
 Périphériques technologiques
IA
Yan Shuicheng a pris les commandes et a établi la forme ultime du « grand modèle visuel multimodal universel » ! Compréhension/génération/segmentation/édition unifiée
Périphériques technologiques
IA
Yan Shuicheng a pris les commandes et a établi la forme ultime du « grand modèle visuel multimodal universel » ! Compréhension/génération/segmentation/édition unifiée
Yan Shuicheng a pris les commandes et a établi la forme ultime du « grand modèle visuel multimodal universel » ! Compréhension/génération/segmentation/édition unifiée

Récemment, le professeur Yan Shuicheng team A publié conjointement et en open source le grand modèle de langage visuel multimodal universel au niveau des pixels Vitron.

Page d'accueil et démo du projet : https://www.php.cn/link/d8a3b2dde3181c8257e2e45efbd1e8aeLien papier : https://www.php.cn/link/0ec5ba 872f117 9835987f9028c4cc4df code open source :https://www.php.cn/link/26d6e896db39edc7d7bdd357d6984c95
Il s'agit d'un modèle multimodal visuel général robuste qui prend en charge tout, depuis une série de tâches visuelles allant de la compréhension visuelle à la génération visuelle, du niveau bas au niveau élevé, résout le problème de séparation des modèles image/vidéo qui tourmente depuis longtemps la grande industrie des modèles de langage et fournit une compréhension complète et unifiée et la génération d'images statiques et de contenu vidéo dynamique. Le grand modèle visuel multimodal à usage général au niveau des pixels pour des tâches telles que la segmentation et l'édition jette les bases de la forme ultime du grand modèle visuel à usage général de nouvelle génération. , et marque également un autre grand pas vers l’intelligence artificielle générale (AGI) pour les grands modèles.
Vitron, en tant que grand modèle de langage visuel multimodal unifié au niveau des pixels, offre une prise en charge complète des tâches visuelles de bas niveau à haut niveau, peut gérer des tâches visuelles complexes et comprendre et générer des images. et du contenu vidéo, offrant de puissantes capacités de compréhension visuelle et d’exécution de tâches. Dans le même temps, Vitron prend en charge les opérations continues avec les utilisateurs, permettant une interaction homme-machine flexible, démontrant le grand potentiel vers un modèle universel multimodal visuel plus unifié.
