
 Périphériques technologiques
IA
Au-delà de BEVFormer ! CR3DT : RV Fusion facilite la détection et le suivi 3D du nouveau SOTA (ETH)
Périphériques technologiques
IA
Au-delà de BEVFormer ! CR3DT : RV Fusion facilite la détection et le suivi 3D du nouveau SOTA (ETH)
Au-delà de BEVFormer ! CR3DT : RV Fusion facilite la détection et le suivi 3D du nouveau SOTA (ETH)

Écrit devant et compréhension personnelle de l'auteur
Cet article présente une méthode de fusion caméra-radar à ondes millimétriques (CR3DT) pour la détection de cibles 3D et le suivi multi-cibles. La méthode basée sur le lidar a établi une norme élevée dans ce domaine, mais sa puissance de calcul élevée et son coût élevé ont limité le développement de cette solution dans le domaine de la conduite autonome ; les solutions de détection et de suivi de cibles 3D basées sur une caméra sont dues à leur haute qualité. coût Il est relativement faible et a attiré l'attention de nombreux chercheurs, mais en raison de ses mauvais résultats. La fusion des caméras et du radar à ondes millimétriques devient donc une solution prometteuse. Dans le cadre de la caméra existante BEVDet, l'auteur fusionne les informations spatiales et de vitesse du radar à ondes millimétriques et les combine avec la tête de suivi CC-3DT++ pour améliorer considérablement la précision de la détection et du suivi des cibles 3D et neutraliser la contradiction entre performances et coût.
Contribution principale
Architecture de fusion de capteursLe CR3DT proposé utilise une technologie de fusion intermédiaire avant et après l'encodeur BEV pour intégrer les données radar à ondes millimétriques tandis que pour le suivi, une tête d'intégration d'apparence quasi-dense est utilisée, Target ; corrélation utilisant l'estimation de la vitesse à partir d'un radar à ondes millimétriques.
Évaluation des performances de détection CR3DT a obtenu 35,1 % de mAP et 45,6 % de score de détection (NDS) nuScenes sur l'ensemble de validation de détection 3D nuScenes. Tirant parti des riches informations de vitesse contenues dans les données radar, l'erreur de vitesse moyenne (mAVE) du détecteur est réduite de 45,3 % par rapport aux détecteurs de caméra SOTA.
Évaluation des performances de suivi Les performances de suivi de CR3DT sur l'ensemble de validation de suivi nuScenes sont de 38,1 % AMOTA, une amélioration AMOTA de 14,9 % par rapport au modèle de suivi SOTA avec caméra uniquement, l'utilisation explicite des informations de vitesse dans le tracker et d'autres améliorations a considérablement réduit le nombre d’IDS d’environ 43 %.
Architecture du modèle
Cette méthode est basée sur le cadre EV-Det, fusionne les informations spatiales et de vitesse du RADAR et est combinée avec la tête de suivi CC-3DT++, qui utilise explicitement un détecteur amélioré de radar à ondes millimétriques dans son association de données. Estimation de la vitesse, permettant finalement la détection et le suivi de cibles 3D.
