
 Périphériques technologiques
IA
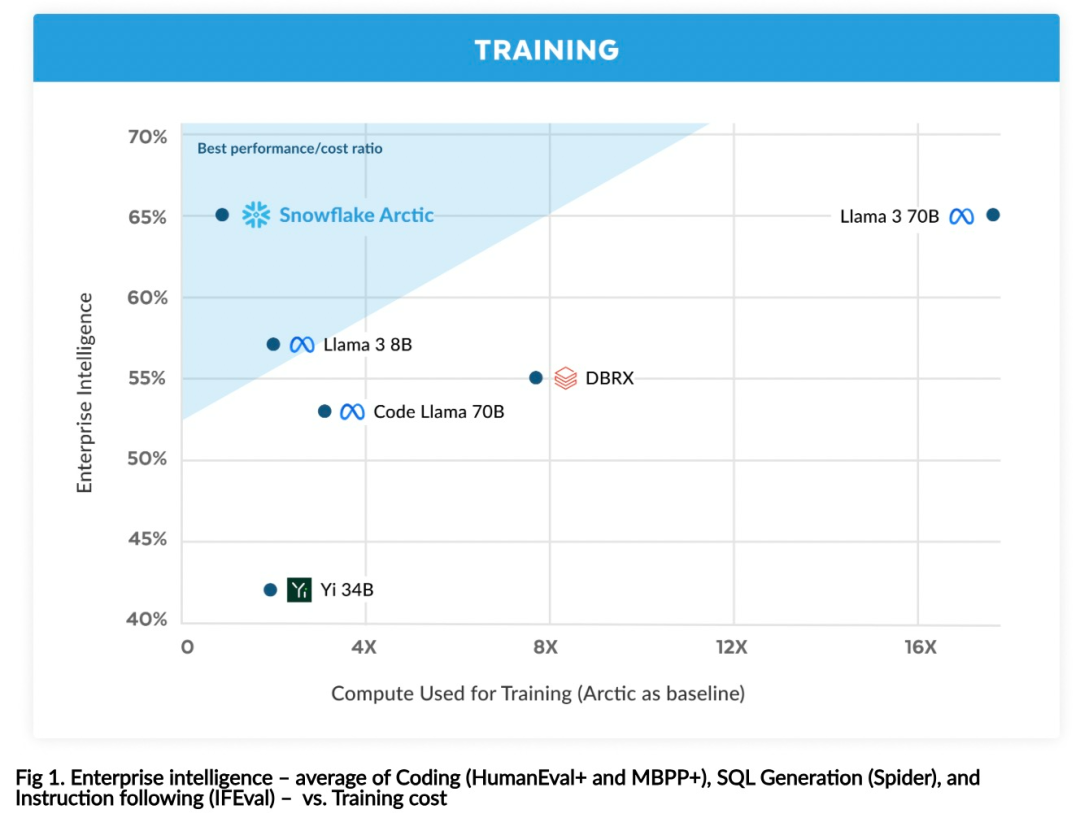
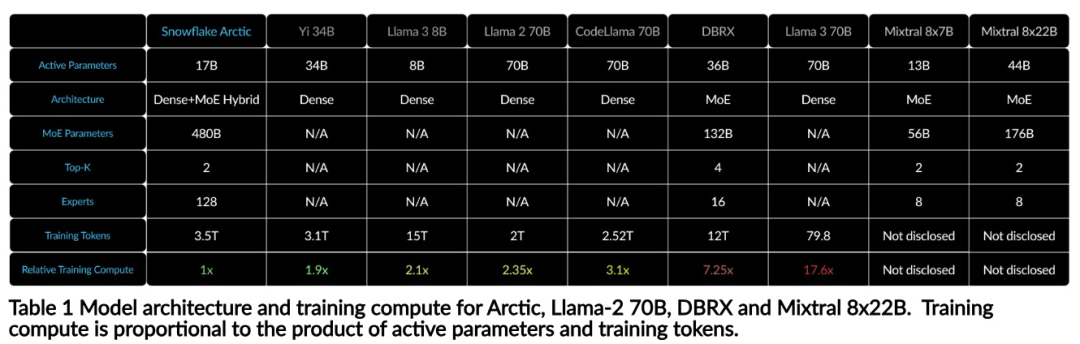
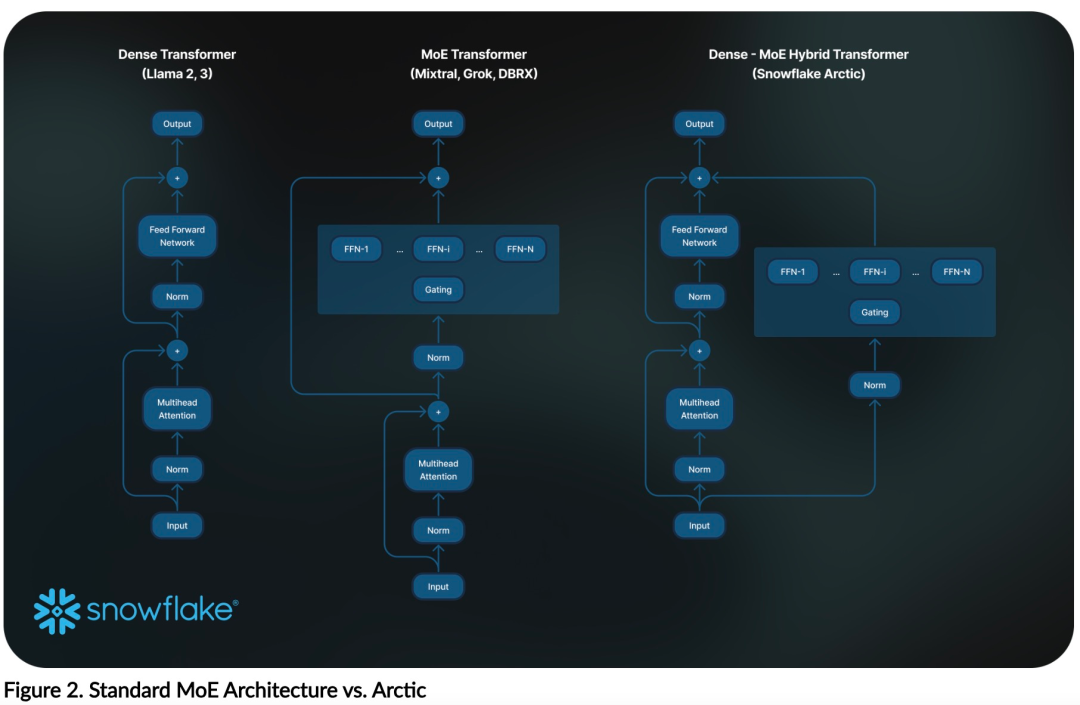
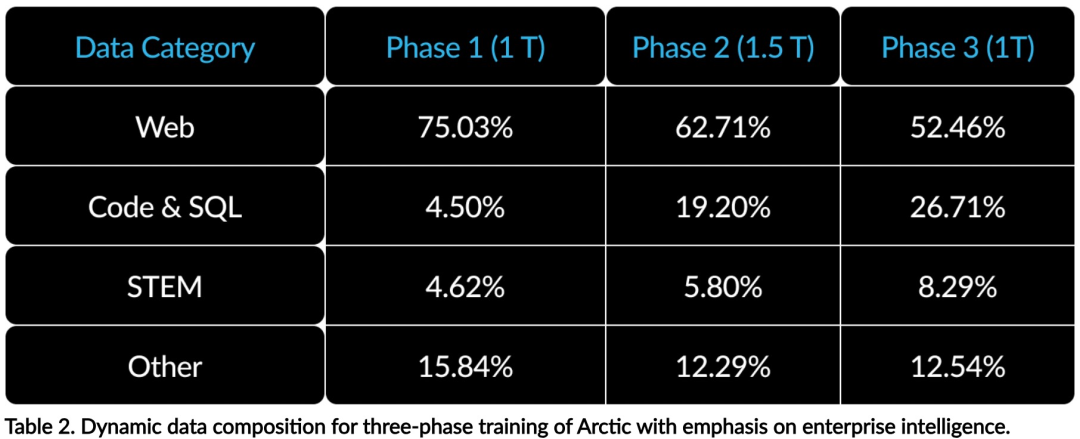
Avec seulement 1/17 du coût de formation de Llama3, modèle MoE open source 128x3B de Snowflake
Périphériques technologiques
IA
Avec seulement 1/17 du coût de formation de Llama3, modèle MoE open source 128x3B de Snowflake
Avec seulement 1/17 du coût de formation de Llama3, modèle MoE open source 128x3B de Snowflake

Snowflake rejoint la mêlée LLM.
