
 Périphériques technologiques
IA
La plus grande reconstruction de l'histoire de 25km² ! NeRF-XL : Utilisation vraiment efficace de l'entraînement commun multi-cartes !
Périphériques technologiques
IA
La plus grande reconstruction de l'histoire de 25km² ! NeRF-XL : Utilisation vraiment efficace de l'entraînement commun multi-cartes !
La plus grande reconstruction de l'histoire de 25km² ! NeRF-XL : Utilisation vraiment efficace de l'entraînement commun multi-cartes !

Titre original : NeRF-XL : Scaling NeRFs with Multiple GPUs
Lien papier : https://research.nvidia.com/labs/toronto-ai/nerfxl/assets/nerfxl.pdf
Lien du projet : https:// / /research.nvidia.com/labs/toronto-ai/nerfxl/
Affiliation de l'auteur : NVIDIA University of California, Berkeley

Idée de thèse :
Cet article propose NeRF-XL, qui est un principe procédé de distribution de champs de rayons neuronaux (NeRF) sur plusieurs unités de traitement graphique (GPU), permettant ainsi la formation et le rendu de NeRF avec des capacités arbitrairement grandes. Cet article passe d'abord en revue plusieurs méthodes GPU existantes qui décomposent de grandes scènes en plusieurs NeRF formés indépendamment [9, 15, 17] et identifie plusieurs problèmes fondamentaux avec ces méthodes qui posent problème lorsque l'utilisation de ressources informatiques (GPU) supplémentaires pour la formation empêche l'amélioration de la reconstruction. qualité. NeRF-XL résout ces problèmes et permet aux NeRF avec un nombre illimité de paramètres d'être entraînés et rendus en utilisant simplement plus de matériel. Le cœur de notre approche est une nouvelle formulation de formation et de rendu distribuée, qui est mathématiquement équivalente au cas classique d'un seul GPU et minimise la communication entre les GPU. En déverrouillant les NeRF avec un nombre arbitrairement grand de paramètres, notre méthode est la première à révéler les lois de mise à l'échelle GPU des NeRF, montrant une qualité de reconstruction améliorée à mesure que le nombre de paramètres augmente et que plus de GPU sont utilisés. La vitesse augmente avec l'augmentation. Cet article démontre l'efficacité de NeRF-XL sur une variété d'ensembles de données, y compris MatrixCity [5], qui contient environ 258 000 images et couvre une zone urbaine de 25 kilomètres carrés.
Conception du papier :
Les progrès récents dans la nouvelle synthèse de perspective ont considérablement amélioré notre capacité à capturer les champs de rayonnement neuronal (NeRF), rendant le processus plus accessible. Ces progrès nous permettent de reconstruire des scènes plus grandes et des détails plus fins. Que ce soit en augmentant l'échelle spatiale (par exemple, capturer des kilomètres d'un paysage urbain) ou en augmentant le niveau de détail (par exemple, scanner des brins d'herbe dans un champ), élargir la portée d'une scène capturée implique d'incorporer une plus grande quantité d'informations dans NeRF pour Réalisez une reconstruction précise. Par conséquent, pour les scènes riches en informations, le nombre de paramètres pouvant être entraînés requis pour la reconstruction peut dépasser la capacité de mémoire d'un seul GPU.
Cet article propose NeRF-XL, un algorithme de principe pour une distribution efficace des scènes radiales neuronales (NeRF) sur plusieurs GPU. La méthode décrite dans cet article permet de capturer des scènes à contenu informatif élevé (y compris des scènes avec des fonctionnalités à grande échelle et très détaillées) en augmentant simplement les ressources matérielles. Le cœur de NeRF-XL est d’attribuer les paramètres NeRF parmi un ensemble de régions spatiales disjointes et de les entraîner conjointement sur les GPU. Contrairement aux processus de formation distribués traditionnels qui synchronisent les gradients lors de la propagation vers l'arrière, notre méthode n'a besoin que de synchroniser les informations lors de la propagation vers l'avant. De plus, en restituant soigneusement les équations et les termes de perte associés dans un environnement distribué, nous réduisons considérablement le transfert de données requis entre les GPU. Cette nouvelle réécriture améliore la formation et l’efficacité du rendu. La flexibilité et l'évolutivité de cette méthode permettent à cet article d'optimiser efficacement plusieurs GPU et d'utiliser plusieurs GPU pour une optimisation efficace des performances.
