
 Périphériques technologiques
IA
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Périphériques technologiques
IA
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |

FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 !
Lao Huang voulait que tout le monde utilise INT8/INT4. L'équipe Microsoft DeepSpeed a commencé à exécuter de force FP6 sur A100 sans le support officiel de NVIDIA.
Les résultats des tests montrent que la vitesse de quantification FP6 de la nouvelle méthode TC-FPx sur l'A100 est proche ou même parfois dépasse INT4, et qu'elle a une précision plus élevée que cette dernière. Sur cette base, il existe également un
support de bout en bout de grands modèles, qui a été open source et intégré dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles.
Après l'avoir lu, un chercheur en apprentissage automatique a déclaré que les recherches de Microsoft pouvaient être qualifiées de folles.
 les packs d'émoticônes sont également en ligne immédiatement, soyez comme :
les packs d'émoticônes sont également en ligne immédiatement, soyez comme :
Microsoft : Très bien, je le ferai moi-même.
 Alors, quels types d'effets ce cadre peut-il produire et quel type de technologie est utilisé derrière ?
Alors, quels types d'effets ce cadre peut-il produire et quel type de technologie est utilisé derrière ?
En utilisant FP6 pour exécuter Llama, une seule carte est plus rapide que deux cartes
L'utilisation de la précision FP6 sur A100 apporte
amélioration des performances au niveau du noyau. Les chercheurs ont sélectionné des couches linéaires dans des modèles Llama et des modèles OPT de différentes tailles et les ont testés à l'aide de CUDA 11.8 sur la plate-forme GPU NVIDIA A100-40GB.
Les résultats se comparent à ceux officiels de NVIDIA cuBLAS
(W16A16)et TensorRT-LLM(W8A16), TC-FPx(W6A16)speedL'amélioration de la vitesse maximale est respectivement de 2,6 fois et 1,9 fois. Par rapport à la méthode 4 bits BitsandBytes
(W4A16), l'amélioration de la vitesse maximale de TC-FPx est de 8,9 fois.
(W et A représentent respectivement la largeur de bit de quantification de poids et la largeur de bit de quantification d'activation)
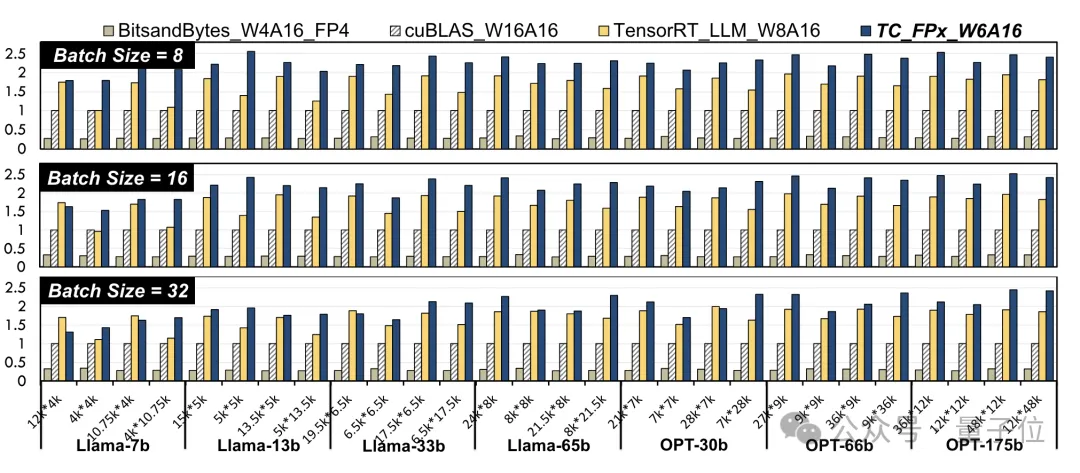 △Données normalisées, le résultat cuBLAS étant 1
△Données normalisées, le résultat cuBLAS étant 1
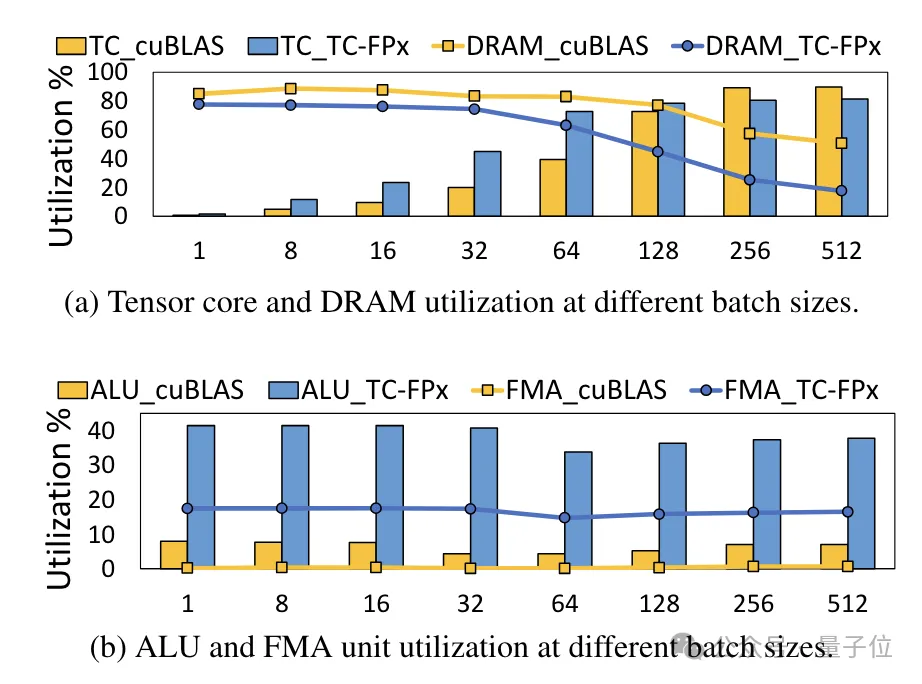
En même temps, le noyau TC-FPx réduit également le besoin d'accès à la mémoire DRAM et améliore l'utilisation de la bande passante DRAM et l'utilisation des cœurs Tensor, ainsi que l'utilisation des unités ALU et FMA.
