
 Périphériques technologiques
IA
LeCun relayé, l'IA permet aux aphasiques de reprendre la parole ! NYU lance un nouveau décodeur de « parole neuronale »
Périphériques technologiques
IA
LeCun relayé, l'IA permet aux aphasiques de reprendre la parole ! NYU lance un nouveau décodeur de « parole neuronale »
LeCun relayé, l'IA permet aux aphasiques de reprendre la parole ! NYU lance un nouveau décodeur de « parole neuronale »

Le développement de l'interface cerveau-ordinateur (BCI) dans le domaine de la recherche et des applications scientifiques a récemment fait l'objet d'une large attention. Les gens sont généralement curieux des perspectives d'application de la BCI.
L'aphasie causée par des anomalies du système nerveux entrave non seulement gravement la vie quotidienne des patients, mais peut également limiter leur évolution de carrière et leurs activités sociales. Avec le développement rapide de l’apprentissage profond et de la technologie d’interface cerveau-ordinateur, la science moderne s’oriente vers l’aide aux personnes aphasiques à retrouver leurs capacités de communication grâce à des prothèses vocales neuronales.
Le cerveau humain a réalisé une série de développements passionnants, et il y a eu de nombreuses percées dans le décodage des signaux dans la parole, les opérations, etc. Il convient particulièrement de mentionner que la société Neuralink d’Elon Musk a également réalisé des progrès décisifs dans ce domaine, avec le développement révolutionnaire de la technologie d’interface cérébrale.
La société a implanté avec succès des électrodes dans le cerveau d'un sujet de test, permettant la saisie, les jeux et d'autres fonctions grâce à de simples opérations de curseur. Cela marque une autre étape vers un décodage neuro-vocal/moteur d’une plus grande complexité. Comparé à d’autres technologies d’interface cerveau-ordinateur, le décodage de la neuro-parole est plus complexe et ses travaux de recherche et développement reposent principalement sur une source de données spéciale : l’électrocorticographie (ECoG).
Au lit, je m'occupe principalement des données du dossier électrodermique reçues pendant le processus de récupération du patient. Les chercheurs ont utilisé ces électrodes pour collecter des données sur l’activité cérébrale lors des vocalisations. Ces données ont non seulement un degré élevé de résolution temporelle et spatiale, mais ont également obtenu des résultats remarquables dans la recherche sur le décodage de la parole, favorisant grandement le développement de la technologie d'interface cerveau-ordinateur. Grâce à ces technologies avancées, nous devrions voir davantage de personnes atteintes de troubles neurologiques retrouver la liberté de communiquer à l’avenir.
Une percée a été réalisée dans une étude récente publiée dans Nature, qui a utilisé les caractéristiques HuBERT quantifiées comme représentations intermédiaires sur un patient avec un dispositif implanté, combinées à un synthétiseur vocal pré-entraîné pour convertir ces caractéristiques en parole. La méthode améliore non seulement le naturel de la parole, mais maintient également une grande précision.
Cependant, les fonctionnalités HuBERT ne peuvent pas capturer les caractéristiques acoustiques uniques du locuteur, et le son généré est généralement la voix unifiée du locuteur. Des modèles supplémentaires sont donc encore nécessaires pour convertir ce son universel en la voix spécifique d'un patient.
Un autre point remarquable est que cette étude et la plupart des tentatives précédentes ont adopté une architecture non causale, ce qui peut limiter son utilisation pratique dans les applications d'interface cerveau-ordinateur qui nécessitent des opérations causales.
