des capteurs est plus évident. En comparaison, notre modèle d’algorithme donne des résultats de segmentation plus précis, avec des détails plus évidents et moins de bruit.
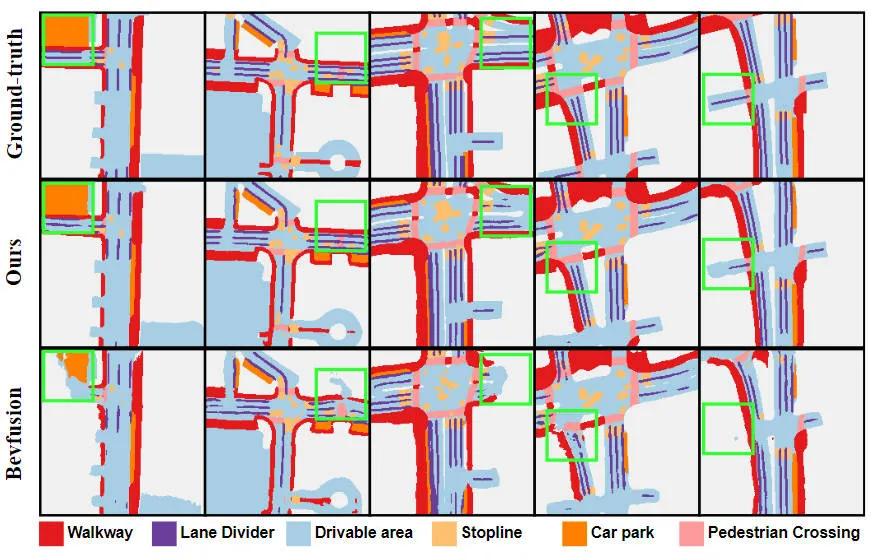
Comparaison des résultats de visualisation de segmentation du modèle d'algorithme proposé et du modèle de base
De plus, nous avons également comparé le modèle d'algorithme proposé avec d'autres modèles d'algorithme de détection de cibles 3D. Les résultats expérimentaux spécifiques sont présentés dans le tableau ci-dessous.
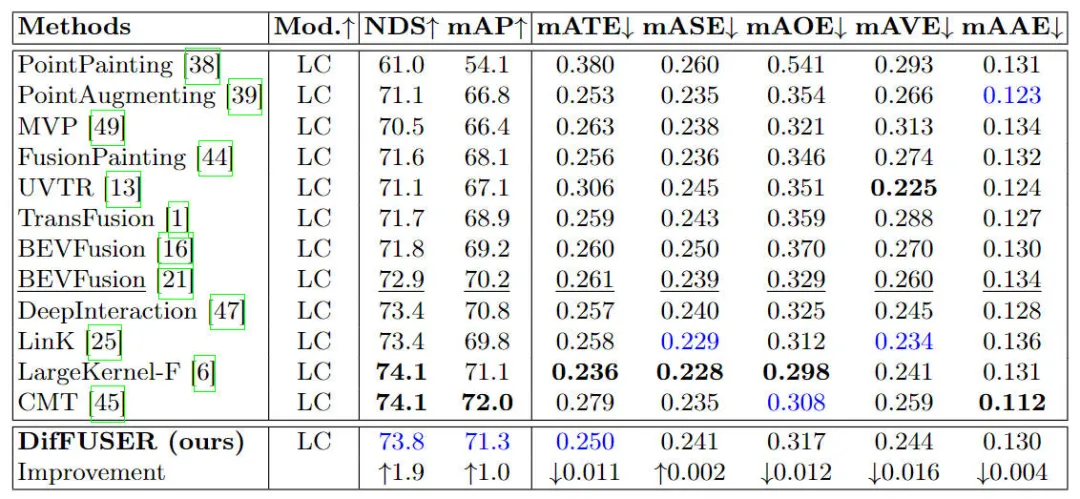
Comparaison des résultats expérimentaux de différents modèles d'algorithme sur la tâche de détection de cible 3D sur l'ensemble de données nuScenes
Comme le montrent les résultats répertoriés dans le tableau, notre modèle d'algorithme proposé DifFUSER a de meilleures performances à la fois en NDS et en mAP indicateurs que le modèle de base. Par rapport aux 72,9 % NDS et 70,2 % mAP du modèle de base BEVFusion, notre modèle d'algorithme est respectivement 1,8 % et 1,0 % plus élevé. L'amélioration des indicateurs pertinents montre que le module de fusion par diffusion multimodale que nous avons proposé est efficace dans le processus de réduction et de raffinement des caractéristiques.
De plus, afin de montrer la robustesse perceptuelle du modèle d'algorithme proposé en cas de défaillance ou d'occlusion du capteur, nous avons comparé les résultats des tâches de segmentation associées, comme le montre la figure ci-dessous.
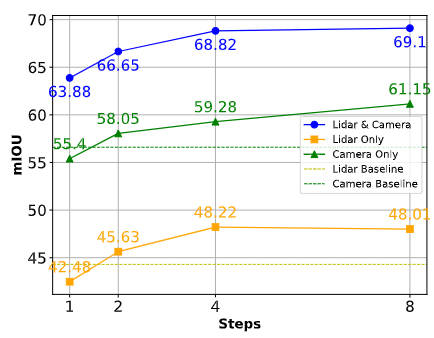
Comparaison des performances de l'algorithme dans différentes situations
Comme le montre la figure ci-dessus, lorsque l'échantillonnage est suffisant, le modèle d'algorithme que nous proposons peut compenser efficacement les fonctionnalités manquantes et être utilisé comme base pour la collecte de capteurs manquants. informations. Contenu alternatif. La capacité de notre modèle d'algorithme DifFUSER proposé à générer et à utiliser des fonctionnalités synthétiques atténue efficacement la dépendance à l'égard d'une modalité de capteur unique et garantit que le modèle peut fonctionner sans problème dans des environnements divers et difficiles.