 Le
Le
cadre d'inférence de bout en bout FP6-LLM conçu sur la base de TC-FPx apporte également des améliorations significatives des performances aux grands modèles. En prenant Llama-70B comme exemple, le débit d'exécution de FP6-LLM sur une seule carte est 2,65 fois supérieur à celui du FP16 sur des cartes doubles, et la latence dans les tailles de lots inférieures à 16 est également inférieure à celle du FP16.
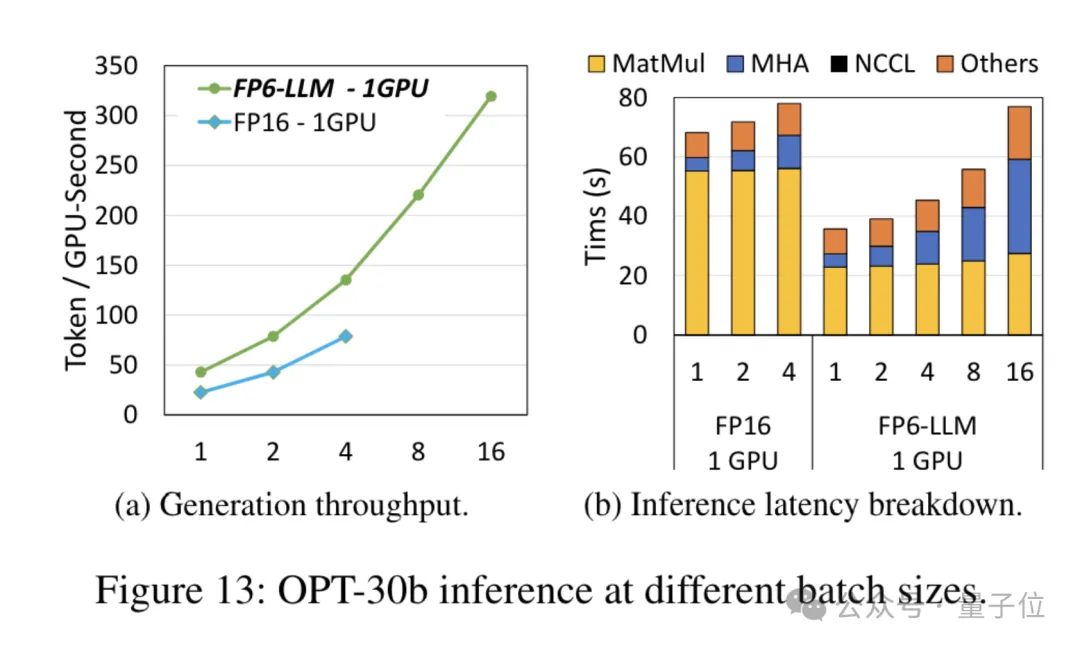
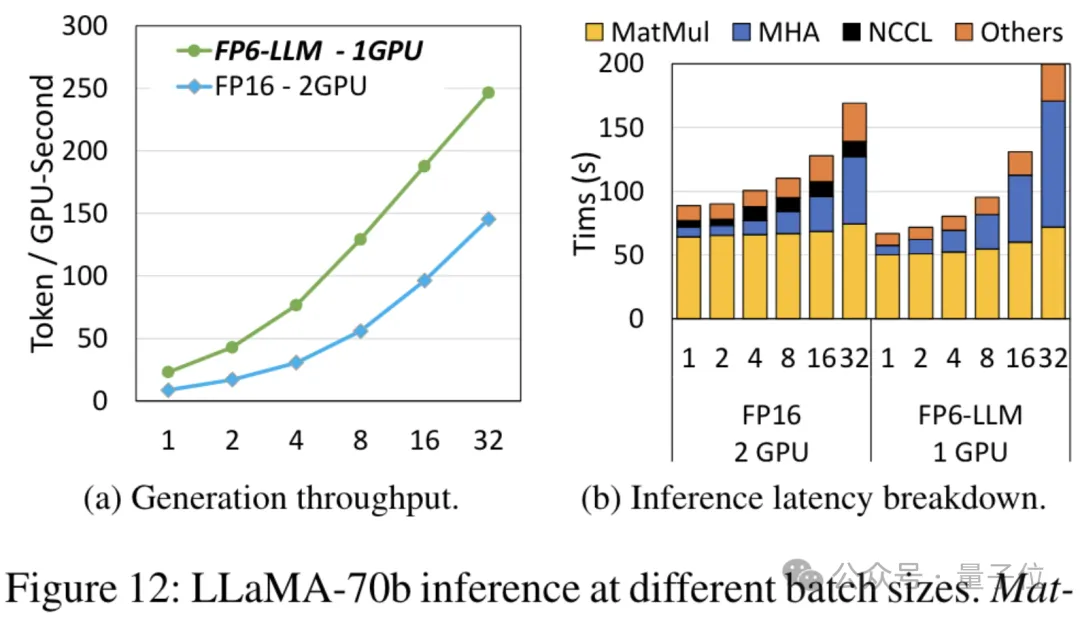 Pour le modèle OPT-30B avec un plus petit nombre de paramètres (FP16 utilise également une seule carte), FP6-LLM apporte également une amélioration significative du débit et une réduction de la latence.
Pour le modèle OPT-30B avec un plus petit nombre de paramètres (FP16 utilise également une seule carte), FP6-LLM apporte également une amélioration significative du débit et une réduction de la latence.
Et la taille de lot maximale prise en charge par une seule carte FP16 dans cette condition n'est que de 4, mais FP6-LLM peut fonctionner normalement avec une taille de lot de 16.
 Alors, comment l'équipe Microsoft a-t-elle réalisé la quantification FP16 sur A100 ?
Alors, comment l'équipe Microsoft a-t-elle réalisé la quantification FP16 sur A100 ?
