
 Périphériques technologiques
IA
Les performances de quantification low-bit de Llama 3 diminuent considérablement ! Les résultats complets de l'évaluation sont ici |
Périphériques technologiques
IA
Les performances de quantification low-bit de Llama 3 diminuent considérablement ! Les résultats complets de l'évaluation sont ici |
Les performances de quantification low-bit de Llama 3 diminuent considérablement ! Les résultats complets de l'évaluation sont ici |

La puissance des grands modèles permet à LLaMA3 d'atteindre de nouveaux sommets :
Sur les données du jeton 15T+ qui ont été pré-entraînées à grande échelle, des améliorations de performances impressionnantes ont été obtenues, et elles ont encore une fois explosé car elles dépassent de loin les recommandations. volume de discussion de la communauté Chinchilla Open source.
Dans le même temps, au niveau de l'application pratique, un autre sujet brûlant a également fait surface :
Quelle sera la performance quantitative de LLaMA3 dans des scénarios aux ressources limitées ?
L'Université de Hong Kong, l'Université Beihang et l'École polytechnique fédérale de Zurich ont lancé conjointement une étude empirique qui a pleinement révélé les capacités de quantification à bits faibles de LLaMA3.

Les chercheurs ont évalué les résultats de LLaMA3 avec 1 à 8 bits et divers ensembles de données d'évaluation en utilisant 10 méthodes de réglage fin quantifiées LoRA post-formation existantes. Ils ont découvert :
Malgré ses performances impressionnantes, LLaMA3 souffre toujours d'une dégradation non négligeable à faible quantification de bits, en particulier à des largeurs de bits ultra-faibles.

Le projet a été open source sur GitHub, et le modèle quantitatif a également été lancé sur HuggingFace.
Regardons spécifiquement les résultats empiriques.
Piste 1 : Quantification post-entraînement
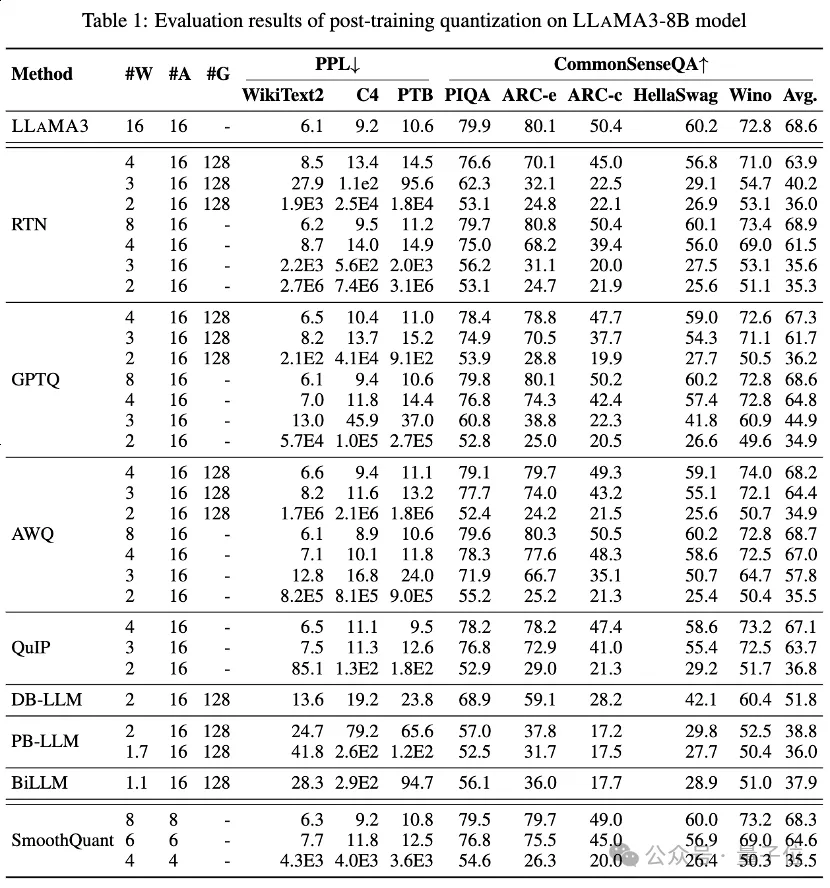
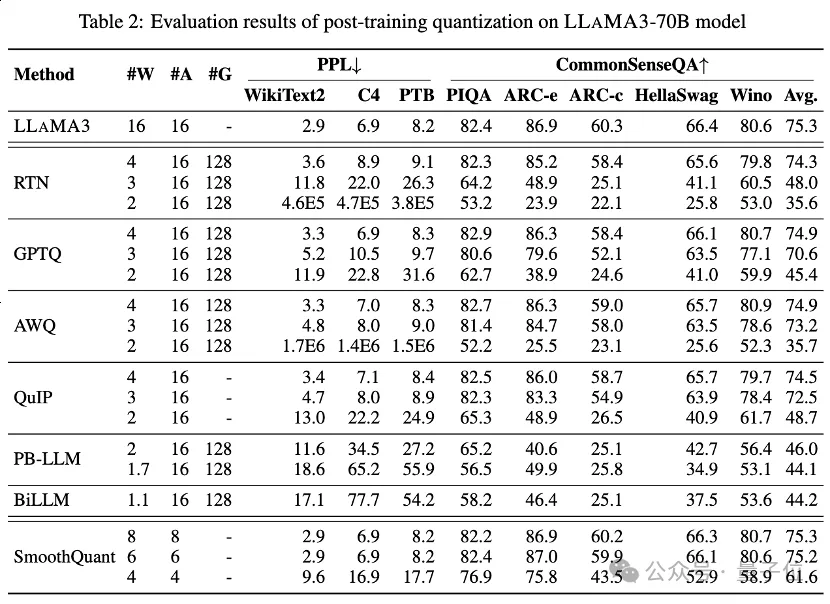
