
 Périphériques technologiques
IA
ICLR 2024 Spotlight | L'exploration d'étiquettes négatives facilite les tâches de détection de non-distribution basées sur CLIP
Périphériques technologiques
IA
ICLR 2024 Spotlight | L'exploration d'étiquettes négatives facilite les tâches de détection de non-distribution basées sur CLIP
ICLR 2024 Spotlight | L'exploration d'étiquettes négatives facilite les tâches de détection de non-distribution basées sur CLIP

Alors que les modèles d'apprentissage automatique sont de plus en plus utilisés dans les scénarios de monde ouvert, la manière d'identifier et de traiter efficacement les données hors distribution (OOD) est devenue un domaine de recherche important. La présence de données non distribuées peut conduire à un excès de confiance dans le modèle et à des prédictions incorrectes, ce qui est particulièrement dangereux dans les applications critiques pour la sécurité telles que la conduite autonome et les diagnostics médicaux. Par conséquent, le développement d’un mécanisme de détection OOD efficace est crucial pour améliorer la sécurité et la fiabilité du modèle dans les applications pratiques.
Les méthodes de détection OOD traditionnelles se concentrent principalement sur un seul modèle, en particulier les données d'image, tout en ignorant d'autres sources d'informations potentiellement utiles, telles que les données textuelles. Avec l'essor des modèles de langage visuel (VLM), ils ont démontré de solides performances dans des scénarios d'apprentissage multimodaux, en particulier dans les tâches qui nécessitent une compréhension simultanée des images et des descriptions textuelles associées. Les méthodes de détection OOD existantes basées sur les VLM [3, 4, 5] utilisent uniquement les informations sémantiques des balises d'identification, ignorant la puissante capacité d'échantillon zéro du modèle VLM et l'espace sémantique très large que les VLM peuvent expliquer. Sur cette base, nous pensons que les VLM ont un énorme potentiel inexploité en matière de détection OOD, en particulier parce qu'ils peuvent utiliser de manière exhaustive les informations d'image et de texte pour améliorer les résultats de détection.
Cet article s'articule autour de trois questions :
1. Les informations des balises non-ID sont-elles utiles pour la détection OOD zéro tir ?
2. Comment extraire des informations bénéfiques pour la détection OOD à échantillon nul ?
3. Comment utiliser les informations extraites pour la détection OOD à échantillon nul ?
Dans ce projet, nous proposons une approche innovante appelée NegLabel qui utilise les VLM pour la détection OOD. La méthode NegLabel introduit spécifiquement un mécanisme de « étiquette négative ». Ces étiquettes négatives présentent des différences sémantiques significatives avec les étiquettes de catégorie d'identification connues. En analysant et en comparant l'affinité et la nature des images et des étiquettes d'identification et des étiquettes négatives, NegLabel peut efficacement distinguer les distributions appartenant à. échantillons en dehors du modèle, améliorant ainsi considérablement la capacité du modèle à identifier les échantillons OOD.
NegLabel a atteint des performances supérieures dans plusieurs tests de détection OOD zéro tir. Il peut atteindre 94,21 % AUROC et 25,40 % FPR95 sur des ensembles de données à grande échelle tels que ImageNet-1k. Comparé aux méthodes de détection OOD basées sur les VLM, NegLabel ne nécessite pas seulement de processus de formation supplémentaires, mais affiche également des performances supérieures. De plus, NegLabel fait preuve d’une excellente polyvalence et robustesse sur différentes architectures VLM.

ØLien papier : https://arxiv.org/pdf/2403.20078.pdf
ØLien code : https://github.com/tmlr-group/NegLabel
Je vous le présenterai brièvement ensuite Partager nos résultats de recherche récemment publiés sur la détection hors distribution à l’ICLR 2024.