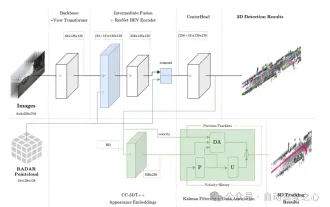
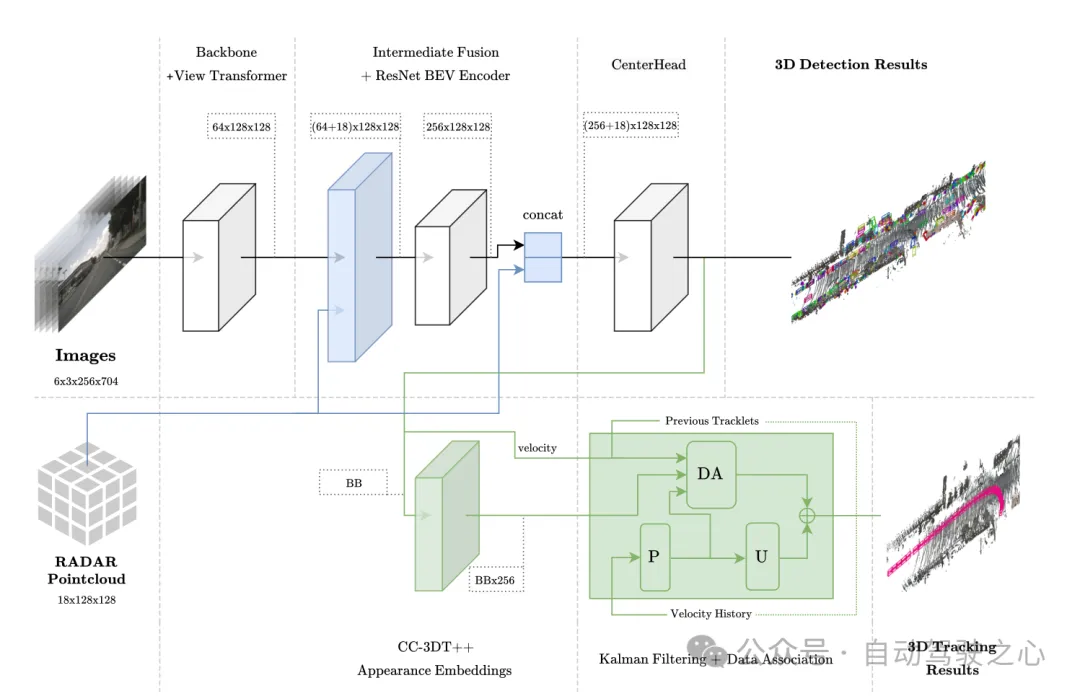 Figure 1 Architecture globale. La détection et le suivi sont surlignés respectivement en bleu clair et vert.
Figure 1 Architecture globale. La détection et le suivi sont surlignés respectivement en bleu clair et vert.
Fusion de capteurs dans l'espace BEV
Ce module adopte une méthode de fusion similaire à PointPillars, y compris l'agrégation et la connexion en son sein. La grille BEV est définie sur [-51,2, 51,2] avec une résolution de 0,8, ce qui donne une grille de fonctionnalités (128 × 128). Projetez les caractéristiques de l'image directement dans l'espace BEV. Le nombre de canaux de chaque unité de grille est de 64, puis les caractéristiques de l'image BEV sont (64 × 128 × 128) de la même manière, les informations à 18 dimensions du radar sont agrégées dans chaque In ; l'unité de grille, cela inclut les coordonnées x, y et z du point, et aucune amélioration n'est apportée aux données radar. L'auteur a confirmé que le nuage de points Radar contient déjà plus d'informations que le nuage de points LiDAR, la fonction Radar BEV est donc (18 × 128 × 128). Enfin, les caractéristiques de l'image BEV (64 × 128 × 128) et les caractéristiques du radar BEV (18 × 128 × 128) sont directement connectées ((64 + 18) × 128 × 128) en tant qu'entrée de la couche de codage des caractéristiques BEV. Dans des expériences d'ablation ultérieures, il a été constaté qu'il est avantageux d'ajouter des connexions résiduelles à la sortie de la couche de codage de caractéristiques BEV avec une dimension de (256 × 128 × 128), ce qui donne une taille d'entrée finale de la tête de détection CenterPoint de ( (256+18 )×128×128).

Figure 2 Visualisation du nuage de points radar agrégé dans l'espace BEV pour l'opération de fusion
Architecture du module de suivi
Le suivi consiste à associer des cibles dans deux cadres différents en fonction de la corrélation de mouvement et de la similarité des caractéristiques visuelles. Au cours du processus de formation, des vecteurs d'intégration de caractéristiques visuelles unidimensionnelles sont obtenus grâce à un apprentissage à contraste positif multivarié quasi-dense, puis la détection et l'intégration de caractéristiques sont utilisées simultanément dans l'étape de suivi de CC-3DT. L'étape d'association de données (module DA sur la figure 1) a été modifiée pour tirer parti de la détection de position et de l'estimation de la vitesse CR3DT améliorées. Les détails sont les suivants :

Les expériences et les résultats
ont été réalisés sur la base de l'ensemble de données nuScenes, et toutes les formations n'ont pas utilisé le CBGS.
