
 Périphériques technologiques
IA
L'index de grand modèle multimodal de texte 8B est proche de GPT4V, proposé conjointement par Byte, Huashan et Huake, TextSquare.
Périphériques technologiques
IA
L'index de grand modèle multimodal de texte 8B est proche de GPT4V, proposé conjointement par Byte, Huashan et Huake, TextSquare.
L'index de grand modèle multimodal de texte 8B est proche de GPT4V, proposé conjointement par Byte, Huashan et Huake, TextSquare.


La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous avez un excellent travail que vous souhaitez partager, veuillez soumettre un article ou contacter l'e-mail de rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com.
Récemment, les grands modèles multimodaux (MLLM) ont fait des progrès significatifs dans le domaine de la VQA centrée sur le texte, en particulier plusieurs modèles à source fermée, tels que : GPT4V et Gemini, montrant même des performances surhumaines dans certains aspects. de capacité. Cependant, les performances des modèles open source sont encore loin derrière les modèles fermés. Récemment, de nombreuses études révolutionnaires, telles que : MonKey, LLaVAR, TG-Doc, ShareGPT4V, etc., ont commencé à se concentrer sur le problème de l'insuffisance des instructions. données de réglage. Bien que ces efforts aient abouti à des résultats remarquables, certains problèmes subsistent. Les données de description d'image et les données VQA appartiennent à des domaines différents, et il existe des incohérences dans la granularité et la portée de la présentation du contenu de l'image. De plus, la taille relativement petite des données synthétiques empêche MLLM de réaliser tout son potentiel.

Titre de l'article : TextSquare : Scaling up Text-Centric Visual Instruction Tuning
Adresse de l'article : https://arxiv.org/abs/2404.12803
Afin de réduire cela
Génération de données VQA
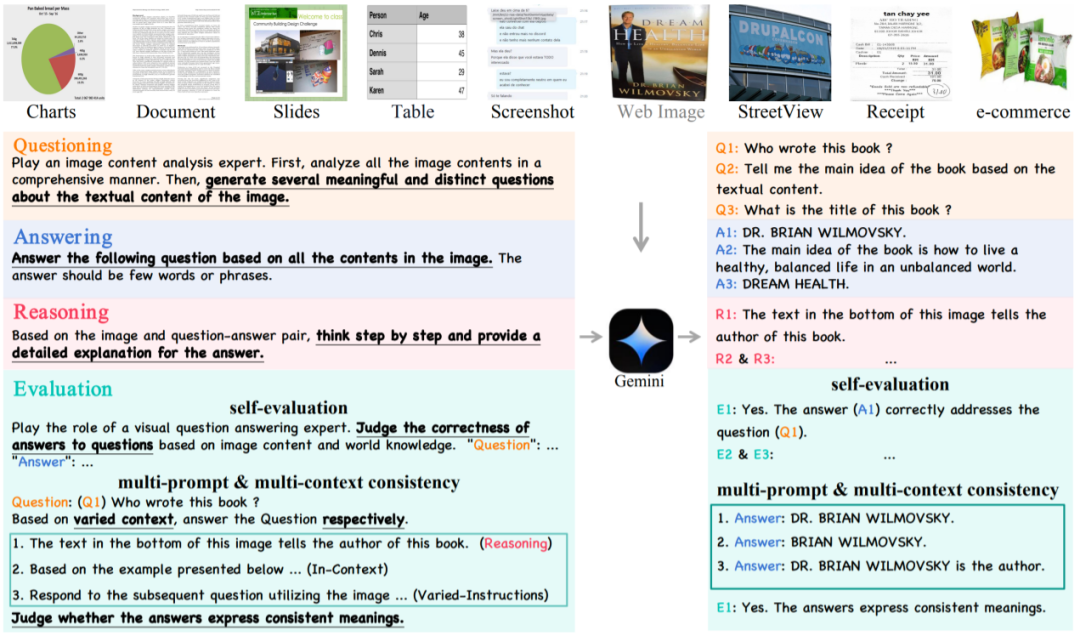
La méthode stratégique Square+ comprend quatre étapes : Auto-questionnement, Réponse, Raisonnement et Auto-évaluation. L'auto-questionnement exploite les capacités de MLLM en matière d'analyse et de compréhension texte-image pour générer des questions liées au contenu du texte dans l'image. L'auto-réponse utilise diverses techniques d'incitation telles que Thought Chain CoT et Few-shot pour fournir des réponses à ces questions. L'auto-raisonnement utilise les puissantes capacités de raisonnement des MLLM pour générer le processus de raisonnement derrière le modèle. L'auto-évaluation améliore la qualité des données et réduit les biais en évaluant la validité des questions, leur pertinence par rapport au contenu du texte de l'image et l'exactitude des réponses. S Figure 1, comparaison du modèle open source et fermé de TextSquare et de source avancée, le classement moyen sur Benchmark sur 10 textes a dépassé GPT4V (classement 2,2 contre 2,4). Les chercheurs ont collecté un ensemble diversifié d'images contenant une grande quantité de texte. à partir de diverses sources publiques, y compris des scènes naturelles, des graphiques, des formulaires, des reçus, des livres, des PPT, des PDF, etc. pour construire Square-10M, et sur la base de cet ensemble de données, nous avons formé le MLLM TextSquare-8B suivant, centré sur la compréhension du texte.
