
 Périphériques technologiques
IA
Accélérez le modèle de diffusion, générez des images de niveau SOTA en une étape la plus rapide, Byte Hyper-SD est open source
Périphériques technologiques
IA
Accélérez le modèle de diffusion, générez des images de niveau SOTA en une étape la plus rapide, Byte Hyper-SD est open source
Accélérez le modèle de diffusion, générez des images de niveau SOTA en une étape la plus rapide, Byte Hyper-SD est open source

Récemment, Diffusion Model a fait des progrès significatifs dans le domaine de la génération d'images, offrant des opportunités de développement sans précédent aux tâches de génération d'images et de génération de vidéos. Malgré les résultats impressionnants, les propriétés de débruitage itératif en plusieurs étapes inhérentes au processus d'inférence des modèles de diffusion entraînent des coûts de calcul élevés. Récemment, une série d’algorithmes de distillation de modèles de diffusion ont vu le jour pour accélérer le processus d’inférence des modèles de diffusion. Ces méthodes peuvent être grossièrement divisées en deux catégories : i) distillation préservant la trajectoire ; ii) distillation par reconstruction de trajectoire ; Toutefois, ces deux types de méthodes seront limitées par le plafond d’effet limité ou par les changements dans le domaine de la production.
Afin de résoudre ces problèmes, l'équipe technique de ByteDance a proposé un modèle de cohérence de segmentation de trajectoire appelé Hyper-SD. L'open source d'Hyper-SD a également été reconnu par Clem Delangue, PDG de Huggingface.
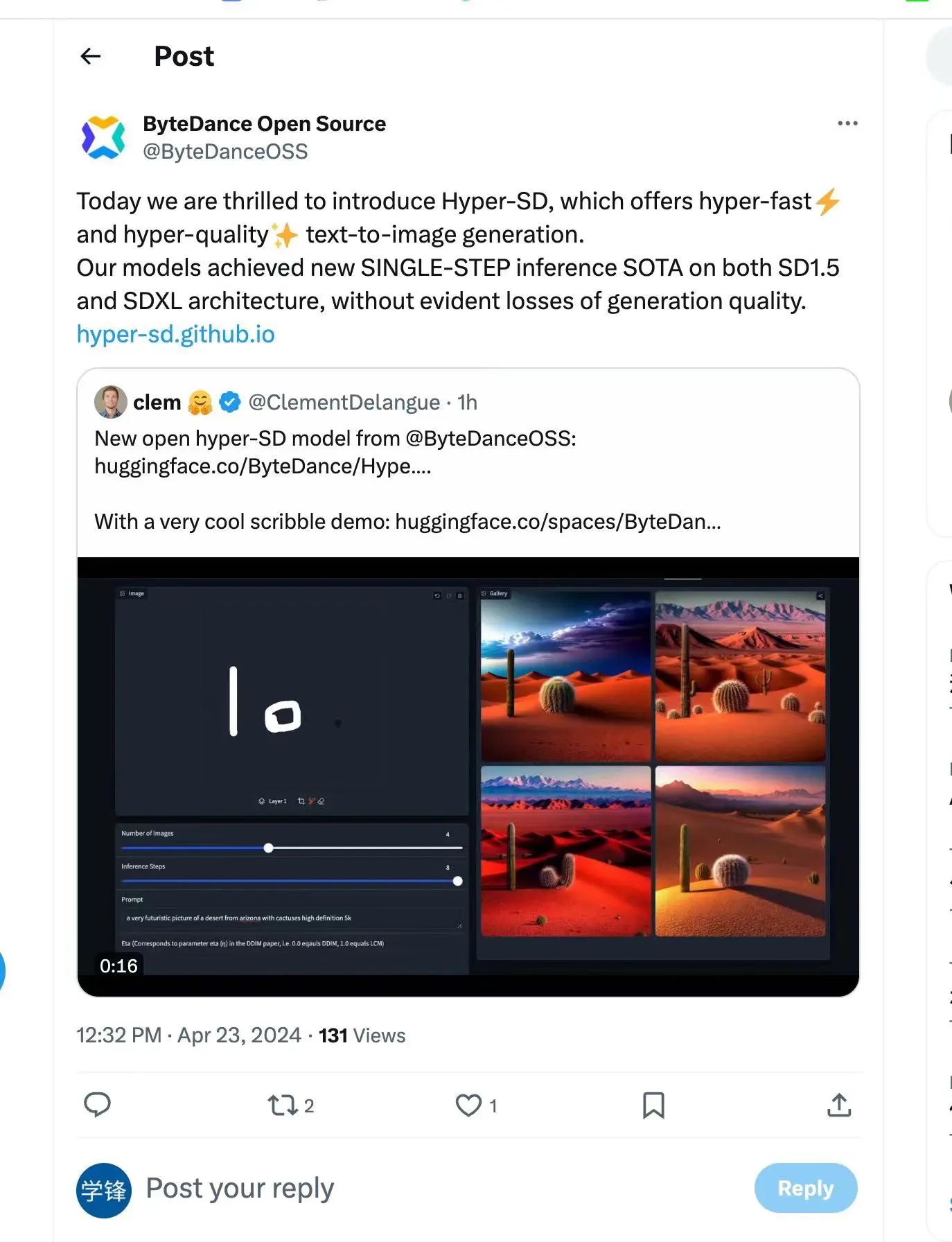
Ce modèle est un nouveau cadre de distillation de modèle de diffusion qui combine les avantages de la distillation préservant la trajectoire et de la distillation par reconstruction de trajectoire pour compresser le nombre d'étapes de débruitage tout en maintenant des performances quasiment sans perte. Comparée aux algorithmes d’accélération de modèles de diffusion existants, cette méthode permet d’obtenir d’excellents résultats d’accélération. Après des expériences approfondies et des avis d'utilisateurs, Hyper-SD+ peut atteindre des performances de génération d'images de niveau SOTA en 1 à 8 étapes sur les architectures SDXL et SD1.5.

