

Le rôle de float en Java

Le type de données float en Java est utilisé pour représenter des nombres à virgule flottante avec une partie décimale allant de ±3,40282347E+38 à -1,4E-45 avec une précision d'environ 7 chiffres significatifs. Les flotteurs conviennent pour représenter des grandeurs physiques (telles que la température, la distance), des probabilités et des approximations dans les calculs scientifiques. Par rapport au double, float a une plage et une précision plus petites et occupe moins de mémoire. Il convient aux situations où les exigences de précision ne sont pas élevées et la mémoire est limitée.

Le rôle de float en Java
Dans le langage de programmation Java, le type de données float est utilisé pour représenter des nombres à virgule flottante. Il s'agit d'un type de données primitif de 32 bits qui peut représenter des valeurs numériques avec une partie fractionnaire.
scénarios applicables float
Le type de données float est généralement utilisé pour représenter :
- Quantités physiques avec des parties fractionnaires, telles que la température et la distance.
- Probabilité et pourcentage.
- Approximations dans les calculs scientifiques.
plage de flottement et précision
- Plage : ±3.40282347E+38 à -1.4E-45 (environ).
- Précision : 7 chiffres significatifs (environ).
Différence entre float et double
Float et double sont tous deux des types de données utilisés pour représenter des nombres à virgule flottante, mais il existe quelques différences clés entre eux :
- Plage et précision : double a à la fois une plage et une précision. Plus grand que le flotteur. La plage du double va de ±1,7976931348623157E+308 à -4,9406564584124654E-324, avec une précision de 15 à 16 chiffres significatifs.
- Empreinte mémoire : double nécessite 64 bits d'espace de stockage, tandis que float ne nécessite que 32 bits.
Quand utiliser float
L'utilisation du type de données float est plus appropriée dans les situations suivantes :
- Lorsqu'une précision extrêmement élevée n'est pas requise.
- Quand la mémoire est limitée.
- Lorsque vous devez stocker un grand nombre de nombres à virgule flottante.
Quand utiliser double
L'utilisation du type de données double est plus appropriée dans les situations suivantes :
- Lorsqu'une précision extrêmement élevée est requise.
- Lorsque la plage des nombres à virgule flottante dépasse la plage des nombres flottants.
- Lorsque les exigences de performance ne sont pas un facteur critique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Étapes détaillées pour nettoyer la mémoire à Xiaohongshu
Apr 26, 2024 am 10:43 AM
Étapes détaillées pour nettoyer la mémoire à Xiaohongshu
Apr 26, 2024 am 10:43 AM
1. Ouvrez Xiaohongshu, cliquez sur Moi dans le coin inférieur droit 2. Cliquez sur l'icône des paramètres, cliquez sur Général 3. Cliquez sur Vider le cache
 Que faire si votre téléphone Huawei a une mémoire insuffisante (Méthodes pratiques pour résoudre le problème de mémoire insuffisante)
Apr 29, 2024 pm 06:34 PM
Que faire si votre téléphone Huawei a une mémoire insuffisante (Méthodes pratiques pour résoudre le problème de mémoire insuffisante)
Apr 29, 2024 pm 06:34 PM
Le manque de mémoire sur les téléphones mobiles Huawei est devenu un problème courant auquel sont confrontés de nombreux utilisateurs, avec l'augmentation des applications mobiles et des fichiers multimédias. Pour aider les utilisateurs à utiliser pleinement l'espace de stockage de leurs téléphones mobiles, cet article présentera quelques méthodes pratiques pour résoudre le problème de mémoire insuffisante sur les téléphones mobiles Huawei. 1. Nettoyer le cache : enregistrements d'historique et données invalides pour libérer de l'espace mémoire et effacer les fichiers temporaires générés par les applications. Recherchez « Stockage » dans les paramètres de votre téléphone Huawei, cliquez sur « Vider le cache » et sélectionnez le bouton « Vider le cache » pour supprimer les fichiers de cache de l'application. 2. Désinstallez les applications rarement utilisées : pour libérer de l'espace mémoire, supprimez certaines applications rarement utilisées. Faites glisser vers le haut de l'écran du téléphone, appuyez longuement sur l'icône « Désinstaller » de l'application que vous souhaitez supprimer, puis cliquez sur le bouton de confirmation pour terminer la désinstallation. 3.Application mobile pour
 Comment affiner la profondeur localement
Feb 19, 2025 pm 05:21 PM
Comment affiner la profondeur localement
