
Ce site publie des chroniques au contenu académique et technique. Ces dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com.
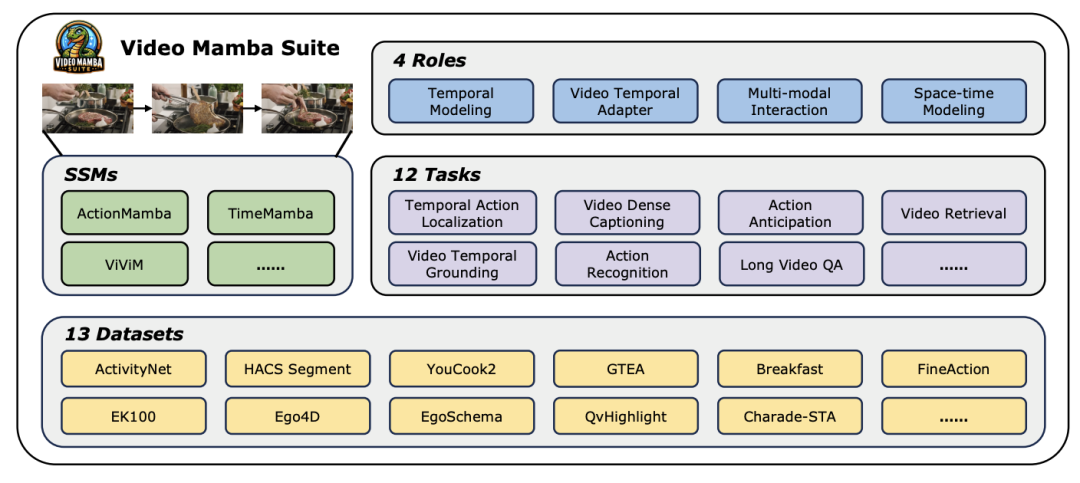
Explorez un nouveau domaine de compréhension vidéo, le modèle Mamba mène une nouvelle tendance dans la recherche en vision par ordinateur ! Les limites des architectures traditionnelles ont été brisées. Le modèle d'espace d'état Mamba a apporté des changements révolutionnaires dans le domaine de la compréhension vidéo grâce à ses avantages uniques dans le traitement de longues séquences. Une équipe de recherche de l'Université de Nanjing, du Laboratoire d'intelligence artificielle de Shanghai, de l'Université de Fudan et de l'Université du Zhejiang a publié un travail révolutionnaire. Ils examinent de manière approfondie les multiples rôles de Mamba dans la modélisation vidéo, proposent la suite Video Mamba pour 14 modèles/modules et effectuent une évaluation approfondie de 12 tâches de compréhension vidéo. Les résultats sont passionnants : Mamba montre un fort potentiel dans les tâches spécifiques à la vidéo et dans les tâches vidéo-verbales, atteignant un équilibre idéal entre efficacité et performances. Il s’agit non seulement d’un saut technologique, mais également d’un puissant élan pour les futures recherches sur la compréhension de la vidéo.
- Titre de l'article : Video Mamba Suite : State Space Model as a Versatile Alternative for Video Understanding
- Lien de l'article : https://arxiv.org/abs/2403.09626
- Lien du code : https ://github.com/OpenGVLab/video-mamba-suite
Dans le domaine actuel en développement rapide de la vision par ordinateur, la technologie de compréhension vidéo est devenue l'un des principaux moteurs du progrès de l'industrie. De nombreux chercheurs s’engagent à explorer et à optimiser diverses architectures d’apprentissage profond afin de réaliser une analyse plus approfondie du contenu vidéo. Depuis les premiers réseaux de neurones récurrents (RNN) et les réseaux de neurones convolutifs tridimensionnels (3D CNN) jusqu'au modèle Transformer actuellement très attendu, chaque avancée technologique a considérablement élargi notre compréhension et notre application des données vidéo. En particulier, le modèle Transformer a réalisé des réalisations remarquables dans plusieurs domaines de la compréhension vidéo grâce à ses excellentes performances, y compris, mais sans s'y limiter, la détection de cibles, la segmentation d'images et la réponse multimodale aux questions. Cependant, face aux caractéristiques inhérentes aux séquences ultra-longues des données vidéo, le modèle Transformer expose également ses limites inhérentes : en raison de son augmentation quadratique de la complexité informatique, il devient extrêmement difficile de modéliser directement des séquences vidéo ultra-longues. Dans ce contexte, l'architecture du modèle d'espace d'états - représentée par Mamba - a émergé comme l'exigent les temps. Avec son avantage de complexité informatique linéaire, elle présente un fort potentiel pour le traitement de données à séquence longue, qui est la base du Transformer. La substitution offre des possibilités. Malgré cela, il existe encore certaines limites dans l'application actuelle de l'architecture de modèle d'espace d'état dans le domaine de la compréhension vidéo : premièrement, elle se concentre principalement sur les tâches globales de compréhension vidéo, telles que la classification et la récupération, deuxièmement, elle explore principalement les méthodes de modélisation spatio-temporelle directe ; Cependant, l’exploration de méthodes de modélisation plus diversifiées reste encore insuffisante. Afin de surmonter ces limites et d'évaluer de manière globale le potentiel du modèle Mamba dans le domaine de la compréhension vidéo, l'équipe de recherche a soigneusement construit la suite vidéo-mamba (Video Mamba Suite). Cette suite vise à compléter les recherches existantes, en explorant les divers rôles et avantages potentiels de Mamba dans la compréhension vidéo à travers une série d'expériences et d'analyses approfondies. L'équipe de recherche a divisé l'application du modèle Mamba en quatre rôles différents et a en conséquence construit une suite vidéo Mamba contenant 14 modèles/modules. Après une évaluation complète de 12 tâches de compréhension vidéo, les résultats expérimentaux révèlent non seulement le grand potentiel de Mamba dans le traitement des tâches vidéo et en langage vidéo, mais démontrent également son excellent équilibre entre efficacité et performances. Les auteurs attendent avec impatience que ces travaux fournissent des ressources de référence et des idées pour de futures recherches dans le domaine de la compréhension vidéo.