Les articles, codes et démonstrations liés à Vitron ont tous été rendus publics. Ses avantages et son potentiel uniques en termes d'exhaustivité, d'innovation technologique, d'interaction homme-machine et de potentiel d'application n'ont pas seulement favorisé la multimodalité. le développement de grands modèles ouvre également une nouvelle direction pour la recherche future sur les grands modèles visuels. Le développement actuel des grands modèles de langage visuels (LLM) a fait des progrès gratifiants. La communauté croit de plus en plus que la construction de grands modèles multimodaux (MLLM) plus généraux et plus puissants sera le seul moyen de parvenir à une intelligence artificielle générale (AGI). Cependant, il reste encore quelques défis majeurs dans le processus d'évolution vers un modèle général multimodal (Généraliste). Par exemple, une grande partie du travail ne parvient pas à une compréhension visuelle fine au niveau des pixels, ou manque de prise en charge unifiée pour les images et les vidéos. Ou bien la prise en charge de diverses tâches visuelles est insuffisante, et c'est loin d'être un grand modèle universel. Afin de combler cette lacune, l'équipe a récemment publié conjointement le grand modèle de langage visuel multimodal universel open source Vitron au niveau des pixels. Vitron prend en charge une série de tâches visuelles allant de la compréhension visuelle à la génération visuelle, du niveau bas au niveau élevé, y compris la compréhension, la génération, la segmentation et l'édition complètes d'images statiques et de contenu vidéo dynamique. 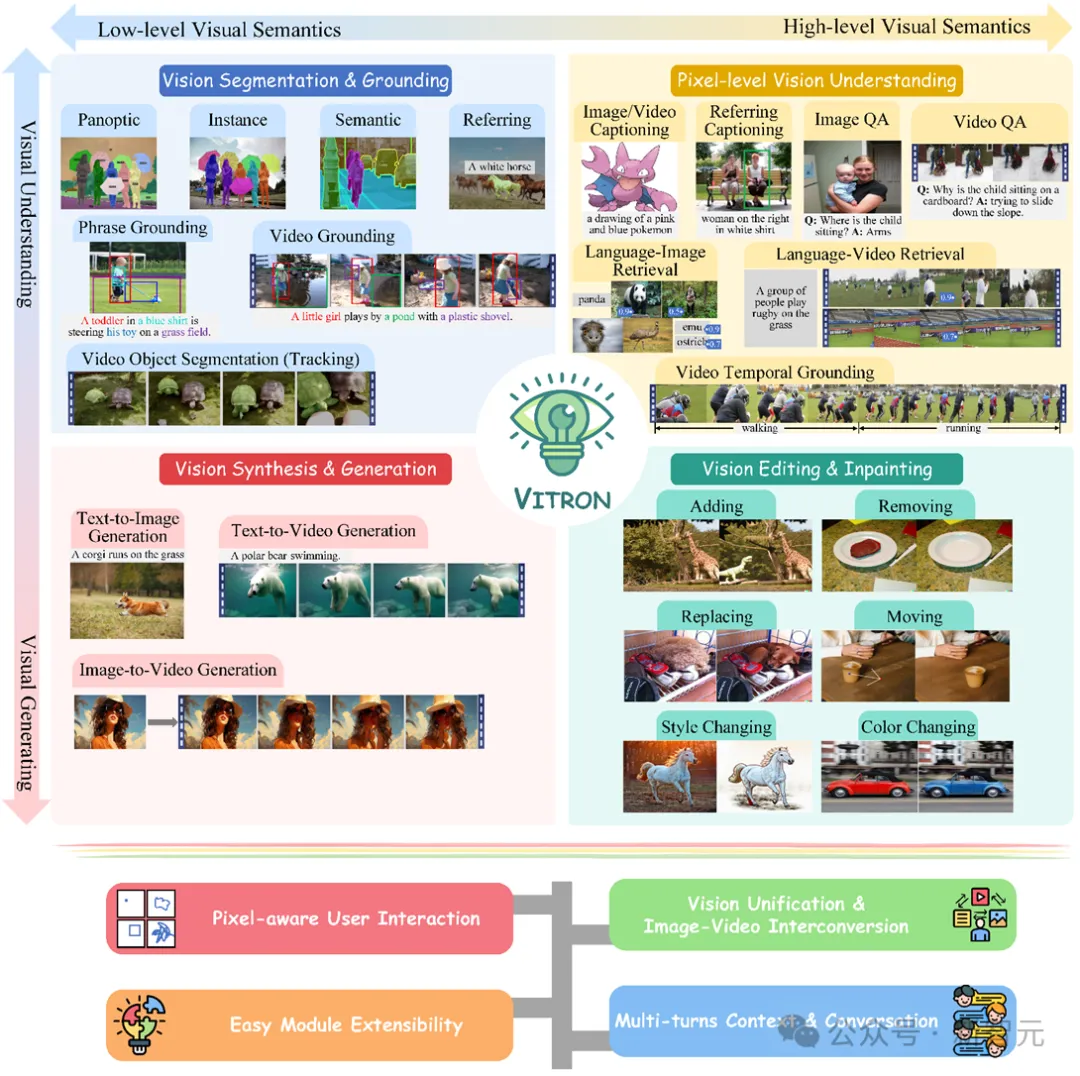 La figure ci-dessus décrit de manière exhaustive le support fonctionnel de Vitron pour quatre tâches majeures liées à la vision, ainsi que ses principaux avantages. Vitron prend également en charge un fonctionnement continu avec les utilisateurs pour obtenir une interaction homme-machine flexible. Ce projet démontre le grand potentiel d’un modèle général multimodal de vision plus unifiée, jetant les bases de la forme ultime de la prochaine génération de grands modèles de vision générale. Les articles, codes et démos liés à Vitron sont désormais tous publics.