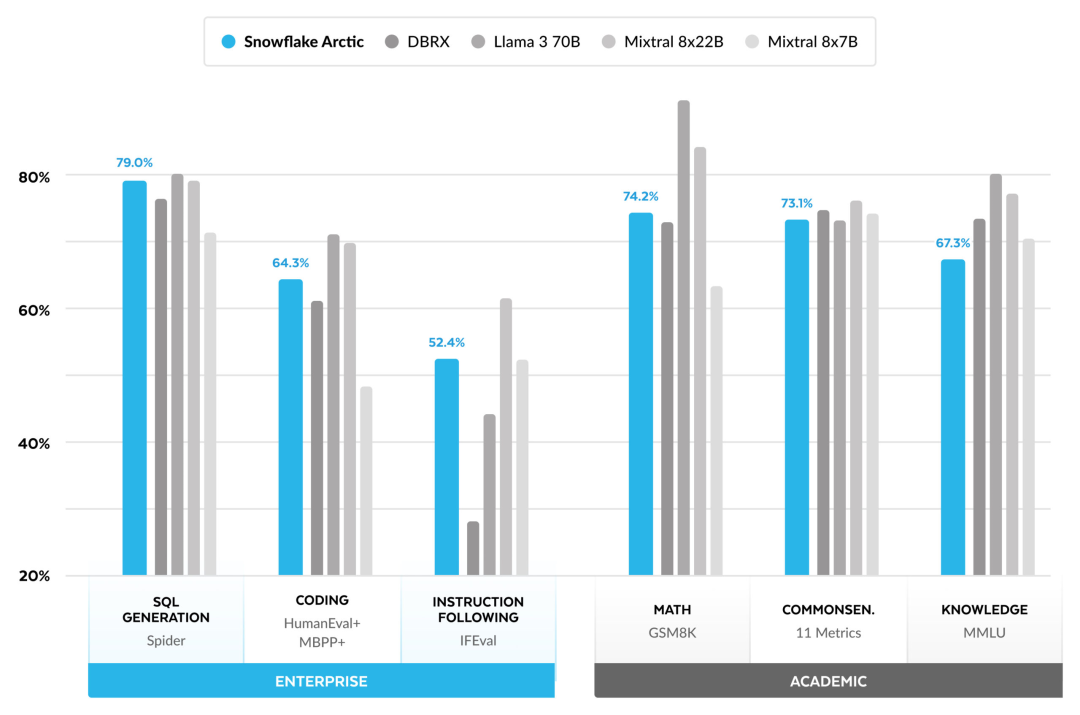
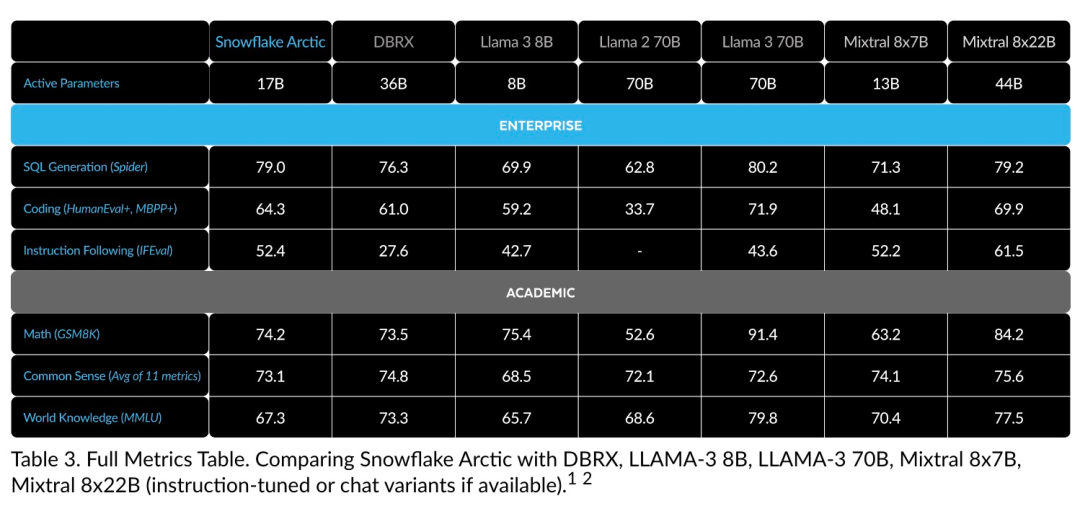
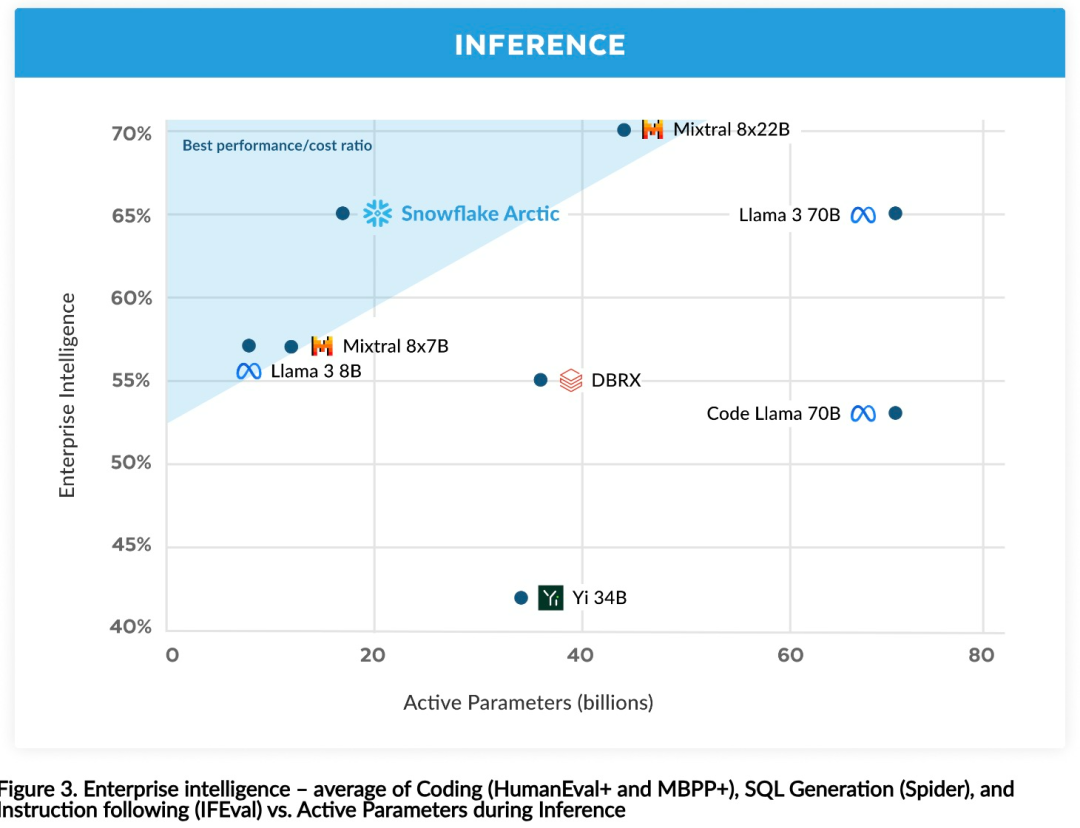
Intelligence efficace : Arctic fonctionne bien dans les tâches d'entreprise, telles que la génération SQL, la programmation et le suivi d'instructions. , même comparable aux modèles open source entraînés avec des coûts de calcul plus élevés. Arctic établit une nouvelle référence en matière de formation rentable, permettant aux clients de Snowflake de créer des modèles personnalisés de haute qualité à faible coût pour les besoins de leur entreprise. Open source : Arctic adopte la licence Apache 2.0, offrant un accès ouvert aux poids et au code, et Snowflake ouvrira également toutes les solutions de données et les résultats de recherche en open source.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment définir le répertoire CGI dans Apache
Apr 13, 2025 pm 01:18 PM
Comment définir le répertoire CGI dans Apache
Apr 13, 2025 pm 01:18 PM
Pour configurer un répertoire CGI dans Apache, vous devez effectuer les étapes suivantes: Créez un répertoire CGI tel que "CGI-Bin" et accorder des autorisations d'écriture Apache. Ajoutez le bloc directif "Scriptalias" dans le fichier de configuration Apache pour mapper le répertoire CGI à l'URL "/ cgi-bin". Redémarrez Apache.