Modèle restreint
Parce que l'auteur a réalisé l'intégralité du modèle sur un ordinateur équipé d'une carte graphique 3090, on l'appelle un modèle restreint. La partie détection de cible de ce modèle utilise BEVDet comme référence de détection, l'épine dorsale de codage d'image est ResNet50 et l'entrée d'image est définie sur (3 × 256 × 704) les informations d'image passées ou futures ne sont pas utilisées dans le modèle, et la taille du lot est définie sur 8. Pour atténuer la rareté des données radar, cinq analyses sont utilisées pour améliorer les données. Aucune information temporelle supplémentaire n'est utilisée dans le modèle de fusion.
Pour la détection de cibles, utilisez les scores de mAP, NDS et mAVE pour évaluer le suivi, utilisez AMOTA, AMOTP et IDS pour évaluer.
Résultats de détection d'objets
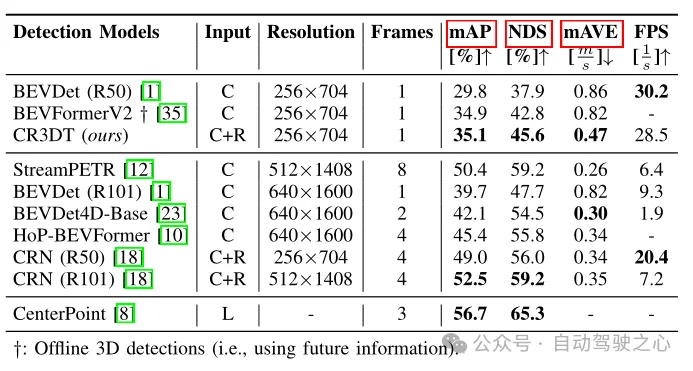
Tableau 1 Résultats de détection sur l'ensemble de validation nuScenes
Le Tableau 1 montre les performances de détection de CR3DT par rapport à l'architecture de base BEVDet (R50) en utilisant uniquement des caméras. Il est évident que l’ajout du Radar améliore considérablement les performances de détection. Sous les contraintes d'une petite résolution et d'un laps de temps réduit, CR3DT atteint avec succès une amélioration de 5,3 % de mAP et de 7,7 % de NDS par rapport au BEVDet avec caméra uniquement. Cependant, en raison des limites de la puissance de calcul, l'article n'a pas abouti à des résultats expérimentaux de haute résolution, de fusion d'informations temporelles, etc. De plus, le temps d'inférence est également indiqué dans la dernière colonne du tableau 1.