Page d'accueil du projet : https://hyper-sd.github.io/
Lien papier : https://arxiv.org/abs/2404.13686
Lien Huggingface : https:// // /huggingface.co/ByteDance/Hyper-SD
Lien de démonstration de génération en une seule étape : https://huggingface.co/spaces/ByteDance/Hyper-SDXL-1Step-T2I
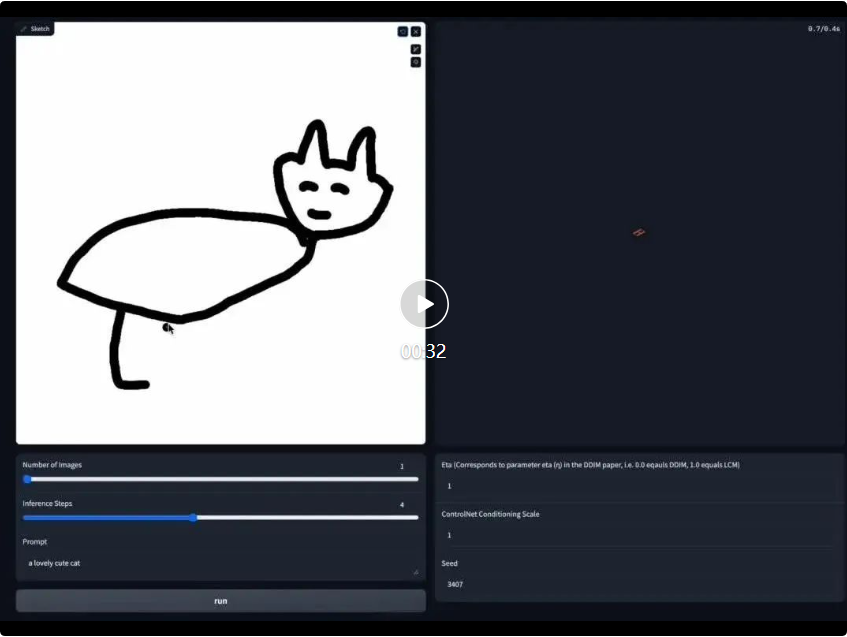
Dessin en temps réel Lien de démonstration du tableau : https://huggingface.co/spaces/ByteDance/Hyper-SD15-Scribble

Les méthodes de distillation existantes pour l'accélération du modèle de diffusion peuvent être grossièrement divisées en deux catégories : distillation préservant la trajectoire et distillation de reconstruction de trajectoire. La technique de distillation préservant la trajectoire vise à maintenir la trajectoire originale de l'équation différentielle ordinaire (ODE) correspondant à la diffusion. Le principe est de réduire les étapes d'inférence en forçant le modèle distillé et le modèle d'origine à produire des résultats similaires. Cependant, il convient de noter que même si une accélération peut être obtenue, de telles méthodes peuvent conduire à une diminution de la qualité de la génération en raison de la capacité limitée du modèle et des erreurs inévitables lors de la formation et de l'ajustement. En revanche, les méthodes de reconstruction de trajectoire utilisent directement les points finaux de la trajectoire ou des images réelles comme source principale de supervision, ignorant les étapes intermédiaires de la trajectoire. Elles peuvent réduire le nombre d'étapes d'inférence en reconstruisant des trajectoires plus efficaces et en l'exécutant dans un délai limité. temps. Explorez le potentiel de votre modèle par étapes, en le libérant des contraintes de la trajectoire originale. Cependant, cela aboutit souvent à ce que le domaine de sortie du modèle accéléré soit incohérent avec le modèle d'origine, ce qui entraîne des résultats sous-optimaux.
Cet article propose un modèle de cohérence de segmentation de trajectoire (Hyper-SD en abrégé) qui combine les avantages des stratégies de préservation et de reconstruction de trajectoire. Plus précisément, l'algorithme introduit d'abord une distillation de cohérence de segmentation de trajectoire pour renforcer la cohérence au sein de chaque segment et réduit progressivement le nombre de segments pour obtenir une cohérence à temps plein. Cette stratégie résout le problème des performances sous-optimales des modèles cohérents en raison de capacités d’ajustement de modèle insuffisantes et de l’accumulation d’erreurs d’inférence. Par la suite, l'algorithme utilise l'apprentissage par rétroaction humaine (RLHF) pour améliorer l'effet de génération de modèle afin de compenser la perte de l'effet de génération de modèle pendant le processus d'accélération et de le rendre mieux adapté au raisonnement à faible échelon. Enfin, l'algorithme utilise la distillation fractionnée pour améliorer les performances de génération en une étape et obtient un modèle de diffusion idéalisé et cohérent à temps plein grâce à un LORA unifié, obtenant ainsi d'excellents résultats en termes d'effets de génération.