La figure ci-dessus décrit de manière exhaustive le support fonctionnel de Vitron pour quatre tâches majeures liées à la vision, ainsi que ses principaux avantages. Vitron prend également en charge un fonctionnement continu avec les utilisateurs pour obtenir une interaction homme-machine flexible. Ce projet démontre le grand potentiel d’un modèle général multimodal de vision plus unifiée, jetant les bases de la forme ultime de la prochaine génération de grands modèles de vision générale. Les articles, codes et démos liés à Vitron sont désormais tous publics.
Le modèle de grand langage multimodal unifié ultime
Ces dernières années, les grands modèles de langage (LLM) ont démontré des capacités puissantes sans précédent, et ils ont été progressivement vérifiés comme la voie technique vers l'AGI. Les grands modèles de langage multimodaux (MLLM) se développent rapidement dans de nombreuses communautés et émergent rapidement. En introduisant des modules capables d'effectuer une perception visuelle, les LLM purement linguistiques sont étendus aux MLLM. De nombreux MLLM puissants et excellents dans la compréhension des images ont été développés. tels que BLIP-2, LLaVA, MiniGPT-4, etc. Parallèlement, des MLLM axés sur la compréhension de la vidéo ont également été lancés, tels que VideoChat, Video-LLaMA, Video-LLaVA, etc.
Par la suite, les chercheurs ont principalement tenté d'étendre davantage les capacités des MLLM à partir de deux dimensions. D'une part, les chercheurs tentent d'approfondir la compréhension de la vision par les MLLM, en passant d'une compréhension approximative au niveau de l'instance à une compréhension fine des images au niveau des pixels, obtenant ainsi des capacités de positionnement de région visuelle (Regional Grounding), telles que GLaMM, PixelLM. , NExT-Chat et MiniGPT-v2 etc.
D'autre part, les chercheurs tentent d'étendre les fonctions visuelles que les MLLM peuvent prendre en charge. Certaines recherches ont commencé à étudier comment les MLLM non seulement comprennent les signaux visuels d'entrée, mais prennent également en charge la génération de contenu visuel de sortie. Par exemple, les MLLM tels que GILL et Emu peuvent générer du contenu d'image de manière flexible, et GPT4Video et NExT-GPT réalisent la génération de vidéo.
À l'heure actuelle, la communauté de l'intelligence artificielle est progressivement parvenue à un consensus selon lequel la tendance future des MLLM visuels évoluera inévitablement dans le sens de capacités hautement unifiées et plus fortes. Cependant, malgré les nombreux MLLM développés par la communauté, une lacune évidente existe encore.
1. Presque tous les LLM visuels existants traitent les images et les vidéos comme des entités différentes et ne prennent en charge que les images ou uniquement les vidéos.
Les chercheurs préconisent que la vision devrait inclure à la fois des images statiques et des vidéos dynamiques - les deux sont des composants essentiels du monde visuel et peuvent même être interchangés dans la plupart des scénarios. Par conséquent, il est nécessaire de créer un cadre MLLM unifié pouvant prendre en charge à la fois les modalités image et vidéo.
2. Actuellement, la prise en charge des fonctions visuelles par les MLLM est encore insuffisante.
La plupart des modèles sont uniquement capables de comprendre, ou tout au plus de générer des images ou des vidéos. Les chercheurs estiment que les futurs MLLM devraient être un grand modèle de langage général capable de couvrir un plus large éventail de tâches et d'opérations visuelles, d'obtenir une prise en charge unifiée de toutes les tâches liées à la vision et d'atteindre des capacités « un pour tous ». Ceci est crucial pour les applications pratiques, notamment dans la création visuelle qui implique souvent une série d’opérations itératives et interactives.