Solution de noyau repensée
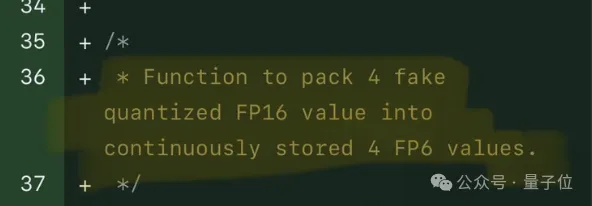
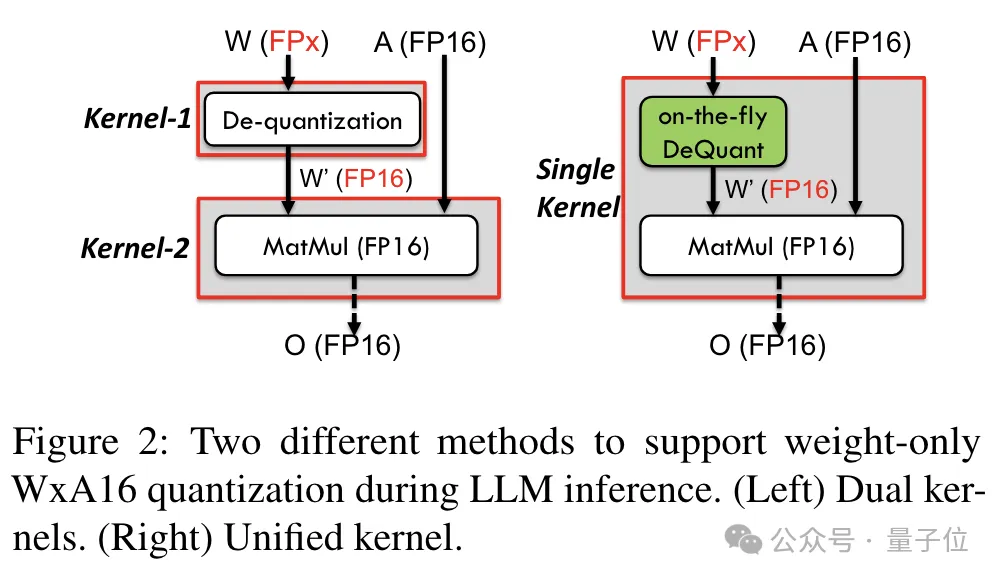
Afin de prendre en charge la précision, y compris 6 bits, l'équipe TC-FPx a conçu une solution de noyau unifiée qui peut prendre en charge des poids de quantification de différentes largeurs de bits.
Par rapport à la méthode traditionnelle dual-core, TC-FPx réduit le nombre d'accès à la mémoire et améliore les performances en intégrant la déquantification et la multiplication matricielle dans un seul cœur.
Le secret principal pour obtenir une quantification de faible précision est de « déguiser » les données de précision FP6 en FP16 grâce à la déquantification, puis de les transmettre au GPU pour le calcul au format FP16.
Dans le même temps, l'équipe a également utilisé la technologie de pré-emballage au niveau des bits pour résoudre le problème selon lequel le système de mémoire GPU n'est pas compatible avec des largeurs de bits non puissantes de 2 (telles que 6 -peu).
Plus précisément, le pré-packing au niveau des bits est la réorganisation des données de poids avant l'inférence du modèle, y compris la réorganisation des poids quantifiés sur 6 bits afin qu'ils puissent être consultés de manière conviviale pour le système de mémoire GPU.
De plus, étant donné que les systèmes de mémoire GPU accèdent généralement aux données par blocs de 32 ou 64 bits, la technologie de pré-emballage au niveau des bits emballera également des poids de 6 bits afin qu'ils puissent être stockés et accessibles sous la forme de ceux-ci alignés. blocs.

Une fois le pré-conditionnement terminé, l'équipe de recherche utilise les capacités de traitement parallèle du noyau SIMT pour effectuer une déquantification parallèle sur les poids FP6 dans le registre afin de générer des poids au format FP16.
Les poids FP16 déquantifiés sont reconstruits dans le registre puis envoyés au Tensor Core. Les poids FP16 reconstruits sont utilisés pour effectuer des opérations de multiplication matricielle pour compléter le calcul de la couche linéaire.
Dans ce processus, l'équipe a profité du parallélisme au niveau des bits du noyau SMIT pour améliorer l'efficacité de l'ensemble du processus de déquantification.