Connaissances préliminaires

Introduction à la méthode
Le cœur de NegLabel est l'introduction du mécanisme "étiquette négative". Ces étiquettes négatives ont des différences sémantiques significatives avec les étiquettes de catégorie d'identification connues en analysant et en comparant l'image avec l'ID. étiquette et étiquette négative Grâce à son affinité, NegLabel peut distinguer efficacement les échantillons qui appartiennent à des échantillons hors distribution, améliorant ainsi considérablement la capacité du modèle à identifier les échantillons OOD.
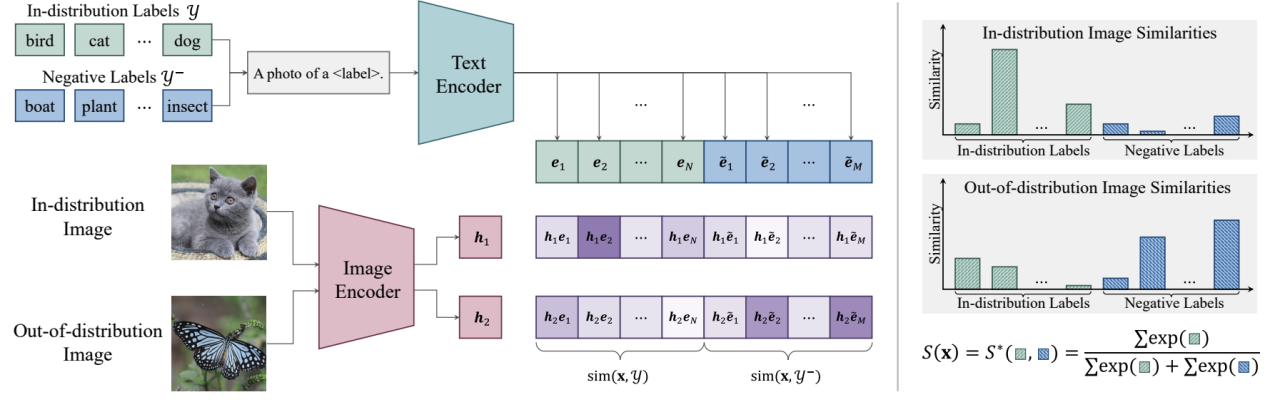
Figure 1. Présentation de NegLabel
1 Comment sélectionner les étiquettes négatives ?