Par exemple, les utilisateurs commencent généralement par du texte et convertissent une idée en contenu visuel via des diagrammes de Vincent ; puis affinent l'idée initiale et ajoutent plus de détails grâce à une édition d'image plus fine, puis génèrent une vidéo via des images ; du contenu dynamique ; enfin, effectuer plusieurs séries d'interactions itératives, comme le montage vidéo, pour affiner la création.
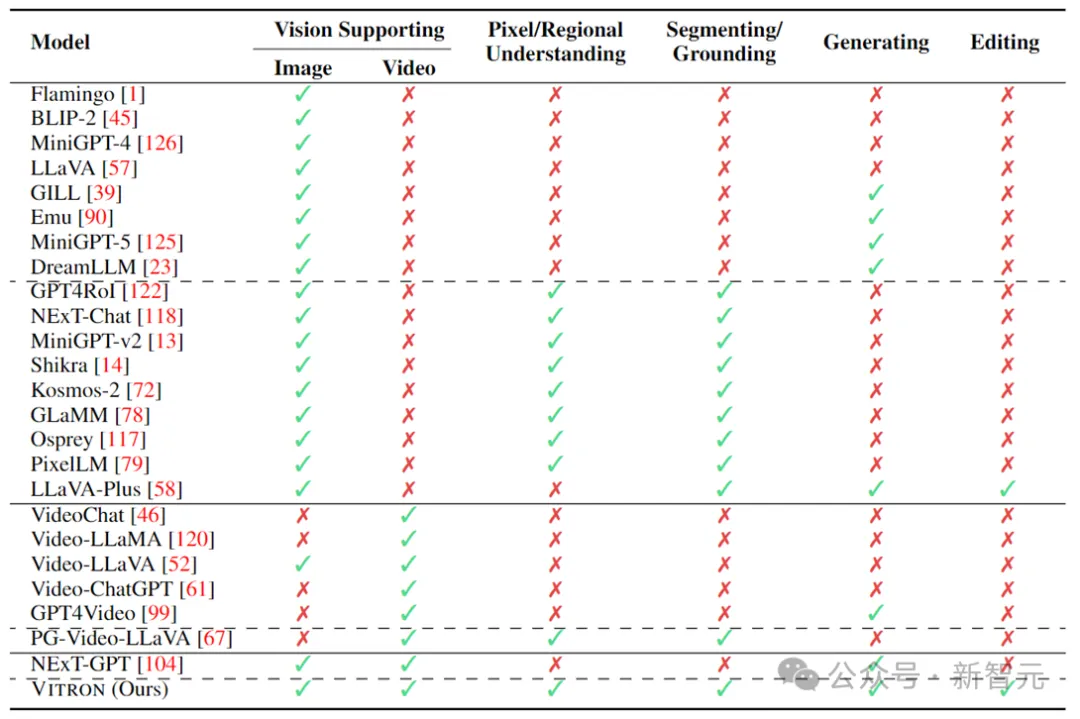
Le tableau ci-dessus résume simplement les capacités du MLLM visuel existant (n'inclut que de manière représentative certains modèles et la couverture est incomplète). Pour combler ces lacunes, l'équipe propose Vitron, un MLLM visuel général au niveau des pixels.
Architecture du système Vitron : trois modules clés
Le cadre global de Vitron est présenté dans la figure ci-dessous. Vitron adopte une architecture similaire aux MLLM associés existants, comprenant trois parties clés : 1) module d'encodage visuel et linguistique frontal, 2) module central de compréhension et de génération de texte du LLM, et 3) réponse de l'utilisateur back-end et appels de module pour le contrôle visuel. module.