Nos travaux contrastent avec les approches récentes qui ont adopté des algorithmes GPU pour modéliser des scènes à grande échelle en entraînant un ensemble de NeRF stéréoscopiques indépendants [9, 15, 17]. Bien que ces méthodes ne nécessitent pas de communication entre les GPU, chaque NeRF doit modéliser l'intégralité de l'espace, y compris les zones d'arrière-plan. Cela entraîne une redondance accrue de la capacité du modèle à mesure que le nombre de GPU augmente. De plus, ces méthodes nécessitent un mélange de NeRF lors du rendu, ce qui dégrade la qualité visuelle et introduit des artefacts dans les régions qui se chevauchent. Par conséquent, contrairement à NeRF-XL, ces méthodes utilisent davantage de paramètres de modèle dans l’entraînement (ce qui équivaut à davantage de GPU) et ne parviennent pas à améliorer la qualité visuelle.
Cet article démontre l'efficacité de notre approche à travers un ensemble diversifié de cas de capture, notamment des analyses de rues, des survols de drones et des vidéos centrées sur les objets. Les cas vont de petites scènes (10 mètres carrés) à des villes entières (25 kilomètres carrés). Nos expériences montrent qu'à mesure que nous allouons davantage de ressources informatiques au processus d'optimisation, NeRF-XL commence à améliorer la qualité visuelle (mesurée par le PSNR) et la vitesse de rendu. Par conséquent, NeRF-XL permet d’entraîner NeRF avec une capacité arbitraire sur des scènes de n’importe quelle échelle spatiale et de n’importe quel détail.

Figure 1 : L'algorithme de formation distribué multi-GPU basé sur le principe de cet article peut faire évoluer les NeRF à n'importe quelle grande échelle.

Figure 2 : Formation indépendante et formation conjointe multi-GPU. La formation de plusieurs NeRF [9, 15, 18] nécessite indépendamment que chaque NeRF modélise à la fois la région focale et son environnement, ce qui conduit à une redondance dans la capacité du modèle. En revanche, notre méthode de formation conjointe utilise des NeRF qui ne se chevauchent pas et ne présente donc aucune redondance.
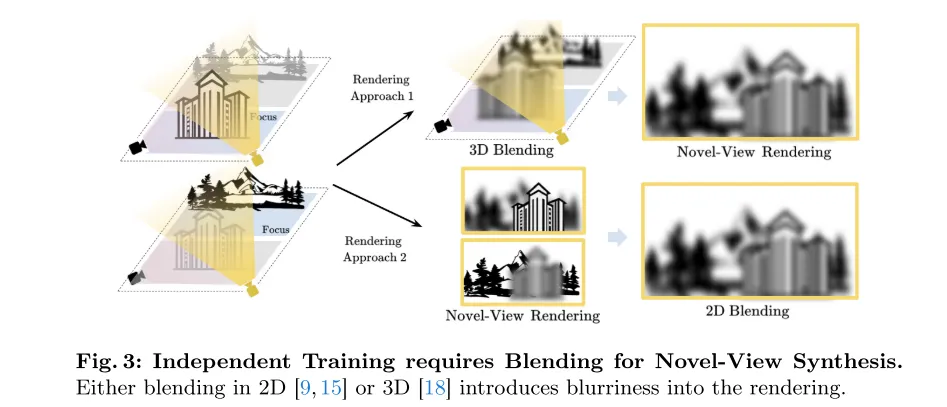
Figure 3 : La formation indépendante nécessite un mélange lorsque de nouvelles perspectives sont synthétisées. Que le mélange soit effectué en 2D [9, 15] ou en 3D [18], du flou sera introduit dans le rendu.