Comme le montre la figure 1, TextSquare-8B peut obtenir des résultats comparables ou meilleurs que GPT4V et Gemini sur plusieurs benchmarks, et dépasse largement les autres modèles open source. Les expériences TextSquare ont vérifié l'impact positif des données d'inférence sur la tâche VQA, démontrant leur capacité à améliorer les performances du modèle tout en réduisant les hallucinations. 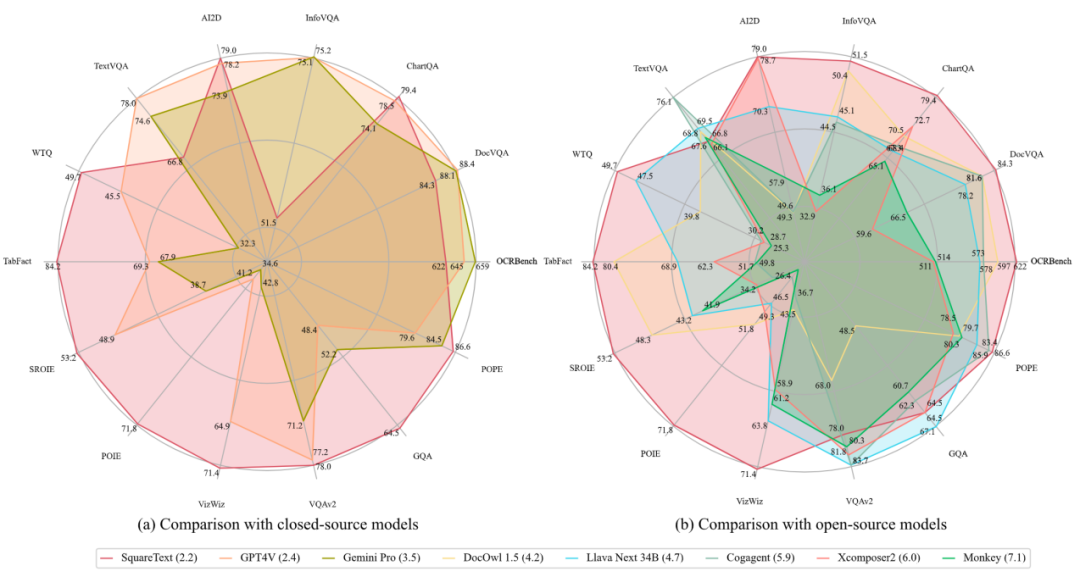
Figure 3 Square-10M Détails de la distribution des images et de la distribution QA
 . collecte de données
. collecte de données
L'objectif principal de la stratégie de collecte de données est de couvrir un large éventail de scénarios réels riches en texte. À cette fin, les chercheurs ont collecté 3,8 millions d’images riches en texte. Ces images présentent des caractéristiques différentes, par exemple, les graphiques et les tableaux se concentrent sur des éléments de texte contenant des informations statistiques denses ; les PPT, les captures d'écran et les images Web sont conçus pour l'interaction entre le texte et les informations visuelles mises en évidence, les reçus et les images du commerce électronique ; avec un texte détaillé et dense, les vues de rue sont dérivées de scènes naturelles. Les images collectées constituent une cartographie des éléments textuels du monde réel et constituent la base de l'étude de la VQA centrée sur le texte.