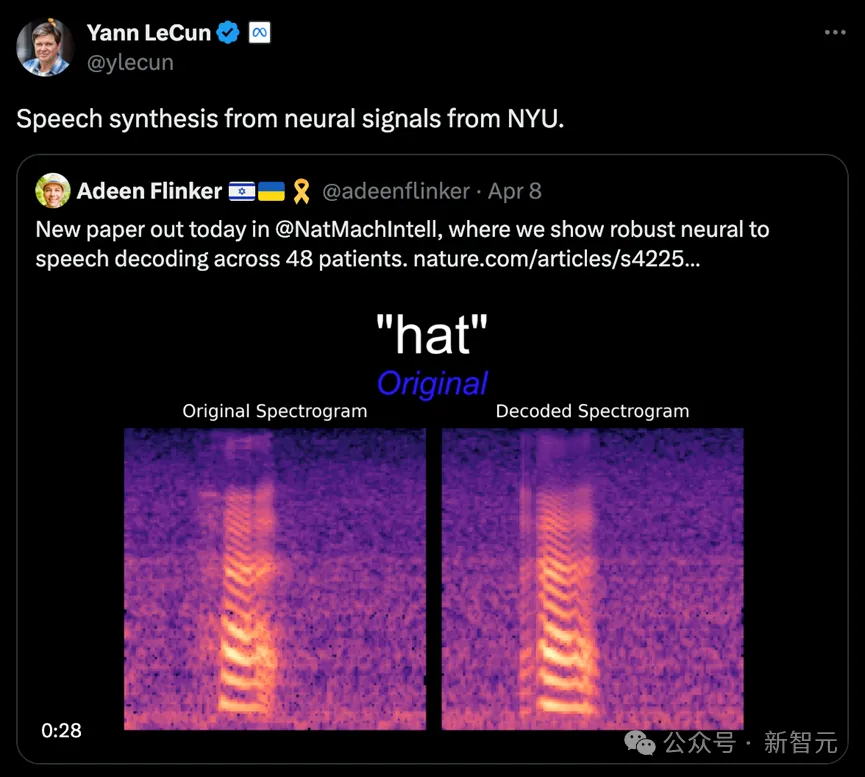
Le 8 avril 2024, le VideoLab de l'Université de New York et le Flinker Lab ont publié conjointement une recherche révolutionnaire dans le magazine « Nature Machine Intelligence ».
 Photos
Photos
Lien papier : https://www.nature.com/articles/s42256-024-00824-8
Recherche de code open source associé sur https://github.com/flinkerlab/ neural_speech_decoding
Plus d'exemples de parole générée sur : https://xc1490.github.io/nsd/
Cette recherche, intitulée "Un cadre de décodage de la parole neuronale exploitant l'apprentissage en profondeur et la synthèse vocale", présente une innovation Synthétiseur vocal différenciable .
Ce synthétiseur combine un réseau neuronal convolutif léger, qui peut coder la parole en une série de paramètres vocaux interprétables, tels que la hauteur, le volume et la fréquence des formants, et utiliser une technologie différentiable pour re-synthétiser la parole.
Cette étude a réussi à construire un système de décodage neuronal de la parole hautement interprétable et applicable à de petits ensembles de données en mappant les signaux neuronaux à ces paramètres vocaux spécifiques. Ce système peut non seulement reconstruire une parole haute fidélité et naturelle, mais également fournir une base empirique pour une grande précision dans les futures applications d’interface cerveau-ordinateur.
L'équipe de recherche a collecté des données sur un total de 48 sujets et, sur cette base, a tenté de décoder la parole, jetant ainsi une base solide pour l'application pratique et le développement d'une technologie d'interface cerveau-ordinateur de haute précision.
Lecun, lauréat du prix Turing, a également fait part des progrès de la recherche.
 Photos
Photos
État de la recherche
Dans la recherche actuelle sur le décodage du signal neuronal vers la parole, il y a deux défis principaux.
La première est la limitation du volume de données : afin d'entraîner un modèle personnalisé de décodage neuronal-parole, le temps total de données disponible pour chaque patient n'est généralement qu'une dizaine de minutes, ce qui est très limité pour les modèles d'apprentissage profond. qui reposent sur de grandes quantités de données d’entraînement. Une contrainte importante.
Deuxièmement, la grande diversité de la parole humaine augmente également la complexité de la modélisation. Même si la même personne prononce et épelle le même mot à plusieurs reprises, des facteurs tels que sa vitesse de parole, son intonation et sa hauteur peuvent changer, ajoutant ainsi une difficulté supplémentaire à la construction du modèle.
Dans les premières tentatives, les chercheurs ont principalement utilisé des modèles linéaires pour décoder les signaux neuronaux en parole. Ce type de modèle ne nécessite pas la prise en charge d’un énorme ensemble de données et présente une forte interprétabilité, mais sa précision est généralement faible.
Récemment, avec les progrès de la technologie d'apprentissage profond, en particulier l'application du réseau neuronal convolutif (CNN) et du réseau neuronal récurrent (RNN), les chercheurs ont progressé dans la simulation de la représentation latente intermédiaire de la parole et dans l'amélioration de la qualité de la parole synthétisée. discours. Essayez-le largement.
Par exemple, certaines études décodent l'activité du cortex cérébral en mouvements de la bouche, puis les convertissent en parole. Bien que cette méthode soit plus puissante en termes de performances de décodage, la voix reconstruite ne semble souvent pas assez naturelle.
De plus, certaines nouvelles méthodes tentent d'utiliser le vocodeur Wavenet et le réseau contradictoire génératif (GAN) pour reconstruire une parole naturelle. Bien que ces méthodes puissent améliorer le naturel du son, leur précision est encore limitée.