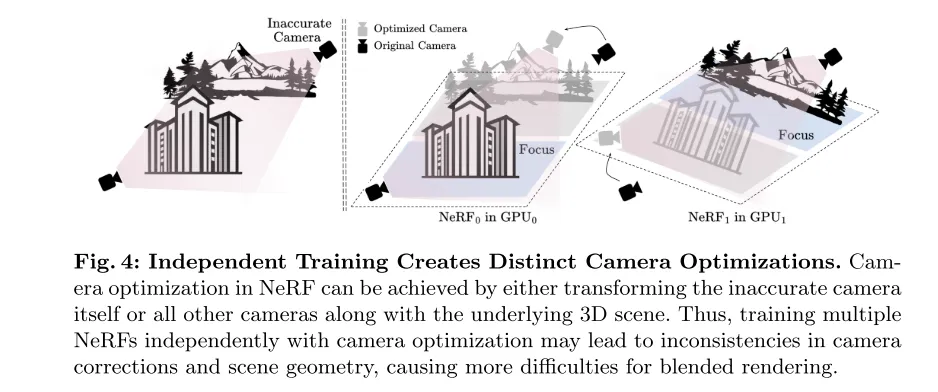
Figure 4 : Une formation indépendante conduit à différentes optimisations de caméra. Dans NeRF, l'optimisation de la caméra peut être obtenue en transformant la caméra imprécise elle-même ou toutes les autres caméras ainsi que la scène 3D sous-jacente. Par conséquent, la formation indépendante de plusieurs NeRF ainsi que l’optimisation de la caméra peuvent entraîner des incohérences dans les corrections de la caméra et la géométrie de la scène, ce qui entraîne davantage de difficultés pour le rendu hybride.
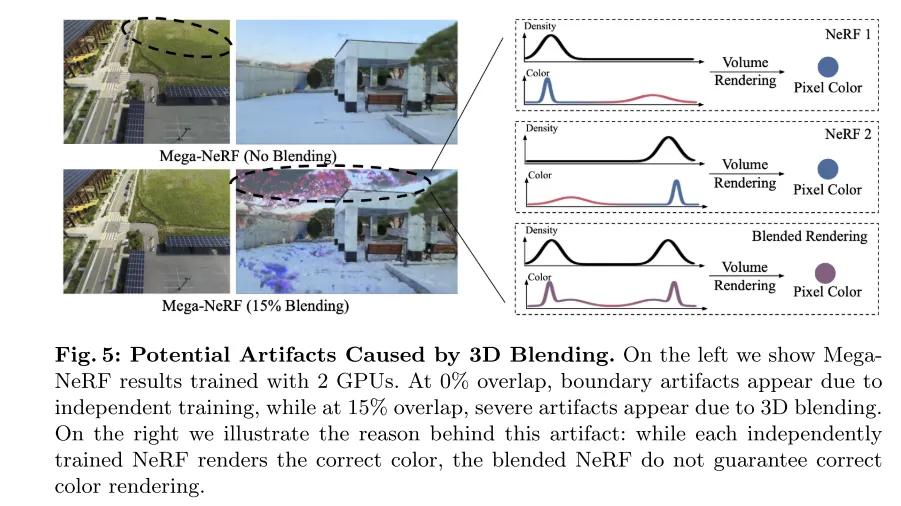
Figure 5 : Artefacts visuels pouvant être causés par le mélange 3D. L'image de gauche montre les résultats de MegaNeRF entraîné à l'aide de 2 GPU. À un chevauchement de 0 %, des artefacts apparaissent aux limites en raison d'un entraînement indépendant, tandis qu'à un chevauchement de 15 %, des artefacts importants apparaissent en raison du mélange 3D. L'image de droite illustre la cause de cet artefact : alors que chaque NeRF formé indépendamment restitue la couleur correcte, le NeRF mélangé ne garantit pas un rendu correct des couleurs.
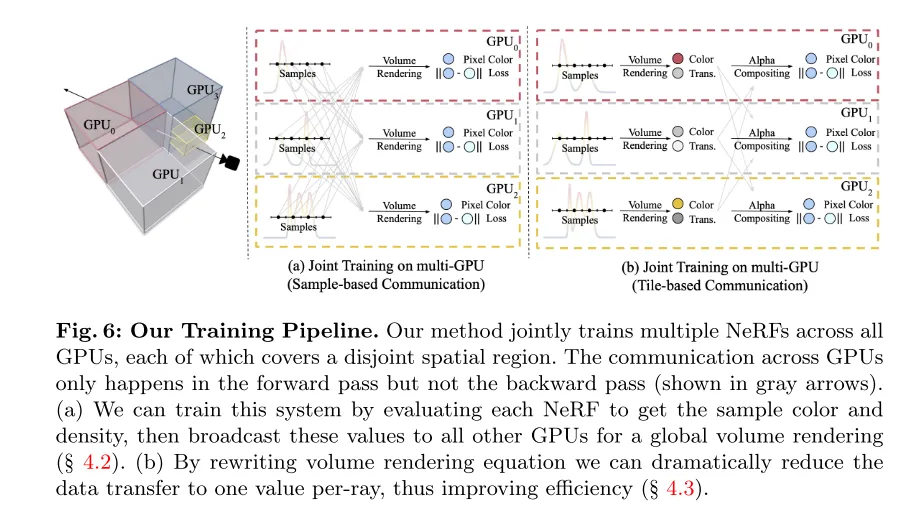
Figure 6 : Le processus de formation de cet article. Notre méthode entraîne conjointement plusieurs NeRF sur tous les GPU, chaque NeRF couvrant une région spatiale disjointe. La communication entre les GPU se produit uniquement en passe avant et non en passe arrière (comme indiqué par la flèche grise). (a) Cet article peut être mis en œuvre en évaluant chaque NeRF pour obtenir la couleur et la densité d'un échantillon, puis en diffusant ces valeurs à tous les autres GPU pour un rendu de volume global (voir section 4.2). (b) En réécrivant l'équation de rendu du volume, cet article peut réduire considérablement la quantité de transmission de données à une valeur par rayon, améliorant ainsi l'efficacité (voir section 4.3).
