
 Périphériques technologiques
IA
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Périphériques technologiques
IA
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)

Écrit devant
Lien du projet : https://nianticlabs.github.io/mickey/
Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle.
Cet article propose MicKey, un processus de correspondance de points clés qui peut prédire les correspondances métriques dans l'espace d'une caméra tridimensionnelle. En apprenant la correspondance des coordonnées 3D sur les images, nous sommes en mesure de déduire une pose relative métrique sans test de profondeur. Il n’est pas non plus nécessaire de procéder à des tests de profondeur, à une reconstruction de scène ou à des informations de chevauchement d’images pendant la formation. MicKey est supervisé uniquement par des paires d'images et leurs poses relatives. MicKey atteint des performances de pointe sur les tests de relocalisation sans carte tout en nécessitant moins de supervision que les autres méthodes concurrentes.
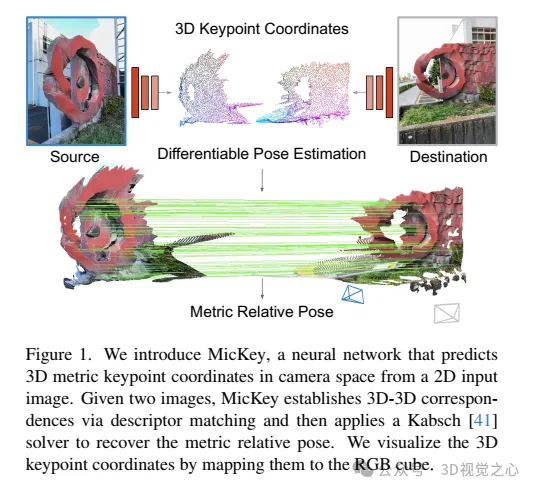
"Metric+Keypoints (MicKey) est un processus de détection de fonctionnalités qui résout deux problèmes. Premièrement, MicKey régresse les emplacements des points clés dans l'espace de la caméra, ce qui permet d'établir des correspondances métriques grâce à la correspondance de descripteurs. À partir des métriques Dans la correspondance, la métrique relative La pose peut être récupérée, comme le montre la figure 1. Deuxièmement, en utilisant l'optimisation de pose différentiable pour la formation de bout en bout, MicKey n'a besoin que de paires d'images et de leurs véritables poses relatives sans supervision pendant le processus de formation. profondeur des points clés implicitement et uniquement pour les régions caractéristiques trouvées avec précision. Notre processus de formation est robuste aux paires d'images avec un chevauchement visuel inconnu, de sorte que les informations obtenues par SFM (telles que le chevauchement d'images) ne sont pas nécessaires. Cette faible supervision rend MicKey très accessible et. attrayant car l'entraîner sur de nouveaux domaines ne nécessite aucune information supplémentaire à l'exception de la pose. »
Dans le test de relocalisation sans carte, MicKey est arrivé en tête, surpassant les méthodes de pointe récentes. MicKey fournit une estimation fiable de la pose à l'échelle métrique, même sous des changements d'angle de vue extrêmes, pris en charge par une prédiction de profondeur spécifiquement ciblée sur la correspondance de caractéristiques clairsemées. La correspondance des déformations sous des changements d'angle de vue extrêmes prises en charge par cette précision rend MicKey idéal pour prendre en charge l'estimation de la profondeur nécessaire à la correspondance de l'estimation de la profondeur prise en charge par la prédiction de la profondeur spécifiquement pour la correspondance des caractéristiques clairsemées.
Les principales contributions sont les suivantes :
MicKey est un réseau de neurones capable de prédire les points clés à partir d'une seule image et de les décrire. De tels descripteurs peuvent permettre d'estimer des poses relatives métriques entre les images.
Cette stratégie de formation ne nécessite qu'une surveillance de la pose relative, aucune mesure de profondeur et aucune connaissance du chevauchement des paires d'images.