Partie analyse qualitative
La figure suivante montre la visualisation des résultats de détection de cible 3D et de segmentation sémantique de l'espace BEV de notre modèle d'algorithme DifFUSER proposé. Il ressort des résultats de visualisation que le modèle d'algorithme que nous avons proposé est bon. Détection et effet Split.

Conclusion
Cet article propose un modèle d'algorithme de perception multimodale DifFUSER basé sur le modèle de diffusion, qui améliore la qualité de fusion du modèle de réseau en améliorant l'architecture de fusion du modèle de réseau et en utilisant les propriétés de débruitage du modèle de diffusion. Les résultats expérimentaux sur l'ensemble de données Nuscenes montrent que le modèle d'algorithme que nous avons proposé atteint des performances de segmentation SOTA dans la tâche de segmentation sémantique de l'espace BEV et peut atteindre des performances de détection similaires au modèle d'algorithme SOTA actuel dans la tâche de détection de cible 3D.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Un didacticiel sur le modèle de diffusion qui vaut votre temps, de l'Université Purdue
Apr 07, 2024 am 09:01 AM
Un didacticiel sur le modèle de diffusion qui vaut votre temps, de l'Université Purdue
Apr 07, 2024 am 09:01 AM
La diffusion permet non seulement de mieux imiter, mais aussi de « créer ». Le modèle de diffusion (DiffusionModel) est un modèle de génération d'images. Par rapport aux algorithmes bien connus tels que GAN et VAE dans le domaine de l’IA, le modèle de diffusion adopte une approche différente. Son idée principale est un processus consistant à ajouter d’abord du bruit à l’image, puis à la débruiter progressivement. Comment débruiter et restaurer l’image originale est la partie centrale de l’algorithme. L'algorithme final est capable de générer une image à partir d'une image bruitée aléatoirement. Ces dernières années, la croissance phénoménale de l’IA générative a permis de nombreuses applications passionnantes dans la génération de texte en image, la génération de vidéos, et bien plus encore. Le principe de base de ces outils génératifs est le concept de diffusion, un mécanisme d'échantillonnage spécial qui surmonte les limites des méthodes précédentes.
 Un article résumant l'application du modèle de diffusion dans les séries chronologiques
Mar 07, 2024 am 10:30 AM
Un article résumant l'application du modèle de diffusion dans les séries chronologiques
Mar 07, 2024 am 10:30 AM
Le modèle de diffusion est actuellement le module de base de l'IA générative et a été largement utilisé dans les grands modèles d'IA générative tels que Sora, DALL-E et Imagen. Parallèlement, les modèles de diffusion sont de plus en plus appliqués aux séries chronologiques. Cet article vous présente les idées de base du modèle de diffusion, ainsi que plusieurs travaux typiques du modèle de diffusion utilisé dans les séries chronologiques, pour vous aider à comprendre les principes d'application du modèle de diffusion dans les séries chronologiques. 1. Idée de modélisation du modèle de diffusion Le cœur du modèle génératif est de pouvoir échantillonner un point à partir d'une distribution simple aléatoire et mapper ce point à une image ou un échantillon dans l'espace cible à travers une série de transformations. La méthode du modèle de diffusion consiste à supprimer en continu le bruit sur les points d'échantillonnage échantillonnés, et après plusieurs étapes de suppression du bruit, les données finales sont générées.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Comment accélérer BitGenie_Comment accélérer la vitesse de téléchargement de BitGenie
Apr 29, 2024 pm 02:58 PM
Comment accélérer BitGenie_Comment accélérer la vitesse de téléchargement de BitGenie
Apr 29, 2024 pm 02:58 PM
1. Tout d'abord, assurez-vous que vos graines BT sont saines, contiennent suffisamment de graines et sont suffisamment populaires pour qu'elles répondent aux conditions préalables au téléchargement BT et que la vitesse soit rapide. Ouvrez la colonne « Sélectionner » de votre propre BitComet, cliquez sur « Connexion réseau » dans la première colonne et ajustez la vitesse de téléchargement maximale globale à 1 000 sans limite (1 000 pour les utilisateurs de moins de 2 M est un nombre inaccessible, mais il est normal de ne pas l'ajuster. ça, qui ne veut pas le télécharger) Très rapide). La vitesse de téléchargement maximale peut être ajustée à 40 sans aucune limite (à choisir en fonction de votre situation personnelle, l'ordinateur se bloquera si la vitesse est trop rapide). 3. Cliquez sur Paramètres de tâche. Vous pouvez ajuster le répertoire de téléchargement par défaut à l'intérieur. 4. Cliquez sur Apparence de l'interface. Modifiez le nombre maximum de pairs affichés à 1000, ce qui permet d'afficher les détails des utilisateurs connectés à vous, afin que vous ayez l'esprit tranquille. 5. Cliquez sur.
 Comment utiliser la commande netsh dans win7
Apr 09, 2024 am 10:03 AM
Comment utiliser la commande netsh dans win7
Apr 09, 2024 am 10:03 AM
La commande netsh est utilisée pour gérer les réseaux dans Windows 7 et est capable d'effectuer les opérations suivantes : Afficher les informations réseau Configurer les paramètres TCP/IP Gérer les réseaux sans fil Configurer des proxys réseau
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
