
 Périphériques technologiques
IA
58 lignes de code échelle Llama 3 à 1 million de contextes, toute version affinée est applicable
Périphériques technologiques
IA
58 lignes de code échelle Llama 3 à 1 million de contextes, toute version affinée est applicable
58 lignes de code échelle Llama 3 à 1 million de contextes, toute version affinée est applicable

Llama 3, le majestueux roi de l'open source, fenêtre de contexte originale n'a en fait que... 8k, ce qui m'a fait ravaler les mots "ça sent si bon".
À partir de 32k, 100k est courant aujourd'hui. Est-ce intentionnel de laisser de la place aux contributions à la communauté open source ?
La communauté open source n'a certainement pas manqué cette opportunité :
Désormais, avec seulement 58 lignes de code, toute version affinée de Llama 3 70b peut automatiquement évoluer jusqu'à 1048k (un million) contexte.
Derrière se trouve un LoRA, extrait d'une version affinée de Llama 3 70B Instruct qui étend un bon contexte, Le fichier ne fait que 800 Mo.
Ensuite, en utilisant Mergekit, vous pouvez l'exécuter avec d'autres modèles de la même architecture ou le fusionner directement dans le modèle.
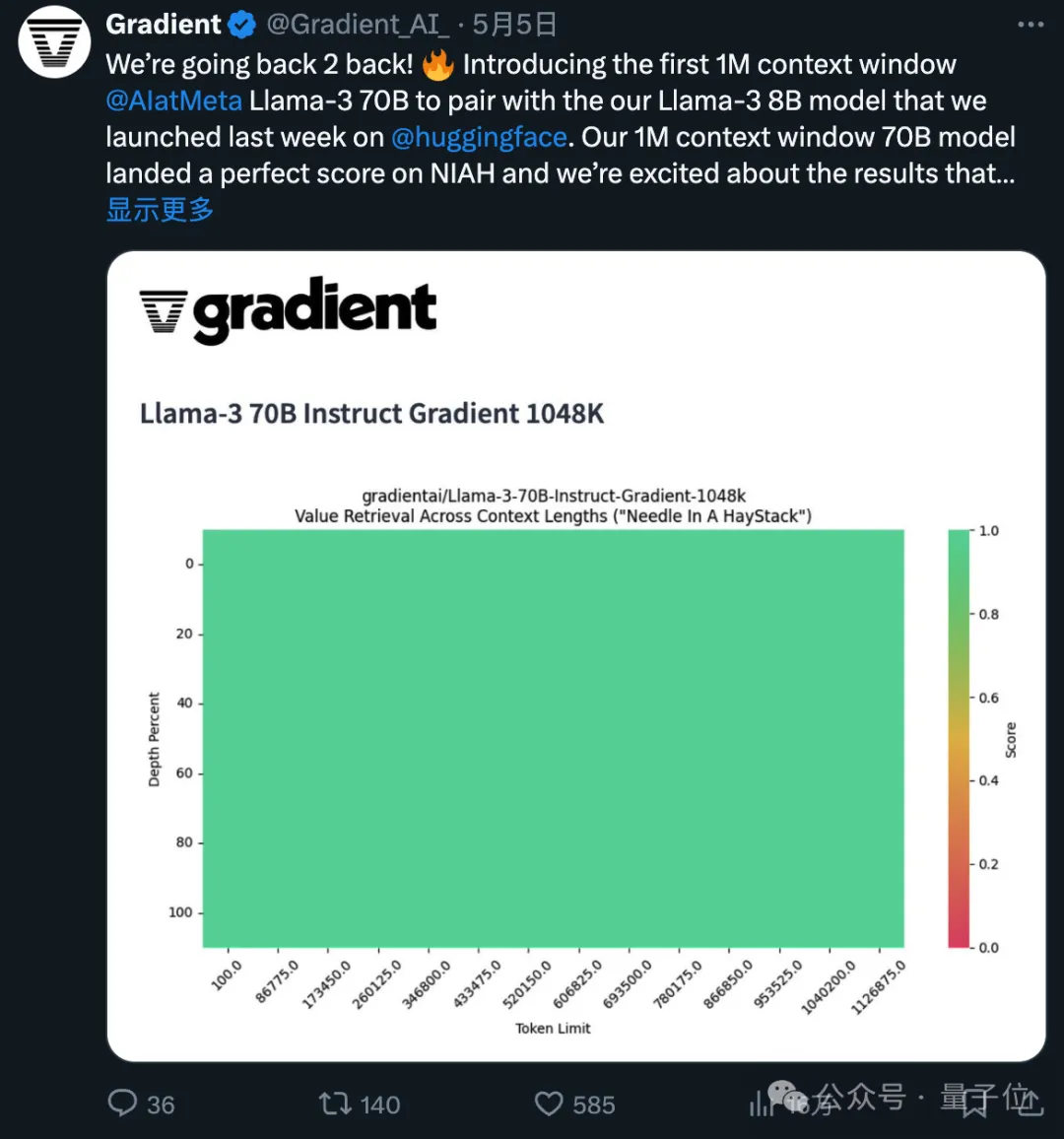
La version affinée du contexte 1048k utilisé vient d'obtenir un score entièrement vert (100 % de précision) au populaire test de l'aiguille dans une botte de foin.
Je dois dire que la vitesse de progression de l'open source est exponentielle.