Introduction à MicKey
MicKey prédit les coordonnées tridimensionnelles des points clés dans l'espace de la caméra. Le réseau prédit également les probabilités de sélection de points clés (distribution des points clés) et les descripteurs qui guident la probabilité de correspondance (distribution de correspondance). En combinant ces deux distributions, nous obtenons la probabilité que deux points clés deviennent des points correspondants et optimisons le réseau pour rendre les points correspondants plus susceptibles d'apparaître. Dans une boucle RANSAC différentiable, plusieurs hypothèses de pose relative sont générées et leurs pertes par rapport à la vraie transformation sont calculées. Générez des gradients via REINFORCE pour entraîner les probabilités correspondantes. Étant donné que notre solveur de pose et notre fonction de perte sont différentiables, la rétropropagation fournit également un signal direct pour la formation des coordonnées des points clés 3D.
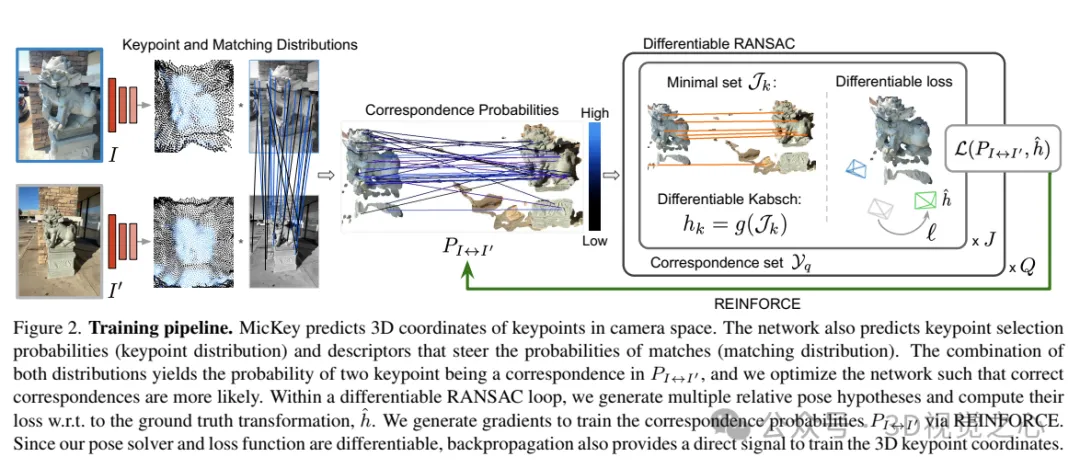
1) Apprentissage supervisé par pose métrique
À partir de deux images, calculez leurs poses relatives métriques, ainsi que les scores des points clés, les probabilités d'appariement et les confiances de pose (sous la forme de décomptes d'inliers souples). Notre objectif est de former tous les modules d'estimation de pose relative de bout en bout. Pendant le processus de formation, nous supposons que les données de formation se trouvent où se trouve la transformation réelle et K/K' est le paramètre intrinsèque de la caméra. Le diagramme schématique de l’ensemble du système est présenté à la figure 2.
Afin d'apprendre les coordonnées, la confiance et les descripteurs des points clés 3D, nous avons besoin que le système soit entièrement différentiable. Cependant, étant donné que certains éléments du pipeline ne sont pas différenciables, comme l'échantillonnage de points clés ou le comptage inlier, le pipeline d'estimation de pose relative est redéfini comme probabiliste. Cela signifie que nous traitons la sortie du réseau comme la probabilité d'une correspondance potentielle et que, pendant l'entraînement, le réseau optimise sa sortie pour générer des probabilités telles que la correspondance correcte ait plus de chances d'être sélectionnée.
2) Structure du réseau
MicKey suit une architecture de réseau multi-têtes avec un encodeur partagé qui déduit des points clés métriques 3D ainsi que des descripteurs à partir de l'image d'entrée, comme le montre la figure 3.