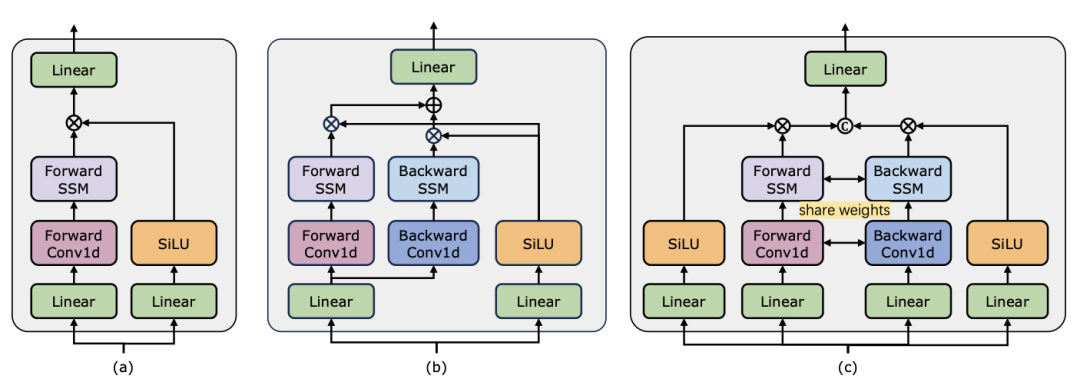
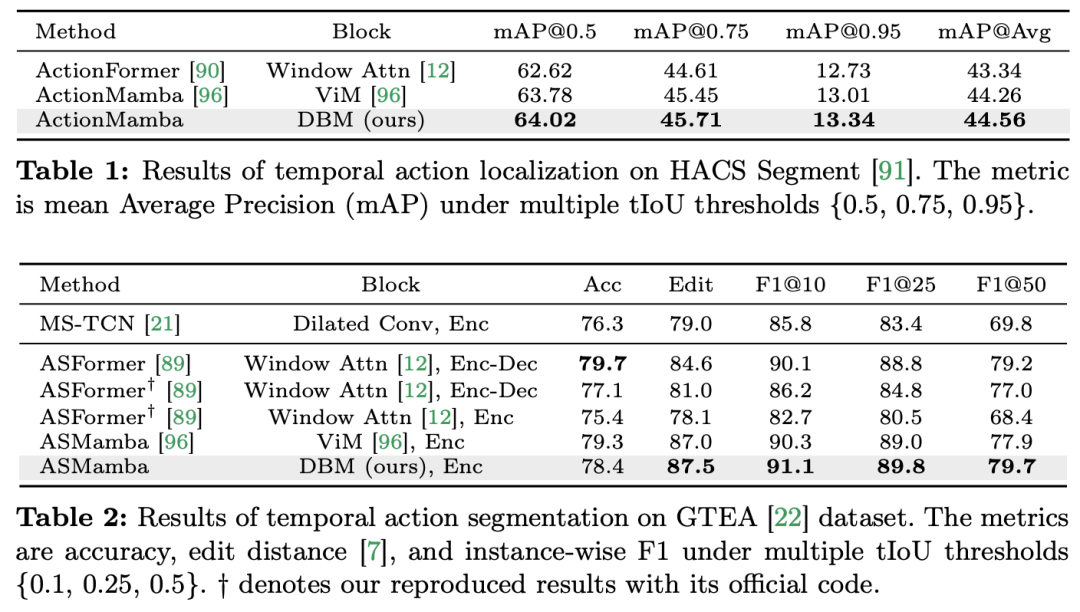
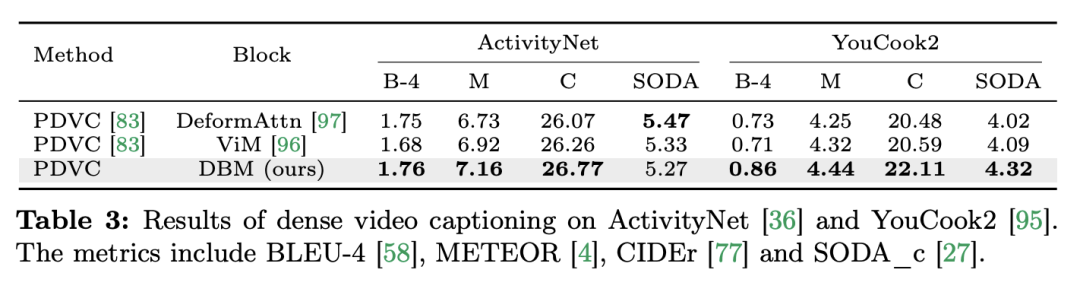
La compréhension de la vidéo est un problème fondamental dans la recherche en vision par ordinateur. Son objectif principal est de capturer la dynamique spatio-temporelle dans la vidéo et de l'utiliser pour identifier et déduire la nature de l'activité et son évolution. processus. Actuellement, l’exploration de l’architecture pour la compréhension vidéo est principalement divisée en trois directions. Premièrement, les méthodes de codage de caractéristiques basées sur des trames modélisent la dépendance temporelle via des réseaux récurrents (tels que GRU et LSTM), mais cette méthode de modélisation spatio-temporelle segmentée est difficile à capturer des informations spatio-temporelles conjointes. Deuxièmement, l'utilisation de noyaux de convolution tridimensionnels permet de considérer simultanément les corrélations spatiales et temporelles dans les réseaux de neurones convolutifs. Avec le grand succès des modèles Transformer dans les domaines du langage et de l'image, les modèles vidéo Transformer ont également fait des progrès significatifs dans le domaine de la compréhension vidéo, démontrant des capacités au-delà des RNN et des 3D-CNN. Video Transformer traite les informations temporelles ou spatio-temporelles de la vidéo de manière unifiée en encapsulant la vidéo dans une série de jetons et en utilisant le mécanisme d'attention pour mettre en œuvre une interaction contextuelle globale et un calcul dynamique dépendant des données. Cependant, en raison de l'efficacité de calcul limitée de Video Transformer lors du traitement de longues vidéos, certaines variantes de modèles ont émergé qui établissent un équilibre entre vitesse et performances. Récemment, les modèles spatiaux d'états (SSM) ont démontré leurs avantages dans le domaine du traitement du langage naturel (NLP). Les SSM modernes présentent de fortes capacités de représentation dans la modélisation de longues séquences tout en conservant une complexité temporelle linéaire. En effet, leur mécanisme de sélection élimine le besoin de stocker le contexte complet. Le modèle Mamba, en particulier, intègre des paramètres variables dans le temps dans SSM et propose un algorithme sensible au matériel pour une formation et une inférence efficaces. Les excellentes performances de mise à l'échelle de Mamba montrent qu'il peut constituer une alternative prometteuse à Transformer. En même temps, les hautes performances et l'efficacité de Mamba le rendent très approprié pour les tâches de compréhension vidéo. Bien qu'il y ait eu quelques premières tentatives pour explorer l'application de Mamba dans la modélisation d'images/vidéos, son efficacité dans la compréhension vidéo n'est toujours pas claire. Le manque de recherches