
 Tutoriel matériel
Examen du matériel
Comprenez facilement les images 4K HD ! Ce grand modèle multimodal analyse automatiquement le contenu des affiches Web, ce qui le rend très pratique pour les travailleurs.
Tutoriel matériel
Examen du matériel
Comprenez facilement les images 4K HD ! Ce grand modèle multimodal analyse automatiquement le contenu des affiches Web, ce qui le rend très pratique pour les travailleurs.
Comprenez facilement les images 4K HD ! Ce grand modèle multimodal analyse automatiquement le contenu des affiches Web, ce qui le rend très pratique pour les travailleurs.

Un grand modèle capable d'analyser automatiquement le contenu des PDF, des pages Web, des affiches et des graphiques Excel n'est pas très pratique pour les travailleurs à temps partiel.
Le modèle InternLM-XComposer2-4KHD (en abrégé IXC2-4KHD) proposé par le Shanghai AI Lab, l'Université chinoise de Hong Kong et d'autres instituts de recherche en fait une réalité.

Par rapport à d'autres grands modèles multimodaux qui ont une limite de résolution ne dépassant pas 1 500 x 1 500, ce travail augmente l'image d'entrée maximale du grand modèle multimodal à une résolution supérieure à 4K (3 840 x 1 600) et prend en charge tout Rapport de longueur et de largeur et changements de résolution dynamique de 336 pixels ~ 4K.
Trois jours après sa sortie, le modèle était en tête de la liste de popularité des modèles visuels de questions et réponses de Hugging Face.
Compréhension facile des images 4K
Jetons d'abord un coup d'œil à l'effet ~
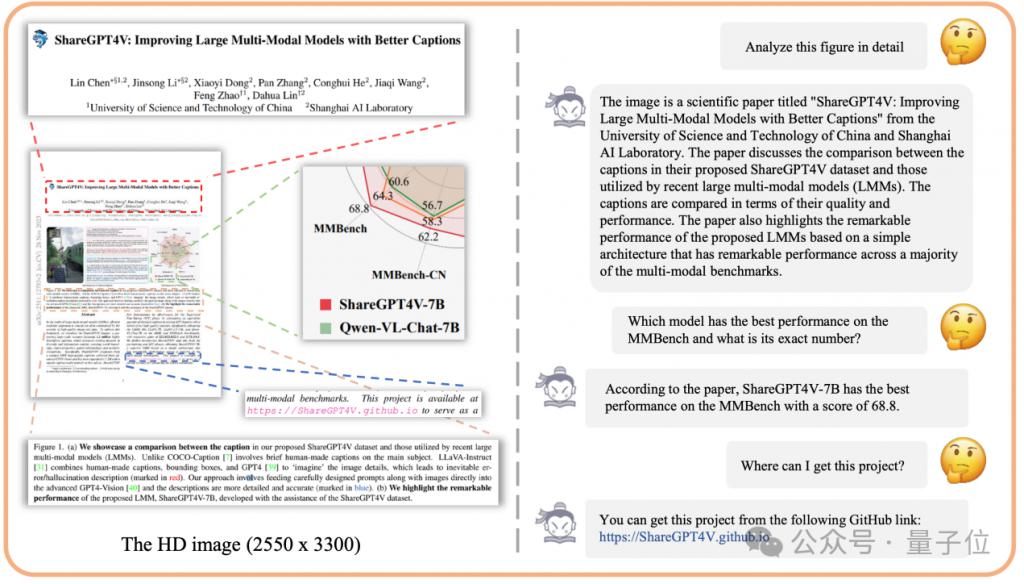
Le chercheur a saisi une capture d'écran de la page d'accueil de l'article (ShareGPT4V : amélioration des grands modèles multimodaux avec de meilleures légendes) (la résolution est de 2 550 x 3 300). ), et a demandé quel papier Le modèle a les performances les plus élevées sur MMBench.
Il est à noter que cette information n'est pas mentionnée dans la partie texte de la capture d'écran de saisie, mais n'apparaît que dans un graphique radar assez compliqué. Face à une question aussi délicate, IXC2-4KHD a réussi à comprendre les informations contenues dans la carte radar et à répondre correctement à la question.
Face à une entrée d'image à résolution plus extrême (816 x 5133), IXC2-4KHD comprend facilement que l'image se compose de 7 parties et explique avec précision le contenu des informations textuelles contenues dans chaque partie.

Par la suite, les chercheurs ont également testé de manière approfondie les capacités d'IXC2-4KHD sur 16 indicateurs d'évaluation multimodaux de grands modèles, dont 5 évaluations (DocVQA, ChartQA, InfographicVQA, TextVQA, OCRBench) axées sur la haute résolution de la capacité de compréhension de l'image du taux de modèle.