Cadre du modèle principal
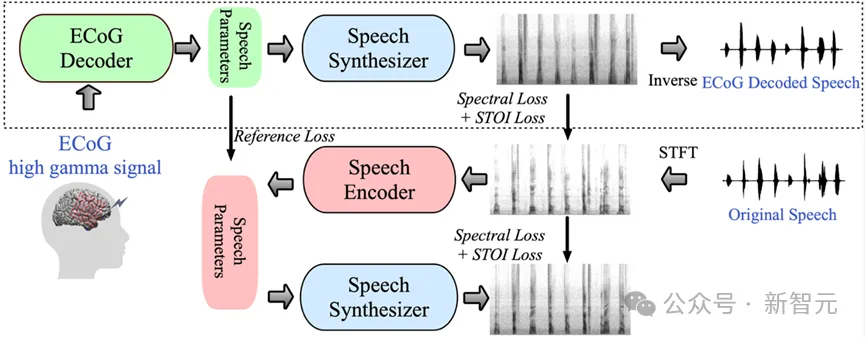
Dans cette étude, l'équipe de recherche a démontré un cadre de décodage innovant des signaux de l'électroencéphalogramme (ECoG) à la parole. Ils ont construit un espace de représentation latente de faible dimension généré par un modèle léger de codage et de décodage de la parole utilisant uniquement des signaux vocaux.
Ce cadre contient deux parties principales : premièrement, le décodeur ECoG, qui est chargé de convertir le signal ECoG en une série de paramètres de parole acoustique compréhensibles, tels que la hauteur, s'il est prononcé, le volume et la fréquence des formants, etc. ; deuxièmement, la partie synthétiseur vocal chargée de convertir ces paramètres en spectrogramme.
En construisant un synthétiseur vocal différentiable, les chercheurs ont pu entraîner le décodeur ECoG tout en optimisant le synthétiseur vocal pour réduire conjointement l'erreur de reconstruction du spectrogramme. La forte interprétabilité de cet espace latent de faible dimension, combinée aux paramètres vocaux de référence générés par le codeur vocal léger pré-entraîné, rend l'ensemble du cadre de décodage neuronal de la parole efficace et adaptable, résolvant efficacement le problème de la rareté des données dans ce domaine.
De plus, ce framework peut non seulement générer une parole naturelle très proche du locuteur, mais prend également en charge l'insertion de plusieurs architectures de modèles d'apprentissage profond dans la partie décodeur ECoG et peut effectuer des opérations causales.
L'équipe de recherche a traité les données ECoG de 48 patients en neurochirurgie et a utilisé diverses architectures d'apprentissage profond (y compris la convolution, le réseau neuronal récurrent et le transformateur) pour réaliser le décodage ECoG.
Ces modèles ont montré une grande précision dans les expériences, en particulier celles utilisant l'architecture convolutive ResNet. Ce cadre de recherche permet non seulement d'obtenir une grande précision grâce à des opérations causales et un taux d'échantillonnage relativement faible (espacement de 10 mm), mais démontre également la capacité de décoder efficacement la parole des hémisphères gauche et droit du cerveau, étendant ainsi la portée des applications de l'analyse neuronale. décodage de la parole Du côté droit du cerveau.
 Pictures
Pictures
L'une des principales innovations de cette recherche est le développement d'un synthétiseur vocal différenciable, qui améliore considérablement l'efficacité de la resynthèse vocale et peut synthétiser un son haute fidélité proche de l'original. son .
La conception de ce synthétiseur vocal s'inspire du système vocal humain et subdivise la parole en deux parties : Voix (principalement utilisée pour la simulation des voyelles) et Non-voix (principalement utilisée pour la simulation des consonnes).
Dans la partie Voix, le signal de fréquence fondamentale est d'abord utilisé pour générer des harmoniques, puis passé à travers un filtre composé de formants F1 à F6 pour obtenir les caractéristiques spectrales des voyelles.
Pour la partie Unvoice, le spectre correspondant est généré en effectuant un filtrage spécifique sur le bruit blanc. Un paramètre apprenable contrôle le rapport de mélange des deux parties à chaque instant.
Enfin, le spectre vocal final est généré en ajustant le signal sonore et en ajoutant du bruit de fond.
Sur la base de ce synthétiseur vocal, l'équipe de recherche a conçu un cadre de resynthèse vocale efficace et un cadre de décodage neuronal de la parole. Pour la structure détaillée du cadre, veuillez vous référer à la figure 6 de l'article original.
