
 Périphériques technologiques
IA
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Périphériques technologiques
IA
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.

Je pleure à mort, le monde entier est fou de faire de gros modèles, les données sur Internet ne suffisent pas, pas assez du tout.
Le modèle de formation est comme « The Hunger Games », et les chercheurs en IA du monde entier s'inquiètent de la manière de nourrir ces mangeurs de big data.
Particulièrement dans les tâches multimodales, ce problème est particulièrement important. Alors que
était perdue, l'équipe de start-up du département de l'Université Renmin a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « les données générées par le modèle s'alimentent elles-mêmes » une réalité.
De plus, il s'agit d'une approche à deux volets du côté compréhension et du côté génération. Les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même.
Quel est le modèle ?
Le grand modèle multimodal Awaker 1.0 vient d'apparaître sur le Forum Zhongguancun.
Qui est l'équipe ?
Moteur Sophon. Fondée par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l'Université Renmin de Chine, avec le professeur Lu Zhiwu de la Hillhouse School of Artificial Intelligence en tant que consultant. Lorsque l'entreprise a été fondée en 2021, elle est entrée très tôt dans la voie du « no man's land » de la multimodalité.
L'architecture MOE résout le problème de conflit de la formation multimodale et multitâche
Ce n'est pas la première fois que Sophon Engine publie un modèle.
Le 8 mars de l'année dernière, l'équipe qui a consacré deux ans de recherche et développement a publié le premier modèle multimodal auto-développé, le modèle de séquence ChatImg avec des dizaines de milliards de paramètres, et sur cette base, a lancé le premier au monde évaluation publique dialogue multimodal Appliquer ChatImg(元 multiplier xiang).
Plus tard, ChatImg a continué à itérer, et la recherche et le développement du nouveau modèle Awaker ont également avancé en parallèle. Ce dernier hérite également des capacités de base du modèle précédent.
Par rapport au modèle de séquence ChatImg de la génération précédente, Awaker 1.0 adopte l'architecture du modèle MoE.
La raison en est que nous voulons résoudre le problème des conflits graves dans la formation multimodale et multitâche.
Grâce à l'architecture du modèle MoE, il peut mieux apprendre les capacités générales multimodales et les capacités uniques requises pour chaque tâche, améliorant ainsi encore les capacités de l'ensemble de l'Awaker 1.0 sur plusieurs tâches.
Les données valent mille mots :
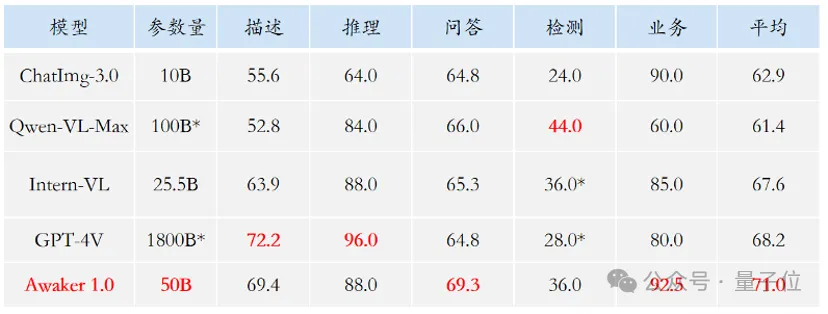
Compte tenu du problème de fuite de données d'évaluation dans les listes d'évaluation multimodales traditionnelles, l'équipe Tomoko a strictement construit son propre ensemble d'évaluation, et la plupart des images de test provenaient de données personnelles. albums de téléphones portables.
Le tableau montre que l'équipe a évalué Awaker 1.0 et les trois grands modèles multimodaux les plus avancés au pays et à l'étranger.
Encore une chose à mentionner, puisque GPT-4V et Intern-VL ne prennent pas directement en charge les tâches de détection, leurs résultats de détection sont obtenus en exigeant que le modèle utilise un langage pour décrire l'orientation de l'objet.
On peut voir que dans les tâches de réponse visuelle aux questions et d'applications métier, le modèle de base d'Awaker 1.0 dépasse GPT-4V, Qwen-VL-Max et Intern-VL.
Le modèle de base d'Awaker 1.0 a obtenu les deuxièmes meilleurs résultats dans les tâches de description, de raisonnement et de détection.