approfondies sur le potentiel de Mamba en matière de compréhension vidéo limite l’exploration plus approfondie de ses capacités dans diverses tâches liées à la vidéo. En réponse aux problèmes ci-dessus, l'équipe de recherche a exploré le potentiel de Mamba dans le domaine de la compréhension vidéo. Le but de leurs recherches est d'évaluer si Mamba peut être une alternative viable aux Transformers dans ce domaine. Pour ce faire, ils ont d’abord abordé la question de savoir comment réfléchir aux différents rôles de Mamba dans la compréhension de la vidéo. Sur cette base, ils ont étudié plus en détail quelles tâches Mamba accomplissait le mieux. L'article divise le rôle de Mamba dans la modélisation vidéo en quatre catégories suivantes : 1) modèle temporel, 2) module temporel, 3) réseau d'interaction multimodal, 4) modèle spatio-temporel. Pour chaque rôle, l’équipe de recherche a étudié ses capacités de modélisation vidéo sur différentes tâches de compréhension vidéo. Pour opposer équitablement Manba à Transformer, l'équipe de recherche a soigneusement sélectionné des modèles de comparaison basés sur des architectures Transformer standard ou modifiées. Sur cette base, ils ont obtenu une suite vidéo Mamba contenant 14 modèles/modules adaptés à 12 tâches de compréhension vidéo. L’équipe de recherche espère que Video Mamba Suite pourra devenir à l’avenir une ressource de base pour explorer les modèles de compréhension vidéo basés sur SSM. Mamba comme modèle de chronométrage vidéoTâches et données : L'équipe de recherche a évalué les performances de Mamba sur cinq tâches de chronométrage vidéo : Localisation de l'action temporelle ( HACS Segment), segmentation d'action temporelle (GTEA), sous-titrage vidéo dense (ActivityNet, YouCook), sous-titrage de segment vidéo (ActivityNet, YouCook) et prédiction d'action (Epic-Kitchen-100). Baseline et Challenger : L'équipe de recherche a sélectionné des modèles basés sur Transformer comme référence pour chaque tâche. Plus précisément, ces modèles de base incluent ActionFormer, ASFormer, Testra et PDVC. Afin de créer un challenger Mamba, ils ont remplacé le module Transformer dans le modèle de base par un module basé sur Mamba, comprenant trois modules comme indiqué ci-dessus, le Mamba (a) d'origine, le ViM (b) et le DBM (c) à l'origine. conçu par l'équipe de recherche). Il convient de noter que l'article compare les performances du modèle de base avec le module Mamba original dans une tâche de prédiction d'action impliquant une inférence causale. Résultats et analyse : Le document montre les résultats de comparaison de différents modèles sur quatre tâches. Dans l’ensemble, bien que certains modèles basés sur Transformer aient incorporé des variantes d’attention pour améliorer les performances. Le tableau ci-dessous montre les performances supérieures