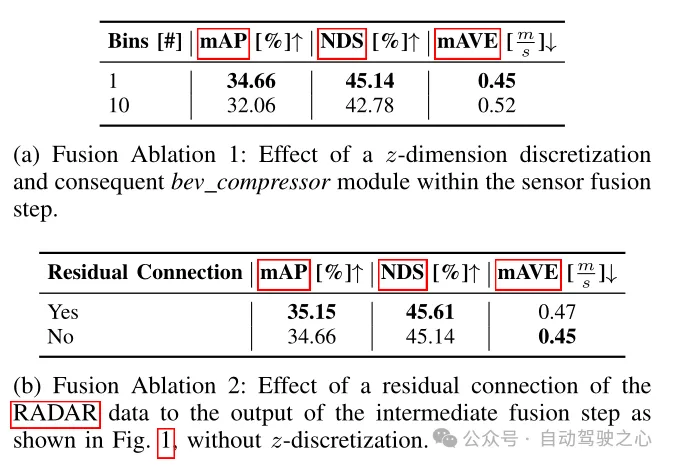
Tableau 2 Expérience d'ablation du cadre de détection
Dans le tableau 2, l'impact de différentes architectures de fusion sur les indicateurs de détection est comparé. Les méthodes de fusion ici sont divisées en deux types : la première est mentionnée dans l'article, qui abandonne la voxélisation dimensionnelle z et la convolution 3D ultérieure, et agrège directement les caractéristiques d'image améliorées et les données RADAR pures en colonnes, obtenant ainsi la taille des caractéristiques connues. est ((64+18)×128×128) ; l'autre consiste à voxer les caractéristiques d'image améliorées et les données RADAR pures dans un cube d'une taille de 0,8×0,8×0,8 m pour obtenir des caractéristiques alternatives. La taille est ((64+ 18) × 10 × 128 × 128), le module compresseur BEV doit donc être utilisé sous forme de convolution 3D. Comme le montre le tableau 2(a), une augmentation du nombre de compresseurs BEV entraînera une diminution des performances, et on peut voir que la première solution est plus performante. Il ressort également du tableau 2 (b) que l'ajout du bloc résiduel de données radar peut également améliorer les performances, ce qui confirme également ce qui a été mentionné dans l'architecture du modèle précédent. L'ajout de connexions résiduelles à la sortie de la couche de codage de fonctionnalités BEV est un avantage. .
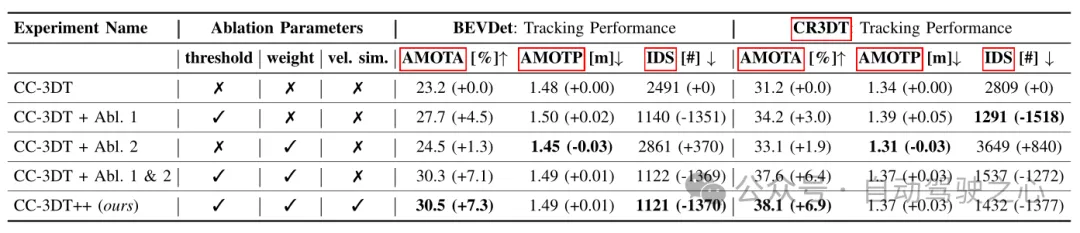 Tableau 3 Résultats de suivi sur l'ensemble de validation nuScenes en fonction de différentes configurations de base BEVDet et CR3DT
Tableau 3 Résultats de suivi sur l'ensemble de validation nuScenes en fonction de différentes configurations de base BEVDet et CR3DT
Le Tableau 3 montre les résultats de suivi du modèle de suivi CC3DT++ amélioré sur l'ensemble de validation nuScenes. Il montre les résultats de suivi du tracker sur. la référence et les performances sur le modèle de détection CR3DT. Le modèle CR3DT améliore les performances de l'AMOTA de 14,9 % par rapport à la ligne de base et la diminue de 0,11 m dans l'AMOTP. De plus, on peut constater que l’IDS est réduit d’environ 43 % par rapport à la ligne de base.
