
 Périphériques technologiques
IA
CVPR 2024 | Un modèle général de fusion d'images basé sur MoE, ajoutant 2,8 % de paramètres pour effectuer plusieurs tâches
Périphériques technologiques
IA
CVPR 2024 | Un modèle général de fusion d'images basé sur MoE, ajoutant 2,8 % de paramètres pour effectuer plusieurs tâches
CVPR 2024 | Un modèle général de fusion d'images basé sur MoE, ajoutant 2,8 % de paramètres pour effectuer plusieurs tâches


La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com.

Lien papier : https://arxiv.org/abs/2403.12494 Lien code : https://github.com/YangSun22/TC-MoA Titre du papier : Mélange d'adaptateurs personnalisés en fonction des tâches pour la fusion générale d'images

- Nous proposons une méthode de régularisation mutuelle des informations pour les adaptateurs, qui permet à notre modèle d'identifier plus précisément l'intensité dominante des différentes images sources.
- Au meilleur de nos connaissances, nous proposons pour la première fois un adaptateur flexible basé sur MoE. En ajoutant seulement 2,8 % des paramètres apprenables, notre modèle peut gérer de nombreuses tâches de fusion. Des expériences approfondies démontrent les avantages de nos méthodes concurrentes tout en montrant une contrôlabilité et une généralisation significatives.
 , le réseau intègre des informations complémentaires provenant de différentes sources pour obtenir une image fusionnée
, le réseau intègre des informations complémentaires provenant de différentes sources pour obtenir une image fusionnée 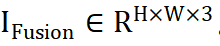 . Nous entrons l'image source dans le réseau ViT et obtenons le jeton de l'image source via la couche d'encodage du patch. ViT se compose d'un encodeur pour l'extraction de caractéristiques et d'un décodeur pour la reconstruction d'images, tous deux composés de blocs Transformer.
. Nous entrons l'image source dans le réseau ViT et obtenons le jeton de l'image source via la couche d'encodage du patch. ViT se compose d'un encodeur pour l'extraction de caractéristiques et d'un décodeur pour la reconstruction d'images, tous deux composés de blocs Transformer.  Transformer dans l'encodeur et le décodeur. Le réseau module progressivement le résultat de la fusion via ces TC-MoA. Chaque TC-MoA se compose d'une banque de routeurs spécifiques à une tâche
Transformer dans l'encodeur et le décodeur. Le réseau module progressivement le résultat de la fusion via ces TC-MoA. Chaque TC-MoA se compose d'une banque de routeurs spécifiques à une tâche  , d'une banque d'adaptateurs de partage de tâches
, d'une banque d'adaptateurs de partage de tâches  et d'une couche de fusion d'indices F. TC-MoA se compose de deux étapes principales : la génération de signaux et la fusion pilotée par signaux. Pour faciliter l'expression, nous prenons VIF comme exemple, supposons que l'entrée provient de l'ensemble de données VIF et utilisons G pour représenter
et d'une couche de fusion d'indices F. TC-MoA se compose de deux étapes principales : la génération de signaux et la fusion pilotée par signaux. Pour faciliter l'expression, nous prenons VIF comme exemple, supposons que l'entrée provient de l'ensemble de données VIF et utilisons G pour représenter  . O Figure 2 L'architecture globale de TC-MOA
. O Figure 2 L'architecture globale de TC-MOA 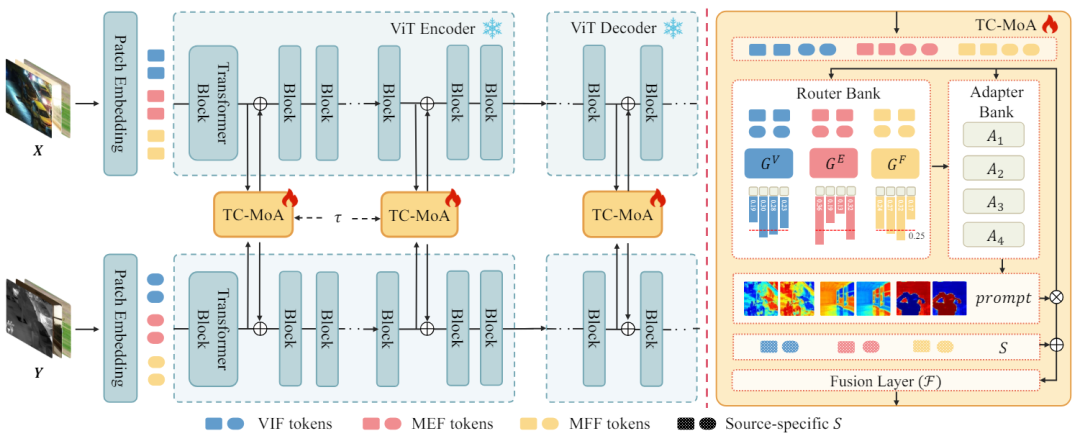
. Nous concaténons en tant que représentations de caractéristiques de paires de jetons multi-sources. Cela permet aux jetons de différentes sources d'échanger des informations au sein du réseau suivant. Cependant, le calcul direct de caractéristiques concaténées de grande dimension apportera un grand nombre de paramètres inutiles. Par conséquent, nous utilisons


