
 Périphériques technologiques
IA
LeCun sur la lune ? Nankai et Byte open source StoryDiffusion pour rendre les bandes dessinées multi-images et les longues vidéos plus cohérentes
Périphériques technologiques
IA
LeCun sur la lune ? Nankai et Byte open source StoryDiffusion pour rendre les bandes dessinées multi-images et les longues vidéos plus cohérentes
LeCun sur la lune ? Nankai et Byte open source StoryDiffusion pour rendre les bandes dessinées multi-images et les longues vidéos plus cohérentes

Il y a deux jours, Yann LeCun, lauréat du prix Turing, a republié la longue bande dessinée "Allez sur la Lune et explorez-vous", qui a suscité de vives discussions parmi les internautes.

Dans l'article "Story Diffusion: Consistent Self-Attention for long-range image and video Generation", l'équipe de recherche a proposé une nouvelle méthode appelée Story Diffusion pour générer des images et des vidéos cohérentes pour décrire des situations complexes. Les recherches sur ces bandes dessinées proviennent d'institutions telles que l'Université de Nankai et ByteDance.

- Adresse papier : https://arxiv.org/pdf/2405.01434v1
- Page d'accueil du projet : https://storydiffusion.github.io/
Des projets associés sont déjà en cours GitHub A obtenu un montant de 1 000 étoiles.
Adresse GitHub : https://github.com/HVision-NKU/StoryDiffusion
Selon la démonstration du projet, StoryDiffusion peut générer des bandes dessinées de styles variés, racontant une histoire cohérente tout en conservant la cohérence des personnages. style et vêtements.

StoryDiffusion peut conserver l'identité de plusieurs personnages simultanément et générer des personnages cohérents à travers une série d'images.

De plus, StoryDiffusion est capable de générer des vidéos de haute qualité conditionnées par des images cohérentes générées ou des images saisies par l'utilisateur.


Nous savons que maintenir la cohérence du contenu à travers une série d'images générées, en particulier celles contenant des sujets et des détails complexes, est un défi important pour les modèles génératifs basés sur la diffusion.
Par conséquent, l'équipe de recherche a proposé une nouvelle méthode de calcul de l'auto-attention, appelée Consistent Self-Attention, en établissant des connexions entre les images au sein d'un lot lors de la génération d'images et en générant des images thématiquement cohérentes sans formation.
Afin d'étendre cette méthode à la génération de vidéos longues, l'équipe de recherche a introduit un prédicteur de mouvement sémantique (Semantic Motion Predictor), qui encode les images dans l'espace sémantique et prédit le mouvement dans l'espace sémantique pour générer des vidéos. C’est plus stable que la prédiction de mouvement basée uniquement sur l’espace latent.
Effectuez ensuite l'intégration du framework, combinant une attention personnelle cohérente et des prédicteurs de mouvement sémantique pour générer des vidéos cohérentes et raconter des histoires complexes. StoryDiffusion peut générer des vidéos plus fluides et plus cohérentes que les méthodes existantes.