En utilisant uniquement les paramètres 7B, IXC2-4KHD a obtenu des résultats comparables, voire supérieurs, à GPT4V et Gemini Pro dans 10 des évaluations, démontrant qu'il ne se limite pas à la compréhension d'images haute résolution, mais qu'il est polyvalent pour diverses tâches et capacités de scénarios. .
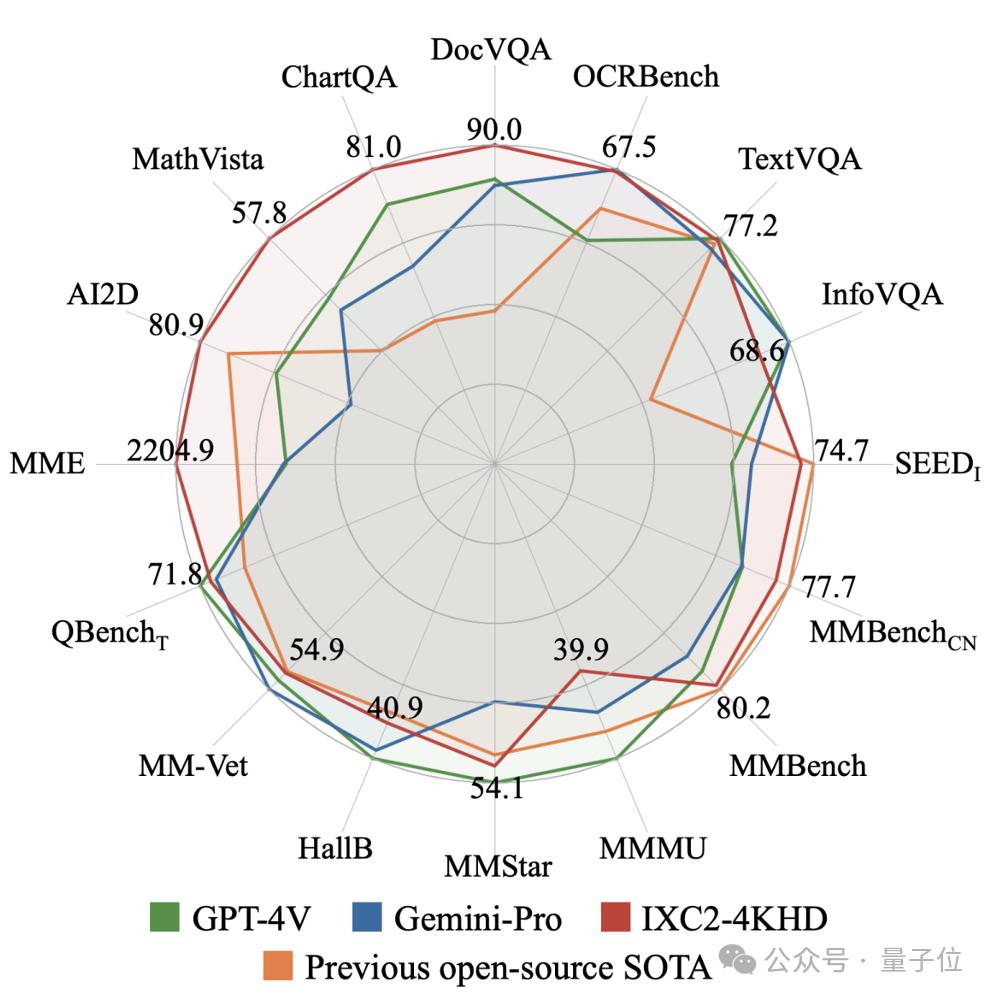
△Les performances du IXC2-4KHD avec seulement 7B de paramètres sont comparables à celles du GPT-4V et du Gemini-Pro. Comment obtenir une résolution dynamique 4K ?