Comment la LoRA contextuelle 1048k a été créée
Tout d'abord, la version contextuelle 1048k du modèle affiné de Llama 3 provient de Gradient AI, une startup de solutions d'IA d'entreprise.

La LoRA correspondante provient du développeur Eric Hartford En comparant les différences entre le modèle affiné et la version originale, les modifications des paramètres sont extraites.
Il a d'abord produit une version contextuelle 524k, puis a mis à jour la version 1048k.
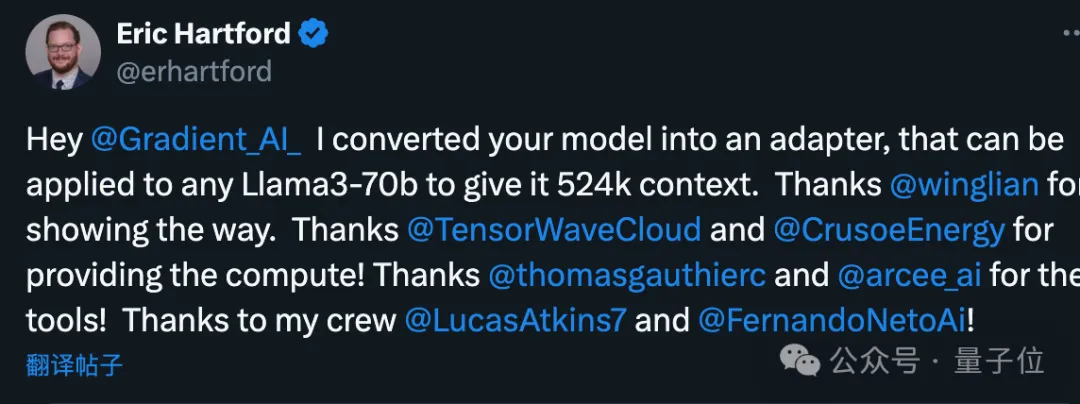
Tout d'abord, l'équipe Gradient a continué sa formation basée sur le Llama 3 70B Instruct original et a obtenu Llama-3-70B-Instruct-Gradient-1048k.
La méthode spécifique est la suivante :
- Ajuster l'encodage de position : Utilisez l'interpolation compatible NTK pour initialiser la planification optimale de RoPE theta et l'optimiser pour éviter la perte d'informations haute fréquence après l'extension de la length
- Formation progressive : Utilisez la méthode Blockwise RingAttention proposée par l'équipe Pieter Abbeel de l'UC Berkeley pour étendre la longueur du contexte du modèle
Il convient de noter que l'équipe a superposé la parallélisation au-dessus de Ring Attention grâce à une topologie de réseau personnalisée pour mieux utiliser les clusters GPU à grande échelle, ils sont utilisés pour gérer les goulots d'étranglement du réseau causés par le transfert de nombreux blocs KV entre appareils.