Le Tableau 1 et le Tableau 2 fournissent les performances en bits faibles de LLaMA3-8B et LLaMA3-70B sous 8 méthodes PTQ différentes, couvrant une large plage de 1 bit à 8 bits de largeur de bit.
1. Poids de privilège faible en bits
Parmi eux, Round-To-Nearest (RTN) est une méthode de quantification d'arrondi de base.
GPTQ est l'une des méthodes de quantification par poids uniquement les plus efficaces et les plus efficaces actuellement disponibles, qui exploite la compensation des erreurs de quantification. Mais à 2-3 bits, GPTQ provoque un grave effondrement de la précision lors de la quantification de LLaMA3.
AWQ utilise une méthode de suppression de canal anormale pour réduire la difficulté de quantification des poids, tandis que QuIP garantit l'incohérence entre les poids et le Hessian en optimisant les calculs matriciels. Ils maintiennent tous les capacités de LLaMA3 à 3 bits et poussent même la quantification à 2 bits à des niveaux prometteurs.
2. Compression de poids LLM à largeur de bit ultra-faible
La méthode de quantification binaire LLM récemment apparue permet d'obtenir une compression de poids LLM à largeur de bit ultra-faible.
PB-LLM adopte une stratégie de quantification à précision mixte pour conserver la pleine précision d'une petite partie des poids importants tout en quantifiant la plupart des poids en 1 bit.
DB-LLM permet une compression LLM efficace grâce à une double division de poids de binarisation et propose une stratégie de distillation tenant compte des biais pour améliorer encore les performances LLM 2 bits.
BiLLM repousse encore la limite de quantification LLM jusqu'à 1,1 bits grâce à une approximation résiduelle des poids significatifs et une quantification groupée des poids non significatifs. Ces méthodes de quantification LLM spécialement conçues pour une largeur de bit ultra-faible peuvent atteindre une quantification de plus grande précision LLaMA3-8B, à ⩽2 bits dépassant de loin les méthodes telles que GPTQ, AWQ et QuIP à 2 bits (et même dans certains cas 3 bits).
