
 Périphériques technologiques
IA
Nouveau benchmark de test publié, le Llama 3 open source le plus puissant est gêné
Périphériques technologiques
IA
Nouveau benchmark de test publié, le Llama 3 open source le plus puissant est gêné
Nouveau benchmark de test publié, le Llama 3 open source le plus puissant est gêné

Si les questions du test sont trop faciles, les meilleurs étudiants comme les mauvais étudiants peuvent obtenir 90 points, et l'écart ne peut pas être creusé...
Avec la sortie de modèles plus puissants tels que Claude 3, Llama 3 et même GPT-5 , l'industrie a un besoin urgent d'un modèle plus difficile et de tests de référence plus différenciés.
LMSYS, l'organisation derrière le grand modèle Arena, a lancé la référence de nouvelle génération Arena-Hard, qui a attiré une large attention.
La dernière référence est également disponible pour la force des deux versions d'instructions affinées de Llama 3.
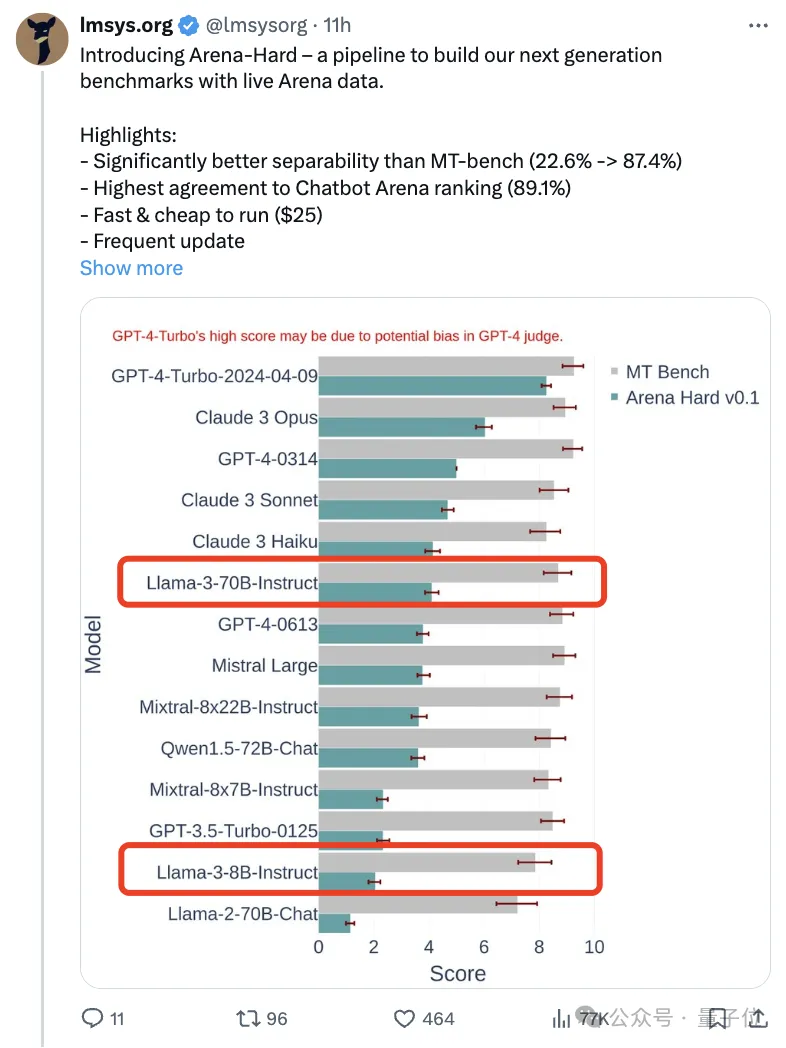
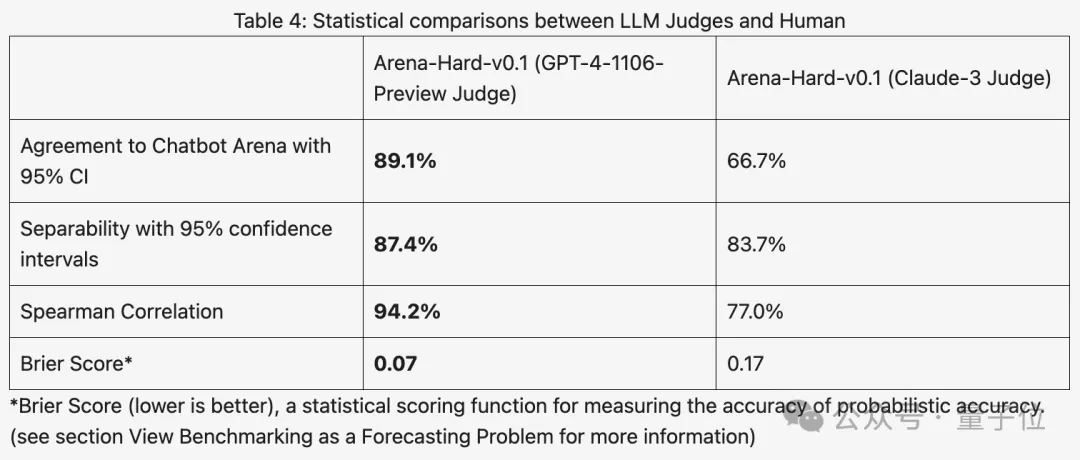
Par rapport au précédent MT Bench, qui avait des scores similaires, la discrimination Arena-Hard est passée de 22,6% à 87,4%, ce qui est clair en un coup d'œil.