En fin de compte, la vitesse d'entraînement du modèle est augmentée de 33 fois.
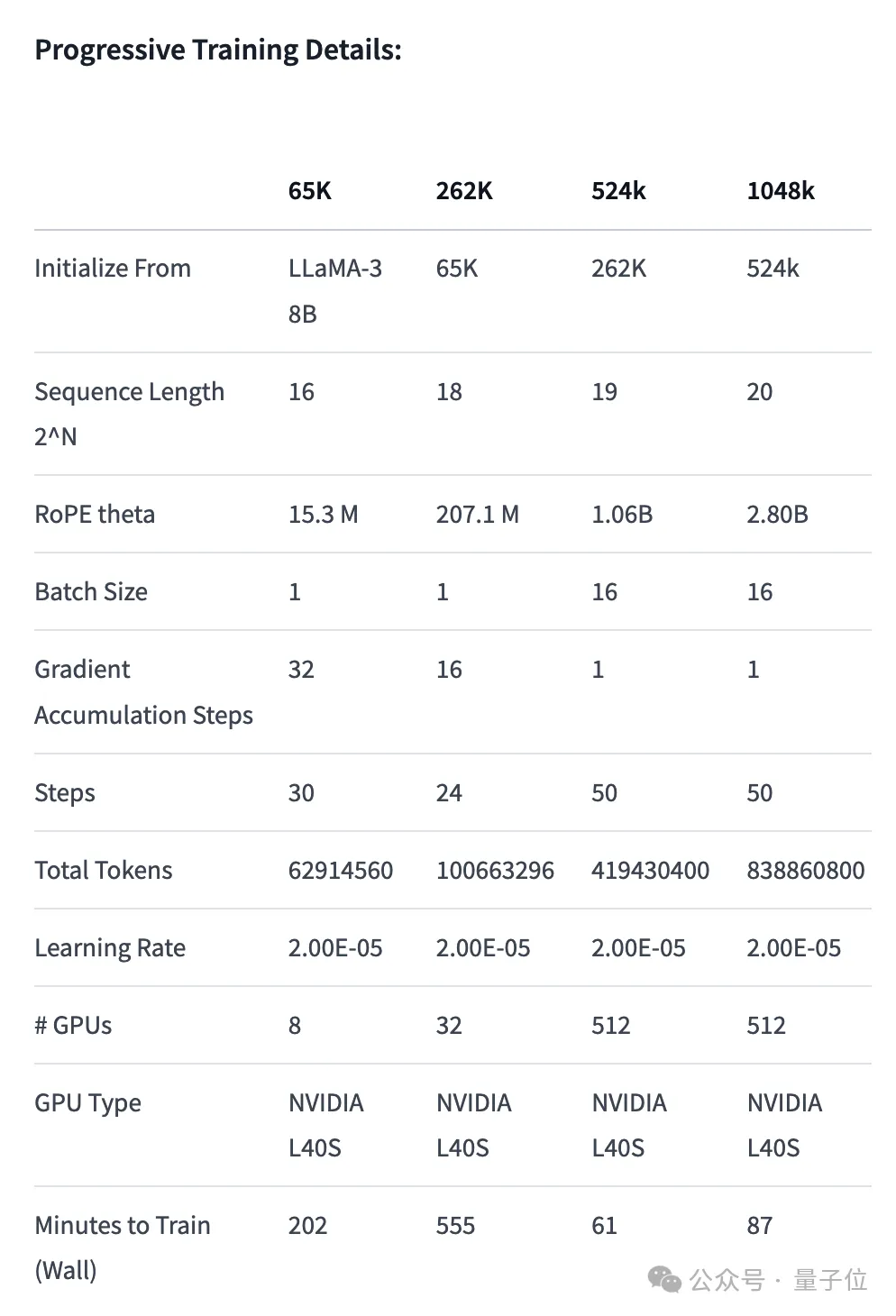
Dans l'évaluation des performances de récupération de texte long, uniquement dans la version la plus difficile, des erreurs sont susceptibles de se produire lorsque « l'aiguille » est cachée au milieu du texte.