Génération de données
Les chercheurs utilisent les capacités de compréhension multimodale de Gemini Pro pour sélectionner des images à partir de sources de données spécifiques et générer des paires de contextes VQA et d'inférence à travers trois étapes d'auto-interrogation, d'auto-réponse et d'auto-inférence.
Auto-question : Certaines invites seront données à ce stade. Gemini Pro effectuera une analyse complète de l'image sur la base de ces invites et générera des questions significatives basées sur la compréhension. Considérant que la capacité générale du MLLM à comprendre les éléments de texte est généralement plus faible que celle des modèles visuels, nous prétraitons le texte extrait en invite via un modèle OCR spécialisé.
Auto-réponse : Gemini Pro utilisera la chaîne de pensée (CoT) et l'incitation à quelques tirs (invite à quelques tirs) et d'autres technologies pour générer des questions afin d'enrichir les informations contextuelles et d'améliorer la fiabilité des réponses générées.
Auto-raisonnement : Cette étape génère des raisons détaillées pour la réponse, obligeant Gemini Pro à réfléchir davantage au lien entre la question et les éléments visuels, réduisant ainsi les illusions et améliorant les réponses précises.
Filtrage des données
Bien que les questions, les réponses et le raisonnement soient efficaces, les paires image-texte générées peuvent être confrontées à un contenu illusoire, à des questions dénuées de sens et à des réponses incorrectes. Par conséquent, nous concevons des règles de filtrage basées sur les capacités d'évaluation de LLM pour sélectionner des paires VQA de haute qualité.
Auto-évaluation invite Gemini Pro et d'autres MLLM à déterminer si les questions générées ont du sens et si les réponses sont suffisantes pour résoudre correctement le problème.
Cohérence multi-invites En plus d'évaluer directement le contenu généré, les chercheurs ajoutent également manuellement des invites et un espace contextuel dans la génération de données. Une paire VQA correcte et significative doit être sémantiquement cohérente lorsque différentes invites sont fournies.
Cohérence multi-contexte Les chercheurs ont en outre vérifié la paire VQA en préparant différentes informations contextuelles avant la question.
TextSquare-8B
TextSquare-8B s'appuie sur la structure du modèle d'InternLM-Xcomposer2, y compris l'encodeur visuel de CLIP ViT-L-14-336, et la résolution de l'image est encore augmentée à 700 sur la base de ; InternLM2-7B-ChatSFT Grand modèle de langage LLM ; un projecteur de pont qui aligne les jetons visuels et textuels.
La formation de TextSquare-8B comprend trois étapes de SFT :
La première étape affine le modèle avec tous les paramètres (Vision Encoder, Projecteur, LLM) à une résolution de 490.
Dans la deuxième étape, la résolution d'entrée est augmentée à 700 et seul le Vision Encoder est formé pour s'adapter au changement de résolution.
Dans la troisième étape, un réglage fin complet des paramètres est effectué à une résolution de 700.
TextSquare confirme que, sur la base de l'ensemble de données Square-10M, un modèle avec des paramètres 8B et une résolution d'image de taille normale peut obtenir de meilleures performances sur le VQA centré sur le texte que la plupart des MLLM, même les modèles à source fermée (GPT4V, Gemini Pro).
Résultats expérimentaux
La figure 4(a) montre que TextSquare a des fonctions arithmétiques simples. La figure 4 (b) montre la capacité à comprendre le contenu du texte et à fournir une localisation approximative dans un texte dense. La figure 4(c) montre la capacité de TextSquare à comprendre les structures des tableaux.

MLLM Benchmark
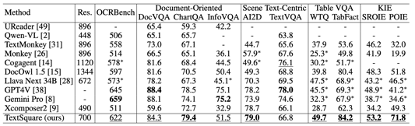
Benchmark orienté document Dans la scène documentaire VQA Benckmark (DocVQA, ChartQA, InfographicVQA), l'amélioration moyenne est de 3,5%, meilleure que tous les modèles open source, dans les données ChartQA L'ensemble est légèrement supérieur à celui de GPT4V et Gemini Pro. La résolution de ce modèle n'est que de 700, ce qui est plus petit que la plupart des MLLM orientés documents. Si la résolution est encore améliorée, je pense que les performances du modèle seront également encore améliorées. Monkey l’a prouvé.