Enfin, en regardant le score moyen, Awaker 1.0 a la valeur la plus élevée parmi eux.
Par conséquent, les résultats ci-dessus confirment également l'efficacité du modèle multimodal multitâche utilisant l'architecture MoE.
Les résultats de l'évaluation de l'ensemble de données sont disponibles, mais l'effet réel doit être expérimenté davantage.
Ici, nous posons principalement quelques questions sur l'OCR chinois (reconnaissance de texte d'image) et les problèmes de comptage, les tâches de description détaillée, etc. entre celui-ci et le grand modèle de comparaison.
C'est principalement les tests comptent :
Awaker 1.0 peut donner la bonne réponse, tandis que les trois autres modèles répondent tous de manière incorrecte.
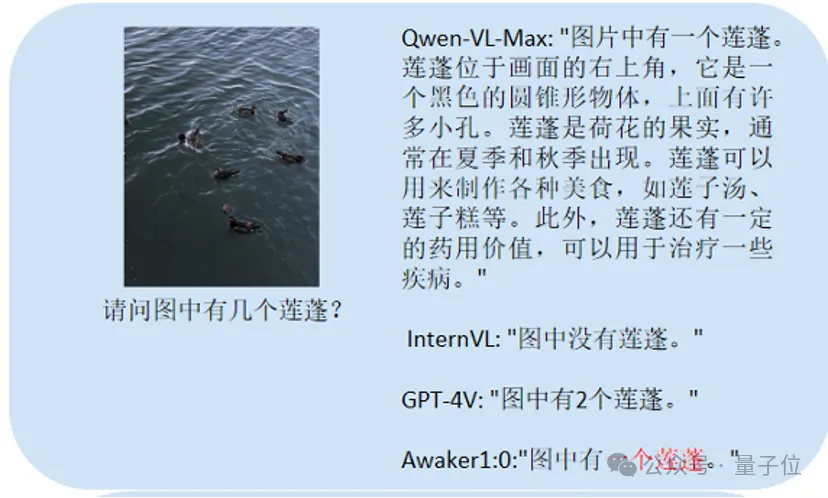
Ce test principal est Chinese OCR :
Les joueurs qui ont répondu correctement sont Qwen-VL-Max et Awaker 1.0.

La dernière question teste comprendre le contenu de l'image.
GPT-4V et Awaker 1.0 peuvent non seulement décrire le contenu de l'image en détail, mais également identifier avec précision les détails de l'image, tels que le Coca-Cola montré sur l'image.

Je dois mentionner qu'Awaker 1.0 hérite de certains des résultats de recherche dont l'équipe Sophon a déjà reçu beaucoup d'attention.
Je parle de vous - le côté généré d'Awaker 1.0.
Le côté génération d'Awaker 1.0 est la base de génération vidéo de type Sora, VDT (Video Diffusion Transformer) développée indépendamment par Sophon Engine.
L'article académique de VDT a précédé la sortie d'OpenAI Sora (en mai de l'année dernière) et a été accepté par la conférence ICLR 2024.

Les innovations uniques de VDT comprennent principalement deux points.
Tout d'abord, le Diffusion Transformer est adopté dans l'architecture technique avant OpenAI, il a montré l'énorme potentiel de Transformer dans le domaine de la génération vidéo. Son avantage réside dans ses excellentes capacités de capture dépendant du temps, capables de générer des images vidéo temporellement cohérentes, notamment en simulant la dynamique physique d'objets tridimensionnels au fil du temps.
La seconde consiste à proposer un mécanisme de modélisation de masque spatio-temporel unifié pour permettre à VDT de gérer une variété de tâches de génération vidéo. Les méthodes flexibles de traitement de l'information conditionnelle de VDT, telles que le simple épissage de l'espace de jetons, unifient efficacement les informations de différentes longueurs et modalités.
Dans le même temps, en se combinant avec le mécanisme de modélisation de masque spatio-temporel proposé dans ce travail, VDT est devenu un outil de diffusion vidéo universel, qui peut être appliqué à la génération inconditionnelle, à la prédiction d'images vidéo ultérieures, à l'insertion d'images, etc. structure du modèle.Diverses tâches de génération vidéo telles que des vidéos de création d'images et la réalisation d'écrans vidéo.