Méthode
1. Distillation de cohérence de segmentation de trajectoire
.Consistent Distillation (CD) [24] et Consistent Trajectory Model (CTM) [4] visent tous deux à convertir le modèle de diffusion en un modèle cohérent pour toute la plage de pas de temps [0, T] grâce à une distillation en un seul coup. Cependant, ces modèles de distillation ne parviennent souvent pas à atteindre l’optimalité en raison des limitations des capacités d’ajustement des modèles. Inspirés par l'objectif de cohérence douce introduit dans CTM, nous affinons le processus de formation en divisant toute la plage de pas de temps [0, T] en k segments et en effectuant une distillation de modèle cohérente par morceaux, étape par étape.
Dans la première étape, nous définissons k=8 et utilisons le modèle de diffusion original pour initialiser 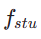 et
et 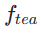 . Le pas de temps de départ
. Le pas de temps de départ 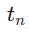 est uniformément échantillonné de manière aléatoire à partir de
est uniformément échantillonné de manière aléatoire à partir de  . Ensuite, nous échantillonnons le pas de temps de fin
. Ensuite, nous échantillonnons le pas de temps de fin 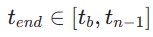 , où
, où 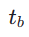 est calculé comme suit :
est calculé comme suit :
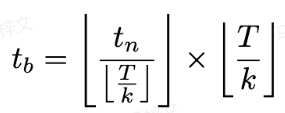
La perte d'entraînement est calculée comme suit :
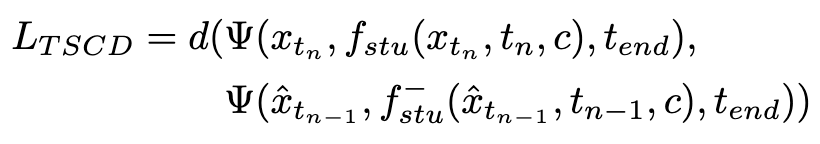
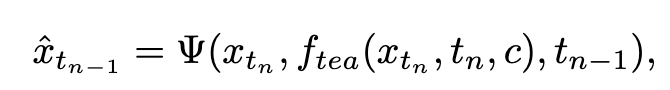
où 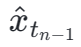 est calculée par l'équation 3 et
est calculée par l'équation 3 et 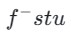 représente l'exponentielle moyenne mobile du modèle étudiant (EMA).
représente l'exponentielle moyenne mobile du modèle étudiant (EMA).
Ensuite, nous rétablissons les poids du modèle de l'étape précédente et continuons l'entraînement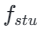 , en réduisant progressivement k à [4,2,1]. Il est à noter que k=1 correspond au schéma de formation standard CTM. Pour la métrique de distance d, nous employons un mélange de perte contradictoire et de perte d’erreur quadratique moyenne (MSE). Dans les expériences, nous avons observé que la perte MSE est plus efficace lorsque les valeurs prédites et cibles sont proches (par exemple, pour k = 8, 4), tandis que la perte contradictoire augmente à mesure que la différence entre les valeurs prédites et cibles augmente. . devient plus précis (par exemple, pour k=2, 1). Par conséquent, nous augmentons dynamiquement le poids de la perte adverse et diminuons le poids de la perte MSE tout au long de la phase d’entraînement. De plus, nous intégrons également un mécanisme de perturbation du bruit pour améliorer la stabilité de la formation. Prenons comme exemple le processus de distillation consensuelle du segment de trajectoire (TSCD) en deux étapes. Comme le montre la figure ci-dessous, notre première étape effectue une distillation de cohérence indépendante dans les périodes
, en réduisant progressivement k à [4,2,1]. Il est à noter que k=1 correspond au schéma de formation standard CTM. Pour la métrique de distance d, nous employons un mélange de perte contradictoire et de perte d’erreur quadratique moyenne (MSE). Dans les expériences, nous avons observé que la perte MSE est plus efficace lorsque les valeurs prédites et cibles sont proches (par exemple, pour k = 8, 4), tandis que la perte contradictoire augmente à mesure que la différence entre les valeurs prédites et cibles augmente. . devient plus précis (par exemple, pour k=2, 1). Par conséquent, nous augmentons dynamiquement le poids de la perte adverse et diminuons le poids de la perte MSE tout au long de la phase d’entraînement. De plus, nous intégrons également un mécanisme de perturbation du bruit pour améliorer la stabilité de la formation. Prenons comme exemple le processus de distillation consensuelle du segment de trajectoire (TSCD) en deux étapes. Comme le montre la figure ci-dessous, notre première étape effectue une distillation de cohérence indépendante dans les périodes 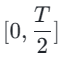 et
et 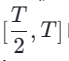 , puis effectue une distillation de trajectoire de cohérence globale basée sur les deux périodes précédentes de résultats de distillation de cohérence.
, puis effectue une distillation de trajectoire de cohérence globale basée sur les deux périodes précédentes de résultats de distillation de cohérence.