 Comment démarrer Apache
Apr 13, 2025 pm 01:06 PM
Comment démarrer Apache
Apr 13, 2025 pm 01:06 PM
Les étapes pour démarrer Apache sont les suivantes: Installez Apache (Commande: Sudo apt-get install Apache2 ou téléchargez-le à partir du site officiel) Start Apache (Linux: Sudo SystemCTL Démarrer Apache2; Windows: Cliquez avec le bouton droit sur le service "APACHE2.4" et SELECT ") Vérifiez si elle a été lancée (Linux: SUDO SYSTEMCTL STATURE APACHE2; (Facultatif, Linux: Sudo SystemCTL
 Comment vérifier la configuration de Debian OpenSSL
Apr 12, 2025 pm 11:57 PM
Comment vérifier la configuration de Debian OpenSSL
Apr 12, 2025 pm 11:57 PM
Cet article présente plusieurs méthodes pour vérifier la configuration OpenSSL du système Debian pour vous aider à saisir rapidement l'état de sécurité du système. 1. Confirmez d'abord la version OpenSSL, vérifiez si OpenSSL a été installé et des informations de version. Entrez la commande suivante dans le terminal: si OpenSSLVersion n'est pas installée, le système invitera une erreur. 2. Affichez le fichier de configuration. Le fichier de configuration principal d'OpenSSL est généralement situé dans /etc/ssl/opensessl.cnf. Vous pouvez utiliser un éditeur de texte (tel que Nano) pour afficher: Sutonano / etc / ssl / openssl.cnf Ce fichier contient des informations de configuration importantes telles que la clé, le chemin de certificat et l'algorithme de chiffrement. 3. Utiliser OPE
 Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Comment utiliser les journaux Debian Apache pour améliorer les performances du site Web
Apr 12, 2025 pm 11:36 PM
Cet article expliquera comment améliorer les performances du site Web en analysant les journaux Apache dans le système Debian. 1. Bases de l'analyse du journal APACH LOG enregistre les informations détaillées de toutes les demandes HTTP, y compris l'adresse IP, l'horodatage, l'URL de la demande, la méthode HTTP et le code de réponse. Dans Debian Systems, ces journaux sont généralement situés dans les répertoires /var/log/apache2/access.log et /var/log/apache2/error.log. Comprendre la structure du journal est la première étape d'une analyse efficace. 2.
 Comment supprimer plus que les noms de serveurs d'Apache
Apr 13, 2025 pm 01:09 PM
Comment supprimer plus que les noms de serveurs d'Apache
Apr 13, 2025 pm 01:09 PM
Pour supprimer une directive de nom de serveur supplémentaire d'Apache, vous pouvez prendre les étapes suivantes: Identifier et supprimer la directive supplémentaire de serveur. Redémarrez Apache pour que les modifications prennent effet. Vérifiez le fichier de configuration pour vérifier les modifications. Testez le serveur pour vous assurer que le problème est résolu.
 Comment afficher votre version Apache
Apr 13, 2025 pm 01:15 PM
Comment afficher votre version Apache
Apr 13, 2025 pm 01:15 PM
Il existe 3 façons d'afficher la version sur le serveur Apache: via la ligne de commande (apachectl -v ou apache2ctl -v), cochez la page d'état du serveur (http: // & lt; serveur ip ou nom de domaine & gt; / server-status), ou afficher le fichier de configuration Apache (serverVeelion: apache / & lt; version & gt;).
 Comment optimiser la configuration CentOS HDFS
Apr 14, 2025 pm 07:15 PM
Comment optimiser la configuration CentOS HDFS
Apr 14, 2025 pm 07:15 PM
Améliorer les performances HDFS sur CentOS: un guide d'optimisation complet pour optimiser les HDF (système de fichiers distribué Hadoop) sur CentOS nécessite une considération complète du matériel, de la configuration du système et des paramètres réseau. Cet article fournit une série de stratégies d'optimisation pour vous aider à améliorer les performances du HDFS. 1. Expansion de la mise à niveau matérielle et des ressources de sélection: augmentez autant que possible le CPU, la mémoire et la capacité de stockage du serveur. Matériel haute performance: adopte les cartes réseau et les commutateurs de réseau haute performance pour améliorer le débit du réseau. 2. Configuration du système Réglage des paramètres du noyau à réglage fin: Modifier /etc/sysctl.conf Fichier pour optimiser les paramètres du noyau tels que le numéro de connexion TCP, le numéro de manche de fichier et la gestion de la mémoire. Par exemple, ajustez l'état de la connexion TCP et la taille du tampon
 Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Comment se connecter à la base de données d'Apache
Apr 13, 2025 pm 01:03 PM
Apache se connecte à une base de données nécessite les étapes suivantes: Installez le pilote de base de données. Configurez le fichier web.xml pour créer un pool de connexion. Créez une source de données JDBC et spécifiez les paramètres de connexion. Utilisez l'API JDBC pour accéder à la base de données à partir du code Java, y compris l'obtention de connexions, la création d'instructions, les paramètres de liaison, l'exécution de requêtes ou de mises à jour et de traitement des résultats.