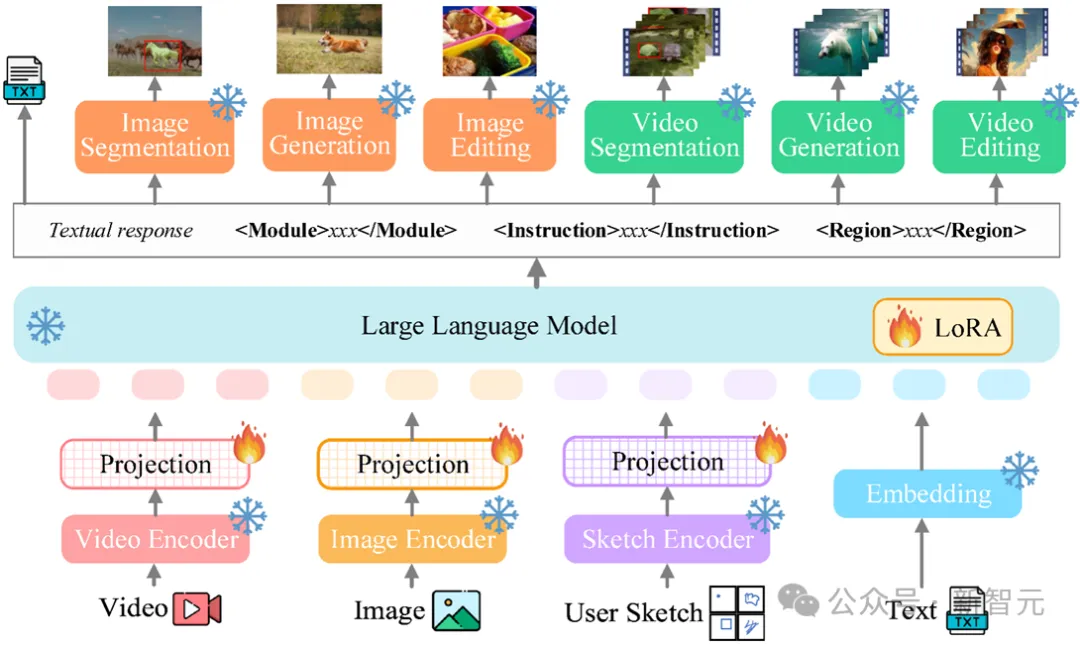
Module frontal : Codage visuo-linguistique
Afin de percevoir les signaux modaux d'image et de vidéo et de prendre en charge la saisie visuelle fine de l'utilisateur, Vitron intègre un encodeur d'image, un encodeur vidéo, Encodeur de boîte de région/croquis.
Module central : Core LLM
Vitron utilise Vicuna (7B, v1.5) pour parvenir à la compréhension, au raisonnement, à la prise de décision et à plusieurs cycles d'interaction utilisateur.
Module Backend : Réponse de l'utilisateur et appel de module
Vitron adopte une stratégie d'appel centrée sur le texte et intègre plusieurs modules de traitement d'image et vidéo disponibles sur étagère (SoTA) puissants et avancés pour le décodage et effectuer une gamme de tâches de terminal visuel de niveaux bas à élevés. En adoptant une méthode d'appel d'intégration de module centrée sur le texte, Vitron réalise non seulement l'unification du système, mais garantit également l'efficacité de l'alignement et l'évolutivité du système.
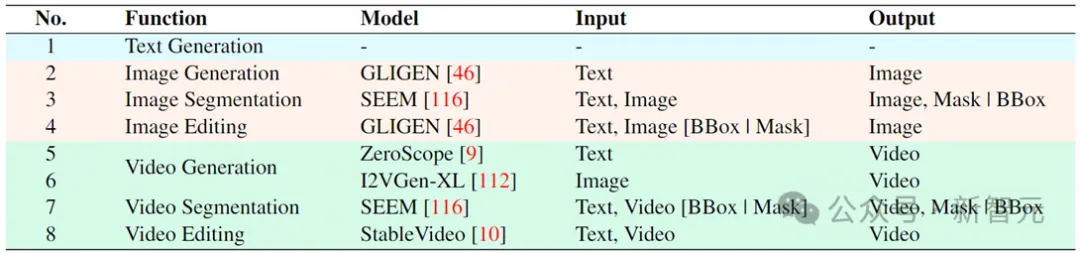
Trois étapes principales de la formation du modèle Vitron
Basé sur l'architecture ci-dessus, Vitron est formé et affiné pour lui donner de puissantes capacités de compréhension visuelle et d'exécution de tâches. La formation du modèle comprend principalement trois étapes différentes.