Il est entendu que l'équipe du moteur Sophon a non seulement exploré la simulation de lois physiques simples par VDT, mais a également découvert que
peut simuler des processus physiques :
 a également été réalisée sur
a également été réalisée sur
hyper- tâche de génération de vidéos de portraits réalistes Explorez en profondeur. Étant donné que l'œil nu est très sensible aux changements dynamiques des visages et des personnes, cette tâche présente des exigences très élevées en matière de qualité de génération vidéo. Cependant, le moteur Sophon a dépassé la plupart des technologies clés pour la génération de portraits vidéo hyperréalistes et n'est pas moins impressionnant que Sora.
Il n’y a aucun fondement à ce que vous dites.
C'est l'effet du moteur Sophon combinant VDT et génération contrôlable pour améliorer la qualité de la génération de vidéos de portrait :
Il est rapporté que le moteur Sophon continuera d'optimiser l'algorithme de génération contrôlable de personnages et d'explorer activement la commercialisation.
Générer un flux constant de nouvelles données interactives
Ce qui est plus remarquable, c'est que l'équipe du moteur Sophon a souligné :
Awaker 1.0 est
le premier grand modèle multimodal au monde qui peut être mis à jour indépendamment. En d'autres termes, Awaker 1.0 est "en direct" et ses paramètres peuvent être mis à jour en continu en temps réel - cela rend Awaker 1.0 différent de tous les autres grands modèles multimodaux
Le mécanisme de mise à jour autonome d'Awaker 1.0 comprend trois clés. les technologies sont :
Génération active de données- Réflexion et évaluation du modèle
- Mise à jour continue du modèle
- Ces trois technologies donnent à Awaker 1.0 la capacité d'apprendre, de réfléchir et de se mettre à jour de manière autonome, et peuvent être utilisées dans ce monde. pour explorer et même interagir avec les humains.
Sur cette base, Awaker 1.0 peut générer un flux constant de nouvelles données interactives à la fois du côté compréhension et du côté génération.
Comment faire ?
Côté compréhension, Awaker 1.0 interagit avec le monde numérique et réel. Dans le processus d'exécution des tâches, Awaker 1.0 renvoie les données de comportement de la scène au modèle pour réaliser une mise à jour et une formation continues.
Du côté de la génération, Awaker 1.0 peut effectuer une génération de contenu multimodal de haute qualité, fournissant plus de données de formation pour le modèle côté compréhension. Dans les deux boucles du côté compréhension et du côté génération, Awaker 1.0 réalise en fait l'intégration de la compréhension visuelle et de la génération visuelle.
Vous devez savoir qu'après l'avènement de Sora, de plus en plus de voix ont déclaré que pour réaliser l'AGI, une "unité de compréhension et de génération" doit être réalisée.
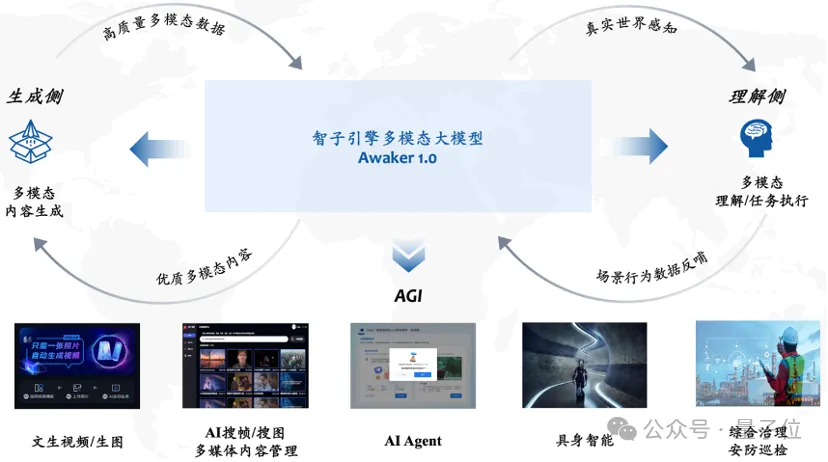 Prenant l'injection de nouvelles connaissances comme exemple, regardons un exemple spécifique de run-through.