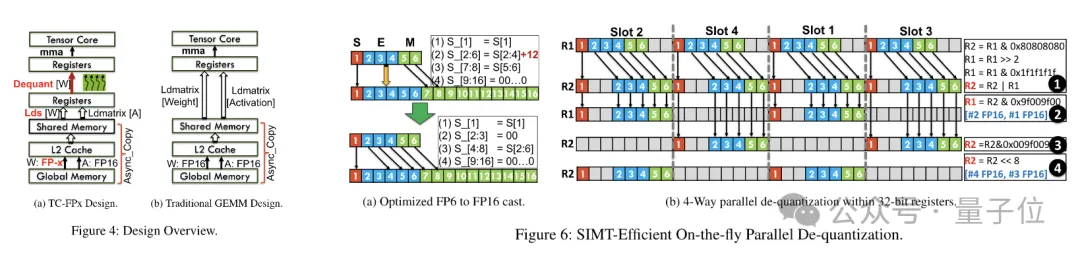
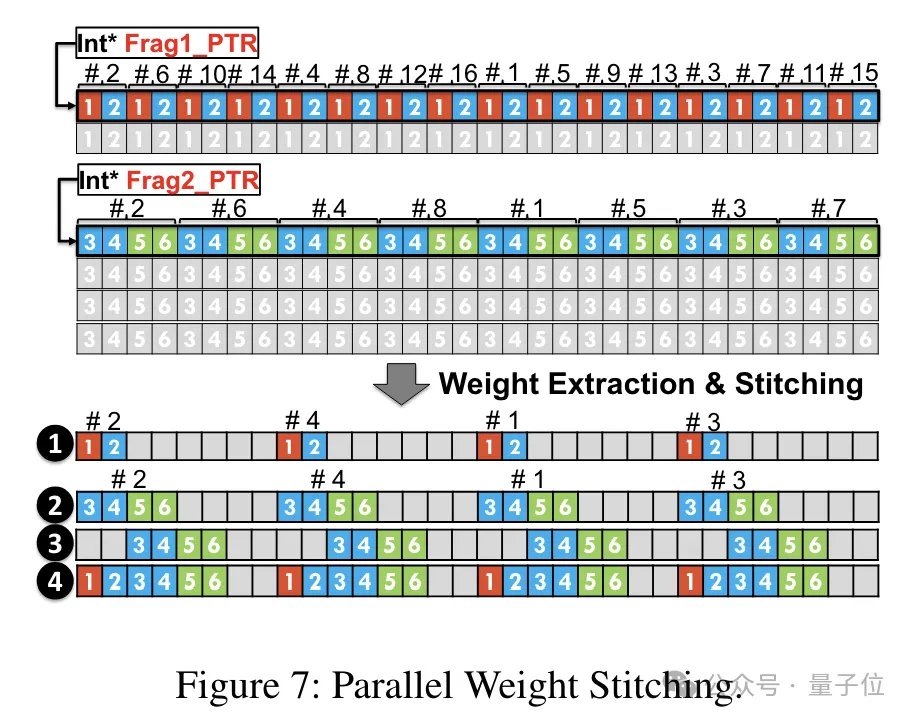
Afin de permettre à la tâche de reconstruction du poids de se dérouler en parallèle, l'équipe a également utilisé une technologie de épissage parallèle des poids.
Plus précisément, chaque poids est divisé en plusieurs parties, et la largeur de bit de chaque partie est une puissance de 2 (comme diviser 6 en 2+4 ou 4+2).
Avant la déquantification, les poids sont d'abord chargés dans des registres à partir de la mémoire partagée. Étant donné que chaque poids est divisé en plusieurs parties, le poids complet doit être reconstruit au niveau du registre au moment de l'exécution.
Afin de réduire les frais d'exécution, TC-FPx propose une méthode d'extraction et d'épissage parallèles des poids. Cette approche utilise deux ensembles de registres pour stocker des segments de 32 poids FP6, en reconstruisant ces poids en parallèle.
Dans le même temps, afin d'extraire et de fusionner les poids en parallèle, il est nécessaire de s'assurer que la disposition initiale des données répond aux exigences de commande spécifiques, de sorte que TC-FPx réorganise les fragments de poids avant de s'exécuter.