Étape 1 : Apprentissage de l'alignement global visuel-verbal. Les caractéristiques du langage visuel d'entrée sont mappées dans un espace de caractéristiques unifié, lui permettant ainsi de comprendre efficacement les signaux multimodaux d'entrée. Il s’agit d’un apprentissage d’alignement visuo-linguistique à gros grain qui permet au système de traiter efficacement les signaux visuels entrants dans leur ensemble. Les chercheurs ont utilisé des ensembles de données existants de paire image-légende (CC3M), de paire vidéo-légende (Webvid) et de paire région-légende (RefCOCO) pour la formation.
Étape 2 : Ajustement fin des instructions de positionnement visuel spatio-temporel. Le système utilise des modules externes pour effectuer diverses tâches visuelles au niveau des pixels, mais LLM lui-même n'a subi aucune formation visuelle fine, ce qui empêchera le système d'atteindre une véritable compréhension visuelle au niveau des pixels. À cette fin, les chercheurs ont proposé une formation de réglage précis des instructions de positionnement visuel spatio-temporel. L’idée principale est de permettre à LLM de localiser la spatialité fine de l’image et les caractéristiques temporelles spécifiques de la vidéo.
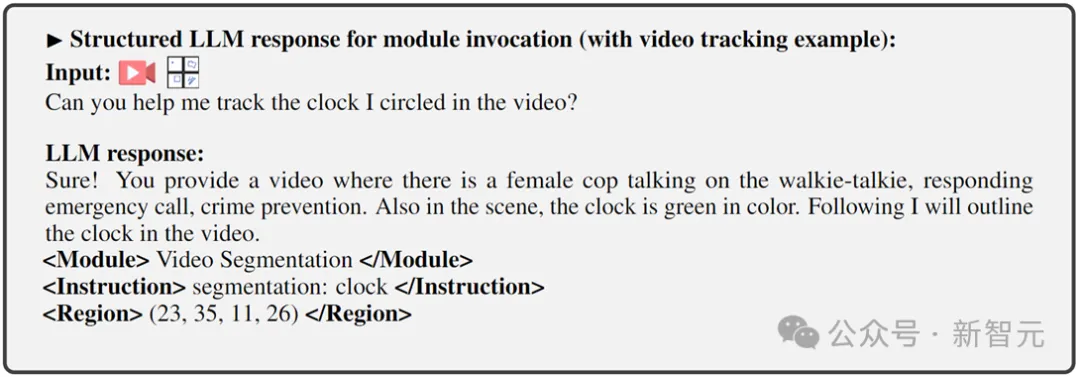
Étape 3 : Affinez la fin de sortie de l'appel de commande. La deuxième étape de la formation décrite ci-dessus donne au LLM et à l'encodeur frontal la capacité de comprendre la vision au niveau des pixels. Cette dernière étape, le réglage fin des instructions pour l'invocation de commandes, vise à doter le système de la capacité d'exécuter des commandes avec précision, permettant à LLM de générer un texte d'invocation approprié et correct. Étant donné que différentes tâches de vision du terminal peuvent nécessiter différentes commandes d'appel, afin d'unifier cela, les chercheurs ont proposé de standardiser la réponse de LLM dans un format de texte structuré, qui comprend :
1) Sortie de réponse de l'utilisateur, réponse directe au Entrée de l'utilisateur
2) Nom du module pour indiquer la fonction ou la tâche qui sera effectuée.
3) Appelez la commande pour déclencher la méta-instruction du module de tâches.