Arena-Hard est construit à partir de données humaines en temps réel provenant de l'arène, et le taux de cohérence avec les préférences humaines atteint 89,1 %.
En plus des deux indicateurs ci-dessus atteignant SOTA, il y a un avantage supplémentaire :
Les données de test mises à jour en temps réel contiennent des mots d'invite nouvellement inventés par les humains et jamais vus par l'IA pendant la phase d'entraînement, atténuant ainsi les données potentielles. .
Après avoir publié un nouveau modèle, vous n'avez plus besoin d'attendre environ une semaine pour que les utilisateurs humains votent, il suffit de dépenser 25 $ pour exécuter rapidement le pipeline de test et obtenir les résultats.
Certains internautes ont fait remarquer qu'il est très important d'utiliser de vrais mots d'invite pour les utilisateurs au lieu des examens du secondaire pour les tests.

Comment fonctionne le nouveau benchmark ?
Pour faire simple, 500 mots d'invite de haute qualité sont sélectionnés comme ensemble de test parmi 200 000 requêtes d'utilisateurs dans le domaine des grands modèles.
Tout d'abord, veillez à la diversité pendant le processus de sélection, c'est-à-dire que l'ensemble de tests doit couvrir un large éventail de sujets du monde réel.
Pour garantir cela, l'équipe a adopté le pipeline de modélisation de sujets dans BERTopic, en convertissant d'abord chaque astuce à l'aide du modèle d'intégration d'OpenAI (text-embedding-3-small), en réduisant la dimensionnalité à l'aide d'UMAP et en regroupant à l'aide d'un algorithme de modèle basé sur la hiérarchie ( HDBSCAN) pour identifier les clusters, et enfin utiliser GPT-4-turbo pour l'agrégation.
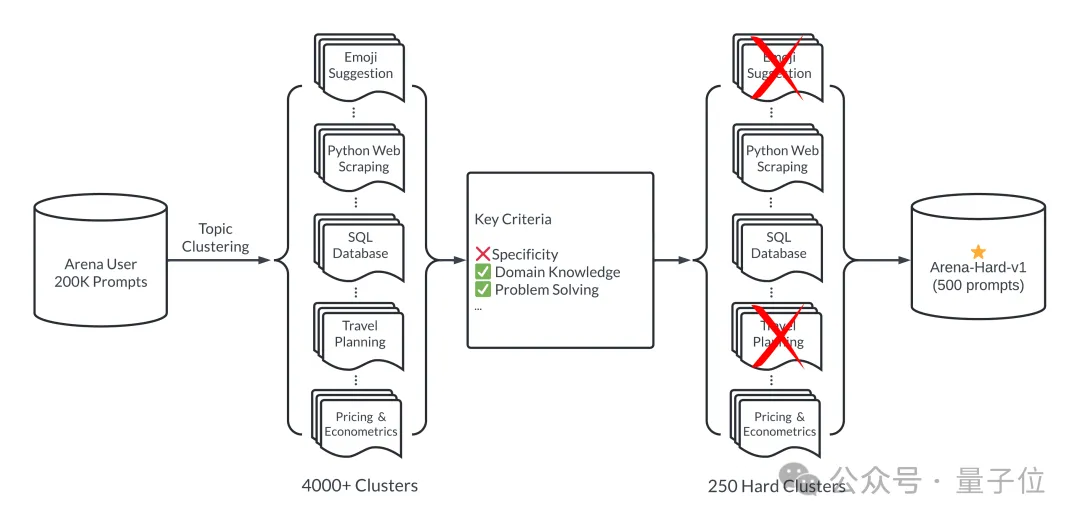
Assurez-vous également que les mots d'invite sélectionnés sont de haute qualité, qui sont mesurés par sept indicateurs clés :
- Spécificité : le mot d'invite nécessite-t-il un résultat spécifique ?