Benchmark centré sur le texte de scène Le benchmark VQA (TextVQA, AI2D) des scènes naturelles a obtenu des résultats SOTA, mais il n'y a pas d'amélioration majeure par rapport à la référence Xcomposer2. Cela peut être dû au fait que Xcomposer2 a utilisé des éléments de haute qualité. domaine Les données sont entièrement optimisées.
Table VQA Benchmark Dans le VQA Benchmark (WTQ, TabFact) de la scène des tables, il a obtenu des résultats qui dépassent de loin ceux de GPT4V et Gemini Pro, dépassant respectivement les autres modèles SOTA de 3%.
Benchmark KIE centré sur le texte Extrayez les informations clés du centre de texte du benchmark de tâches KIE (SROIE, POIE), convertissez la tâche KIE en tâche VQA et obtenez les meilleures performances dans les deux ensembles de données, avec un amélioration moyenne de 14,8 %.
OCRBench Comprenant 29 tâches d'évaluation liées à l'OCR telles que la reconnaissance de texte, la reconnaissance de formules, le VQA centré sur le texte, le KIE, etc., a obtenu les meilleures performances du modèle open source et est devenu le premier paramètre de 10 B à atteindre atteindre 600 points Modèle.
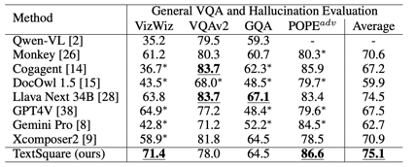
Benchmark général d'évaluation VQA et hallucination Par rapport à Xconposer2, TextSquare ne présente aucune dégradation significative et conserve toujours les meilleures performances sur le benchmark général VQA (VizWiz VQAv2, GQA, POPE show). des performances significatives, 3,6% supérieures aux meilleures méthodes, ce qui met en évidence l'efficacité de la méthode pour atténuer les hallucinations des modèles.
Expérience d'ablation

TextSquare a une amélioration moyenne de 7,7% dans chaque benchmark par rapport à Xcomposer2.
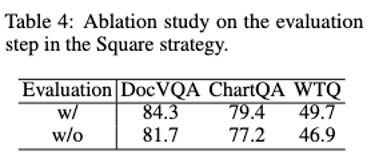
Après l'ajout de l'auto-évaluation, les performances du modèle ont été considérablement améliorées.
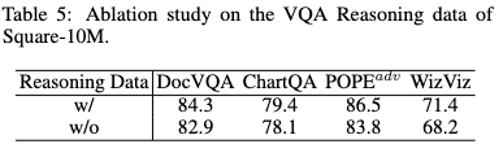
L'ajout de données d'inférence peut aider à améliorer considérablement les performances et à réduire la génération d'hallucinations.