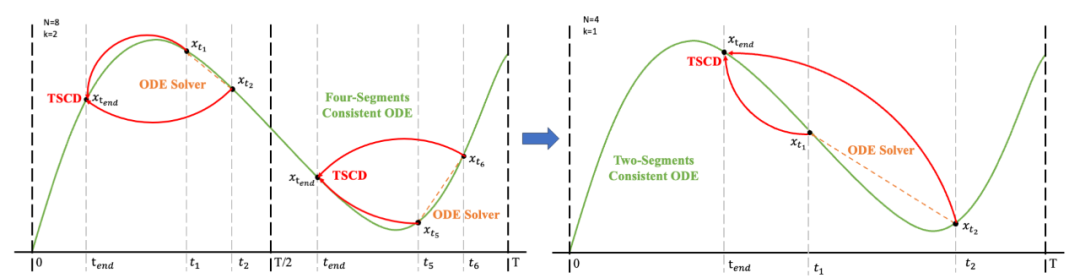
Le processus complet de l'algorithme est le suivant :

2. Apprentissage par feedback humain
En plus de la distillation, nous combinons davantage l'apprentissage par feedback pour améliorer les performances du modèle de diffusion accélérée. Plus précisément, nous améliorons la qualité de génération de modèles accélérés en tirant parti des retours sur les préférences esthétiques humaines et des modèles de perception visuelle existants. Pour les commentaires esthétiques, nous utilisons le prédicteur esthétique LAION et le modèle de récompense de préférence esthétique fourni dans ImageReward pour guider le modèle afin de générer des images plus esthétiques, comme indiqué ci-dessous :
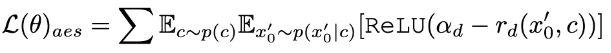
où 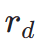 est le modèle de récompense esthétique, y compris le prédicteur esthétique de l'ensemble de données LAION et du modèle ImageReward, c est l'invite de texte,
est le modèle de récompense esthétique, y compris le prédicteur esthétique de l'ensemble de données LAION et du modèle ImageReward, c est l'invite de texte, 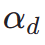 est utilisé avec la fonction ReLU comme perte de charnière. En plus des retours sur les préférences esthétiques, nous notons que les modèles de perception visuelle existants intégrant de riches connaissances préalables sur les images peuvent également constituer de bons fournisseurs de retours. Empiriquement, nous constatons que les modèles de segmentation d'instances peuvent guider le modèle pour générer des objets bien structurés. Plus précisément, nous diffusons d'abord le bruit sur l'image
est utilisé avec la fonction ReLU comme perte de charnière. En plus des retours sur les préférences esthétiques, nous notons que les modèles de perception visuelle existants intégrant de riches connaissances préalables sur les images peuvent également constituer de bons fournisseurs de retours. Empiriquement, nous constatons que les modèles de segmentation d'instances peuvent guider le modèle pour générer des objets bien structurés. Plus précisément, nous diffusons d'abord le bruit sur l'image 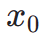 à
à 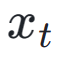 dans l'espace latent, après quoi, comme ImageReward, nous effectuons un débruitage itératif jusqu'à un pas de temps spécifique
dans l'espace latent, après quoi, comme ImageReward, nous effectuons un débruitage itératif jusqu'à un pas de temps spécifique 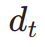 et prédisons directement