 Ensuite, en fonction de la tâche à laquelle Φ appartient, nous sélectionnons un routeur spécifique à la tâche dans la banque de routeurs pour personnaliser le schéma de routage, c'est-à-dire quel adaptateur dans la banque d'adaptateurs doit être saisi pour chaque paire de jetons source.
Ensuite, en fonction de la tâche à laquelle Φ appartient, nous sélectionnons un routeur spécifique à la tâche dans la banque de routeurs pour personnaliser le schéma de routage, c'est-à-dire quel adaptateur dans la banque d'adaptateurs doit être saisi pour chaque paire de jetons source. 

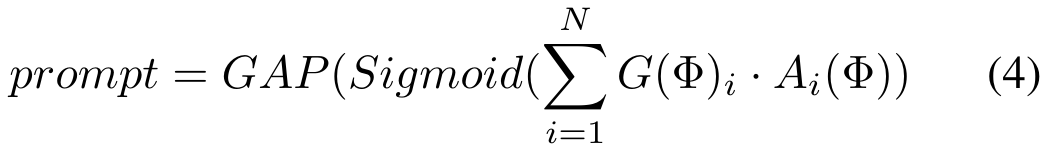
 , puis obtenons les caractéristiques de fusion via la couche de fusion F. Le processus est le suivant :
, puis obtenons les caractéristiques de fusion via la couche de fusion F. Le processus est le suivant : 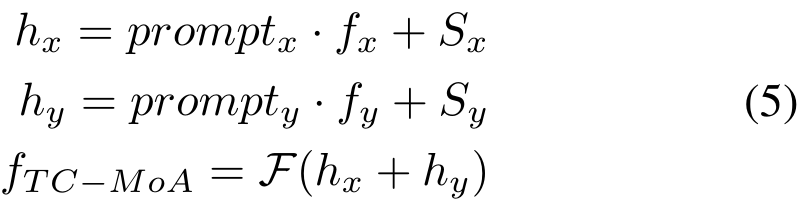
 est un hyperparamètre) :
est un hyperparamètre) : 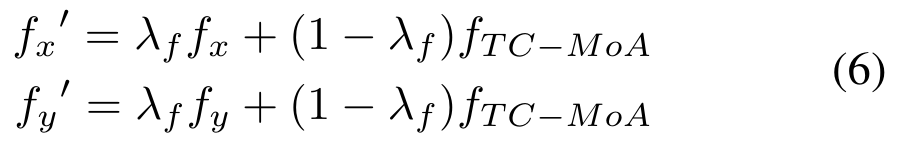