Figure 1 : Images et vidéos générées par le StroyDiffusion de l'équipe
Aperçu de la méthode
La méthode de l'équipe de recherche peut être divisée en deux étapes, comme le montrent les figures 2 et 3.
Dans la première étape, StoryDiffusion utilise l'auto-attention cohérente pour générer des images cohérentes avec un sujet sans formation. Ces images cohérentes peuvent être utilisées directement dans la narration ou comme contribution à une deuxième étape. Dans un deuxième temps, StoryDiffusion crée des vidéos de transition cohérentes basées sur ces images cohérentes.
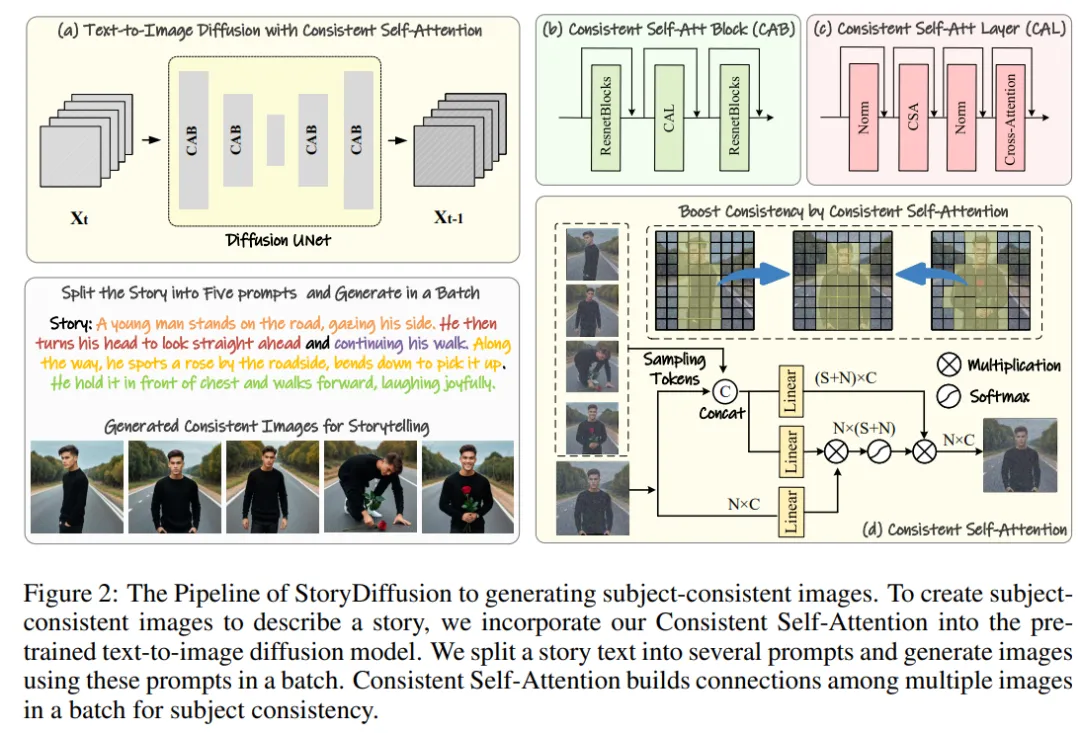
Figure 2 : Présentation du processus StoryDiffusion pour générer des images cohérentes avec un thème
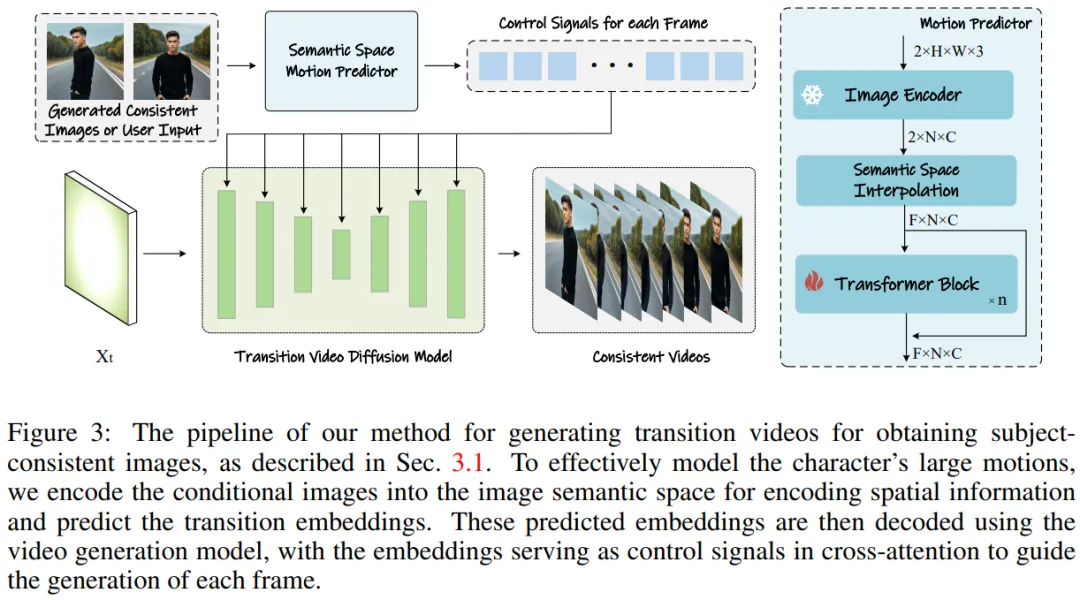 Figure 3 : Méthode de génération de vidéos de transition pour obtenir des images cohérentes avec un thème.
Figure 3 : Méthode de génération de vidéos de transition pour obtenir des images cohérentes avec un thème.
Génération d'images cohérentes sans formation
L'équipe de recherche a introduit la méthode "comment générer des images cohérentes avec un thème sans formation". La clé pour résoudre le problème ci-dessus est de savoir comment maintenir la cohérence des caractères dans un lot d'images. Cela signifie que lors du processus de génération, ils doivent établir des connexions entre un lot d'images.
Après avoir réexaminé le rôle des différents mécanismes d'attention dans le modèle de diffusion, ils ont été inspirés pour explorer l'utilisation de l'auto-attention pour maintenir la cohérence des images au sein d'un lot d'images, et ont proposé une auto-attention cohérente - Attention ).
L'équipe de recherche insère une auto-attention cohérente dans la position d'auto-attention d'origine dans l'architecture U-Net du modèle de génération d'images existant, et réutilise les poids d'auto-attention d'origine pour ne maintenir aucune formation et plug-and-play Fonctionnalités utilisées.
À partir de jetons appariés, la méthode de l’équipe de recherche effectue une auto-attention sur un lot d’images, favorisant les interactions entre les différentes caractéristiques de l’image. Ce type d'interaction entraîne la convergence du modèle sur les personnages, les visages et les vêtements au cours de la génération. Bien que la méthode d’auto-attention cohérente soit simple et ne nécessite aucune formation, elle peut générer efficacement des images thématiquement cohérentes.
Pour illustrer plus clairement, l'équipe de recherche montre le pseudocode dans l'algorithme 1.