Résultats expérimentaux :

Figure 7 : Comparaison qualitative. Par rapport aux travaux précédents, notre méthode exploite efficacement les configurations multi-GPU et améliore les performances sur tous les types de données.
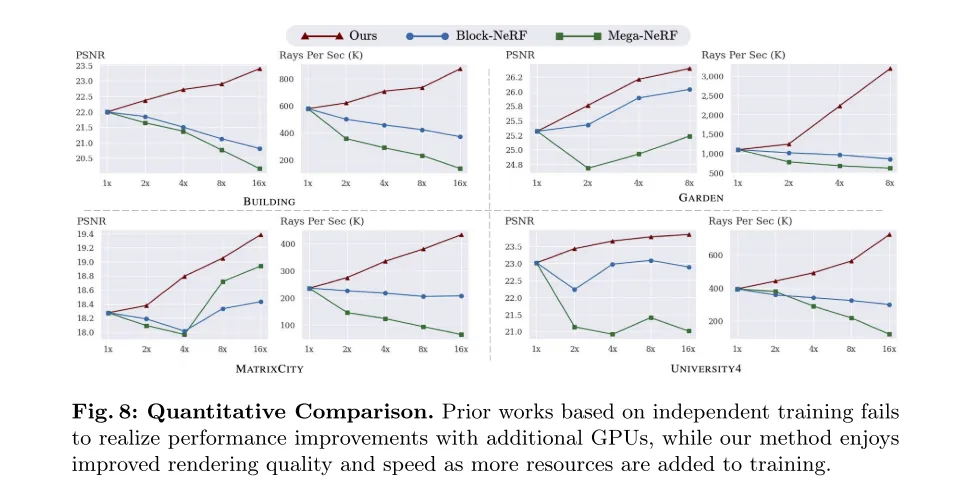
Figure 8 : Comparaison quantitative. Les travaux antérieurs basés sur une formation indépendante n'ont pas réussi à améliorer les performances avec l'ajout de GPU supplémentaires, tandis que notre méthode bénéficie d'améliorations en termes de qualité et de vitesse de rendu à mesure que les ressources de formation augmentent.

Figure 9 : Scalabilité de la méthode dans cet article. Un plus grand nombre de GPU permettent des paramètres plus apprenables, ce qui se traduit par une plus grande capacité de modèle et une meilleure qualité.

Figure 10 : Plus de résultats de rendu sur une capture à grande échelle. Cet article teste la robustesse de notre méthode sur un ensemble de données capturées plus vaste utilisant davantage de GPU. Veuillez consulter la page Web de cet article pour une visite vidéo de ces données.