Prenant l'injection de nouvelles connaissances comme exemple, regardons un exemple spécifique de run-through.
Awaker 1.0 peut apprendre en continu des informations d'actualité en temps réel sur Internet. En même temps, il combine les informations d'actualité nouvellement apprises pour répondre à diverses questions complexes.
Ceci est différent des deux méthodes traditionnelles actuelles, à savoir RAG et les méthodes traditionnelles à contexte long, Awaker 1.0 est vraiment
"mémoriser" de nouvelles connaissances dans les paramètres de son propre modèle.
 Vous pouvez voir que pendant les trois jours consécutifs d'auto-mise à jour, Awaker 1.0 peut apprendre chaque jour les informations d'actualité du jour et indiquer avec précision les informations correspondantes dans la description.
Vous pouvez voir que pendant les trois jours consécutifs d'auto-mise à jour, Awaker 1.0 peut apprendre chaque jour les informations d'actualité du jour et indiquer avec précision les informations correspondantes dans la description.
Et même s'il a appris, Awaker 1.0 n'a pas perdu de vue une chose ou une autre, il n'oubliera pas de sitôt les connaissances qu'il a acquises.
Par exemple, les connaissances liées au Zhijie S7 apprises le 16 avril étaient encore mémorisées ou comprises par Awaker 1.0 2 jours plus tard.
Alors, dans cette époque où les données sont comme de l’or, arrêtez de vous plaindre du « pas assez de données ».
Pour les équipes confrontées à des goulots d'étranglement en matière de données, Awaker 1.0 n'est-il pas une nouvelle option réalisable et utilisable ?
Le cerveau « vivant » de l'intelligence incarnée
En d'autres termes, c'est précisément à cause de l'intégration de la compréhension visuelle et de la génération visuelle que face au problème de « l'adaptation des grands modèles multimodaux à l'intelligence incarnée », la fierté de Awaker 1.0 Cela a été clairement révélé.
Le problème est le suivant :
Awaker 1.0, un grand modèle multimodal, possède des capacités de compréhension visuelle qui peuvent être naturellement combinées avec les « yeux » de l'intelligence incarnée.
Et les voix dominantes pensent également que « les grands modèles multimodaux + l'intelligence incarnée » peuvent grandement améliorer l'adaptabilité et la créativité de l'intelligence incarnée, et peuvent même constituer une voie réalisable pour réaliser l'AGI.
Les raisons ne sont que deux points.
Premièrement, Les gens s'attendent à ce que l'intelligence incarnée soit adaptable, c'est-à-dire que l'agent peut s'adapter à l'évolution des environnements d'application grâce à l'apprentissage continu.
De cette manière, l'intelligence incarnée peut non seulement faire de mieux en mieux sur des tâches multimodales connues, mais aussi s'adapter rapidement à des tâches multimodales inconnues.
Deuxièmement, Les gens s'attendent également à ce que l'intelligence incarnée soit véritablement créative, en espérant qu'elle puisse découvrir de nouvelles stratégies et solutions et explorer les limites des capacités de l'IA grâce à l'exploration autonome de l'environnement.
Mais l’adaptation des deux n’est pas aussi simple que de simplement relier un grand modèle multimodal au corps, ou d’installer directement un cerveau dans l’intelligence incarnée.
En prenant comme exemple les grands modèles multimodaux, nous sommes confrontés à au moins deux problèmes évidents.
Premièrement, le cycle de mise à jour itérative du modèle est long, ce qui nécessite beaucoup d'investissement en main-d'œuvre
Deuxièmement, les données d'entraînement du modèle sont toutes dérivées de données existantes, et le modèle ne peut pas être continu ; acquérir une grande quantité de nouvelles connaissances. Bien qu'il soit également possible d'injecter de nouvelles connaissances émergentes en permanence via RAG et d'élargir la fenêtre contextuelle, le modèle ne peut pas s'en souvenir et la méthode de remédiation entraînera des problèmes supplémentaires.
En bref, les grands modèles multimodaux actuels n'ont pas une forte adaptabilité dans les scénarios d'application réels, encore moins de créativité, ce qui entraîne diverses difficultés lors de leur mise en œuvre dans l'industrie.