3. Les activations quantifiées à faible bit
ont également effectué une évaluation LLaMA3 sur les activations quantifiées via SmoothQuant, qui transfère la difficulté de quantification des activations aux poids pour lisser les valeurs aberrantes d'activation. L'évaluation montre que SmoothQuant peut préserver la précision de LLaMA3 avec des poids et des activations de 8 bits et 6 bits, mais risque de s'effondrer à 4 bits.
Piste 2 : quantification fine de LoRA
Sur le jeu de données MMLU, pour LLaMA3-8B sous quantification LoRA-FT, l'observation la plus frappante est que le réglage fin de bas rang sur le jeu de données Alpaca non seulement ne parvient pas à compenser la quantification. Les bugs introduits aggravent encore la dégradation des performances.
Plus précisément, les performances quantifiées du LLaMA3 obtenues par diverses méthodes de quantification LoRA-FT à 4 bits sont pires que les versions correspondantes à 4 bits sans LoRA-FT. Cela contraste fortement avec des phénomènes similaires sur LLaMA1 et LLaMA2, où la version de quantification affinée de bas rang 4 bits surpasse même facilement l'homologue original du FP16 sur MMLU.
Selon une analyse intuitive, la principale raison de ce phénomène est que les performances puissantes de LLaMA3 bénéficient de son pré-entraînement à grande échelle, ce qui signifie que la perte de performances après quantification du modèle original ne peut pas être effectuée sur un petit ensemble de données de paramètres de bas rang Réglage fin pour compenser (cela peut être considéré comme un sous-ensemble du modèle d'origine).
Bien que la dégradation significative causée par la quantification ne puisse pas être compensée par un réglage fin, le LLaMA3-8B quantifié LoRA-FT 4 bits surpasse considérablement le LLaMA1-7B et le LLaMA2-7B selon diverses méthodes de quantification. Par exemple, en utilisant la méthode QLoRA, la précision moyenne du LLaMA3-8B 4 bits est de 57,0 (FP16 : 64,8), ce qui dépasse de 18,6 le 38,4 du LLaMA1-7B 4 bits (FP16 : 34,6) et dépasse le 43,9 de LLaMA2-7B 4 bits (FP16 : 45,5) 13.1. Cela démontre la nécessité d’un nouveau paradigme de quantification LoRA-FT à l’ère LLaMA3.
Un phénomène similaire s'est produit dans le benchmark CommonSenseQA. Les performances du modèle affiné avec QLoRA et IR-QLoRA ont également diminué par rapport à leur homologue 4 bits sans LoRA-FT (par exemple, diminution moyenne de 2,8 % pour QLoRA contre une diminution moyenne de 2,4 % pour IR-QLoRA). Cela démontre en outre l'avantage d'utiliser des ensembles de données de haute qualité dans LLaMA3 et que l'ensemble de données générique Alpaca ne contribue pas aux performances du modèle dans d'autres tâches.
Conclusion
Cet article évalue de manière exhaustive les performances de LLaMA3 dans diverses techniques de quantification à bits faibles, y compris la quantification post-entraînement et la quantification affinée LoRA.
Ce résultat de recherche montre que bien que LLaMA3 présente toujours des performances supérieures après quantification, la baisse de performances associée à la quantification est significative et peut même conduire à une baisse plus importante dans de nombreux cas.
Cette découverte met en évidence les défis potentiels qui peuvent être rencontrés lors du déploiement de LLaMA3 dans des environnements aux ressources limitées et met en évidence une grande marge de croissance et d'amélioration dans le contexte de la quantification à faible débit. En résolvant la dégradation des performances causée par la quantification à bits faibles, on s'attend à ce que les paradigmes de quantification ultérieurs permettent aux LLM d'atteindre des capacités plus fortes à des coûts de calcul inférieurs, conduisant finalement l'intelligence artificielle générative représentative vers de nouveaux sommets.