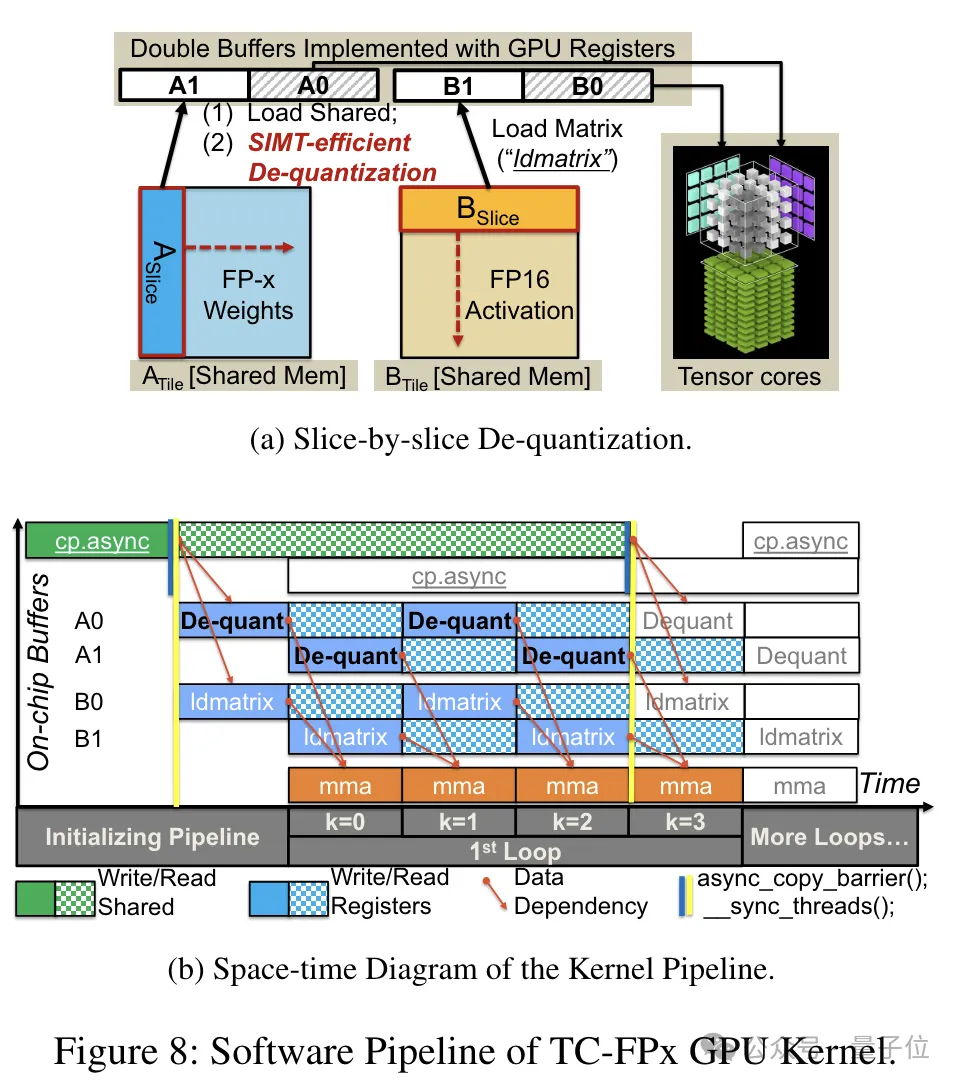
De plus, TC-FPx a également conçu un pipeline logiciel, qui intègre l'étape de déquantification à l'opération de multiplication matricielle de Tensor Core, améliorant l'efficacité globale de l'exécution grâce au parallélisme au niveau des instructions.
Adresse papier : https://arxiv.org/abs/2401.14112
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Dois-je utiliser Flexbox au centre de l'image bootstrap?
Apr 07, 2025 am 09:06 AM
Dois-je utiliser Flexbox au centre de l'image bootstrap?
Apr 07, 2025 am 09:06 AM
Il existe de nombreuses façons de centrer des photos de bootstrap, et vous n'avez pas à utiliser Flexbox. Si vous avez seulement besoin de centrer horizontalement, la classe de cent texte est suffisante; Si vous devez centrer verticalement ou plusieurs éléments, Flexbox ou Grid convient plus. Flexbox est moins compatible et peut augmenter la complexité, tandis que Grid est plus puissant et a un coût d'enseignement supérieur. Lorsque vous choisissez une méthode, vous devez peser les avantages et les inconvénients et choisir la méthode la plus appropriée en fonction de vos besoins et préférences.