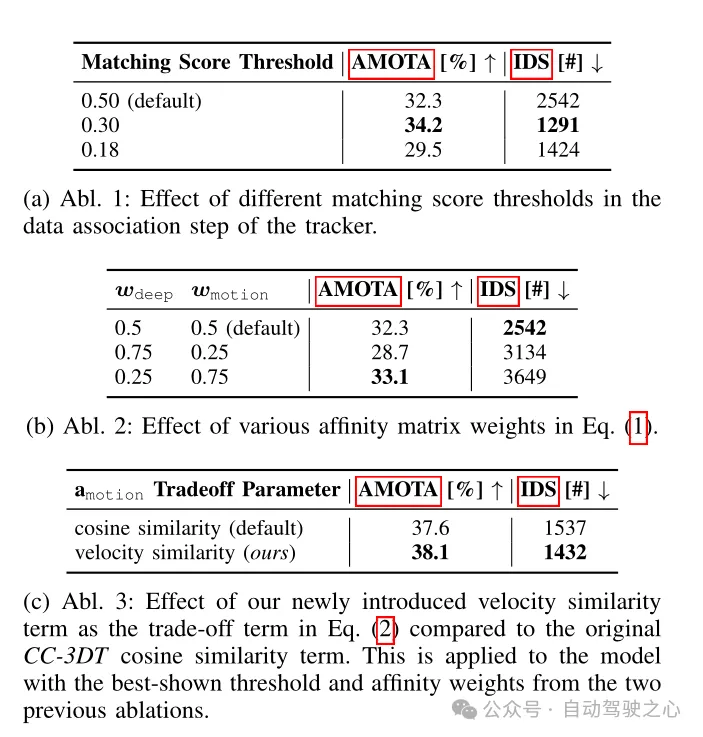
Tableau 4 Expériences d'ablation d'architecture de suivi réalisées sur le squelette de détection CR3DT

Conclusion
Ce travail propose un modèle de fusion caméra-radar efficace - CR3DT, spécifiquement pour la détection d'objets 3D et le suivi multi-objets. En fusionnant les données radar dans l'architecture BEVDet réservée aux caméras et en introduisant l'architecture de suivi CC-3DT++, CR3DT a considérablement amélioré la détection et la précision du suivi des cibles 3D, avec mAP et AMOTA augmentant respectivement de 5,35 % et 14,9 %.
La solution d'intégration d'une caméra et d'un radar à ondes millimétriques présente l'avantage d'être faible par rapport au LiDAR pur ou à la solution d'intégration du LiDAR et d'une caméra, et est proche du développement actuel des véhicules autonomes. De plus, le radar à ondes millimétriques présente l'avantage d'être robuste par mauvais temps et peut faire face à une variété de scénarios d'application. Le gros problème actuel est la rareté des nuages de points radar à ondes millimétriques et l'incapacité de détecter les informations de hauteur. Cependant, avec le développement continu du radar à ondes millimétriques 4D, je pense que l'intégration future des caméras et des solutions de radar à ondes millimétriques atteindra un niveau supérieur et obtiendra des résultats encore meilleurs !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comprenez facilement les images 4K HD ! Ce grand modèle multimodal analyse automatiquement le contenu des affiches Web, ce qui le rend très pratique pour les travailleurs.
Apr 23, 2024 am 08:04 AM
Comprenez facilement les images 4K HD ! Ce grand modèle multimodal analyse automatiquement le contenu des affiches Web, ce qui le rend très pratique pour les travailleurs.
Apr 23, 2024 am 08:04 AM
Un modèle volumineux capable d'analyser automatiquement le contenu des PDF, des pages Web, des affiches et des graphiques Excel n'est pas très pratique pour les travailleurs. Le modèle InternLM-XComposer2-4KHD (en abrégé IXC2-4KHD) proposé par Shanghai AILab, l'Université chinoise de Hong Kong et d'autres instituts de recherche en fait une réalité. Par rapport à d'autres grands modèles multimodaux qui ont une limite de résolution ne dépassant pas 1 500 x 1 500, ce travail augmente l'image d'entrée maximale des grands modèles multimodaux à une résolution supérieure à 4K (3 840 x 1 600) et prend en charge n'importe quel rapport d'aspect et 336 pixels en 4K. Changements de résolution dynamiques. Trois jours après sa sortie, le modèle était en tête de la liste de popularité des modèles de réponses visuelles aux questions HuggingFace. Facile à manier
 CVPR 2024 | Modèle de diffusion LiDAR pour la génération de scènes photoréalistes
Apr 24, 2024 pm 04:28 PM
CVPR 2024 | Modèle de diffusion LiDAR pour la génération de scènes photoréalistes
Apr 24, 2024 pm 04:28 PM
Titre original : TowardsRealisticSceneGenerationwithLiDARDiffusionModels Lien vers l'article : https://hancyran.github.io/assets/paper/lidar_diffusion.pdf Lien vers le code : https://lidar-diffusion.github.io Affiliation de l'auteur : CMU Toyota Research Institute University of Southern California Article idées : Les modèles de diffusion (DM) excellent dans la synthèse d'images photoréalistes, mais les adapter à la génération de scènes lidar présente des défis importants. Ceci est principalement dû au fait que les DM opérant dans l'espace de points ont des difficultés
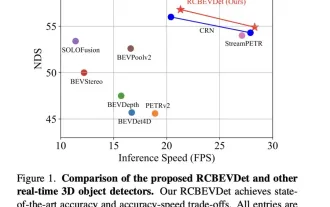 Les performances de RV Fusion sont incroyables ! RCBEVDet : Le radar a aussi du ressort, le dernier SOTA !