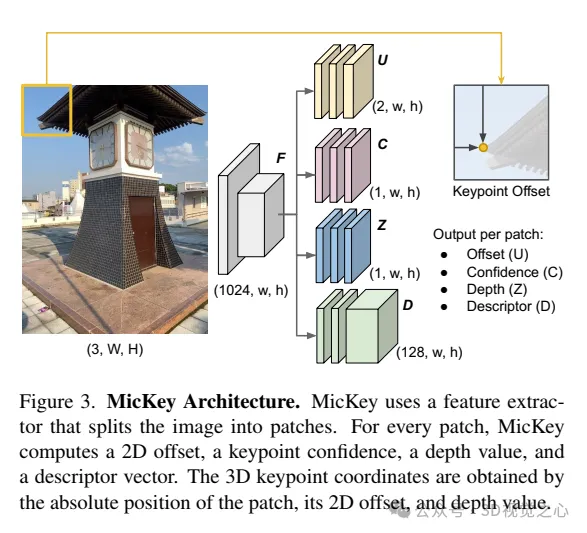
Encodeur. Adoptez un modèle DINOv2 pré-entraîné comme extracteur de fonctionnalités et utilisez ses fonctionnalités directement sans formation ni réglage supplémentaire. DINOv2 divise l'image d'entrée en blocs de taille 14 × 14 et fournit un vecteur de caractéristiques pour chaque bloc. La carte de caractéristiques finale F a une résolution de (1024, w, h), où w = W/14 et h = H/14.
Le point clé est la tête. Quatre têtes parallèles sont définies ici, qui traitent la carte de caractéristiques F et calculent les cartes de décalage xy (U), de profondeur (Z), de confiance (C) et de descripteur (D) où chaque entrée de la carte correspond à l'entrée A 14 ; Bloc ×14 dans l’image. MicKey a la propriété rare de prédire les points clés sous forme de décalages relatifs à partir d'une grille régulière clairsemée. Les coordonnées 2D absolues sont obtenues comme suit :
Comparaison expérimentale
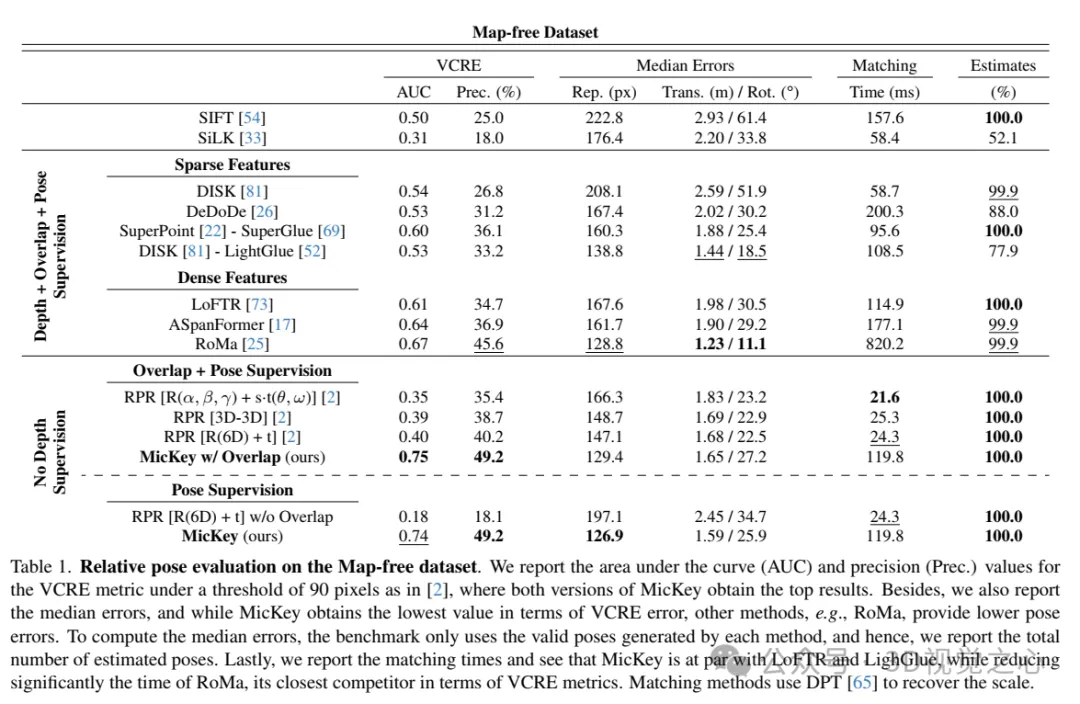
Évaluation de pose relative sur des jeux de données sans carte. Les valeurs d'aire sous la courbe (AUC) et de précision (Prec.) Pour la métrique VCRE à un seuil de 90 pixels sont rapportées, les deux versions de MicKey obtenant les résultats les plus