de la série Mamba par rapport aux méthodes existantes de la série Transformer.L'équipe de recherche s'est non seulement concentrée sur les tâches monomodales, mais a également évalué les performances de Mamba dans les tâches d'interaction multimodale. L'article utilise la tâche de localisation vidéo temporelle (VTG) pour évaluer les performances de Mamba. Les ensembles de données couverts incluent QvHighlight et Charade-STA.
Tâches et données
: L'équipe de recherche a évalué les performances de Mamba sur cinq tâches temporelles vidéo : localisation d'action temporelle (segment HACS), segmentation d'action temporelle (GTEA), sous-titres vidéo denses (ActivityNet, YouCook), sous-titres de paragraphes vidéo (ActivityNet, YouCook) et prédiction d'action (Epic-Kitchen-100).
: L'équipe de recherche a utilisé UniVTG pour créer un modèle VTG basé sur Mamba. UniVTG adopte Transformer comme réseau d'interaction multimodal. Compte tenu des fonctionnalités vidéo et des fonctionnalités de texte, ils ajoutent d’abord des intégrations d’emplacement apprenables et des intégrations de types de modalités pour chaque modalité afin de préserver les informations d’emplacement et de modalité. Les jetons texte et vidéo sont ensuite concaténés pour former une entrée commune qui est ensuite introduite dans l'encodeur multimodal Transformer. Enfin, les fonctionnalités vidéo augmentées de texte sont extraites et introduites dans la tête de prédiction. Pour créer un concurrent Mamba multimodal, l'équipe de recherche a choisi d'empiler des blocs Mamba bidirectionnels pour former un encodeur Mamda multimodal pour remplacer la ligne de base du Transformer.
Résultats et analyse
: Cet article teste les performances de plusieurs modèles via QvHighlight. Mamba a un mAP moyen de 44,74, ce qui représente une amélioration significative par rapport à Transformer. Sur Charade-STA, la méthode basée sur Mamba présente une compétitivité similaire à celle de Transformer. Cela montre que Mamba a le potentiel d’intégrer efficacement plusieurs modalités. Considérant que Mamba est un modèle basé sur un balayage linéaire, tandis que Transformer est basé sur une interaction globale de marques, l'équipe de recherche croit intuitivement que la position du texte dans la séquence de marques peut affecter l'effet de l'agrégation multimodale. Pour étudier cela, ils incluent différentes méthodes de fusion texte-visuel dans le tableau et montrent quatre dispositions de marques différentes dans la figure. La conclusion est que les meilleurs résultats sont obtenus lorsque les conditions textuelles sont fusionnées à gauche des caractéristiques visuelles. QvHighlight a moins d'impact sur cette fusion, tandis que Charade-STA est particulièrement sensible à la position du texte, ce qui peut être attribué aux caractéristiques de l'ensemble de données.