- Connaissance du domaine : le mot d'invite couvre-t-il un ou plusieurs domaines spécifiques ?
- Complexité : le mot d'invite comporte-t-il plusieurs niveaux de raisonnement, de composants ou de variables ?
- Résolution de problèmes : le mot d'invite permet-il directement à l'IA de démontrer sa capacité à résoudre les problèmes de manière proactive ?
- Créativité : le mot d'invite implique-t-il un certain niveau de créativité dans la résolution de problèmes ?
- Précision technique : le mot d'invite nécessite-t-il une précision technique dans la réponse ?
- Application pratique : les mots-clés sont-ils pertinents pour les applications pratiques ?

Utilisez GPT-3.5-Turbo et GPT-4-Turbo pour annoter chaque astuce de 0 à 7 afin de déterminer combien de conditions sont remplies. Chaque cluster est ensuite noté sur la base du score moyen des indices.
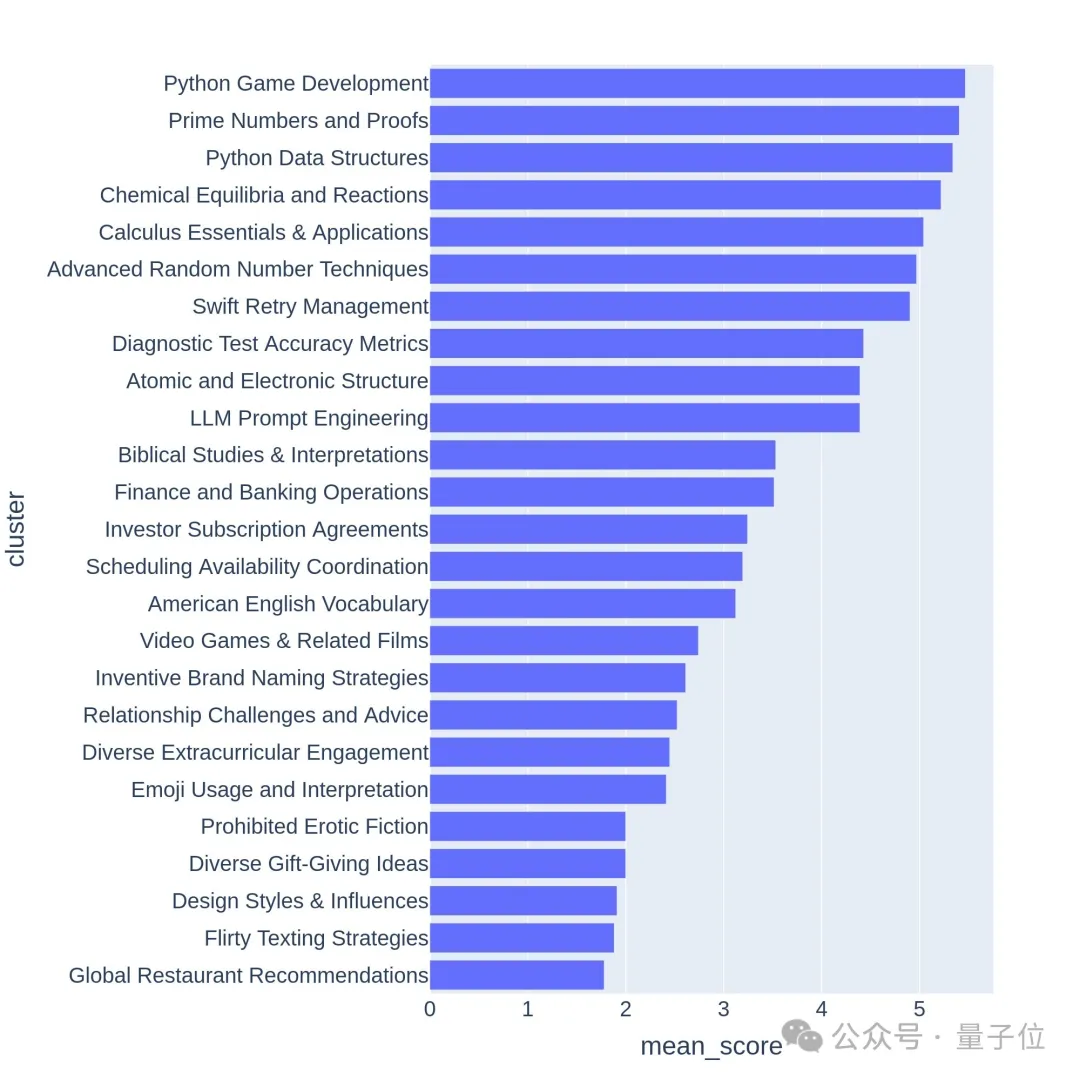
Les questions de haute qualité sont généralement liées à des sujets ou à des tâches difficiles, tels que le développement de jeux ou des preuves mathématiques.