Résultats de la recherche
1. Résultats du décodage vocal avec causalité temporelle
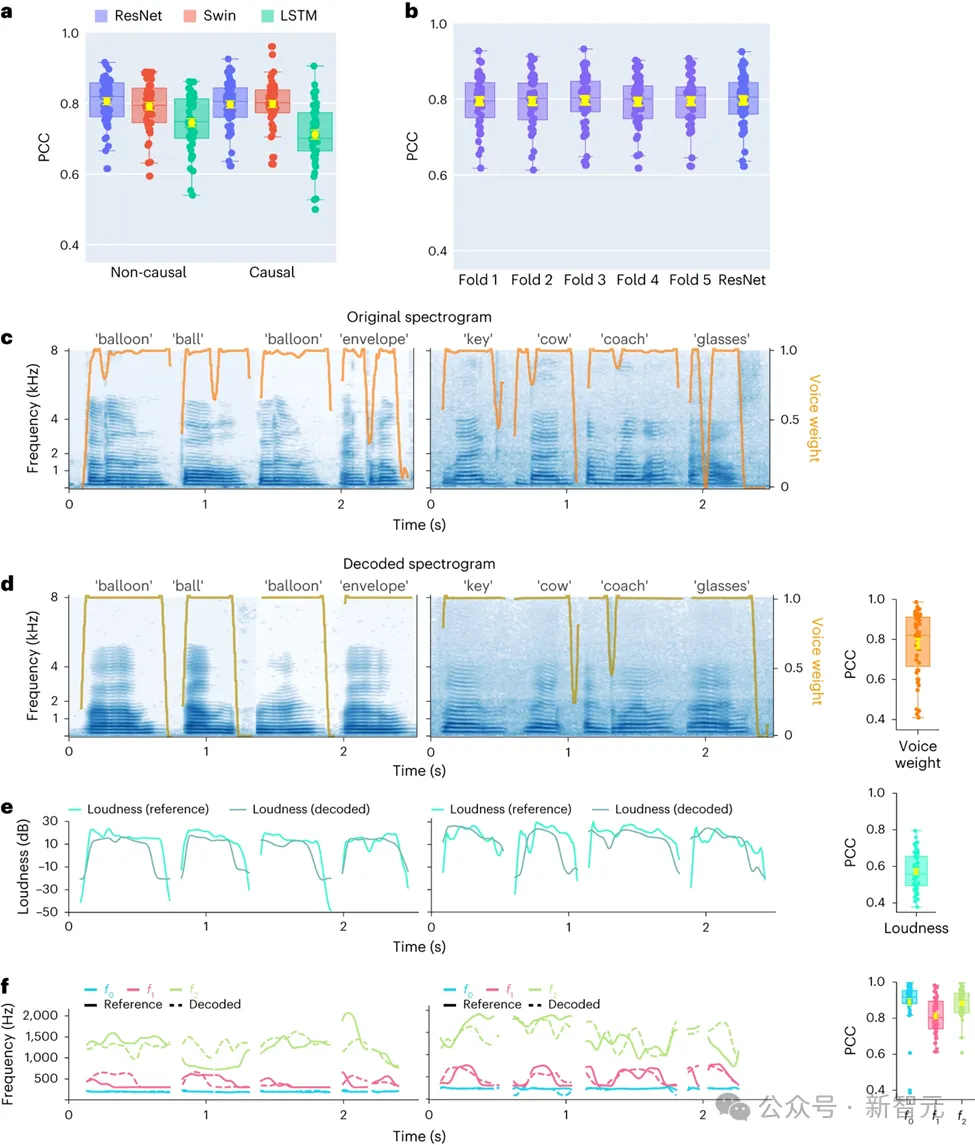
Dans cette étude, les chercheurs ont d'abord comparé directement différentes architectures de modèles, notamment les réseaux convolutifs (ResNet), les réseaux neuronaux récurrents (LSTM) et l'architecture de transformateur ( 3D Swin) pour évaluer leurs différences dans les performances de décodage vocal.
Il convient de noter que ces modèles peuvent effectuer des opérations causales ou causales sur des séries chronologiques.
 Images
Images
Dans l'application de l'interface cerveau-ordinateur (BCI), la causalité des modèles de décodage est d'une grande importance : les modèles causals utilisent uniquement des signaux neuronaux passés et actuels pour générer la parole, et non la cause et effet Le modèle fait également référence à de futurs signaux neuronaux, ce qui n'est pas réalisable en pratique.