Afin d'atteindre l'objectif de résolution dynamique 4K, IXC2-4KHD comprend trois conceptions principales :
(1) Formation à la résolution dynamique :
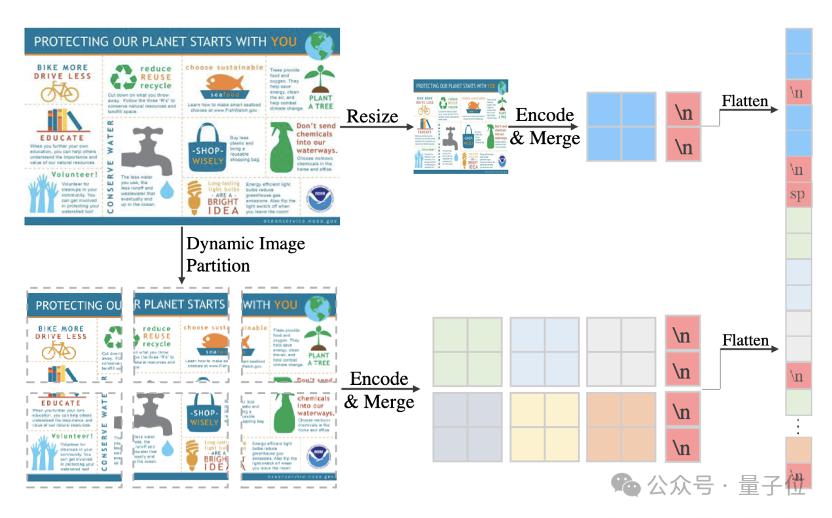
△Stratégie de traitement d'image en résolution 4K
Dans IXC2-4KHD Dans le cadre , l'image d'entrée est agrandie de manière aléatoire à une taille intermédiaire entre la zone d'entrée et la zone maximale (ne dépassant pas 55x336x336, équivalent à une résolution de 3840x1617) tout en conservant le rapport hauteur/largeur.
Par la suite, l'image est automatiquement découpée en plusieurs zones de 336 x 336 pour extraire respectivement les caractéristiques visuelles. Cette stratégie d'entraînement à la résolution dynamique permet au modèle de s'adapter à l'entrée visuelle de n'importe quelle résolution, tout en compensant également le problème de l'insuffisance des données d'entraînement à haute résolution.
Les expériences montrent qu'à mesure que la limite supérieure de la résolution dynamique augmente, le modèle obtient une amélioration stable des performances sur les tâches de compréhension d'images haute résolution (InfographicVQA, DocVQA, TextVQA), et n'atteint toujours pas la limite supérieure à la résolution 4K, montrant un potentiel d'amélioration supplémentaire. expansion à des résolutions plus élevées.
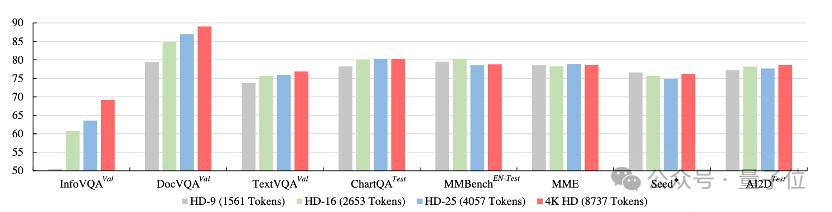
(2) Ajouter des informations sur la disposition des tuiles :
Afin de permettre au modèle de s'adapter aux résolutions dynamiques changeantes, les chercheurs ont constaté qu'il était nécessaire d'ajouter des informations sur la disposition des tuiles comme entrée supplémentaire. Pour y parvenir, les chercheurs ont adopté une stratégie simple : un jeton spécial « nouvelle ligne » (« n ») est inséré après chaque rangée de tuiles pour informer le modèle de la disposition des tuiles. Les expériences montrent que l'ajout d'informations sur la disposition des tuiles a peu d'impact sur l'entraînement à la résolution dynamique avec des changements relativement faibles (HD9 signifie que le nombre de zones de tuiles ne dépasse pas 9), mais peut apporter des améliorations significatives des performances à l'entraînement à la résolution dynamique 4K.
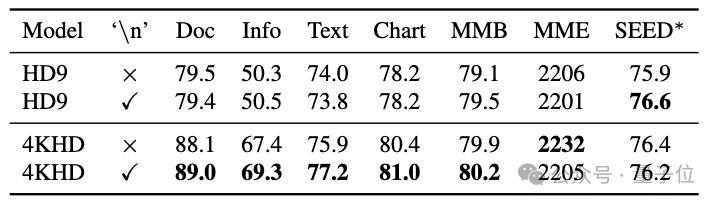
(3) Extension de la résolution pendant la phase d'inférence
Les chercheurs ont également découvert qu'en utilisant un modèle de résolution dynamique, la résolution peut être directement étendue pendant la phase d'inférence en augmentant la limite supérieure maximale des tuiles, et apporter des gains de performances supplémentaires . Par exemple, en testant un modèle entraîné sur HD9 (jusqu'à 9 blocs) directement à l'aide de HD16, une amélioration des performances allant jusqu'à 8 % peut être observée sur InfographicVQA.