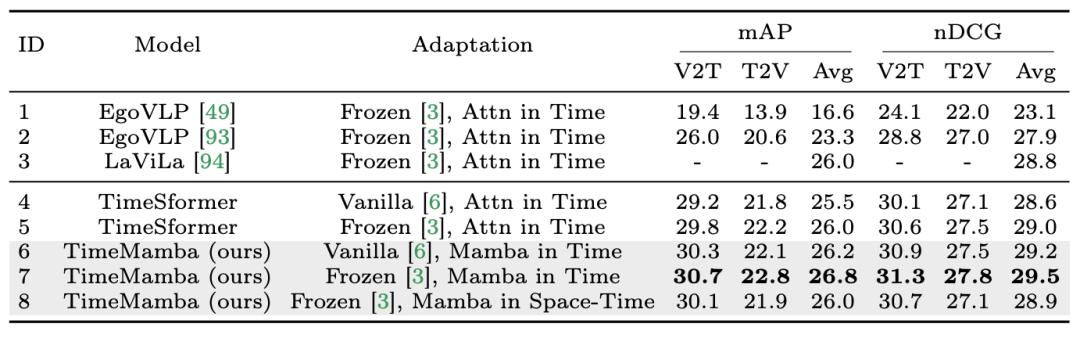
Mamba comme adaptateur de synchronisation vidéo En plus d'évaluer les performances de Mamba en matière de modélisation post-synchronisation, l'équipe de recherche a également examiné son efficacité en tant qu'adaptateur de synchronisation vidéo. Le modèle Two Towers est pré-entraîné en effectuant un apprentissage contrastif vidéo-texte sur des données égocentriques, qui contiennent 4 millions de clips vidéo avec une narration fine. Tâches et données : L'équipe de recherche a évalué les performances de Mamba sur cinq tâches vidéo temporelles, notamment : localisation de l'action temporelle (segment HACS), segmentation de l'action temporelle (GTEA), sous-titres vidéo denses (ActivityNet, YouCook), vidéo sous-titres de paragraphes (ActivityNet, YouCook) et prédiction d'action (Epic-Kitchen-100). Baseline et Challenger : TimeSformer adopte des blocs d'attention spatio-temporelle distincts pour modéliser séparément les relations spatiales et temporelles dans les vidéos. À cette fin, l’équipe de recherche a introduit un bloc Mamba bidirectionnel comme adaptateur de synchronisation pour remplacer l’auto-attention temporelle d’origine et améliorer les interactions spatio-temporelles distinctes. À titre de comparaison équitable, la couche d'attention spatiale dans TimeSformer reste inchangée. Ici, l'équipe de recherche a utilisé des blocs ViM comme modules de synchronisation et a appelé le modèle résultant TimeMamba. Il convient de noter que le bloc ViM standard a plus de paramètres (un peu plus de ) que le bloc d'auto-attention, où C est la dimension des fonctionnalités. Par conséquent, le taux d'expansion E du bloc ViM est fixé à 1 dans l'article, réduisant la taille de ses paramètres à pour une comparaison équitable. En plus de la forme de connexion résiduelle ordinaire utilisée par TimeSformer, l'équipe de recherche a également exploré l'adaptation du style Frozen. Voici 5 structures d'adaptateur :
1. Récupération multi-instance sans tir. L'équipe de recherche a d'abord évalué différents modèles avec des interactions spatio-temporelles distinctes dans le tableau et a constaté que les connexions résiduelles de style Frozen reproduites dans l'article étaient cohérentes avec celles de LaViLa. En comparant les styles original et Frozen, il n'est pas difficile d'observer que le style Frozen produit toujours de meilleurs résultats. De plus, avec la même méthode d'adaptation, le module temporel basé sur ViM surpasse toujours le module temporel basé sur l'attention. Il convient de noter que le bloc temporel ViM utilisé dans l'article a moins de paramètres que le bloc temporel d'auto-attention, soulignant la meilleure utilisation des paramètres et les capacités d'extraction d'informations de l'analyse sélective Mamba. De plus, l'équipe de recherche a vérifié davantage le bloc spatio-temporel ViM. Le bloc ViM spatio-temporel remplace le bloc ViM temporel par une modélisation spatio-temporelle conjointe sur l'ensemble de la séquence vidéo. Étonnamment, malgré l’introduction de la modélisation globale, le bloc ViM spatio-temporel entraîne en réalité une dégradation des performances. À cette fin, l’équipe de recherche suppose que l’analyse spatio-temporelle pourrait détruire le bloc d’attention spatiale pré-entraîné pour produire une distribution de caractéristiques spatiales. Voici les résultats expérimentaux :
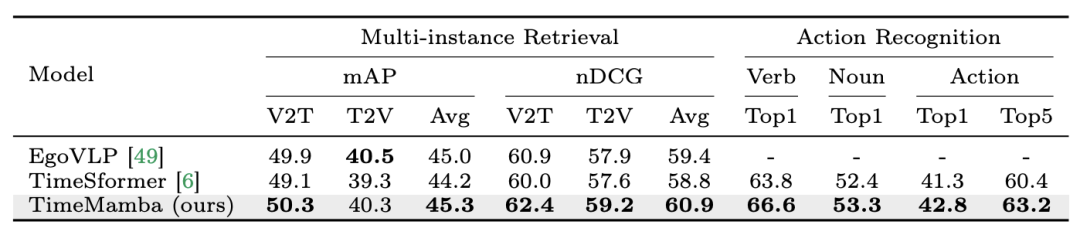
2. Affiner la récupération multi-instance et la reconnaissance d'action. L'équipe de recherche continue d'utiliser des modèles pré-entraînés affinés à 16 images sur l'ensemble de données Epic-Kitchens-100 pour la récupération multi-instances et la reconnaissance d'actions. Il ressort des résultats expérimentaux que TimeMamba surpasse considérablement TimeSformer dans le contexte de la reconnaissance des verbes, dépassant 2,8 points de pourcentage, ce qui montre que TimeMamba peut modéliser efficacement un timing précis.