Lien papier : https://arxiv.org/abs/2404.14047.
Lien du projet : https://github.com/Macaronlin/LLaMA3-Quantizationhttps://huggingface.co/LLMQ.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
La bibliothèque utilisée pour le fonctionnement du numéro de point flottante dans le langage go présente comment s'assurer que la précision est ...
 Dépassant considérablement la SFT, le secret derrière O1 / Deepseek-R1 peut également être utilisé dans les grands modèles multimodaux
Mar 12, 2025 pm 01:03 PM
Dépassant considérablement la SFT, le secret derrière O1 / Deepseek-R1 peut également être utilisé dans les grands modèles multimodaux
Mar 12, 2025 pm 01:03 PM
Des chercheurs de l'Université de Shanghai Jiaotong, de Shanghai Ailab et de l'Université chinoise de Hong Kong ont lancé le projet open source Visual-RFT (visual d'amélioration), qui ne nécessite qu'une petite quantité de données pour améliorer considérablement les performances du gros modèle de langage visuel (LVLM). Visual-RFT combine intelligemment l'approche d'apprentissage en renforcement basée sur les règles de Deepseek-R1 avec le paradigme de relâchement de renforcement d'OpenAI (RFT), prolongeant avec succès cette approche du champ de texte au champ visuel. En concevant les récompenses de règles correspondantes pour des tâches telles que la sous-catégorisation visuelle et la détection d'objets, Visual-RFT surmonte les limites de la méthode Deepseek-R1 limitée au texte, au raisonnement mathématique et à d'autres domaines, fournissant une nouvelle façon de formation LVLM. Vis
 Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
GiteEpages STATIQUE Le déploiement du site Web a échoué: 404 Dépannage des erreurs et résolution lors de l'utilisation de Gitee ...
 Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou des projets open source bien connus? Lors de la programmation en Go, les développeurs rencontrent souvent des besoins communs, ...
 Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Description de la question: Comment obtenir les données de la région d'expédition de la version à l'étranger? Y a-t-il des ressources prêtes à l'emploi disponibles? Soyez précis dans le commerce électronique transfrontalier ou les entreprises mondialisées ...
 CONTRIBLÉE DE MADIFICATION DE LA ROUTE TYPECHO: Pourquoi mon / Test / Tag / son / 10086 correspondant à TestTagIndex au lieu de TestTagPage?
Apr 01, 2025 am 09:03 AM
CONTRIBLÉE DE MADIFICATION DE LA ROUTE TYPECHO: Pourquoi mon / Test / Tag / son / 10086 correspondant à TestTagIndex au lieu de TestTagPage?
Apr 01, 2025 am 09:03 AM
Analyse des règles de correspondance de routage Typecho et enquête sur les problèmes Cet article analysera et répondra aux questions sur les résultats incohérents de l'enregistrement du routage du plug-in Typecho et des résultats de correspondance réels ...
 Dessin graphique de sablier Python: comment éviter les erreurs variables non définies?
Apr 01, 2025 pm 06:27 PM
Dessin graphique de sablier Python: comment éviter les erreurs variables non définies?
Apr 01, 2025 pm 06:27 PM
Précision avec Python: Source de sablier Dessin graphique et vérification d'entrée Cet article résoudra le problème de définition variable rencontré par un novice Python dans le programme de dessin graphique de sablier. Code...
 Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
L'exécution du projet H5 nécessite les étapes suivantes: Installation des outils nécessaires tels que le serveur Web, Node.js, les outils de développement, etc. Créez un environnement de développement, créez des dossiers de projet, initialisez les projets et écrivez du code. Démarrez le serveur de développement et exécutez la commande à l'aide de la ligne de commande. Aperçu du projet dans votre navigateur et entrez l'URL du serveur de développement. Publier des projets, optimiser le code, déployer des projets et configurer la configuration du serveur Web.