Par conséquent, l'objectif de l'étude est de comparer les performances du même modèle lors de l'exécution d'opérations causales et non causales. Les résultats montrent que même la version causale du modèle ResNet a des performances comparables à la version non causale, sans différence de performances significative entre les deux.
De même, les versions causales et non causales du modèle Swin ont des performances similaires, mais la version causale du LSTM est nettement inférieure à sa version non causale. L'étude a également démontré une précision de décodage moyenne (nombre total de 48 échantillons) pour plusieurs paramètres vocaux clés, notamment le poids sonore (un paramètre qui distingue les voyelles des consonnes), l'intensité sonore, la fréquence fondamentale f0, le premier formant f1 et le deuxième formant f2.
La reconstruction précise de ces paramètres vocaux, en particulier la fréquence fondamentale, le poids sonore et les deux premiers formants, est essentielle pour obtenir un décodage précis de la parole et une reproduction naturelle de la voix du participant.
Les résultats de la recherche montrent que les modèles non causals et causals peuvent fournir des effets de décodage raisonnables, ce qui constitue une source d'inspiration positive pour de futures recherches et applications connexes.
2. Recherche sur le décodage de la parole et le taux d'échantillonnage spatial des signaux neuronaux des cerveaux gauche et droit
Dans la dernière étude, les chercheurs ont exploré plus en détail la différence de performance dans le décodage de la parole entre les hémisphères cérébraux gauche et droit.
Traditionnellement, la plupart des recherches se sont concentrées sur l'hémisphère gauche, qui est étroitement lié aux fonctions de la parole et du langage.
 Photos
Photos
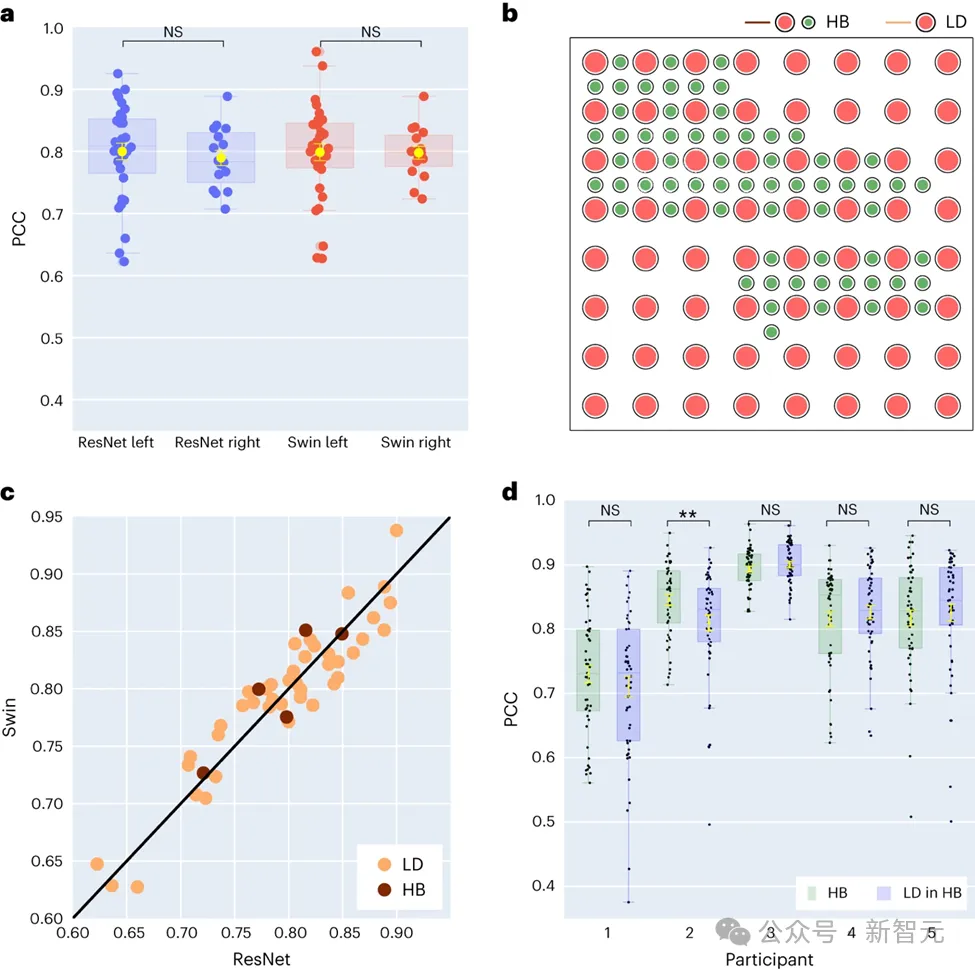
Cependant, notre compréhension de la capacité de l’hémisphère droit du cerveau à décoder les informations verbales est limitée. Pour explorer ce domaine, l'équipe de recherche a comparé les performances de décodage des hémisphères gauche et droit des participants, vérifiant ainsi la faisabilité d'utiliser l'hémisphère droit pour la récupération de la parole.