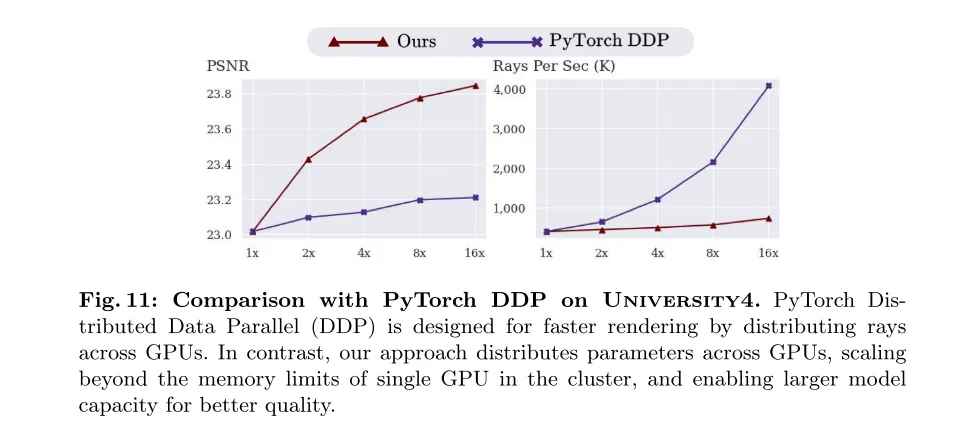
Figure 11 : Comparaison avec PyTorch DDP sur l'ensemble de données University4. PyTorch Distributed Data Parallel (DDP) est conçu pour accélérer le rendu en répartissant la lumière sur le GPU. En revanche, notre méthode distribue les paramètres entre les GPU, dépassant ainsi les limitations de mémoire d'un seul GPU dans le cluster et étant capable d'étendre la capacité du modèle pour une meilleure qualité.
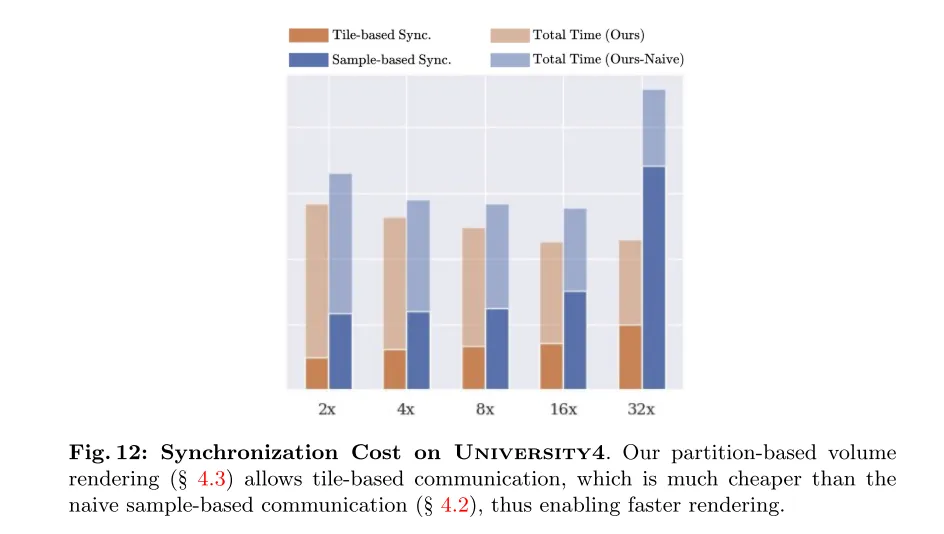
Figure 12 : Coût de synchronisation sur University4. Notre rendu de volume basé sur les partitions (voir Section 4.3) permet une communication basée sur les tuiles, qui est beaucoup moins coûteuse que la communication originale basée sur des échantillons (voir Section 4.2) et permet donc un rendu plus rapide.
Résumé :
En résumé, cet article revisite les méthodes existantes de décomposition de scènes à grande échelle en NeRF (Neural Radiation Fields) formés indépendamment et découvre des obstacles importants qui entravent l'utilisation efficace des ressources informatiques supplémentaires (GPU). ce qui contredit l’objectif principal consistant à exploiter les configurations multi-GPU pour améliorer les performances NeRF à grande échelle. Par conséquent, cet article présente NeRF-XL, un algorithme de principe capable d'exploiter efficacement les configurations multi-GPU et d'améliorer les performances NeRF à n'importe quelle échelle en entraînant conjointement plusieurs NeRF qui ne se chevauchent pas. Il est important de noter que notre méthode ne repose sur aucune règle heuristique et suit les lois de mise à l'échelle de NeRF dans un environnement multi-GPU et est applicable à différents types de données.
Citation :
@misc{li2024nerfxl,title={NeRF-XL: Scaling NeRFs with Multiple GPUs}, author={Ruilong Li and Sanja Fidler and Angjoo Kanazawa and Francis Williams},year={2024},eprint={2404.16221},archivePrefix={arXiv},primaryClass={cs.CV}}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