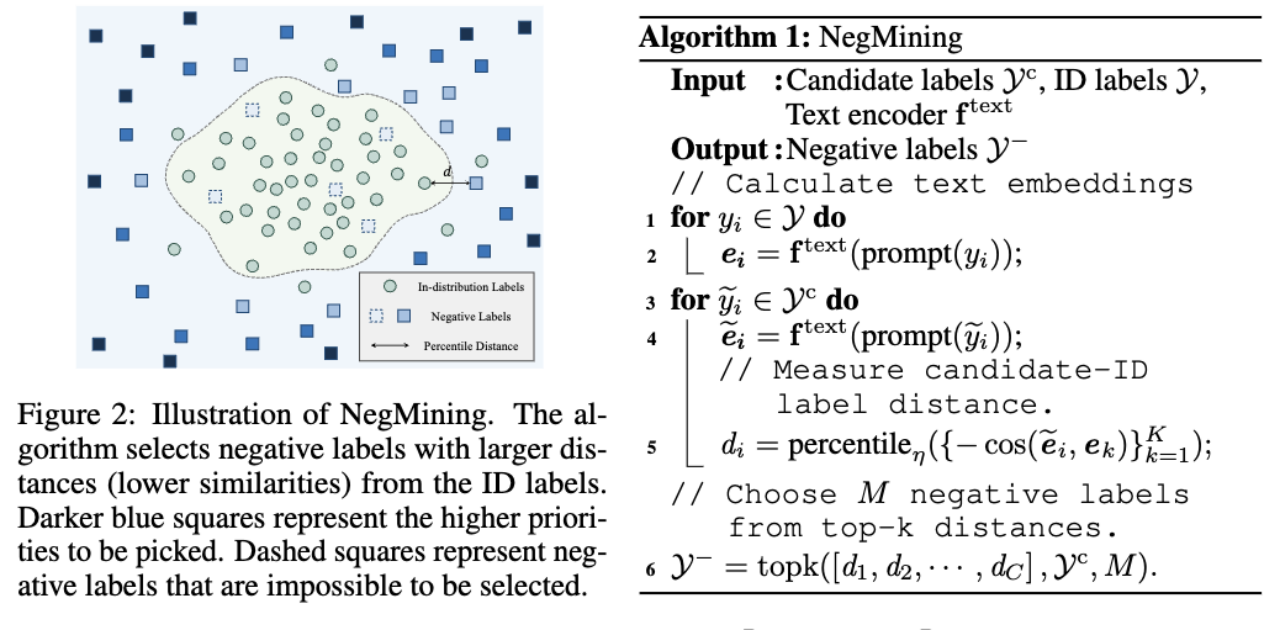
2. Comment utiliser les étiquettes négatives pour la détection OOD ?


3. Comment comprendre que les échantillons négatifs peuvent favoriser la détection OOD sans échantillon ?

Résultats expérimentaux
Nos travaux de recherche fournissent des résultats expérimentaux multidimensionnels pour comprendre les performances et le mécanisme sous-jacent de notre méthode proposée.
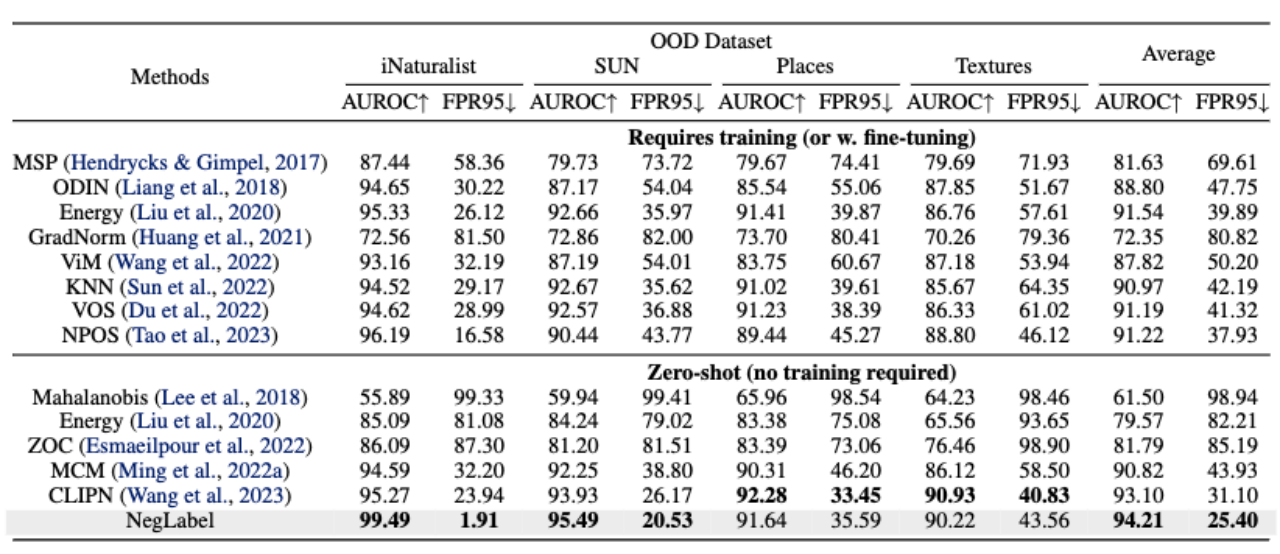
Comme le montre le tableau ci-dessous, par rapport à de nombreuses méthodes de référence et méthodes avancées offrant d'excellentes performances, la méthode proposée dans cet article peut obtenir de meilleurs résultats de détection hors distribution sur des ensembles de données à grande échelle (tels qu'ImageNet).