et prédisons directement 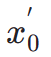 . Par la suite, nous exploitons le modèle de segmentation d'instance perceptuelle pour évaluer les performances de génération de structure en examinant la différence entre les annotations de segmentation d'instance pour des images réelles et les prédictions de segmentation d'instance pour des images débruitées, comme suit :
. Par la suite, nous exploitons le modèle de segmentation d'instance perceptuelle pour évaluer les performances de génération de structure en examinant la différence entre les annotations de segmentation d'instance pour des images réelles et les prédictions de segmentation d'instance pour des images débruitées, comme suit :
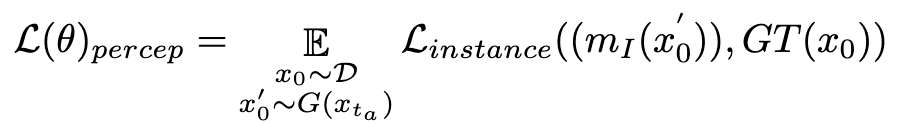
où 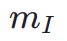 est le modèle de segmentation d'instance (par exemple SOLO). Les modèles de segmentation d'instance peuvent capturer avec plus de précision les défauts structurels des images générées et fournir des signaux de rétroaction plus ciblés. Il convient de noter qu’en plus des modèles de segmentation d’instances, d’autres modèles de perception sont également applicables. Ces modèles perceptuels peuvent servir de retour complémentaire à l’esthétique subjective, en se concentrant davantage sur la qualité générative objective. Par conséquent, notre modèle de diffusion optimisé avec des signaux de rétroaction peut être défini comme :
est le modèle de segmentation d'instance (par exemple SOLO). Les modèles de segmentation d'instance peuvent capturer avec plus de précision les défauts structurels des images générées et fournir des signaux de rétroaction plus ciblés. Il convient de noter qu’en plus des modèles de segmentation d’instances, d’autres modèles de perception sont également applicables. Ces modèles perceptuels peuvent servir de retour complémentaire à l’esthétique subjective, en se concentrant davantage sur la qualité générative objective. Par conséquent, notre modèle de diffusion optimisé avec des signaux de rétroaction peut être défini comme :
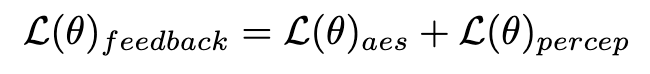
3. Amélioration de la génération en une étape
En raison des limites inhérentes à la perte de cohérence, la génération en une étape dans le cadre du modèle de cohérence n'est pas possible. idéal. Tel qu'analysé dans CM, le modèle de distillation cohérent montre une excellente précision dans le guidage du point final de la trajectoire  à la position
à la position  . Par conséquent, la distillation fractionnée est une méthode appropriée et efficace pour améliorer encore l’effet de génération en une étape de notre modèle TSCD. Plus précisément, nous faisons progresser la génération ultérieure grâce à une technique de distillation par correspondance de distribution optimisée (DMD). DMD améliore le résultat du modèle en utilisant deux fonctions de notation différentes : la distribution