Le nouveau benchmark est-il précis ?
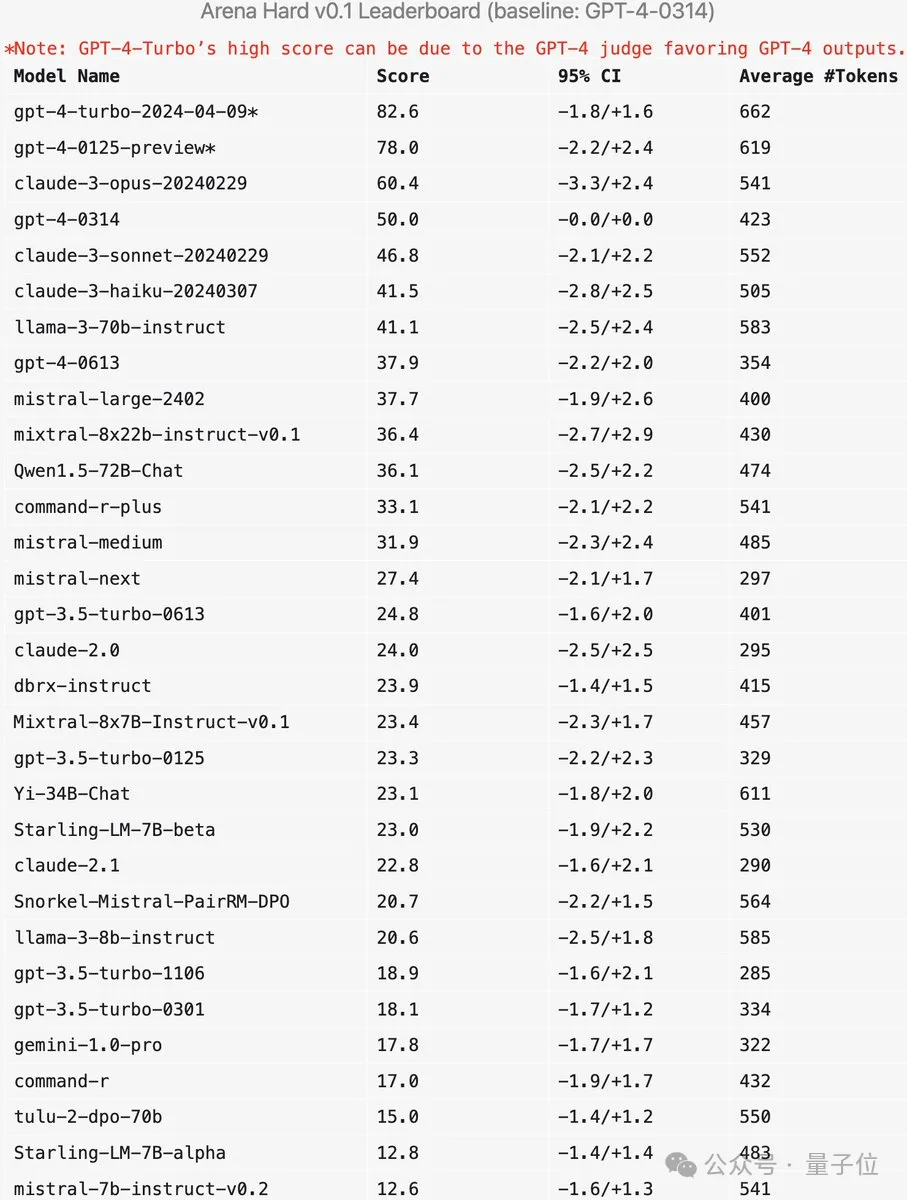
Arena-Hard a actuellement une faiblesse : utiliser GPT-4 comme arbitre préfère sa propre sortie. Les responsables ont également donné des conseils correspondants.