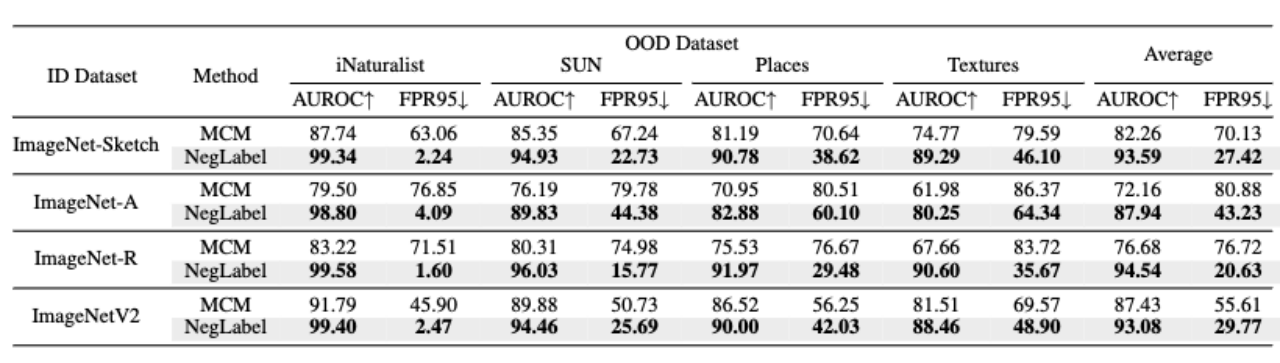
De plus, comme le montre le tableau ci-dessous, la méthode présentée dans cet article présente une meilleure robustesse lorsque les données d'identification subissent une migration de domaine.
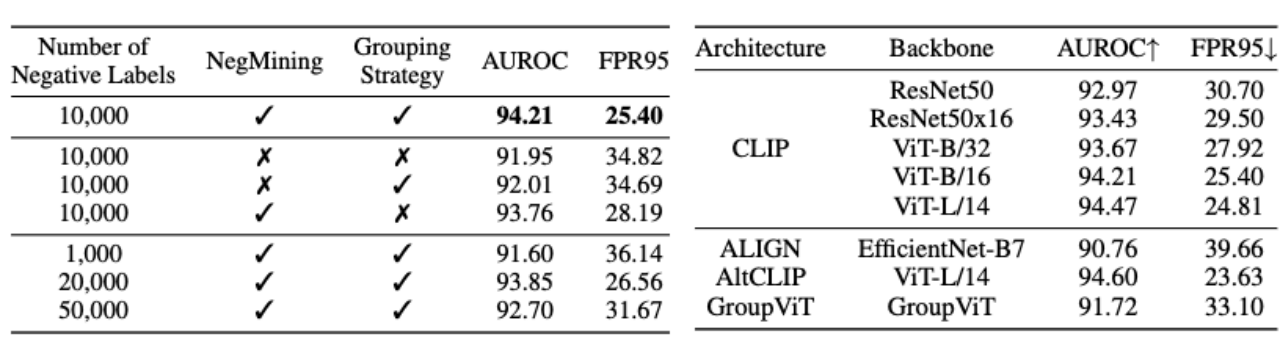
Dans les deux tableaux suivants, nous avons mené des expériences d'ablation sur chaque module de NegLabel et la structure des VLM. Comme le montre le tableau de gauche, l'algorithme NegMining et la stratégie de regroupement peuvent améliorer efficacement les performances de détection OOD. Le tableau de droite montre que l'algorithme NegLabel que nous avons proposé a une bonne adaptabilité aux VLM de différentes structures.