4) Région (sortie facultative) qui spécifie les fonctionnalités visuelles fines requises pour certaines tâches, comme le suivi vidéo ou l'édition visuelle, où les modules backend nécessitent ces informations. Pour les régions, sur la base de la compréhension au niveau des pixels de LLM, des cadres de délimitation décrits par des coordonnées seront générés.
Expériences d'évaluation
Les chercheurs ont mené des évaluations expérimentales approfondies sur 22 ensembles de données de référence communs et 12 tâches de vision image/vidéo basées sur Vitron. Vitron démontre de solides capacités dans quatre grands groupes de tâches visuelles (segmentation, compréhension, génération et édition de contenu), tout en disposant de capacités flexibles d’interaction homme-machine. Ce qui suit montre de manière représentative quelques résultats de comparaison qualitative :
Segmentation de la vision
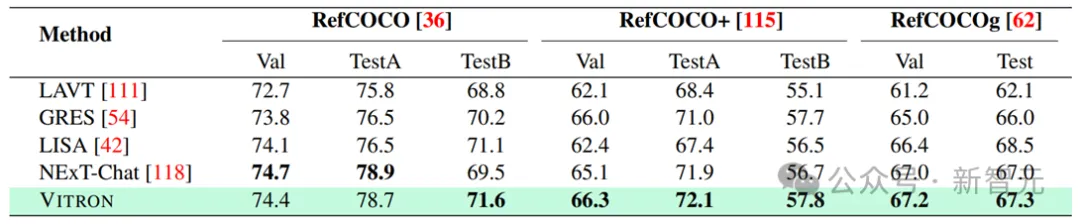
Résultats de la segmentation d'image faisant référence à une image
Compréhension fine de la vision

Résultats de compréhension de l'expression de référence d'image.
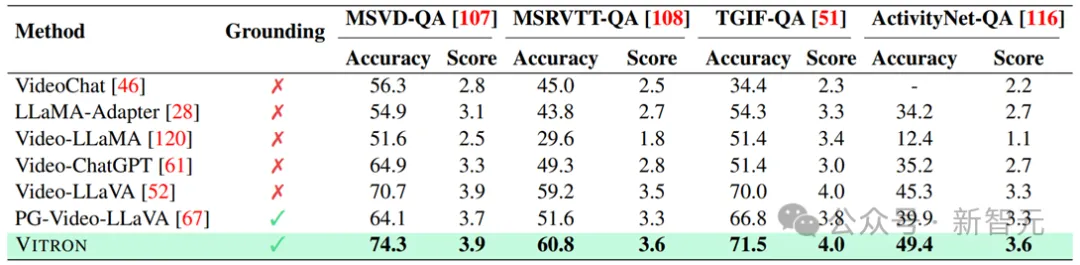
S'il vous plaît reportez-vous à l’article pour un contenu expérimental et des détails plus détaillés.
Future Direction Outlook
En général, ce travail démontre le grand potentiel du développement d'un grand modèle général visuel multimodal unifié, établissant une nouvelle forme pour la prochaine génération de recherche sur les grands modèles visuels et faisant le premier pas dans cette direction. Bien que le système Vitron proposé par l’équipe présente de fortes capacités générales, il présente néanmoins ses propres limites. Les chercheurs suivants énumèrent quelques directions qui pourraient être explorées davantage à l’avenir.
Architecture système
Le système Vitron utilise toujours une approche semi-union, semi-agent pour appeler des outils externes. Bien que cette méthode basée sur les appels facilite l'expansion et le remplacement de modules potentiels, cela signifie également que les modules back-end de cette structure de pipeline ne participent pas à l'apprentissage conjoint des modules front-end et de base LLM.
Cette limitation n'est pas propice à l'apprentissage global du système, ce qui signifie que la limite supérieure de performance des différentes tâches visuelles sera limitée par le module back-end. Les travaux futurs devraient intégrer divers modules de tâches de vision dans une unité unifiée. Parvenir à une compréhension et une production unifiées d’images et de vidéos tout en prenant en charge les capacités de génération et d’édition via un paradigme génératif unique reste un défi. Actuellement, une approche prometteuse consiste à combiner la tokenisation persistante en termes de modularité pour améliorer l'unification du système sur différentes entrées et sorties et diverses tâches.