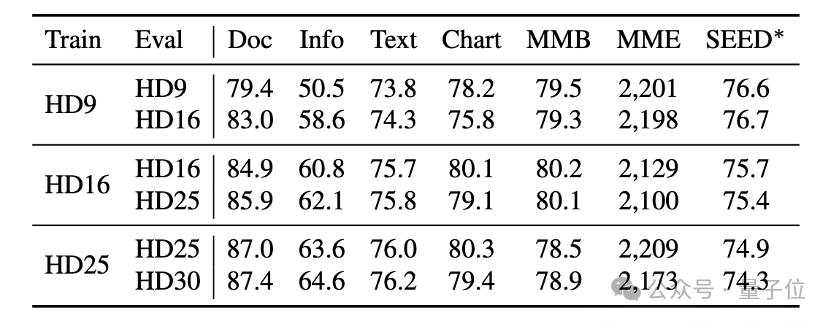
IXC2-4KHD augmente la résolution prise en charge par les grands modèles multimodaux jusqu'au niveau 4K. Les chercheurs ont déclaré que la stratégie actuelle consistant à prendre en charge une entrée d'image plus grande en augmentant le nombre de tuiles se heurte à des contraintes de coût de calcul et de mémoire. ils prévoient de proposer des stratégies plus efficaces pour obtenir un support de résolution plus élevée à l’avenir.
Lien papier :
https://arxiv.org/pdf/2404.06512.pdf
Lien du projet :
https://github.com/InternLM/InternLM-XComposer
—Fin—
Veuillez envoyer vos soumissions Envoyez un e-mail à :
ai@qbitai.com
Indiquez le titre et dites-nous :
Qui êtes-vous, d'où venez-vous, le contenu de votre soumission
Joignez le lien de la page d'accueil de l'article/du projet et les coordonnées
Nous ferons de mon mieux pour vous répondre à temps

Cliquez ici pour me suivre et n'oubliez pas de mettre en vedette~
"Partager", "J'aime" et "Regarder" en trois clics
À tous les jours sur les progrès de pointe de la science et de la technologie ~
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 La résolution du bureau affecte la fréquence d'images '&' réduite de moitié ? Errata de test de fréquence d'images RTX 4060
Aug 16, 2024 am 09:35 AM
La résolution du bureau affecte la fréquence d'images '&' réduite de moitié ? Errata de test de fréquence d'images RTX 4060
Aug 16, 2024 am 09:35 AM
Il y a quelques jours, Game Science a publié le logiciel de référence pour "Black Myth : Wukong". Lors du test, nous avons constaté que lorsqu'un moniteur externe est connecté (l'écran indépendant est directement connecté à l'interface de sortie vidéo), la résolution du bureau est faible. du moniteur est plus grande que la résolution du jeu, la fréquence d'images du jeu diminuera de manière très significative et, dans certains cas, la fréquence d'images diminuera même de moitié. Nous avons donc relancé le test et découvert la raison. Cet article concerne mon dernier test : "2 résolutions x 13 qualités d'image = 26 résultats de test, RTX4060 dans "Black Myth : Wukong" Quelle est la fréquence d'images ? 》Correction et errata, je voudrais d'abord m'excuser auprès de tout le monde ici, théoriquement parlant, le RTX4060 sera beaucoup plus élevé dans "Black Myth : Wukong" que mes résultats de tests précédents.
 Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Il existe de nombreuses façons d'installer Deepseek, notamment: Compiler à partir de Source (pour les développeurs expérimentés) en utilisant des packages précompilés (pour les utilisateurs de Windows) à l'aide de conteneurs Docker (pour le plus pratique, pas besoin de s'inquiéter de la compatibilité), quelle que soit la méthode que vous choisissez, veuillez lire Les documents officiels documentent soigneusement et les préparent pleinement à éviter des problèmes inutiles.