élevés. De plus, l'erreur médiane est également signalée, et bien que MicKey obtienne la valeur la plus faible en termes d'erreur VCRE, d'autres méthodes, telles que RoMa, fournissent des erreurs de pose plus faibles. Pour calculer l'erreur médiane, la ligne de base utilise uniquement des poses valides générées par chaque méthode. Nous rapportons donc le nombre total estimé de poses. Enfin, les temps de correspondance sont rapportés et MicKey s'avère comparable à LoFTR et LighGlue, tout en réduisant considérablement les temps de RoMa, le concurrent le plus proche de MicKey en termes de métriques VCRE. La méthode de correspondance utilise DPT pour récupérer l'échelle.
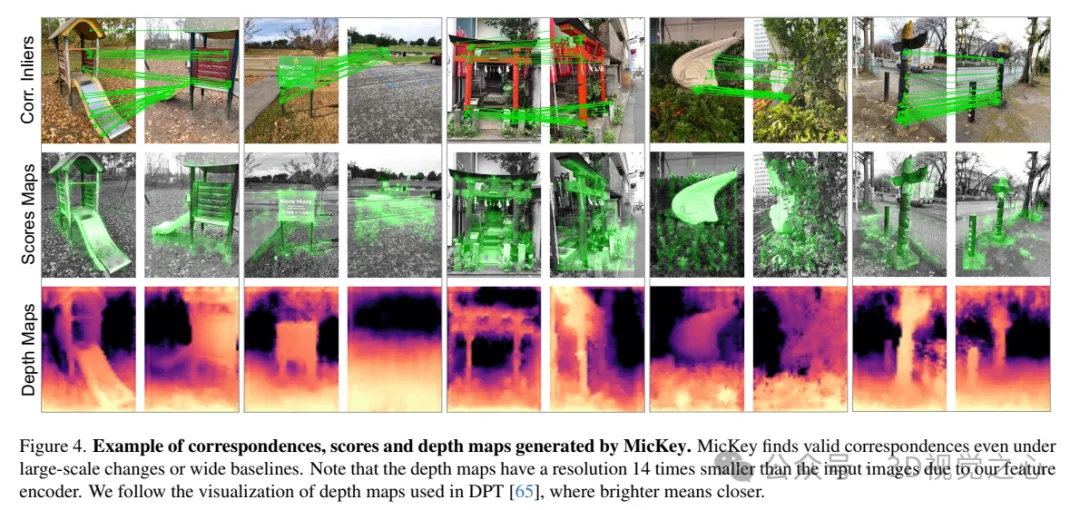
Exemple de points de correspondance, scores et cartes de profondeur générés par MicKey. MicKey trouve des points de correspondance efficaces même en présence de changements à grande échelle ou de lignes de base larges. Notez qu'en raison de notre encodeur de fonctionnalités, la résolution de la carte de profondeur est 14 fois plus petite que l'image d'entrée. Nous suivons la méthode de visualisation de carte de profondeur utilisée dans DPT, où les couleurs plus claires représentent des distances plus proches.