Parmi les 48 sujets collectés dans l'étude, 16 avaient des signaux ECoG provenant du cerveau droit. En comparant les performances des décodeurs ResNet et Swin, les chercheurs ont découvert que l’hémisphère droit peut également décoder efficacement la parole et que son effet est similaire à celui de l’hémisphère gauche. Cette découverte offre une option possible de restauration du langage pour les patients présentant des lésions du côté gauche du cerveau et ayant perdu la fonction du langage.
La recherche porte également sur l'impact de la densité d'échantillonnage des électrodes sur l'effet de décodage de la parole. Les études antérieures utilisaient principalement des grilles d'électrodes de plus haute densité (0,4 mm), tandis que la densité des grilles d'électrodes couramment utilisées en pratique clinique est plus faible (1 cm).
Cinq participants à cette étude ont utilisé des grilles d'électrodes de type hybride (HB), qui sont principalement de faible densité mais avec quelques électrodes supplémentaires ajoutées. Un échantillonnage de faible densité a été utilisé pour les quarante-trois participants restants.
Les résultats montrent que les performances de décodage de ces échantillonnages hybrides (HB) sont similaires à celles de l'échantillonnage à faible densité (LD) traditionnel, ce qui indique que le modèle peut apprendre efficacement des informations vocales à partir de différentes densités de grilles d'électrodes du cortex cérébral. Cette découverte suggère que les densités d’échantillonnage des électrodes couramment utilisées en milieu clinique pourraient être suffisantes pour prendre en charge les futures applications d’interface cerveau-ordinateur.
3. Recherche sur la contribution de différentes zones cérébrales des cerveaux gauche et droit au décodage de la parole
Les chercheurs ont également exploré le rôle des zones cérébrales liées à la parole dans le processus de décodage de la parole, ce qui pourrait avoir des implications. pour le cerveau gauche et droit du futur Les implants hémisphériques d'appareils de restauration de la parole revêtent une grande importance. Pour évaluer l'impact de différentes régions du cerveau sur le décodage de la parole, l'équipe de recherche a utilisé l'analyse d'occlusion.
En comparant les modèles causals et non causals des décodeurs ResNet et Swin, l'étude a révélé que dans le modèle non causal, le rôle du cortex auditif est plus important. Ce résultat met en évidence la nécessité d’utiliser des modèles causals dans des applications de décodage de la parole en temps réel qui ne peuvent pas s’appuyer sur de futurs signaux de neurofeedback.
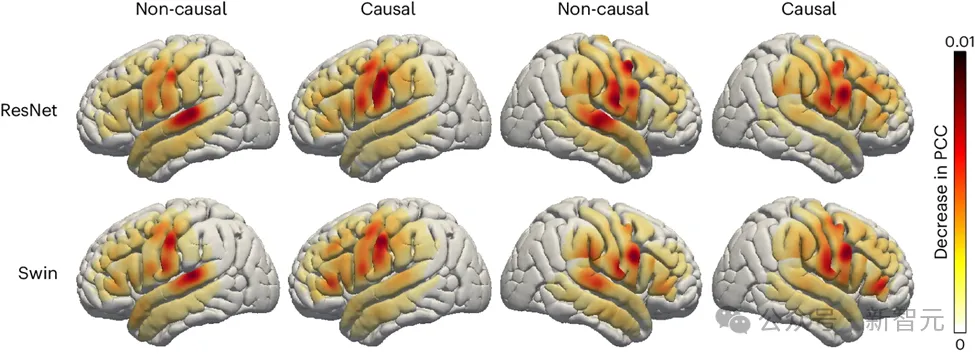 photos
photos
De plus, les recherches montrent également que la contribution du cortex sensorimoteur, notamment de la zone abdominale, au décodage de la parole est similaire que ce soit dans l'hémisphère gauche ou droit du cerveau. Cette découverte suggère que l'implantation d'une prothèse neurologique dans l'hémisphère droit pour restaurer la parole pourrait être une option viable, fournissant des informations importantes sur les futures stratégies de traitement.
Conclusion (Perspectives inspirantes)
L'équipe de recherche a développé un nouveau type de synthétiseur vocal différenciable qui utilise un réseau neuronal convolutif léger pour coder la parole en une série de paramètres interprétables, tels que la hauteur phonétique, l'intensité sonore et la fréquence des formants. , etc., et utilisez le même synthétiseur différentiable pour re-synthétiser la parole.