 Comment calculer C-SUBScript 3 Indice 5 C-SUBScript 3 Indice Indice 5 Tutoriel d'algorithme
Apr 03, 2025 pm 10:33 PM
Comment calculer C-SUBScript 3 Indice 5 C-SUBScript 3 Indice Indice 5 Tutoriel d'algorithme
Apr 03, 2025 pm 10:33 PM
Le calcul de C35 est essentiellement des mathématiques combinatoires, représentant le nombre de combinaisons sélectionnées parmi 3 des 5 éléments. La formule de calcul est C53 = 5! / (3! * 2!), Qui peut être directement calculé par des boucles pour améliorer l'efficacité et éviter le débordement. De plus, la compréhension de la nature des combinaisons et la maîtrise des méthodes de calcul efficaces est cruciale pour résoudre de nombreux problèmes dans les domaines des statistiques de probabilité, de la cryptographie, de la conception d'algorithmes, etc.
 Top 10 des plates-formes de trading de crypto-monnaie, les dix principales applications de plate-forme de trading de devises recommandées
Mar 17, 2025 pm 06:03 PM
Top 10 des plates-formes de trading de crypto-monnaie, les dix principales applications de plate-forme de trading de devises recommandées
Mar 17, 2025 pm 06:03 PM
Les dix principales plates-formes de trading de crypto-monnaie comprennent: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. BitFinex, 10. Gemini. La sécurité, la liquidité, les frais de traitement, la sélection des devises, l'interface utilisateur et le support client doivent être pris en compte lors du choix d'une plate-forme.
 Top 10 des plates-formes de trading de devises virtuelles 2025 Applications de trading de crypto-monnaie classée top dix
Mar 17, 2025 pm 05:54 PM
Top 10 des plates-formes de trading de devises virtuelles 2025 Applications de trading de crypto-monnaie classée top dix
Mar 17, 2025 pm 05:54 PM
Top dix plates-formes de trading de devises virtuelles 2025: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. BitFinex, 10. Gemini. La sécurité, la liquidité, les frais de traitement, la sélection des devises, l'interface utilisateur et le support client doivent être pris en compte lors du choix d'une plate-forme.
 Quelles sont les plates-formes de monnaie numérique sûres et fiables?
Mar 17, 2025 pm 05:42 PM
Quelles sont les plates-formes de monnaie numérique sûres et fiables?
Mar 17, 2025 pm 05:42 PM
Une plate-forme de monnaie numérique sûre et fiable: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. La sécurité, la liquidité, les frais de traitement, la sélection des devises, l'interface utilisateur et le support client doivent être pris en compte lors du choix d'une plate-forme.
 Fonction de fonction distincte Distance de distance C Tutoriel d'utilisation
Apr 03, 2025 pm 10:27 PM
Fonction de fonction distincte Distance de distance C Tutoriel d'utilisation
Apr 03, 2025 pm 10:27 PM
STD :: Unique supprime les éléments en double adjacents dans le conteneur et les déplace jusqu'à la fin, renvoyant un itérateur pointant vers le premier élément en double. STD :: Distance calcule la distance entre deux itérateurs, c'est-à-dire le nombre d'éléments auxquels ils pointent. Ces deux fonctions sont utiles pour optimiser le code et améliorer l'efficacité, mais il y a aussi quelques pièges à prêter attention, tels que: std :: unique traite uniquement des éléments en double adjacents. STD :: La distance est moins efficace lorsqu'il s'agit de transacteurs d'accès non aléatoires. En maîtrisant ces fonctionnalités et les meilleures pratiques, vous pouvez utiliser pleinement la puissance de ces deux fonctions.
 Comment implémenter la disposition adaptative de la position de l'axe y dans l'annotation Web?
Apr 04, 2025 pm 11:30 PM
Comment implémenter la disposition adaptative de la position de l'axe y dans l'annotation Web?
Apr 04, 2025 pm 11:30 PM
L'algorithme adaptatif de la position de l'axe y pour la fonction d'annotation Web Cet article explorera comment implémenter des fonctions d'annotation similaires aux documents de mots, en particulier comment gérer l'intervalle entre les annotations ...
 Applications de logiciels de monnaie virtuels sûrs recommandés Top 10 des applications de trading de devises numériques classement 2025
Mar 17, 2025 pm 05:48 PM
Applications de logiciels de monnaie virtuels sûrs recommandés Top 10 des applications de trading de devises numériques classement 2025
Mar 17, 2025 pm 05:48 PM
Recommandés Applications logicielles de monnaie virtuelle recommandées: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. La sécurité, la liquidité, les frais de traitement, la sélection des devises, l'interface utilisateur et le support client doivent être pris en compte lors du choix d'une plate-forme.