. Par conséquent, la distillation fractionnée est une méthode appropriée et efficace pour améliorer encore l’effet de génération en une étape de notre modèle TSCD. Plus précisément, nous faisons progresser la génération ultérieure grâce à une technique de distillation par correspondance de distribution optimisée (DMD). DMD améliore le résultat du modèle en utilisant deux fonctions de notation différentes : la distribution 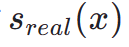 du modèle d'enseignant et la
du modèle d'enseignant et la 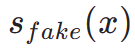 du faux modèle. Nous combinons la perte d’erreur quadratique moyenne (MSE) avec une distillation basée sur les scores pour améliorer la stabilité de l’entraînement. Dans ce processus, les techniques d'apprentissage par rétroaction humaine susmentionnées sont également intégrées pour affiner notre modèle afin de générer efficacement des images haute fidélité.
du faux modèle. Nous combinons la perte d’erreur quadratique moyenne (MSE) avec une distillation basée sur les scores pour améliorer la stabilité de l’entraînement. Dans ce processus, les techniques d'apprentissage par rétroaction humaine susmentionnées sont également intégrées pour affiner notre modèle afin de générer efficacement des images haute fidélité.
En intégrant ces stratégies, notre méthode obtient non seulement d'excellents résultats d'inférence à faible échelon sur SD1.5 et SDXL (et ne nécessite pas de guidage du classificateur), mais permet également d'obtenir un modèle de cohérence globale idéal sans avoir besoin de chacun d'un nombre spécifique. d'étapes est utilisé pour entraîner UNet ou LoRA afin d'obtenir un modèle de raisonnement unifié à faibles étapes.
Expériences
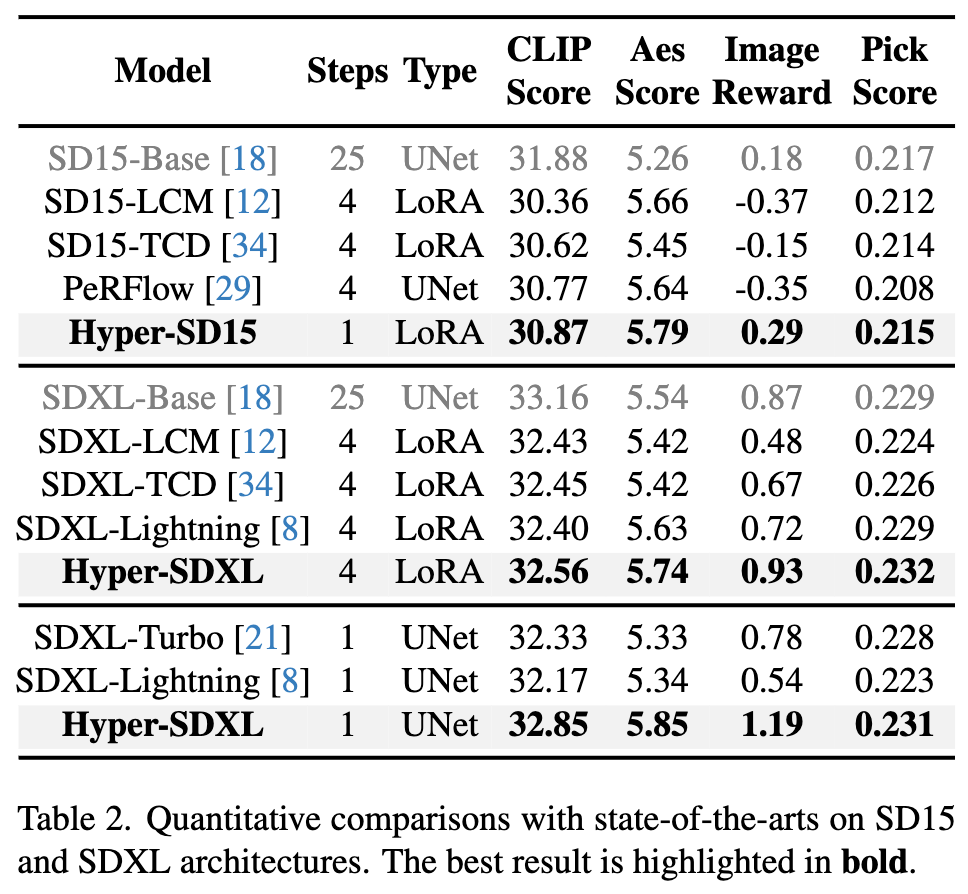
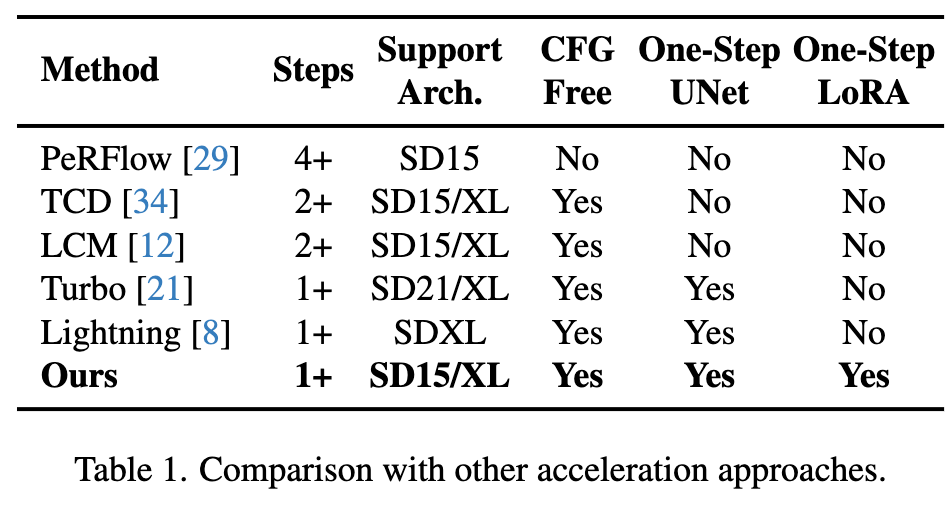
Comparaison quantitative de divers algorithmes d'accélération existants sur SD1.5 et SDXL, on peut voir que Hyper-SD est nettement meilleur que les méthodes de pointe actuelles
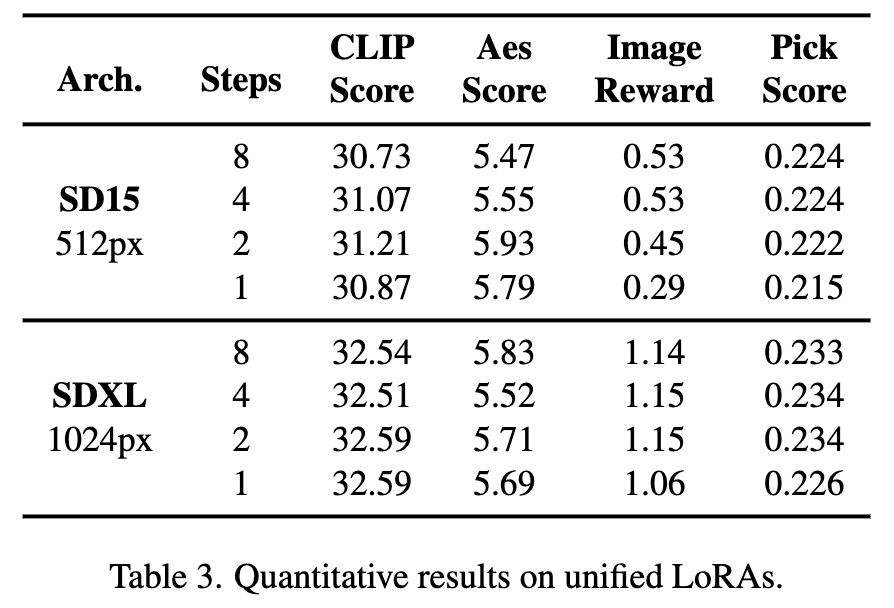
De plus, Hyper-SD peut utiliser un modèle pour réaliser diverses inférences à faible échelon. Les indicateurs quantitatifs ci-dessus montrent également l'effet de notre méthode lors de l'utilisation d'un modèle unifié pour l'inférence.


La visualisation de l'effet d'accélération sur SD1.5 et SDXL démontre intuitivement la supériorité de l'Hyper-SD dans l'accélération de l'inférence de modèle de diffusion.