Après avoir affiné le modèle avec un contexte étendu, utilisez l'outil open source Mergekit pour comparer le modèle affiné et le modèle de base, et extraire la différence de paramètres pour devenir LoRA.
En utilisant également Mergekit, vous pouvez fusionner la LoRA extraite dans d'autres modèles avec la même architecture.
Le code de fusion est également open source sur GitHub par Eric Hartford et ne fait que 58 lignes.
On ne sait pas si cette fusion LoRA fonctionnera avec Llama 3, qui est affiné sur le chinois.
Cependant, on constate que la communauté des développeurs chinois a prêté attention à ce développement.
Version 524k LoRA : https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-524k-adapter
Version 1048k LoRA : https://huggingface.co/ cognitivecomputations/Llama-3-70B-Gradient-1048k-adapter
Code de fusion : https://gist.github.com/ehartford/731e3f7079db234fa1b79a01e09859ac
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Il existe de nombreuses façons d'installer Deepseek, notamment: Compiler à partir de Source (pour les développeurs expérimentés) en utilisant des packages précompilés (pour les utilisateurs de Windows) à l'aide de conteneurs Docker (pour le plus pratique, pas besoin de s'inquiéter de la compatibilité), quelle que soit la méthode que vous choisissez, veuillez lire Les documents officiels documentent soigneusement et les préparent pleinement à éviter des problèmes inutiles.
 Résumé des FAQ pour une utilisation profonde
Feb 19, 2025 pm 03:45 PM
Résumé des FAQ pour une utilisation profonde
Feb 19, 2025 pm 03:45 PM
Deepseekai Tool User Guide et FAQ Deepseek est un puissant outil intelligent AI. FAQ: La différence entre les différentes méthodes d'accès: il n'y a pas de différence de fonction entre la version Web, la version de l'application et les appels API, et l'application n'est qu'un wrapper pour la version Web. Le déploiement local utilise un modèle de distillation, qui est légèrement inférieur à la version complète de Deepseek-R1, mais le modèle 32 bits a théoriquement une capacité de version complète de 90%. Qu'est-ce qu'une taverne? SillyTavern est une interface frontale qui nécessite d'appeler le modèle AI via l'API ou le olllama. Qu'est-ce que la limite de rupture
 Quels sont les outils d'IA ?
Nov 29, 2024 am 11:11 AM
Quels sont les outils d'IA ?
Nov 29, 2024 am 11:11 AM
Les outils d'IA incluent : Doubao, ChatGPT, Gemini, BlenderBot, etc.
 Quels sont les fonds de fiducie de cryptage en niveaux de gris?
Mar 05, 2025 pm 12:33 PM
Quels sont les fonds de fiducie de cryptage en niveaux de gris?
Mar 05, 2025 pm 12:33 PM
Investissement en niveaux de gris: le canal des investisseurs institutionnels pour entrer sur le marché des crypto-monnaies. La société a lancé plusieurs fiducies cryptographiques, ce qui a attiré une attention généralisée, mais l'impact de ces fonds sur les prix des jetons varie considérablement. Cet article présentera en détail certains des principaux fonds de fiducie de crypto de Graycale. Grayscale Major Crypto Trust Funds disponibles dans un investissement GrayScale GRAYS (fondée par DigitalCurrencyGroup en 2013) gère une variété de fonds fiduciaires d'actifs cryptographiques, fournissant des investisseurs institutionnels et des particuliers élevés avec des canaux d'investissement conformes. Ses principaux fonds comprennent: ZCash (Zec), Sol,
 Alors que les principaux marchands entrent sur le marché de la cryptographie, quel impact sur les titres de château auront-ils sur l'industrie?
Mar 04, 2025 pm 08:03 PM
Alors que les principaux marchands entrent sur le marché de la cryptographie, quel impact sur les titres de château auront-ils sur l'industrie?