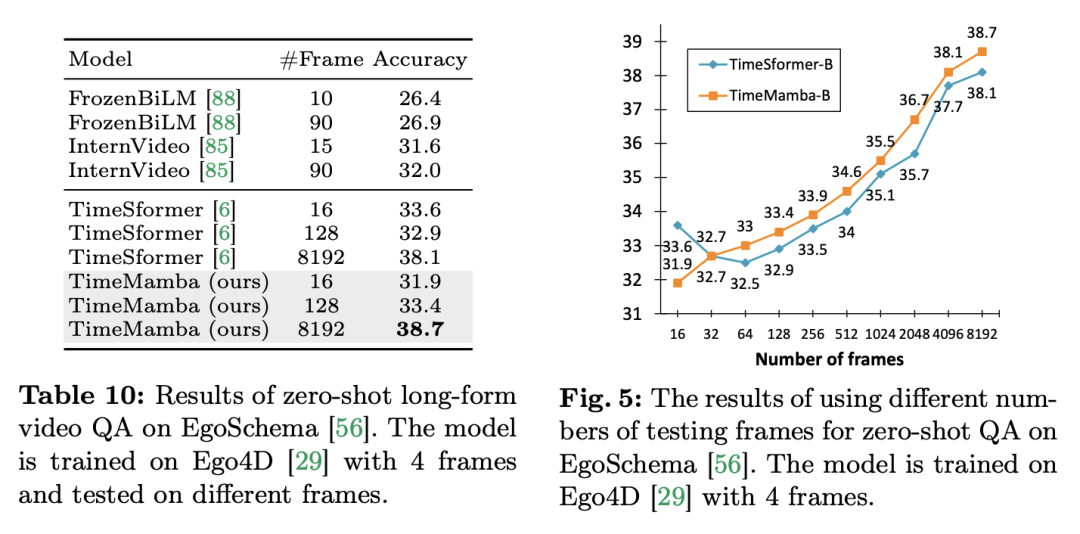
3. Aucun échantillon de questions et réponses sur une longue vidéo. L’équipe de recherche a en outre évalué les performances de questions-réponses vidéo longues du modèle sur l’ensemble de données EgoSchema. Voici les résultats expérimentaux :
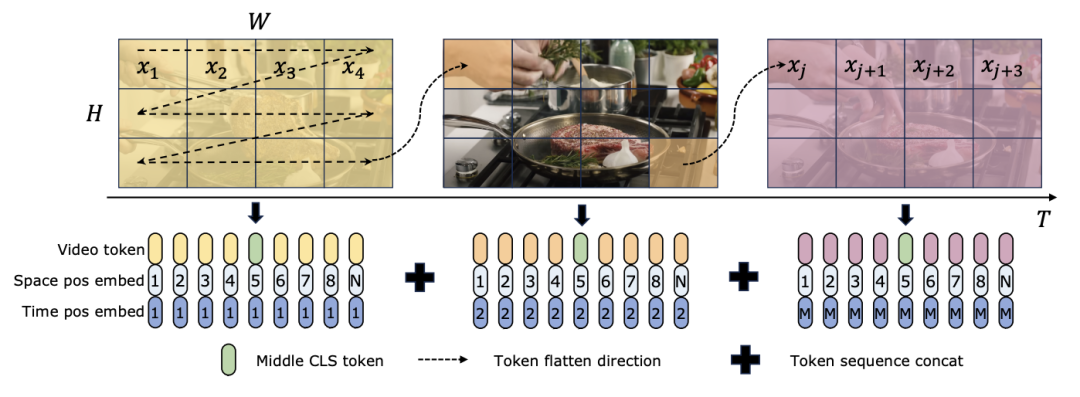
TimeSformer et TimeMamba, après une pré-formation sur Ego4D, dépassent les performances des modèles pré-entraînés à grande échelle (tels qu'InternVideo). De plus, l'équipe de recherche a continuellement augmenté le nombre d'images de test à partir de la vidéo à un FPS fixe pour explorer l'impact des capacités de modélisation temporelle vidéo longue des blocs ViM. Bien que les deux modèles soient pré-entraînés avec 4 images, les performances de TimeMamba et TimeSformer s'améliorent régulièrement à mesure que le nombre d'images augmente. Parallèlement, des améliorations significatives peuvent être observées lors de l’utilisation de trames 8192. Lorsque les images d'entrée dépassent 32, TimeMamba bénéficie généralement de plus d'images que TimeSformer, indiquant la supériorité des blocs Temporal ViM dans l'auto-attention temporelle. Mamba pour la modélisation spatio-temporelleTâches et données : De plus, l'article évalue également les capacités de Mamba en matière de modélisation spatio-temporelle, en particulier dans Epic-Kitchens. dans la récupération multi-instance Zero-shot a été évaluée sur 100 ensembles de données. Baseline and Competitors : ViViT et TimeSformer étudient la transformation de ViT avec attention spatiale en un modèle avec attention spatio-temporelle conjointe. Sur cette base, l’équipe de recherche a élargi l’analyse sélective spatiale du modèle ViM pour inclure l’analyse sélective spatio-temporelle. Nommez ce modèle étendu ViViM. L'équipe de recherche a utilisé le modèle ViM pré-entraîné sur ImageNet-1K pour l'initialisation. Le modèle ViM contient un jeton cls qui est inséré au milieu de la séquence de jetons plats. La figure ci-dessous montre comment convertir le modèle ViM en ViViM. Pour une entrée donnée contenant M trames, insérez un jeton cls au milieu de la séquence de jetons correspondant à chaque trame. De plus, l’équipe de recherche a ajouté l’intégration de la position temporelle, initialisée à zéro pour chaque image. La séquence vidéo aplatie est ensuite entrée dans le modèle ViViM. La sortie du modèle est obtenue en calculant la moyenne des jetons cls pour chaque trame.