On peut voir que les scores des deux dernières versions de GPT-4 sont bien supérieurs à ceux de Claude 3 Opus, mais la différence dans les scores de vote humain n'est pas si évidente.
En fait, sur ce point, des recherches récentes ont démontré que les modèles de pointe préféreront leur propre production.

L'équipe de recherche a également découvert que l'IA peut intrinsèquement déterminer si un morceau de texte a été écrit par elle-même. Après un réglage fin, la capacité d'auto-reconnaissance peut être améliorée et la capacité d'auto-reconnaissance est linéairement liée à l'auto-reconnaissance. préférence.
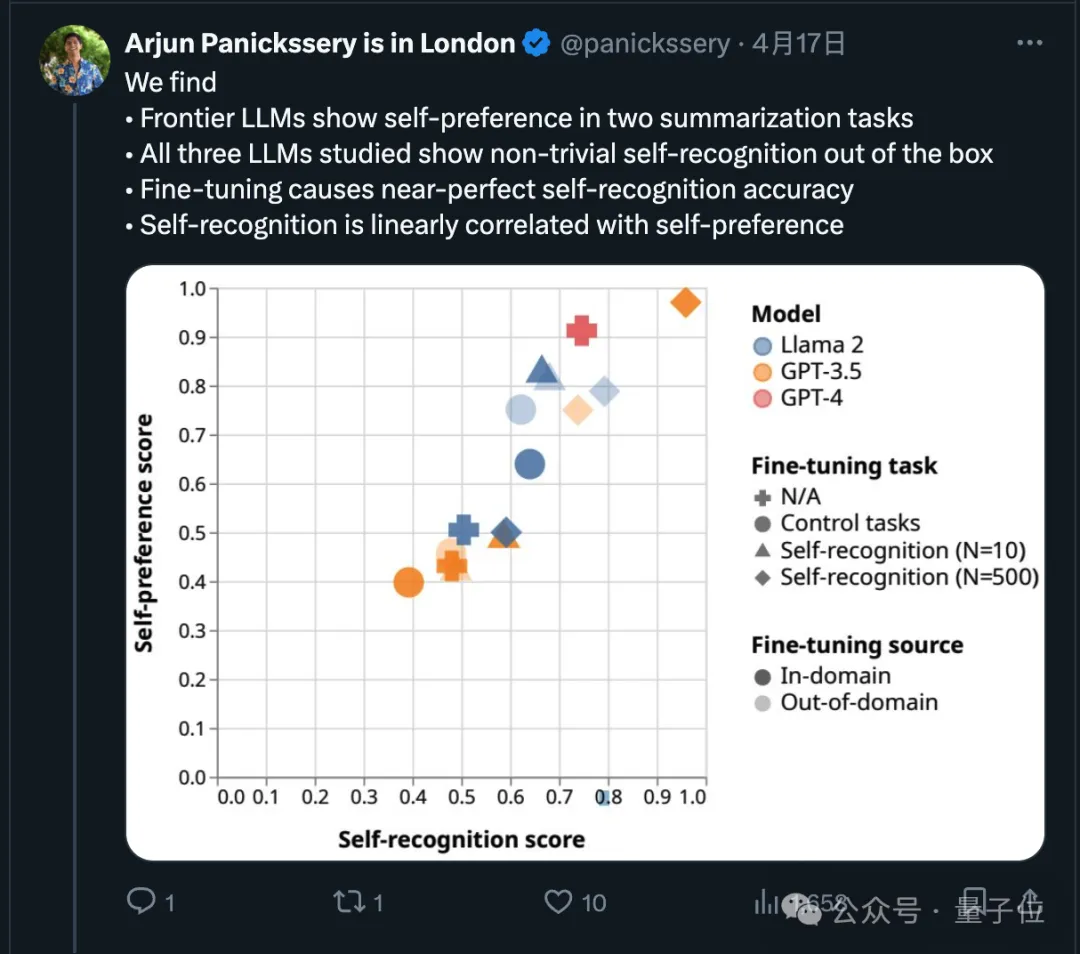
Alors, comment l'utilisation de Claude 3 pour la notation changera-t-elle les résultats ? LMSYS a également réalisé des expériences pertinentes.