Semantic Motion Predictor pour la génération vidéo
L'équipe de recherche a proposé le Semantic Motion Predictor (Semantic Motion Predictor), qui encode les images dans l'espace sémantique de l'image pour capturer des informations spatiales. Cela permet un mouvement plus précis prédiction à partir d’une image de début et d’une image de fin données.
Plus précisément, dans le prédicteur de mouvement sémantique proposé par l'équipe, ils utilisent d'abord une fonction E pour établir un mappage à partir d'images RVB vers des vecteurs d'espace sémantique d'image pour coder des informations spatiales.
L'équipe n'a pas utilisé directement la couche linéaire comme fonction E. Au lieu de cela, elle a utilisé un encodeur d'image CLIP pré-entraîné comme fonction E pour profiter de sa capacité de tir zéro pour améliorer les performances.
À l'aide de la fonction E, la trame de début F_s et la trame de fin données F_e sont compressées en vecteurs d'espace sémantique d'image K_s et K_e.

Résultats expérimentaux
En termes de génération d'images cohérentes avec un sujet, puisque la méthode de l'équipe ne nécessite aucune formation et est plug-and-play, ils ont utilisé deux versions de Stable Diffusion XL et Stable Diffusion 1.5 All mis en œuvre cette méthode. Pour être cohérents avec les modèles comparés, ils ont utilisé les mêmes poids pré-entraînés sur le modèle Stable-XL à des fins de comparaison.
Pour générer des vidéos cohérentes, les chercheurs ont mis en œuvre leur méthode de recherche basée sur le modèle spécialisé Stable Diffusion 1.5 et ont intégré un module temporel pré-entraîné pour prendre en charge la génération de vidéos. Tous les modèles comparés utilisent un score de guidage sans classificateur de 7,5 et un échantillonnage DDIM en 50 étapes.
Comparaison de génération d'images cohérentes
L'équipe a évalué son approche pour générer des images cohérentes par sujet en la comparant à deux méthodes de préservation d'identité de pointe : IP-Adapter et Photo Maker.
Pour tester les performances, ils ont utilisé GPT-4 pour générer vingt instructions de rôle et cent instructions d'activité pour décrire des activités spécifiques.
Les résultats qualitatifs sont présentés dans la figure 4 : "StoryDiffusion est capable de générer des images très cohérentes. Alors que d'autres méthodes, telles que IP-Adapter et PhotoMaker, peuvent produire des images avec des vêtements incohérents ou une contrôlabilité réduite du texte." Figure 4 : Comparaison de la génération d'images cohérentes avec les méthodes actuelles Les chercheurs présentent les résultats de la comparaison quantitative dans le tableau 1. Les résultats montrent : "StoryDiffusion de l'équipe a obtenu les meilleures performances sur les deux mesures quantitatives, indiquant que la méthode peut bien s'adapter à la description de l'invite tout en conservant les caractéristiques des personnages, et montre sa robustesse." génération d'images cohérentes En termes de génération de vidéos de transition, l'équipe de recherche a comparé deux méthodes de pointe - SparseCtrl et SEINE - Des comparaisons ont été faites pour évaluer les performances. Ils ont mené une comparaison qualitative de la génération de vidéos de transition et ont montré les résultats dans la figure 5. Les résultats montrent : "La StoryDiffusion de l'équipe est nettement meilleure que SEINE et SparseCtrl, et la vidéo de transition générée est à la fois fluide et cohérente avec les principes physiques." -méthodes art Comparaison de génération vidéo Ils ont également comparé cette méthode avec SEINE et SparseCtrl et ont utilisé quatre indicateurs quantitatifs, notamment LPIPSfirst, LPIPS-frames, CLIPSIM-first et CLIPSIM-frames, comme indiqué dans le tableau 2. Veuillez vous référer à l'article original pour plus de détails techniques et expérimentaux. 
 Comparaison de la génération de vidéos de transition
Comparaison de la génération de vidéos de transition Tableau 2 : Comparaison quantitative avec le modèle actuel de génération de vidéo de transition de pointe
Tableau 2 : Comparaison quantitative avec le modèle actuel de génération de vidéo de transition de pointe
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravelelognent Model Retrieval: Faconttement l'obtention de données de base de données Eloquentorm fournit un moyen concis et facile à comprendre pour faire fonctionner la base de données. Cet article présentera en détail diverses techniques de recherche de modèles éloquentes pour vous aider à obtenir efficacement les données de la base de données. 1. Obtenez tous les enregistrements. Utilisez la méthode All () pour obtenir tous les enregistrements dans la table de base de données: usApp \ Modèles \ Post; $ poters = post :: all (); Cela rendra une collection. Vous pouvez accéder aux données à l'aide de Foreach Loop ou d'autres méthodes de collecte: ForEach ($ PostsAs $ POST) {echo $ post->
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