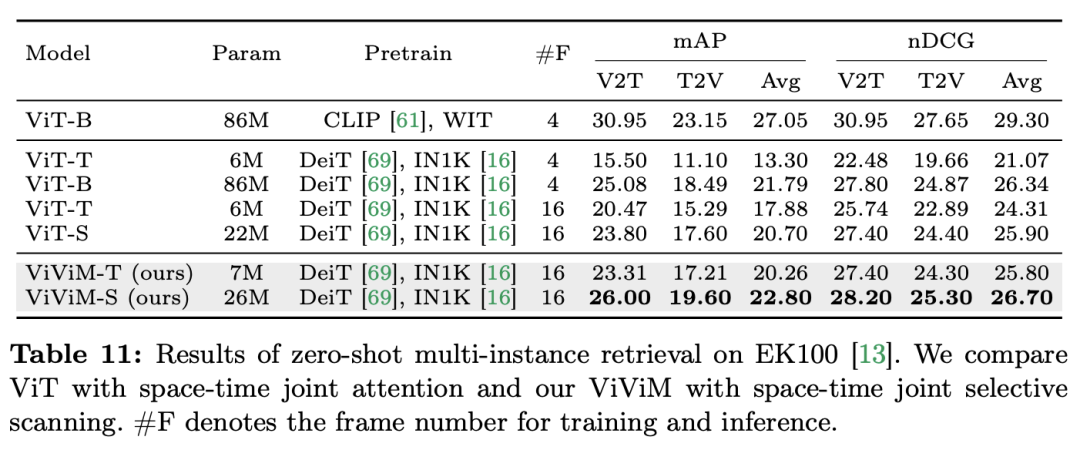
Résultats et analyse : L'article étudie plus en détail les résultats de ViViM dans la récupération multi-instance à échantillon nul. Les résultats expérimentaux sont présentés dans le tableau suivant :
Les résultats montrent que différentes spatio-. les modèles temporels effectuent une récupération multi-instance sans échantillon. Performances lors de la récupération. En comparant ViT et ViViM, tous deux pré-entraînés sur ImageNet-1K, on peut observer que ViViM surpasse ViT. Il est intéressant de noter que bien que l'écart de performances entre ViT-S et ViM-S sur ImageNet-1K soit faible (79,8 contre 80,5), ViViM-S montre une amélioration significative par rapport à la récupération multi-instance sans tir (+2,1 mAP @Avg), ce qui montre que ViViM est très efficace pour modéliser de longues séquences, améliorant ainsi les performances. Cet article démontre le potentiel de Mamba en tant qu'alternative viable aux Transformers traditionnels en évaluant de manière exhaustive ses performances dans le domaine de la compréhension vidéo. Grâce à la suite Video Mamba, composée de 14 modèles/modules pour 12 tâches de compréhension vidéo, l'équipe de recherche a démontré la capacité de Mamba à gérer efficacement des dynamiques spatio-temporelles complexes. Mamba offre non seulement des performances supérieures, mais atteint également un meilleur équilibre efficacité-performance. Ces résultats mettent non seulement en évidence l'adéquation de Mamba aux tâches d'analyse vidéo, mais ouvrent également de nouvelles voies pour son application dans le domaine de la vision par ordinateur. Les travaux futurs pourront explorer davantage l'adaptabilité de Mamba et étendre son utilité à des défis de compréhension vidéo multimodaux plus complexes. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Périphériques technologiques
Périphériques technologiques



 Tâches et données
Tâches et données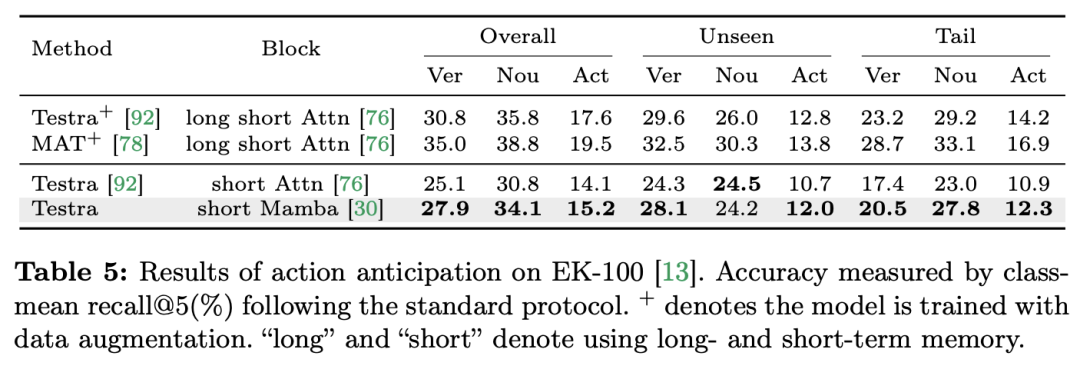
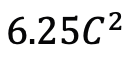 ) que le bloc d'auto-attention, où C est la dimension des fonctionnalités. Par conséquent, le taux d'expansion E du bloc ViM est fixé à 1 dans l'article, réduisant la taille de ses paramètres à