Feb 19, 2025 pm 05:21 PM
Le réglage fin local des modèles de classe Deepseek est confronté au défi des ressources informatiques insuffisantes et de l'expertise. Pour relever ces défis, les stratégies suivantes peuvent être adoptées: quantification du modèle: convertir les paramètres du modèle en entiers à faible précision, réduisant l'empreinte de la mémoire. Utilisez des modèles plus petits: sélectionnez un modèle pré-entraîné avec des paramètres plus petits pour un réglage fin local plus facile. Sélection des données et prétraitement: sélectionnez des données de haute qualité et effectuez un prétraitement approprié pour éviter une mauvaise qualité des données affectant l'efficacité du modèle. Formation par lots: pour les grands ensembles de données, chargez les données en lots de formation pour éviter le débordement de la mémoire. Accélération avec GPU: Utilisez des cartes graphiques indépendantes pour accélérer le processus de formation et raccourcir le temps de formation.
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Que faire si le navigateur Edge prend trop de mémoire Que faire si le navigateur Edge prend trop de mémoire
May 09, 2024 am 11:10 AM
Que faire si le navigateur Edge prend trop de mémoire Que faire si le navigateur Edge prend trop de mémoire
May 09, 2024 am 11:10 AM
1. Tout d’abord, entrez dans le navigateur Edge et cliquez sur les trois points dans le coin supérieur droit. 2. Ensuite, sélectionnez [Extensions] dans la barre des tâches. 3. Ensuite, fermez ou désinstallez les plug-ins dont vous n'avez pas besoin.
 Pour seulement 250$, le directeur technique de Hugging Face vous apprend étape par étape comment peaufiner Llama 3
May 06, 2024 pm 03:52 PM
Pour seulement 250$, le directeur technique de Hugging Face vous apprend étape par étape comment peaufiner Llama 3
May 06, 2024 pm 03:52 PM
Les grands modèles de langage open source familiers tels que Llama3 lancé par Meta, les modèles Mistral et Mixtral lancés par MistralAI et Jamba lancé par AI21 Lab sont devenus des concurrents d'OpenAI. Dans la plupart des cas, les utilisateurs doivent affiner ces modèles open source en fonction de leurs propres données pour libérer pleinement le potentiel du modèle. Il n'est pas difficile d'affiner un grand modèle de langage (comme Mistral) par rapport à un petit en utilisant Q-Learning sur un seul GPU, mais le réglage efficace d'un grand modèle comme Llama370b ou Mixtral est resté un défi jusqu'à présent. . C'est pourquoi Philipp Sch, directeur technique de HuggingFace
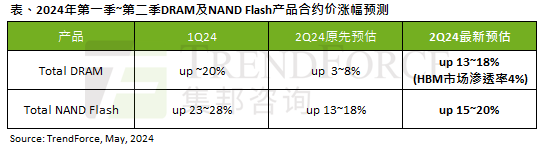 L'impact de la vague de l'IA est évident. TrendForce a révisé à la hausse ses prévisions d'augmentation des prix des contrats de mémoire DRAM et de mémoire flash NAND ce trimestre.
May 07, 2024 pm 09:58 PM
L'impact de la vague de l'IA est évident. TrendForce a révisé à la hausse ses prévisions d'augmentation des prix des contrats de mémoire DRAM et de mémoire flash NAND ce trimestre.
May 07, 2024 pm 09:58 PM
Selon un rapport d'enquête TrendForce, la vague de l'IA a un impact significatif sur les marchés de la mémoire DRAM et de la mémoire flash NAND. Dans l'actualité de ce site du 7 mai, TrendForce a déclaré aujourd'hui dans son dernier rapport de recherche que l'agence avait augmenté les augmentations de prix contractuels pour deux types de produits de stockage ce trimestre. Plus précisément, TrendForce avait initialement estimé que le prix du contrat de mémoire DRAM au deuxième trimestre 2024 augmenterait de 3 à 8 %, et l'estime désormais à 13 à 18 % en termes de mémoire flash NAND, l'estimation initiale augmentera de 13 à 8 % ; 18 %, et la nouvelle estimation est de 15 % ~ 20 %, seul eMMC/UFS a une augmentation inférieure de 10 %. ▲Source de l'image TrendForce TrendForce a déclaré que l'agence prévoyait initialement de continuer à
 Win11 prend-il moins de mémoire que Win10 ?
Apr 18, 2024 am 12:57 AM
Win11 prend-il moins de mémoire que Win10 ?
Apr 18, 2024 am 12:57 AM
Oui, dans l’ensemble, Win11 consomme moins de mémoire que Win10. Les optimisations incluent un noyau système plus léger, une meilleure gestion de la mémoire, de nouvelles options d'hibernation et moins de processus en arrière-plan. Les tests montrent que l'empreinte mémoire de Win11 est généralement inférieure de 5 à 10 % à celle de Win10 dans des configurations similaires. Mais l'utilisation de la mémoire est également affectée par la configuration matérielle, les applications et les paramètres système.