En mappant les signaux neuronaux sur ces paramètres, les chercheurs ont construit un système de décodage neuronal de la parole hautement interprétable et applicable à de petits ensembles de données, capable de générer une parole à consonance naturelle.
Ce système a montré un haut degré de reproductibilité parmi 48 participants, a pu traiter des données avec différentes densités d'échantillonnage spatial et a pu traiter simultanément les signaux EEG des hémisphères cérébraux gauche et droit, démontrant sa capacité à effectuer une parole excellente. potentiel de décodage.
Malgré des progrès significatifs, les chercheurs ont également souligné certaines limites actuelles du modèle, comme le processus de décodage reposant sur des données d'entraînement à la parole associées à des enregistrements ECoG, qui pourraient ne pas être applicables aux personnes aphasiques.
À l'avenir, l'équipe de recherche espère établir une architecture modèle capable de gérer des données hors grille et d'utiliser plus efficacement les données EEG multi-patients et multimodales. Avec l'avancement continu de la technologie matérielle et le développement rapide de la technologie d'apprentissage profond, la recherche dans le domaine de l'interface cerveau-ordinateur en est encore à ses débuts, mais au fil du temps, la vision de l'interface cerveau-ordinateur dans les films de science-fiction va progressivement devenir une réalité.
Références :
https://www.nature.com/articles/s42256-024-00824-8
Premier auteur de cet article : Xupeng Chen (xc1490@nyu.edu), Ran Wang, Auteur correspondant : Adeen Flinker
Pour plus de discussions sur la causalité dans le décodage neuronal de la parole, veuillez vous référer à un autre article des auteurs :
https://www.pnas.org/doi/10.1073/pnas.2300255120
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1209
24
52
1209
24

 WEB3 Trading Platform Ranking_Web3 Global Exchanges Top Ten Résumé
Apr 21, 2025 am 10:45 AM
WEB3 Trading Platform Ranking_Web3 Global Exchanges Top Ten Résumé
Apr 21, 2025 am 10:45 AM
Binance est le suzerain de l'écosystème mondial de trading d'actifs numériques, et ses caractéristiques comprennent: 1. Le volume de négociation quotidien moyen dépasse 150 milliards de dollars, prend en charge 500 paires de négociation, couvrant 98% des monnaies grand public; 2. La matrice d'innovation couvre le marché des dérivés, la mise en page Web3 et le système éducatif; 3. Les avantages techniques sont des moteurs de correspondance d'une milliseconde, avec des volumes de traitement de pointe de 1,4 million de transactions par seconde; 4. Conformité Progress détient des licences de 15 pays et établit des entités conformes en Europe et aux États-Unis.
 Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
Prévisions des prix WorldCoin (WLD) 2025-2031: WLD atteindra-t-il 4 $ d'ici 2031?
Apr 21, 2025 pm 02:42 PM
WorldCoin (WLD) se démarque sur le marché des crypto-monnaies avec ses mécanismes uniques de vérification biométrique et de protection de la vie privée, attirant l'attention de nombreux investisseurs. WLD a permis de se produire avec remarquablement parmi les Altcoins avec ses technologies innovantes, en particulier en combinaison avec la technologie d'Intelligence artificielle OpenAI. Mais comment les actifs numériques se comporteront-ils au cours des prochaines années? Prédons ensemble le prix futur de WLD. Les prévisions de prix de 2025 WLD devraient atteindre une croissance significative de la WLD en 2025. L'analyse du marché montre que le prix moyen du WLD peut atteindre 1,31 $, avec un maximum de 1,36 $. Cependant, sur un marché baissier, le prix peut tomber à environ 0,55 $. Cette attente de croissance est principalement due à WorldCoin2.
 Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Classement des échanges à effet de levier dans le cercle des devises Les dernières recommandations des dix premiers échanges à effet de levier dans le cercle des devises
Apr 21, 2025 pm 11:24 PM
Les plates-formes qui ont des performances exceptionnelles dans le commerce, la sécurité et l'expérience utilisateur en effet de levier en 2025 sont: 1. OKX, adaptés aux traders à haute fréquence, fournissant jusqu'à 100 fois l'effet de levier; 2. Binance, adaptée aux commerçants multi-monnaies du monde entier, offrant un effet de levier 125 fois élevé; 3. Gate.io, adapté aux joueurs de dérivés professionnels, fournissant 100 fois l'effet de levier; 4. Bitget, adapté aux novices et aux commerçants sociaux, fournissant jusqu'à 100 fois l'effet de levier; 5. Kraken, adapté aux investisseurs stables, fournissant 5 fois l'effet de levier; 6. BUTBIT, adapté aux explorateurs Altcoin, fournissant 20 fois l'effet de levier; 7. Kucoin, adapté aux commerçants à faible coût, fournissant 10 fois l'effet de levier; 8. Bitfinex, adapté au jeu senior
 Que signifie la transaction transversale? Quelles sont les transactions transversales?