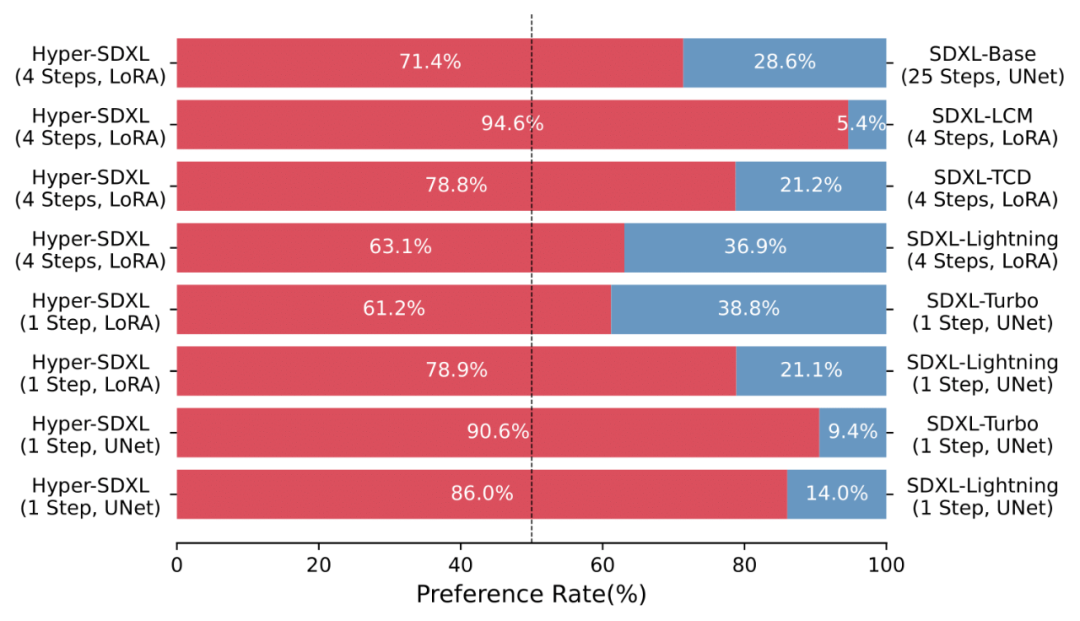
Un grand nombre d'études utilisateur montrent également la supériorité de l'Hyper-SD par rapport aux différents algorithmes d'accélération existants.

La LoRA accélérée entraînée par Hyper-SD est bien compatible avec différents styles de modèles de base de figurine Vincent.
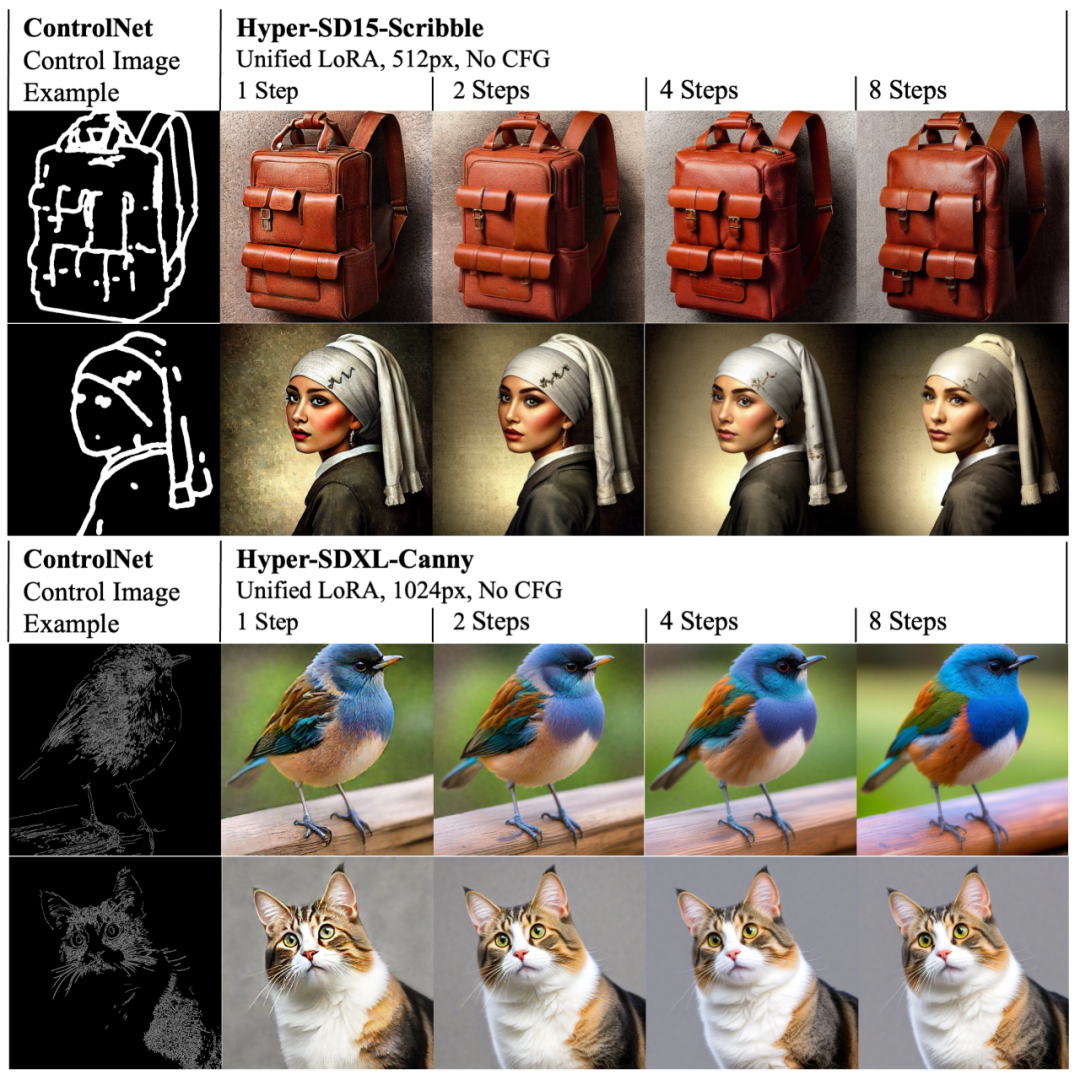
Dans le même temps, la LoRA d'Hyper-SD peut également s'adapter au ControlNet existant pour obtenir une génération d'images contrôlables de haute qualité en un faible nombre d'étapes.