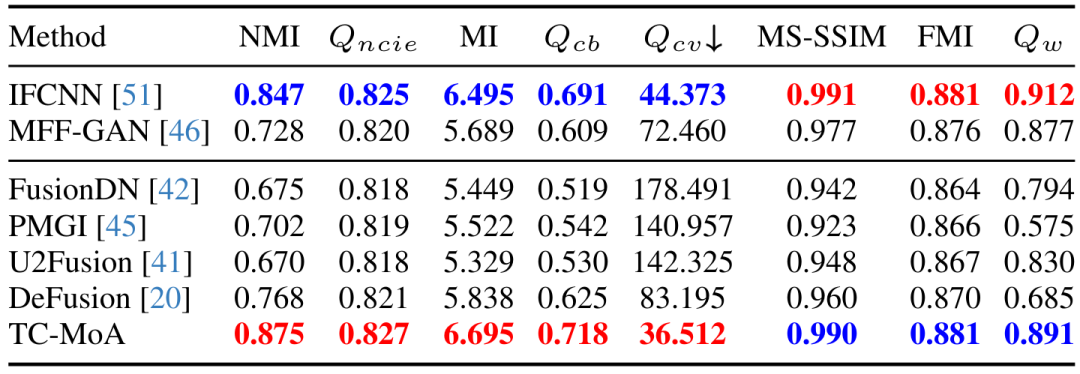 Tableau 3 Ensemble de données LLVIP de la tâche MFF L'expérience comparative quantitative de l'ensemble de données LLVIP
Tableau 3 Ensemble de données LLVIP de la tâche MFF L'expérience comparative quantitative de l'ensemble de données LLVIP
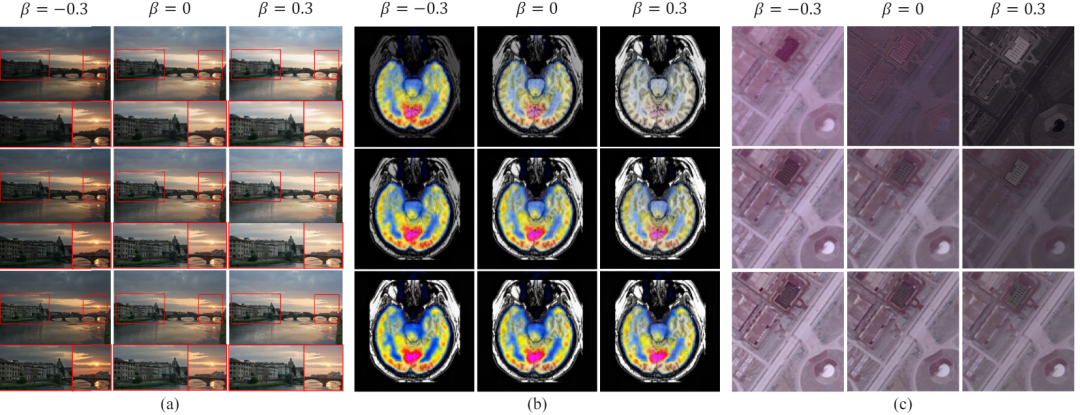 de la tâche de la figure 6 Contrôlabilité et généralisation à des tâches inconnues
de la tâche de la figure 6 Contrôlabilité et généralisation à des tâches inconnues
Contrôleabilité et généralisation
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
La bibliothèque utilisée pour le fonctionnement du numéro de point flottante dans le langage go présente comment s'assurer que la précision est ...
 Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
GiteEpages STATIQUE Le déploiement du site Web a échoué: 404 Dépannage des erreurs et résolution lors de l'utilisation de Gitee ...
 Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
L'exécution du projet H5 nécessite les étapes suivantes: Installation des outils nécessaires tels que le serveur Web, Node.js, les outils de développement, etc. Créez un environnement de développement, créez des dossiers de projet, initialisez les projets et écrivez du code. Démarrez le serveur de développement et exécutez la commande à l'aide de la ligne de commande. Aperçu du projet dans votre navigateur et entrez l'URL du serveur de développement. Publier des projets, optimiser le code, déployer des projets et configurer la configuration du serveur Web.
 Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou des projets open source bien connus? Lors de la programmation en Go, les développeurs rencontrent souvent des besoins communs, ...
 Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Dans le cadre du cadre de beegoorm, comment spécifier la base de données associée au modèle? De nombreux projets Beego nécessitent que plusieurs bases de données soient opérées simultanément. Lorsque vous utilisez Beego ...
 La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La page H5 doit être maintenue en continu, en raison de facteurs tels que les vulnérabilités du code, la compatibilité des navigateurs, l'optimisation des performances, les mises à jour de sécurité et les améliorations de l'expérience utilisateur. Des méthodes de maintenance efficaces comprennent l'établissement d'un système de test complet, à l'aide d'outils de contrôle de version, de surveiller régulièrement les performances de la page, de collecter les commentaires des utilisateurs et de formuler des plans de maintenance.
 Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Le problème de l'utilisation de Redessstream pour implémenter les files d'attente de messages dans le langage GO consiste à utiliser le langage GO et redis ...
 Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Description de la question: Comment obtenir les données de la région d'expédition de la version à l'étranger? Y a-t-il des ressources prêtes à l'emploi disponibles? Soyez précis dans le commerce électronique transfrontalier ou les entreprises mondialisées ...