Interactivité utilisateur
Contrairement aux modèles précédents qui se concentraient sur une tâche à vision unique (par exemple, Stable Diffusion et SEEM), Vitron vise à faciliter une interaction profonde entre LLM et les utilisateurs, similaire à l'industrie au sein du DALL d'OpenAI. -Série E, Midjourney, etc. Atteindre une interactivité utilisateur optimale est l’un des objectifs principaux de ce travail.
Vitron exploite le LLM basé sur la langue existante, combiné à des ajustements pédagogiques appropriés pour atteindre un certain niveau d'interactivité. Par exemple, le système peut répondre de manière flexible à tout message attendu saisi par l'utilisateur et produire des résultats d'opération visuels correspondants sans exiger que l'entrée de l'utilisateur corresponde exactement aux conditions du module principal. Cependant, ces travaux laissent encore beaucoup de marge d’amélioration en termes de renforcement de l’interactivité. Par exemple, en s'inspirant du système Midjourney à source fermée, quelle que soit la décision prise par LLM à chaque étape, le système doit fournir activement des commentaires aux utilisateurs pour garantir que ses actions et décisions sont cohérentes avec les intentions des utilisateurs.
Capacités modales
Actuellement, Vitron intègre un modèle 7B Vicuna, qui peut avoir certaines limitations sur sa capacité à comprendre le langage, les images et les vidéos. Les orientations futures de l'exploration pourraient consister à développer un système complet de bout en bout, par exemple en élargissant l'échelle du modèle pour parvenir à une compréhension plus approfondie et plus complète de la vision. En outre, des efforts devraient être faits pour permettre au LLM d’unifier pleinement la compréhension des modalités de l’image et de la vidéo.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
La bibliothèque utilisée pour le fonctionnement du numéro de point flottante dans le langage go présente comment s'assurer que la précision est ...
 Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou des projets open source bien connus? Lors de la programmation en Go, les développeurs rencontrent souvent des besoins communs, ...
 Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
GiteEpages STATIQUE Le déploiement du site Web a échoué: 404 Dépannage des erreurs et résolution lors de l'utilisation de Gitee ...
 Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
L'exécution du projet H5 nécessite les étapes suivantes: Installation des outils nécessaires tels que le serveur Web, Node.js, les outils de développement, etc. Créez un environnement de développement, créez des dossiers de projet, initialisez les projets et écrivez du code. Démarrez le serveur de développement et exécutez la commande à l'aide de la ligne de commande. Aperçu du projet dans votre navigateur et entrez l'URL du serveur de développement. Publier des projets, optimiser le code, déployer des projets et configurer la configuration du serveur Web.
 Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Dans le cadre du cadre de beegoorm, comment spécifier la base de données associée au modèle? De nombreux projets Beego nécessitent que plusieurs bases de données soient opérées simultanément. Lorsque vous utilisez Beego ...
 Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Le problème de l'utilisation de Redessstream pour implémenter les files d'attente de messages dans le langage GO consiste à utiliser le langage GO et redis ...
 La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La page H5 doit être maintenue en continu, en raison de facteurs tels que les vulnérabilités du code, la compatibilité des navigateurs, l'optimisation des performances, les mises à jour de sécurité et les améliorations de l'expérience utilisateur. Des méthodes de maintenance efficaces comprennent l'établissement d'un système de test complet, à l'aide d'outils de contrôle de version, de surveiller régulièrement les performances de la page, de collecter les commentaires des utilisateurs et de formuler des plans de maintenance.
 Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Description de la question: Comment obtenir les données de la région d'expédition de la version à l'étranger? Y a-t-il des ressources prêtes à l'emploi disponibles? Soyez précis dans le commerce électronique transfrontalier ou les entreprises mondialisées ...