Résumé
L'article propose Hyper-SD, un cadre d'accélération unifié des modèles de diffusion qui peut améliorer considérablement la capacité de génération de modèles de diffusion dans des situations à faible échelon et atteindre de nouvelles performances SOTA basées sur SDXL et SD15. Cette méthode utilise la distillation de cohérence de segmentation de trajectoire pour améliorer la capacité de préservation de la trajectoire pendant le processus de distillation et obtenir un effet de génération proche du modèle d'origine. Ensuite, le potentiel du modèle avec un nombre d'étapes extrêmement faible est amélioré en tirant davantage parti de l'apprentissage par rétroaction humaine et de la distillation fractionnée variationnelle, ce qui permet une génération de modèle plus optimisée et plus efficace. L'article a également publié en open source le plug-in Lora pour l'inférence SDXL et SD15 de 1 à 8 étapes, ainsi qu'un modèle SDXL dédié en une étape, visant à promouvoir davantage le développement de la communauté de l'IA générative.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
La bibliothèque utilisée pour le fonctionnement du numéro de point flottante dans le langage go présente comment s'assurer que la précision est ...
 Bitwise: les entreprises achètent un bitcoin une grande tendance négligée
Mar 05, 2025 pm 02:42 PM
Bitwise: les entreprises achètent un bitcoin une grande tendance négligée
Mar 05, 2025 pm 02:42 PM
Observation hebdomadaire: les entreprises thésaurisation du Bitcoin - un changement de brassage que je souligne souvent certaines tendances du marché négligées dans des mémos hebdomadaires. Le mouvement de Microstrategy est un exemple brutal. Beaucoup de gens peuvent dire: "Microstrategy et Michaelsaylor sont déjà bien connus, à quoi allez-vous faire attention?" Cette vue est unilatérale. Des recherches approfondies sur l'adoption du bitcoin en tant qu'actif de réserve au cours des derniers mois montrent qu'il ne s'agit pas d'un cas isolé, mais d'une tendance majeure qui émerge. Je prédis qu'au cours des 12 à 18 prochains mois, des centaines d'entreprises suivront le pas et achèteront de grandes quantités de Bitcoin
 Dépassant considérablement la SFT, le secret derrière O1 / Deepseek-R1 peut également être utilisé dans les grands modèles multimodaux
Mar 12, 2025 pm 01:03 PM
Dépassant considérablement la SFT, le secret derrière O1 / Deepseek-R1 peut également être utilisé dans les grands modèles multimodaux
Mar 12, 2025 pm 01:03 PM
Des chercheurs de l'Université de Shanghai Jiaotong, de Shanghai Ailab et de l'Université chinoise de Hong Kong ont lancé le projet open source Visual-RFT (visual d'amélioration), qui ne nécessite qu'une petite quantité de données pour améliorer considérablement les performances du gros modèle de langage visuel (LVLM). Visual-RFT combine intelligemment l'approche d'apprentissage en renforcement basée sur les règles de Deepseek-R1 avec le paradigme de relâchement de renforcement d'OpenAI (RFT), prolongeant avec succès cette approche du champ de texte au champ visuel. En concevant les récompenses de règles correspondantes pour des tâches telles que la sous-catégorisation visuelle et la détection d'objets, Visual-RFT surmonte les limites de la méthode Deepseek-R1 limitée au texte, au raisonnement mathématique et à d'autres domaines, fournissant une nouvelle façon de formation LVLM. Vis
 Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
GiteEpages STATIQUE Le déploiement du site Web a échoué: 404 Dépannage des erreurs et résolution lors de l'utilisation de Gitee ...
 Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou des projets open source bien connus? Lors de la programmation en Go, les développeurs rencontrent souvent des besoins communs, ...
 Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Description de la question: Comment obtenir les données de la région d'expédition de la version à l'étranger? Y a-t-il des ressources prêtes à l'emploi disponibles? Soyez précis dans le commerce électronique transfrontalier ou les entreprises mondialisées ...
 Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
L'exécution du projet H5 nécessite les étapes suivantes: Installation des outils nécessaires tels que le serveur Web, Node.js, les outils de développement, etc. Créez un environnement de développement, créez des dossiers de projet, initialisez les projets et écrivez du code. Démarrez le serveur de développement et exécutez la commande à l'aide de la ligne de commande. Aperçu du projet dans votre navigateur et entrez l'URL du serveur de développement. Publier des projets, optimiser le code, déployer des projets et configurer la configuration du serveur Web.
 CONTRIBLÉE DE MADIFICATION DE LA ROUTE TYPECHO: Pourquoi mon / Test / Tag / son / 10086 correspondant à TestTagIndex au lieu de TestTagPage?
Apr 01, 2025 am 09:03 AM
CONTRIBLÉE DE MADIFICATION DE LA ROUTE TYPECHO: Pourquoi mon / Test / Tag / son / 10086 correspondant à TestTagIndex au lieu de TestTagPage?
Apr 01, 2025 am 09:03 AM
Analyse des règles de correspondance de routage Typecho et enquête sur les problèmes Cet article analysera et répondra aux questions sur les résultats incohérents de l'enregistrement du routage du plug-in Typecho et des résultats de correspondance réels ...