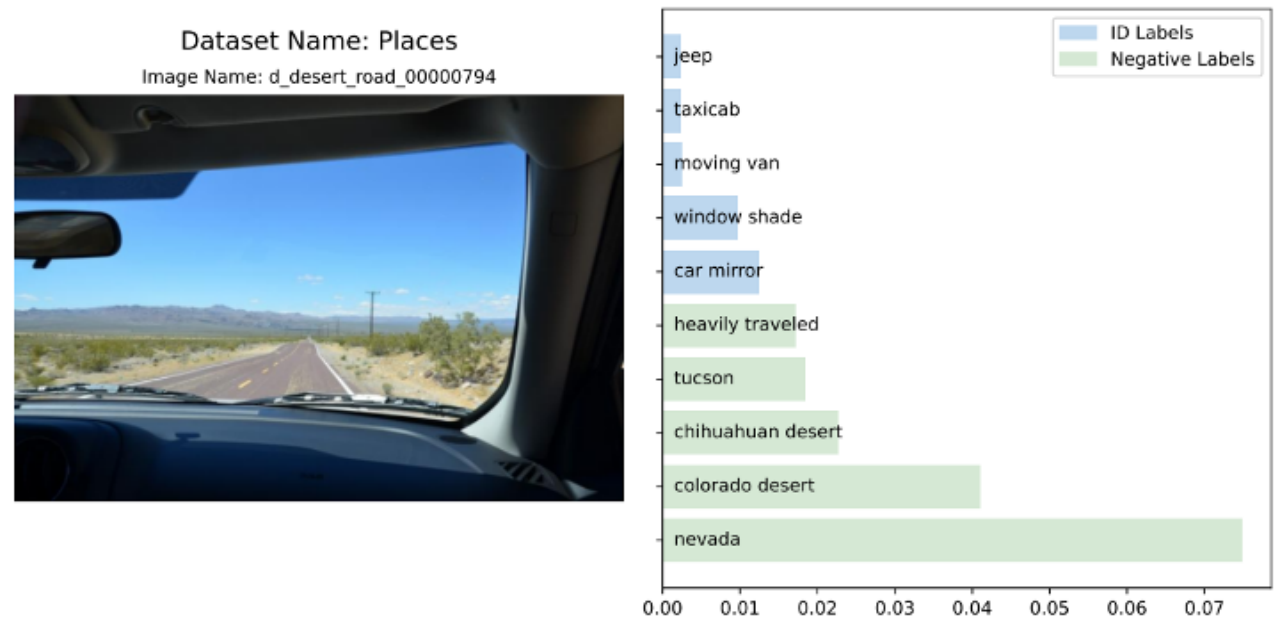
Nous avons également effectué une analyse visuelle de l'affinité de différentes images d'entrée pour les balises d'identification et les balises négatives. Pour des expériences et des résultats plus détaillés, veuillez vous référer à l'article original.

Références
[1] Hendrycks, D. et Gimpel, K. Une base de référence pour détecter les exemples mal classés et hors distribution dans les réseaux de neurones.
[2] Alec. Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Apprentissage de modèles visuels transférables à partir de la supervision du langage naturel.
[ 3] Sepideh Esmaeilpour, Bing Liu, Eric Robertson et Lei Shu. Détection de hors-distribution Zero-shot basée sur le clip du modèle pré-entraîné dans AAAI, 2022.
[4] Yifei Ming, Ziyang Cai, Jiuxiang. Gu, Yiyou Sun, Wei Li et Yixuan Li. Exploration de la détection hors distribution avec des représentations en langage visuel.
[5] Hualiang Wang, Huifeng Yao et Xiaomeng Li. -détection des eaux : Clip pédagogique pour dire non, 2023.
[6] Christiane Fellbaum : Une base de données lexicale électronique, 1998.
.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment se connecter au réseau public du serveur GIT
Apr 17, 2025 pm 02:27 PM
Comment se connecter au réseau public du serveur GIT
Apr 17, 2025 pm 02:27 PM
La connexion d'un serveur GIT au réseau public comprend cinq étapes: 1. Configurer l'adresse IP publique; 2. Ouvrez le port de pare-feu (22, 9418, 80/443); 3. Configurer l'accès SSH (générer des paires de clés, créer des utilisateurs); 4. Configurer l'accès HTTP / HTTPS (installer les serveurs, configurer les autorisations); 5. Testez la connexion (en utilisant les commandes SSH Client ou GIT).