Apr 02, 2024 am 11:49 AM
Les performances de RV Fusion sont incroyables ! RCBEVDet : Le radar a aussi du ressort, le dernier SOTA !
Apr 02, 2024 am 11:49 AM
Écrit ci-dessus et la compréhension personnelle de l’auteur est que le principal problème sur lequel se concentre ce document de discussion est l’application de la technologie de détection de cibles 3D dans le processus de conduite autonome. Bien que le développement de la technologie des caméras de vision environnementale fournisse des informations sémantiques haute résolution pour la détection d'objets 3D, cette méthode est limitée par des problèmes tels que l'incapacité de capturer avec précision les informations de profondeur et les mauvaises performances par mauvais temps ou dans des conditions de faible luminosité. En réponse à ce problème, la discussion a proposé une nouvelle méthode de détection de cible 3D multimode, RCBEVDet, qui combine des caméras à vision panoramique et des capteurs radar économiques à ondes millimétriques. Cette méthode fournit des informations sémantiques plus riches et une solution à des problèmes tels que de mauvaises performances par mauvais temps ou dans des conditions de faible luminosité en utilisant de manière exhaustive les informations provenant de plusieurs capteurs. Pour résoudre ce problème, la discussion a proposé une méthode combinant des caméras à vision panoramique
 Nouvelles idées pour la simulation LiDAR | LidarDM : aide à générer un monde 4D, un tueur de simulation ~
Apr 12, 2024 am 11:46 AM
Nouvelles idées pour la simulation LiDAR | LidarDM : aide à générer un monde 4D, un tueur de simulation ~
Apr 12, 2024 am 11:46 AM
Titre original : LidarDM : GenerativeLiDARSimulationinaGeneratedWorld Lien vers l'article : https://arxiv.org/pdf/2404.02903.pdf Lien vers le code : https://github.com/vzyrianov/lidardm Affiliation de l'auteur : Université de l'Illinois, Massachusetts Institute of Technology Idée d'article : Introduction à cet article LidarDM, un nouveau modèle de génération lidar capable de produire des vidéos lidar réalistes, sensibles à la mise en page, physiquement crédibles et temporellement cohérentes. LidarDM possède deux capacités sans précédent en matière de modélisation générative lidar : (1)
 Au-delà de BEVFormer ! CR3DT : RV Fusion facilite la détection et le suivi 3D du nouveau SOTA (ETH)
Apr 24, 2024 pm 06:07 PM
Au-delà de BEVFormer ! CR3DT : RV Fusion facilite la détection et le suivi 3D du nouveau SOTA (ETH)
Apr 24, 2024 pm 06:07 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Cet article présente une méthode de fusion caméra-radar à ondes millimétriques (CR3DT) pour la détection de cibles 3D et le suivi multi-cibles. La méthode basée sur le lidar a établi une norme élevée dans ce domaine, mais sa puissance de calcul élevée et son coût élevé ont limité le développement de cette solution dans le domaine de la conduite autonome ; les solutions de détection et de suivi de cibles 3D basées sur une caméra sont dues à leur haute qualité. coût Il est relativement faible et a attiré l'attention de nombreux chercheurs, mais en raison de ses mauvais résultats. La fusion des caméras et du radar à ondes millimétriques devient donc une solution prometteuse. Dans le cadre de la caméra existante BEVDet, l'auteur fusionne les informations spatiales et de vitesse du radar à ondes millimétriques et les combine avec la tête de suivi CC-3DT++ pour améliorer considérablement la précision de la détection et du suivi des cibles 3D.