Tout d'abord, les scores de la série Claude vont effectivement augmenter.
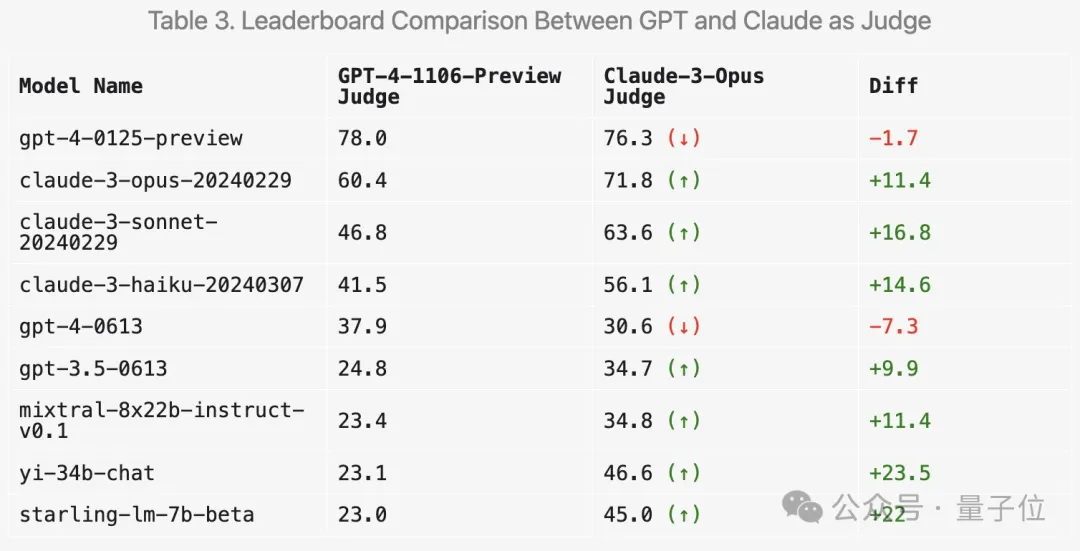
Mais étonnamment, il préfère plusieurs modèles ouverts tels que Mixtral et Zero One Thousand Yi, et obtient même des scores nettement plus élevés sur GPT-3.5.
Dans l'ensemble, la discrimination et la cohérence avec les résultats humains obtenus avec Claude 3 ne sont pas aussi bonnes que GPT-4.
De nombreux internautes ont suggéré d'utiliser plusieurs grands modèles pour une notation complète.
De plus, l'équipe a également mené davantage d'expériences d'ablation pour vérifier l'efficacité du nouveau test de référence.
Par exemple, si vous ajoutez « rendre la réponse aussi détaillée que possible » dans le mot d'invite, la longueur moyenne de sortie sera plus élevée et le score s'améliorera effectivement.
Mais en changeant le mot d'invite en "aime discuter", la durée moyenne de sortie a également augmenté, mais l'amélioration du score n'était pas évidente.