 Comment supprimer un référentiel par git
Apr 17, 2025 pm 04:03 PM
Comment supprimer un référentiel par git
Apr 17, 2025 pm 04:03 PM
Pour supprimer un référentiel GIT, suivez ces étapes: Confirmez le référentiel que vous souhaitez supprimer. Suppression locale du référentiel: utilisez la commande RM -RF pour supprimer son dossier. Supprimer à distance un entrepôt: accédez à l'entrepôt, trouvez l'option "Supprimer l'entrepôt" et confirmez l'opération.
 Comment ajouter des clés publiques au compte GIT
Apr 17, 2025 pm 02:42 PM
Comment ajouter des clés publiques au compte GIT
Apr 17, 2025 pm 02:42 PM
Comment ajouter une clé publique à un compte GIT? Étape: générer une paire de clés SSH. Copiez la clé publique. Ajoutez une clé publique dans Gitlab ou GitHub. Testez la connexion SSH.
 Comment gérer le conflit du code GIT
Apr 17, 2025 pm 02:51 PM
Comment gérer le conflit du code GIT
Apr 17, 2025 pm 02:51 PM
Le conflit de code fait référence à un conflit qui se produit lorsque plusieurs développeurs modifient le même morceau de code et provoquent la fusion de Git sans sélectionner automatiquement les modifications. Les étapes de résolution incluent: ouvrez le fichier contradictoire et découvrez le code contradictoire. Furiez le code manuellement et copiez les modifications que vous souhaitez maintenir dans le marqueur de conflit. Supprimer la marque de conflit. Enregistrer et soumettre des modifications.
 Comment détecter SSH par Git
Apr 17, 2025 pm 02:33 PM
Comment détecter SSH par Git
Apr 17, 2025 pm 02:33 PM
Pour détecter SSH via GIT, vous devez effectuer les étapes suivantes: générer une paire de clés SSH. Ajoutez la clé publique au serveur GIT. Configurez Git pour utiliser SSH. Testez la connexion SSH. Résoudre les problèmes possibles en fonction des conditions réelles.
 Comment séparer Git Commit
Apr 17, 2025 pm 02:36 PM
Comment séparer Git Commit
Apr 17, 2025 pm 02:36 PM
Utilisez GIT pour soumettre le code séparément, en fournissant un suivi granulaire des changements et une capacité de travail indépendante. Les étapes sont les suivantes: 1. Ajouter les fichiers modifiés; 2. Soumettre des modifications spécifiques; 3. Répétez les étapes ci-dessus; 4. Pousser la soumission au référentiel distant.
 Comment construire un serveur GIT
Apr 17, 2025 pm 12:57 PM
Comment construire un serveur GIT
Apr 17, 2025 pm 12:57 PM
La construction d'un serveur GIT comprend: l'installation de GIT sur le serveur. Créer des utilisateurs et des groupes qui exécutent le serveur. Créez un répertoire de référentiel GIT. Initialisez le référentiel nu. Configurer les paramètres de contrôle d'accès. Démarrez le service SSH. Accorder l'accès à l'utilisateur. Tester la connexion.
 Comment générer des clés SSH dans Git
Apr 17, 2025 pm 01:36 PM
Comment générer des clés SSH dans Git
Apr 17, 2025 pm 01:36 PM
Afin de se connecter en toute sécurité à un serveur GIT distant, une clé SSH contenant des clés publiques et privées doit être générée. Les étapes pour générer une touche SSH sont les suivantes: Ouvrez le terminal et entrez la commande ssh-keygen -t rsa -b 4096. Sélectionnez l'emplacement d'enregistrement de la clé. Entrez une phrase de mot de passe pour protéger la clé privée. Copiez la clé publique sur le serveur distant. Enregistrez correctement la clé privée car ce sont les informations d'identification pour accéder au compte.