 « Analyse approfondie » : exploration de l'algorithme de segmentation des nuages de points LiDAR dans la conduite autonome
Apr 23, 2023 pm 04:46 PM
« Analyse approfondie » : exploration de l'algorithme de segmentation des nuages de points LiDAR dans la conduite autonome
Apr 23, 2023 pm 04:46 PM
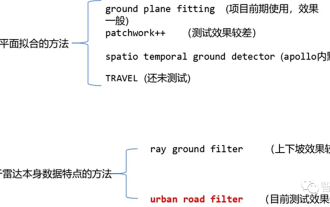
Actuellement, les algorithmes courants de segmentation de nuages de points laser incluent des méthodes basées sur l'ajustement plan et des méthodes basées sur les caractéristiques des données de nuages de points laser. Les détails sont les suivants : Algorithme de segmentation du sol en nuage de points 01 Méthode basée sur l'ajustement de plan - Idée de l'algorithme GroundPlaneFitting : Une méthode de traitement simple consiste à diviser l'espace en plusieurs sous-plans le long de la direction x (la direction de l'avant de la voiture) , puis utilisez l'algorithme d'ajustement du plan de sol (GPF) pour obtenir une méthode de segmentation du sol capable de gérer des pentes abruptes. Cette méthode consiste à adapter un plan global dans un nuage de points à image unique. Elle fonctionne mieux lorsque le nombre de nuages de points est important. Lorsque le nuage de points est clairsemé, il est facile de provoquer des détections manquées et des détections fausses, telles que 16 lignes. lidar. Pseudocode d'algorithme : Le processus d'algorithme de pseudocode est le résultat final de la segmentation pour un nuage de points P donné.
 Solution technologique de détection LiDAR dans des conditions météorologiques extrêmes
May 10, 2023 pm 04:07 PM
Solution technologique de détection LiDAR dans des conditions météorologiques extrêmes
May 10, 2023 pm 04:07 PM
01Résumé Les voitures autonomes s'appuient sur divers capteurs pour collecter des informations sur l'environnement. Le comportement du véhicule est planifié en fonction de la conscience environnementale, sa fiabilité est donc cruciale pour des raisons de sécurité. Les capteurs lidar actifs sont capables de créer des représentations 3D précises de scènes, ce qui en fait un complément précieux à la conscience environnementale des véhicules autonomes. Les performances du LiDAR changent dans des conditions météorologiques défavorables telles que le brouillard, la neige ou la pluie en raison de la diffusion de la lumière et de l'occlusion. Cette limitation a récemment suscité des recherches considérables sur les méthodes permettant d'atténuer la dégradation des performances perceptuelles. Cet article rassemble, analyse et discute différents aspects de la détection environnementale basée sur LiDAR pour faire face aux conditions météorologiques défavorables. et aborde des sujets tels que la disponibilité de données appropriées, le traitement et le débruitage des nuages de points bruts, les algorithmes de perception robustes et la fusion de capteurs pour atténuer
 Introduction à la technologie de traitement du signal radar implémentée en Java
Jun 18, 2023 am 10:15 AM
Introduction à la technologie de traitement du signal radar implémentée en Java
Jun 18, 2023 am 10:15 AM
Introduction : Avec le développement continu de la science et de la technologie modernes, la technologie de traitement des signaux radar est de plus en plus largement utilisée. En tant que l'un des langages de programmation les plus populaires à l'heure actuelle, Java est largement utilisé dans la mise en œuvre d'algorithmes de traitement des signaux radar. Cet article présentera la technologie de traitement des signaux radar implémentée en Java. 1. Introduction à la technologie de traitement des signaux radar La technologie de traitement des signaux radar peut être considérée comme le cœur et l'âme du développement des systèmes radar et constitue la technologie clé pour réaliser l'automatisation et la numérisation des systèmes radar. La technologie de traitement du signal radar comprend le traitement des formes d'onde, le filtrage, la compression des impulsions et la mise en forme adaptative du faisceau.