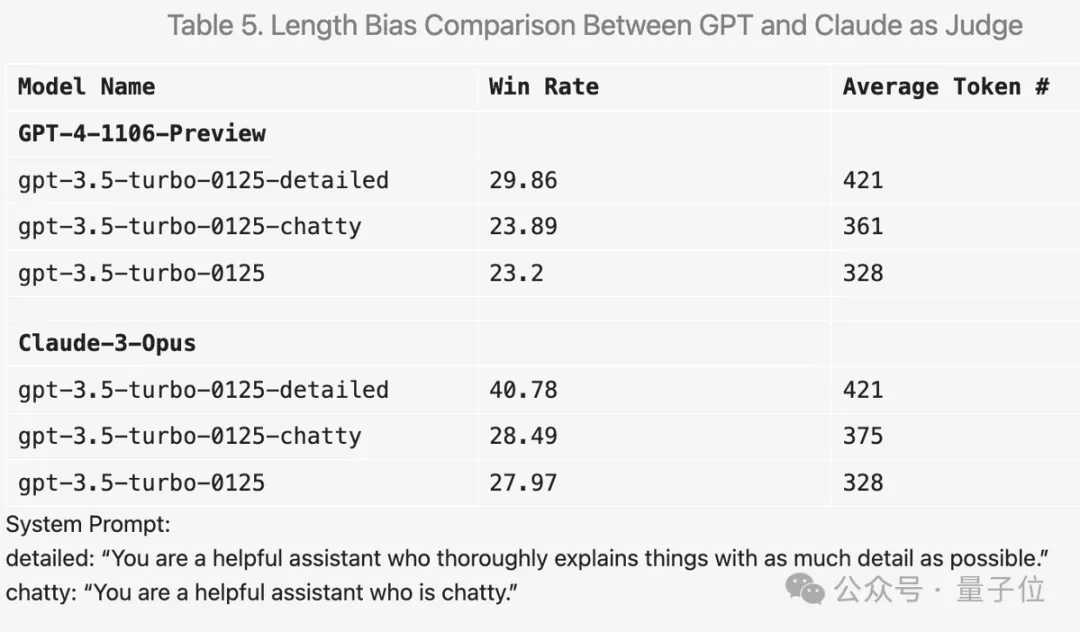
De plus, de nombreuses découvertes intéressantes ont eu lieu au cours de l'expérience.
Par exemple, GPT-4 est très strict dans la notation. S'il y a des erreurs dans la réponse, des points seront sévèrement déduits tandis que Claude 3 sera indulgent même s'il reconnaît de petites erreurs.
Pour les questions de code, Claude 3 a tendance à fournir des réponses avec une structure simple, ne s'appuie pas sur des bibliothèques de codes externes et peut aider les humains à apprendre la programmation tandis que GPT-4-Turbo préfère les réponses les plus pratiques, quel que soit leur niveau de formation ; valeur.
De plus, même si la température est réglée sur 0, GPT-4-Turbo peut produire des jugements légèrement différents.
Il ressort également des 64 premiers clusters de la visualisation hiérarchique que la qualité et la diversité des questions posées par les utilisateurs de la grande arène des modèles sont effectivement élevées.
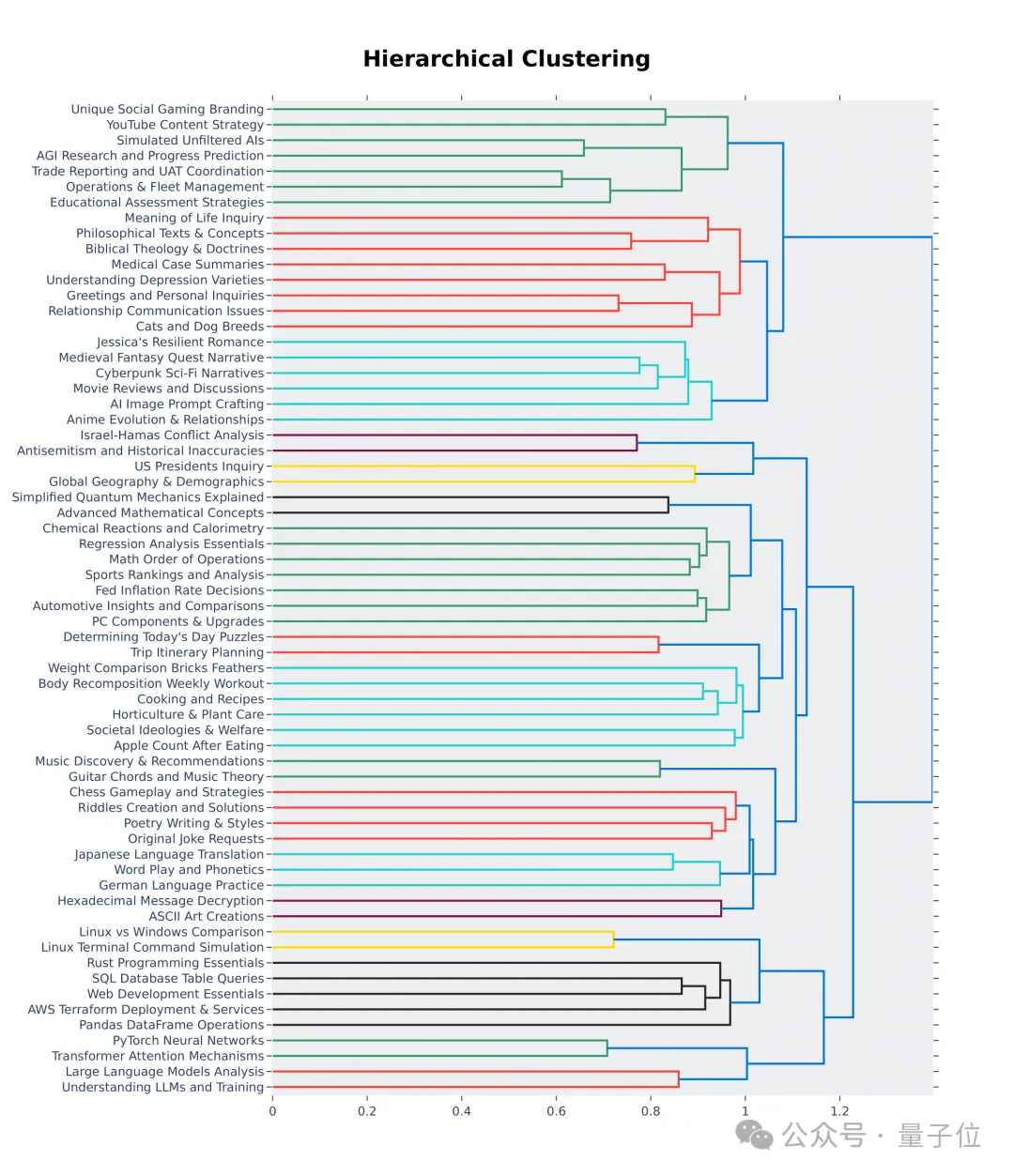
Peut-être y a-t-il votre contribution là-dedans.
Arena-Hard GitHub : https://github.com/lm-sys/arena-hard
Arena-Hard HuggingFace : https://huggingface.co/spaces/lmsys/arena-hard-browser
Grand modèle Arena : https://arena.lmsys.org
Lien de référence :
[1]https://x.com/lmsysorg/status/1782179997622649330
[2]https://lmsys.org/blog/2024-04 - 19-arène-dur/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
La bibliothèque utilisée pour le fonctionnement du numéro de point flottante dans le langage go présente comment s'assurer que la précision est ...
 Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
L'exécution du projet H5 nécessite les étapes suivantes: Installation des outils nécessaires tels que le serveur Web, Node.js, les outils de développement, etc. Créez un environnement de développement, créez des dossiers de projet, initialisez les projets et écrivez du code. Démarrez le serveur de développement et exécutez la commande à l'aide de la ligne de commande. Aperçu du projet dans votre navigateur et entrez l'URL du serveur de développement. Publier des projets, optimiser le code, déployer des projets et configurer la configuration du serveur Web.
 Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
GiteEpages STATIQUE Le déploiement du site Web a échoué: 404 Dépannage des erreurs et résolution lors de l'utilisation de Gitee ...
 Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Dans le cadre du cadre de beegoorm, comment spécifier la base de données associée au modèle? De nombreux projets Beego nécessitent que plusieurs bases de données soient opérées simultanément. Lorsque vous utilisez Beego ...
 Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou des projets open source bien connus? Lors de la programmation en Go, les développeurs rencontrent souvent des besoins communs, ...
 Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Le problème de l'utilisation de Redessstream pour implémenter les files d'attente de messages dans le langage GO consiste à utiliser le langage GO et redis ...
 La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La page H5 doit être maintenue en continu, en raison de facteurs tels que les vulnérabilités du code, la compatibilité des navigateurs, l'optimisation des performances, les mises à jour de sécurité et les améliorations de l'expérience utilisateur. Des méthodes de maintenance efficaces comprennent l'établissement d'un système de test complet, à l'aide d'outils de contrôle de version, de surveiller régulièrement les performances de la page, de collecter les commentaires des utilisateurs et de formuler des plans de maintenance.
 Lorsque vous utilisez SQL.Open, pourquoi ne signale pas une erreur lorsque DSN passe vide?
Apr 02, 2025 pm 12:54 PM
Lorsque vous utilisez SQL.Open, pourquoi ne signale pas une erreur lorsque DSN passe vide?
Apr 02, 2025 pm 12:54 PM
Lorsque vous utilisez SQL.Open, pourquoi le DSN ne signale-t-il pas une erreur? En langue go, sql.open ...