Mar 04, 2025 pm 08:03 PM
L'entrée des principaux acteurs du marché Castle Securities dans Bitcoin Market Maker est un symbole de la maturité du marché Bitcoin et une étape clé pour les forces financières traditionnelles pour concurrencer le pouvoir de tarification des actifs. Le 25 février, selon Bloomberg, Citadel Securities cherche à devenir un fournisseur de liquidité pour les crypto-monnaies. La société vise à rejoindre la liste des fabricants de marché sur divers échanges, y compris les échanges exploités par CoinbaseGlobal, Binanceholdings et Crypto.com, ont déclaré des personnes familières avec l'affaire. Une fois approuvé par l'échange, la société prévoyait initialement de créer une équipe de fabricants de marchés en dehors des États-Unis. Ce mouvement n'est pas seulement un signe
 Delphi Digital: Comment changer la nouvelle économie d'IA en analysant la nouvelle architecture Elizaos V2?
Mar 04, 2025 pm 07:00 PM
Delphi Digital: Comment changer la nouvelle économie d'IA en analysant la nouvelle architecture Elizaos V2?
Mar 04, 2025 pm 07:00 PM
ElizaOSV2: L'autonomisation de l'IA et de la direction de la nouvelle économie de WEB3. Cet article plongera dans les principales innovations d'ElizaOSV2 et comment elle façonne une économie future axée sur l'IA. Automatisation de l'IA: Aller exploiter indépendamment Elizaos était à l'origine un cadre d'IA axé sur l'automatisation Web3. La version V1 permet à l'IA d'interagir avec les contrats intelligents et les données de la blockchain, tandis que la version V2 atteint des améliorations de performances significatives. Au lieu d'exécuter simplement des instructions simples, l'IA peut gérer indépendamment les workflows, exploiter des affaires et développer des stratégies financières. Mise à niveau de l'architecture: amélioré un
 Dépassant considérablement la SFT, le secret derrière O1 / Deepseek-R1 peut également être utilisé dans les grands modèles multimodaux
Mar 12, 2025 pm 01:03 PM
Dépassant considérablement la SFT, le secret derrière O1 / Deepseek-R1 peut également être utilisé dans les grands modèles multimodaux
Mar 12, 2025 pm 01:03 PM
Des chercheurs de l'Université de Shanghai Jiaotong, de Shanghai Ailab et de l'Université chinoise de Hong Kong ont lancé le projet open source Visual-RFT (visual d'amélioration), qui ne nécessite qu'une petite quantité de données pour améliorer considérablement les performances du gros modèle de langage visuel (LVLM). Visual-RFT combine intelligemment l'approche d'apprentissage en renforcement basée sur les règles de Deepseek-R1 avec le paradigme de relâchement de renforcement d'OpenAI (RFT), prolongeant avec succès cette approche du champ de texte au champ visuel. En concevant les récompenses de règles correspondantes pour des tâches telles que la sous-catégorisation visuelle et la détection d'objets, Visual-RFT surmonte les limites de la méthode Deepseek-R1 limitée au texte, au raisonnement mathématique et à d'autres domaines, fournissant une nouvelle façon de formation LVLM. Vis
 Bitwise: les entreprises achètent un bitcoin une grande tendance négligée
Mar 05, 2025 pm 02:42 PM
Bitwise: les entreprises achètent un bitcoin une grande tendance négligée
Mar 05, 2025 pm 02:42 PM
Observation hebdomadaire: les entreprises thésaurisation du Bitcoin - un changement de brassage que je souligne souvent certaines tendances du marché négligées dans des mémos hebdomadaires. Le mouvement de Microstrategy est un exemple brutal. Beaucoup de gens peuvent dire: "Microstrategy et Michaelsaylor sont déjà bien connus, à quoi allez-vous faire attention?" Cette vue est unilatérale. Des recherches approfondies sur l'adoption du bitcoin en tant qu'actif de réserve au cours des derniers mois montrent qu'il ne s'agit pas d'un cas isolé, mais d'une tendance majeure qui émerge. Je prédis qu'au cours des 12 à 18 prochains mois, des centaines d'entreprises suivront le pas et achèteront de grandes quantités de Bitcoin