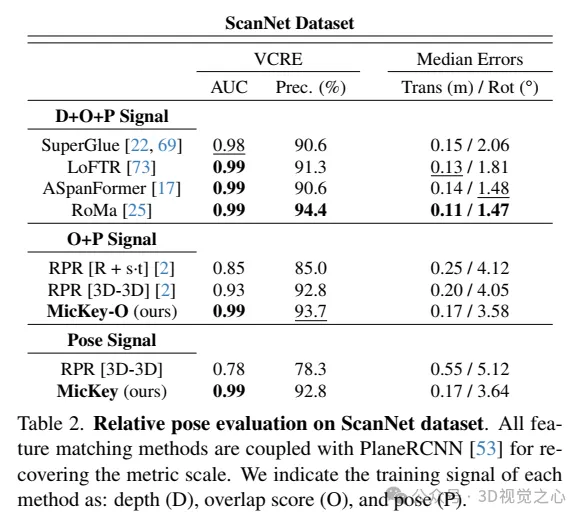
Évaluation de pose relative sur l'ensemble de données ScanNet. Toutes les méthodes de correspondance de fonctionnalités sont utilisées conjointement avec PlaneRCNN pour récupérer les échelles métriques. Nous indiquons les signaux d'entraînement pour chaque méthode : profondeur (D), score de chevauchement (O) et pose (P).


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
La bibliothèque utilisée pour le fonctionnement du numéro de point flottante dans le langage go présente comment s'assurer que la précision est ...
 Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
L'exécution du projet H5 nécessite les étapes suivantes: Installation des outils nécessaires tels que le serveur Web, Node.js, les outils de développement, etc. Créez un environnement de développement, créez des dossiers de projet, initialisez les projets et écrivez du code. Démarrez le serveur de développement et exécutez la commande à l'aide de la ligne de commande. Aperçu du projet dans votre navigateur et entrez l'URL du serveur de développement. Publier des projets, optimiser le code, déployer des projets et configurer la configuration du serveur Web.
 Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
GiteEpages STATIQUE Le déploiement du site Web a échoué: 404 Dépannage des erreurs et résolution lors de l'utilisation de Gitee ...
 Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Dans le cadre du cadre de beegoorm, comment spécifier la base de données associée au modèle? De nombreux projets Beego nécessitent que plusieurs bases de données soient opérées simultanément. Lorsque vous utilisez Beego ...
 Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou des projets open source bien connus? Lors de la programmation en Go, les développeurs rencontrent souvent des besoins communs, ...
 La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La page H5 doit être maintenue en continu, en raison de facteurs tels que les vulnérabilités du code, la compatibilité des navigateurs, l'optimisation des performances, les mises à jour de sécurité et les améliorations de l'expérience utilisateur. Des méthodes de maintenance efficaces comprennent l'établissement d'un système de test complet, à l'aide d'outils de contrôle de version, de surveiller régulièrement les performances de la page, de collecter les commentaires des utilisateurs et de formuler des plans de maintenance.
 Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Le problème de l'utilisation de Redessstream pour implémenter les files d'attente de messages dans le langage GO consiste à utiliser le langage GO et redis ...
 Comment améliorer la précision de la segmentation des mots jieba dans l'analyse des commentaires pittoresques?
Apr 02, 2025 am 07:09 AM
Comment améliorer la précision de la segmentation des mots jieba dans l'analyse des commentaires pittoresques?
Apr 02, 2025 am 07:09 AM
Comment résoudre le problème de la segmentation des mots jieba dans l'analyse des commentaires pittoresques? Lorsque nous effectuons des commentaires et des analyses pittoresques, nous utilisons souvent l'outil de segmentation des mots jieba pour traiter le texte ...