Relation entre l'échelle des données, la perte de convergence et les performances du modèle
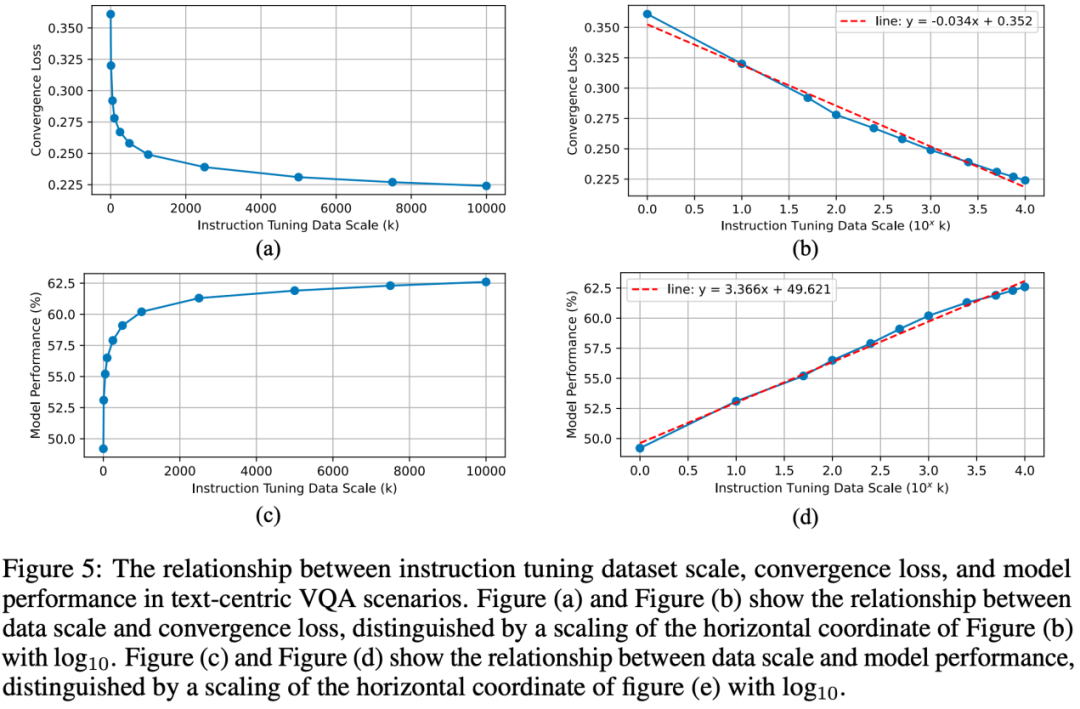
À mesure que l'échelle des données augmente, la perte du modèle continue de diminuer et le taux de déclin ralentit progressivement. La relation entre la perte de convergence et les données de mise à l'échelle des instructions se rapproche d'une fonction logarithmique.
Avec la croissance des données de réglage des instructions, les performances du modèle s'améliorent de plus en plus, mais le taux de croissance continue de ralentir et correspond à peu près à la fonction logarithmique.
En général, dans les scénarios VQA centrés sur le texte, il existe une loi d'échelle correspondante dans la phase d'ajustement des instructions, dans laquelle les performances du modèle sont proportionnelles au logarithme de la mise à l'échelle des données, ce qui peut guider la construction d'ensembles de données potentiellement plus grands et prédire les modèles. performance.
Résumé
Dans cet article, les chercheurs ont proposé une stratégie Square pour créer un ensemble de données de réglage d'instructions centrées sur le texte de haute qualité (Square-10M). En utilisant cet ensemble de données, TextSquare-8B a bien fonctionné sur plusieurs benchmarks. atteint des performances comparables à GPT4V et surpasse considérablement les modèles open source récemment publiés sur divers benchmarks.
En outre, les chercheurs ont dérivé la relation entre la taille de l'ensemble de données d'ajustement des instructions, la perte de convergence et les performances du modèle pour ouvrir la voie à la création d'ensembles de données plus volumineux, confirmant que la quantité et la qualité des données sont essentielles à la performance du modèle.
Enfin, les chercheurs ont souligné que la manière d'améliorer davantage la quantité et la qualité des données afin de réduire l'écart entre les modèles open source et les modèles leaders est considérée comme une direction de recherche très prometteuse.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
Il s'agit également d'une vidéo Tusheng, mais PaintsUndo a emprunté une voie différente. L'auteur de ControlNet, LvminZhang, a recommencé à vivre ! Cette fois, je vise le domaine de la peinture. Le nouveau projet PaintsUndo a reçu 1,4kstar (toujours en hausse folle) peu de temps après son lancement. Adresse du projet : https://github.com/lllyasviel/Paints-UNDO Grâce à ce projet, l'utilisateur saisit une image statique et PaintsUndo peut automatiquement vous aider à générer une vidéo de l'ensemble du processus de peinture, du brouillon de ligne au suivi du produit fini. . Pendant le processus de dessin, les changements de lignes sont étonnants. Le résultat vidéo final est très similaire à l’image originale : jetons un coup d’œil à un dessin complet.
 Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Dans le processus de développement de l'intelligence artificielle, le contrôle et le guidage des grands modèles de langage (LLM) ont toujours été l'un des principaux défis, visant à garantir que ces modèles sont à la fois puissant et sûr au service de la société humaine. Les premiers efforts se sont concentrés sur les méthodes d’apprentissage par renforcement par feedback humain (RL
 En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Les auteurs de cet article font tous partie de l'équipe de l'enseignant Zhang Lingming de l'Université de l'Illinois à Urbana-Champaign (UIUC), notamment : Steven Code repair ; doctorant en quatrième année, chercheur
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
Montrez la chaîne causale à LLM et il pourra apprendre les axiomes. L'IA aide déjà les mathématiciens et les scientifiques à mener des recherches. Par exemple, le célèbre mathématicien Terence Tao a partagé à plusieurs reprises son expérience de recherche et d'exploration à l'aide d'outils d'IA tels que GPT. Pour que l’IA soit compétitive dans ces domaines, des capacités de raisonnement causal solides et fiables sont essentielles. La recherche présentée dans cet article a révélé qu'un modèle Transformer formé sur la démonstration de l'axiome de transitivité causale sur de petits graphes peut se généraliser à l'axiome de transitivité sur de grands graphes. En d’autres termes, si le Transformateur apprend à effectuer un raisonnement causal simple, il peut être utilisé pour un raisonnement causal plus complexe. Le cadre de formation axiomatique proposé par l'équipe est un nouveau paradigme pour l'apprentissage du raisonnement causal basé sur des données passives, avec uniquement des démonstrations.
 Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
acclamations! Qu’est-ce que ça fait lorsqu’une discussion sur papier se résume à des mots ? Récemment, des étudiants de l'Université de Stanford ont créé alphaXiv, un forum de discussion ouvert pour les articles arXiv qui permet de publier des questions et des commentaires directement sur n'importe quel article arXiv. Lien du site Web : https://alphaxiv.org/ En fait, il n'est pas nécessaire de visiter spécifiquement ce site Web. Il suffit de remplacer arXiv dans n'importe quelle URL par alphaXiv pour ouvrir directement l'article correspondant sur le forum alphaXiv : vous pouvez localiser avec précision les paragraphes dans. l'article, Phrase : dans la zone de discussion sur la droite, les utilisateurs peuvent poser des questions à l'auteur sur les idées et les détails de l'article. Par exemple, ils peuvent également commenter le contenu de l'article, tels que : "Donné à".
 Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Récemment, l’hypothèse de Riemann, connue comme l’un des sept problèmes majeurs du millénaire, a réalisé une nouvelle avancée. L'hypothèse de Riemann est un problème mathématique non résolu très important, lié aux propriétés précises de la distribution des nombres premiers (les nombres premiers sont les nombres qui ne sont divisibles que par 1 et par eux-mêmes, et jouent un rôle fondamental dans la théorie des nombres). Dans la littérature mathématique actuelle, il existe plus d'un millier de propositions mathématiques basées sur l'établissement de l'hypothèse de Riemann (ou sa forme généralisée). En d’autres termes, une fois que l’hypothèse de Riemann et sa forme généralisée seront prouvées, ces plus d’un millier de propositions seront établies sous forme de théorèmes, qui auront un impact profond sur le domaine des mathématiques et si l’hypothèse de Riemann s’avère fausse, alors parmi eux ; ces propositions qui en font partie perdront également de leur efficacité. Une nouvelle percée vient du professeur de mathématiques du MIT, Larry Guth, et de l'Université d'Oxford
 Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Génération vidéo illimitée, planification et prise de décision, diffusion, intégration forcée de la prédiction du prochain jeton et diffusion de la séquence complète
Jul 23, 2024 pm 02:05 PM
Actuellement, les modèles linguistiques autorégressifs à grande échelle utilisant le prochain paradigme de prédiction de jetons sont devenus populaires partout dans le monde. Dans le même temps, un grand nombre d'images et de vidéos synthétiques sur Internet nous ont déjà montré la puissance des modèles de diffusion. Récemment, une équipe de recherche de MITCSAIL (dont Chen Boyuan, doctorant au MIT) a intégré avec succès les puissantes capacités du modèle de diffusion en séquence complète et du prochain modèle de jeton, et a proposé un paradigme de formation et d'échantillonnage : le forçage de diffusion (DF ). Titre de l'article : DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Adresse de l'article : https://