Apr 21, 2025 pm 11:39 PM
Que signifie la transaction transversale? Quelles sont les transactions transversales?
Apr 21, 2025 pm 11:39 PM
Échanges qui prennent en charge les transactions transversales: 1. Binance, 2. UniSwap, 3. Sushiswap, 4. Curve Finance, 5. Thorchain, 6. 1inch Exchange, 7. DLN Trade, ces plateformes prennent en charge les transactions d'actifs multi-chaînes via diverses technologies.
 Top 10 plates-formes d'échange de crypto-monnaie La plus grande liste de changes numériques au monde
Apr 21, 2025 pm 07:15 PM
Top 10 plates-formes d'échange de crypto-monnaie La plus grande liste de changes numériques au monde
Apr 21, 2025 pm 07:15 PM
Les échanges jouent un rôle essentiel sur le marché des crypto-monnaies d'aujourd'hui. Ce ne sont pas seulement des plateformes pour les investisseurs pour négocier, mais aussi des sources importantes de liquidité du marché et la découverte des prix. Les plus grands échanges de devises virtuels au monde se classent parmi les dix premiers, et ces échanges sont non seulement bien en avance dans le volume des échanges, mais présentent également leurs propres avantages dans l'expérience utilisateur, la sécurité et les services innovants. Les échanges qui dépassent la liste ont généralement une grande base d'utilisateurs et une influence approfondie du marché, et leur volume de trading et leurs types d'actifs sont souvent difficiles à atteindre par d'autres échanges.
 Aavenomics est une recommandation pour modifier le jeton Aave Protocol et introduire le rachat de jetons, qui a atteint le nombre de personnes quorum.
Apr 21, 2025 pm 06:24 PM
Aavenomics est une recommandation pour modifier le jeton Aave Protocol et introduire le rachat de jetons, qui a atteint le nombre de personnes quorum.
Apr 21, 2025 pm 06:24 PM
Aavenomics est une proposition de modification du jeton de protocole Aave et d'introduire des dépens de jetons, qui a mis en œuvre un quorum pour Aavedao. Marc Zeller, fondateur de l'Aave Project Chain (ACI), l'a annoncé sur X, notant qu'il marque une nouvelle ère pour l'accord. Marc Zeller, fondateur de l'Aave Chain Initiative (ACI), a annoncé sur X que la proposition d'Aavenomics comprend la modification du jeton Aave Protocol et l'introduction de dépens de jetons, a obtenu un quorum pour Aavedao. Selon Zeller, cela marque une nouvelle ère pour l'accord. Les membres d'Aavedao ont voté massivement pour soutenir la proposition, qui était de 100 par semaine mercredi
 Quelles sont les plateformes de trading de blockchain hybrides?
Apr 21, 2025 pm 11:36 PM
Quelles sont les plateformes de trading de blockchain hybrides?
Apr 21, 2025 pm 11:36 PM
Suggestions de choix d'un échange de crypto-monnaie: 1. Pour les exigences de liquidité, la priorité est Binance, Gate.io ou Okx, en raison de sa profondeur de commande et de sa forte résistance à la volatilité. 2. Conformité et sécurité, Coinbase, Kraken et Gemini ont une approbation réglementaire stricte. 3.
 Quelles sont les dix principales plates-formes du cercle d'échange de devises?
Apr 21, 2025 pm 12:21 PM
Quelles sont les dix principales plates-formes du cercle d'échange de devises?
Apr 21, 2025 pm 12:21 PM
Les principaux échanges comprennent: 1. Binance, le plus grand volume de trading au monde, prend en charge 600 devises et les frais de gestion des points sont de 0,1%; 2. Okx, une plate-forme équilibrée, prend en charge 708 paires de trading, et les frais de traitement des contrats perpétuels sont de 0,05%; 3. Gate.io, couvre 2700 petites monnaies, et les frais de traitement des points sont de 0,1% à 0,3%; 4. Coinbase, la référence de conformité américaine, les frais de traitement des points sont de 0,5%; 5. Kraken, la haute sécurité et l'audit de réserve régulière.