Merveilleux - rappelez-vous ce que nous avons mentionné plus tôt, Awaker 1.0 peut non seulement apprendre de nouvelles connaissances, mais également mémoriser de nouvelles connaissances, et ce type d'apprentissage est quotidien, continu et opportun.
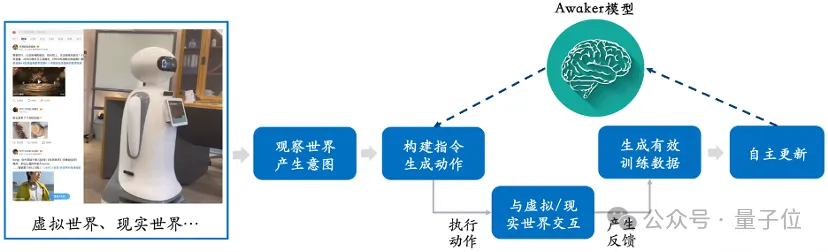
Comme le montre ce diagramme de cadre, Awaker 1.0 peut être combiné avec divers appareils intelligents, observer le monde à travers des appareils intelligents, générer des intentions d'action et construire automatiquement des instructions pour contrôler les appareils intelligents afin d'effectuer diverses actions.
Après avoir effectué diverses actions, l'appareil intelligent générera automatiquement divers retours. Awaker 1.0 peut obtenir des données d'entraînement efficaces à partir de ces actions et retours pour se mettre à jour en permanence et renforcer continuellement les différentes capacités du modèle.
Cela équivaut à une intelligence incarnée ayant un cerveau vivant.
Qui n'a pas dit comment payer (tête de chien)~
Ce qui est particulièrement important, c'est que, en raison de sa capacité à se mettre à jour de manière indépendante, Awaker 1.0 n'est pas seulement adaptable à l'intelligence incarnée, il est également applicable à un une plus large gamme de scénarios industriels d'applications et peut résoudre des tâches pratiques plus complexes.
Par exemple, Awaker 1.0 est intégré à divers appareils intelligents pour réaliser une collaboration à la pointe du cloud.
À l'heure actuelle, Awaker 1.0 est le « cerveau » déployé dans le cloud, observant, commandant et contrôlant divers appareils intelligents de pointe pour effectuer diverses tâches.
Les commentaires obtenus lorsque l'appareil intelligent Edge effectue diverses tâches seront continuellement transmis à Awaker 1.0, lui permettant d'obtenir en permanence des données d'entraînement et de se mettre à jour en permanence.
Ce ne sont pas que des paroles. La voie technique d'Awaker 1.0 et la collaboration cloud-edge avec les appareils intelligents ont été appliquées dans des scénarios d'application tels que les inspections de réseaux intelligents et les villes intelligentes, et ont obtenu des résultats de reconnaissance bien meilleurs que ceux-là. des petits modèles traditionnels.

Le grand modèle multimodal peut entendre, voir et parler. Il a montré un grand potentiel et une grande valeur d'application dans de nombreux domaines tels que la reconnaissance vocale, le traitement d'images et la compréhension du langage naturel.
Mais ses problèmes sont évidents, comment absorber continuellement de nouvelles connaissances et s'adapter aux nouveaux changements ?
On peut dire que cultiver la force interne et améliorer les arts martiaux sont devenus un enjeu important auquel sont confrontés les grands mannequins multimodaux.
L'avènement du moteur Sophon Awaker 1.0 apporte une clé d'auto-transcendance des grands modèles multimodaux.
Il semble avoir maîtrisé la méthode d'attraction d'étoiles. Grâce au mécanisme de mise à jour indépendant, il brise le goulot d'étranglement de la pénurie de données et offre la possibilité d'un apprentissage continu et de l'auto-évolution de grands modèles multimodaux ; technologie de collaboration de pointe pour s'aventurer courageusement dans le monde. Scénarios d'application spécifiques de dispositifs intelligents tels que l'intelligence incorporée.
C'est peut-être un petit pas vers l'AGI, mais c'est aussi le début d'un voyage de dépassement de soi pour les grands modèles multimodaux.
Le voyage long et difficile nécessite qu'une équipe comme Sophon Engine grimpe continuellement au sommet de la technologie.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