 Résumé des FAQ pour une utilisation profonde
Feb 19, 2025 pm 03:45 PM
Résumé des FAQ pour une utilisation profonde
Feb 19, 2025 pm 03:45 PM
Deepseekai Tool User Guide et FAQ Deepseek est un puissant outil intelligent AI. FAQ: La différence entre les différentes méthodes d'accès: il n'y a pas de différence de fonction entre la version Web, la version de l'application et les appels API, et l'application n'est qu'un wrapper pour la version Web. Le déploiement local utilise un modèle de distillation, qui est légèrement inférieur à la version complète de Deepseek-R1, mais le modèle 32 bits a théoriquement une capacité de version complète de 90%. Qu'est-ce qu'une taverne? SillyTavern est une interface frontale qui nécessite d'appeler le modèle AI via l'API ou le olllama. Qu'est-ce que la limite de rupture
 La configuration principale de l'OPPO Find X8 Ultra exposée ! Batterie extra grande Snapdragon 8 Gen4+
Aug 22, 2024 pm 06:54 PM
La configuration principale de l'OPPO Find X8 Ultra exposée ! Batterie extra grande Snapdragon 8 Gen4+
Aug 22, 2024 pm 06:54 PM
Le 22 août, un blogueur numérique a révélé quelques informations de configuration de base d'OPPO Find X8 Ultra. Selon le contenu exposé, ce modèle haut de gamme sera équipé de la dernière plate-forme mobile Snapdragon 8Gen4 de Qualcomm, équipée d'une batterie ultra-grande capacité de 6 000 mAh et prend en charge les fonctions de charge rapide filaire de 100 W et de charge rapide sans fil de 50 W. Conception de l'apparence Il n'existe actuellement aucune information de conception spécifique sur OPPO Find X8 Ultra. Cependant, de vraies images de la version standard d'OPPO Find X8 ont été exposées sur Internet. Apparence du FindX8 À en juger par les photos exposées, le module de caméra arrière de l'OPPO FindX8 adopte un design carré avec un certain degré de courbure aux quatre coins, donnant une sensation plus arrondie. De plus, la machine adopte une direction directe
 Comment s'inscrire à LBank Exchange ?
Aug 21, 2024 pm 02:20 PM
Comment s'inscrire à LBank Exchange ?
Aug 21, 2024 pm 02:20 PM
Pour vous inscrire à LBank, visitez le site officiel et cliquez sur « S'inscrire ». Entrez votre e-mail et votre mot de passe et vérifiez votre e-mail. Téléchargez l'application LBank iOS : recherchez « LBank » dans l'AppStore. Téléchargez et installez l'application "LBank-DigitalAssetExchange". Android : recherchez « LBank » dans le Google Play Store. Téléchargez et installez l'application "LBank-DigitalAssetExchange".
 Quels sont les outils d'IA ?
Nov 29, 2024 am 11:11 AM
Quels sont les outils d'IA ?
Nov 29, 2024 am 11:11 AM
Les outils d'IA incluent : Doubao, ChatGPT, Gemini, BlenderBot, etc.
 Les spécifications de conception du téléphone Redmi 14C de Xiaomi à 100 yuans révélées seront publiées le 31 août
Aug 23, 2024 pm 09:31 PM
Les spécifications de conception du téléphone Redmi 14C de Xiaomi à 100 yuans révélées seront publiées le 31 août
Aug 23, 2024 pm 09:31 PM
La marque Redmi de Xiaomi se prépare à ajouter un autre téléphone économique à son portefeuille : le Redmi 14C. Il est confirmé que l'appareil sortira au Vietnam le 31 août. Cependant, avant le lancement, les spécifications du téléphone ont été révélées par l'intermédiaire d'un détaillant vietnamien. Redmi14CR Redmi apporte souvent de nouveaux designs dans de nouvelles séries, et Redmi14C ne fait pas exception. Le téléphone dispose d’un grand module de caméra circulaire à l’arrière, complètement différent du design de son prédécesseur. La version de couleur bleue utilise même un design dégradé pour lui donner un aspect plus haut de gamme. Cependant, le Redmi14C est en réalité un téléphone mobile économique. Le module caméra se compose de quatre anneaux : l'un abrite le capteur principal de 50 mégapixels et l'autre peut abriter la caméra pour les informations de profondeur.
 Delphi Digital: Comment changer la nouvelle économie d'IA en analysant la nouvelle architecture Elizaos V2?
Mar 04, 2025 pm 07:00 PM
Delphi Digital: Comment changer la nouvelle économie d'IA en analysant la nouvelle architecture Elizaos V2?
Mar 04, 2025 pm 07:00 PM
ElizaOSV2: L'autonomisation de l'IA et de la direction de la nouvelle économie de WEB3. Cet article plongera dans les principales innovations d'ElizaOSV2 et comment elle façonne une économie future axée sur l'IA. Automatisation de l'IA: Aller exploiter indépendamment Elizaos était à l'origine un cadre d'IA axé sur l'automatisation Web3. La version V1 permet à l'IA d'interagir avec les contrats intelligents et les données de la blockchain, tandis que la version V2 atteint des améliorations de performances significatives. Au lieu d'exécuter simplement des instructions simples, l'IA peut gérer indépendamment les workflows, exploiter des affaires et développer des stratégies financières. Mise à niveau de l'architecture: amélioré un