) que le bloc d'auto-attention, où C est la dimension des fonctionnalités. Par conséquent, le taux d'expansion E du bloc ViM est fixé à 1 dans l'article, réduisant la taille de ses paramètres à 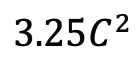 pour une comparaison équitable. En plus de la forme de connexion résiduelle ordinaire utilisée par TimeSformer, l'équipe de recherche a également exploré l'adaptation du style Frozen. Voici 5 structures d'adaptateur :
pour une comparaison équitable. En plus de la forme de connexion résiduelle ordinaire utilisée par TimeSformer, l'équipe de recherche a également exploré l'adaptation du style Frozen. Voici 5 structures d'adaptateur : 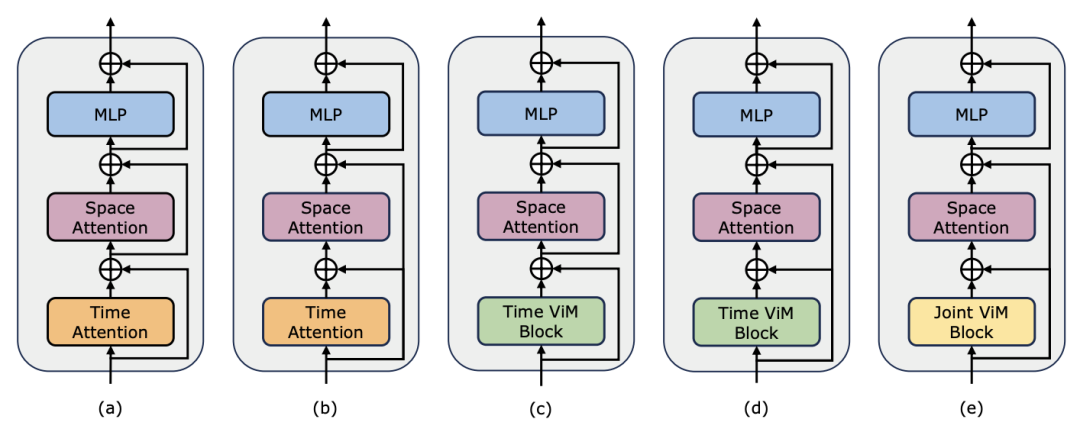















 Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
 Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
 La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
 Comment calculer C-SUBScript 3 Indice 5 C-SUBScript 3 Indice Indice 5 Tutoriel d'algorithme
Apr 03, 2025 pm 10:33 PM
Comment calculer C-SUBScript 3 Indice 5 C-SUBScript 3 Indice Indice 5 Tutoriel d'algorithme
Apr 03, 2025 pm 10:33 PM
 Comment implémenter la disposition adaptative de la position de l'axe y dans l'annotation Web?
Apr 04, 2025 pm 11:30 PM
Comment implémenter la disposition adaptative de la position de l'axe y dans l'annotation Web?
Apr 04, 2025 pm 11:30 PM
 Dois-je utiliser Flexbox au centre de l'image bootstrap?
Apr 07, 2025 am 09:06 AM
Dois-je utiliser Flexbox au centre de l'image bootstrap?
Apr 07, 2025 am 09:06 AM
 Comment faire en sorte que la hauteur des colonnes adjacentes dans l'interface utilisateur de l'élément s'adapte automatiquement au contenu?
Apr 05, 2025 am 06:12 AM
Comment faire en sorte que la hauteur des colonnes adjacentes dans l'interface utilisateur de l'élément s'adapte automatiquement au contenu?
Apr 05, 2025 am 06:12 AM
 Fonction de fonction distincte Distance de distance C Tutoriel d'utilisation
Apr 03, 2025 pm 10:27 PM
Fonction de fonction distincte Distance de distance C Tutoriel d'utilisation
Apr 03, 2025 pm 10:27 PM
