
 Périphériques technologiques
IA
Jetez un œil au passé et au présent de l'Occ et de la conduite autonome ! La première revue résume de manière exhaustive les trois thèmes majeurs de l'amélioration des fonctionnalités/déploiement en production de masse/annotation efficace.
Périphériques technologiques
IA
Jetez un œil au passé et au présent de l'Occ et de la conduite autonome ! La première revue résume de manière exhaustive les trois thèmes majeurs de l'amélioration des fonctionnalités/déploiement en production de masse/annotation efficace.
Jetez un œil au passé et au présent de l'Occ et de la conduite autonome ! La première revue résume de manière exhaustive les trois thèmes majeurs de l'amélioration des fonctionnalités/déploiement en production de masse/annotation efficace.

Écrit devant et compréhension personnelle de l'auteur
Ces dernières années, la conduite autonome a attiré de plus en plus d'attention en raison de son potentiel à réduire la charge du conducteur et à améliorer la sécurité de conduite. La prédiction d'occupation tridimensionnelle basée sur la vision est une tâche de perception émergente adaptée à une enquête rentable et complète sur la sécurité de la conduite autonome. Bien que de nombreuses études aient démontré la supériorité des outils de prédiction d’occupation 3D par rapport aux tâches de perception centrée sur les objets, il existe encore des revues dédiées à ce domaine en développement rapide. Cet article présente d'abord le contexte de la prédiction d'occupation 3D basée sur la vision et discute des défis rencontrés dans cette tâche. Ensuite, nous discutons de manière approfondie de l'état actuel et des tendances de développement des méthodes actuelles de prévision d'occupation 3D sous trois aspects : l'amélioration des fonctionnalités, la convivialité du déploiement et l'efficacité de l'étiquetage. Enfin, les tendances actuelles de la recherche sont résumées et des perspectives d'avenir encourageantes sont proposées.
Lien open source : https://github.com/zya3d/Awesome-3D-Occupancy-Prediction
En résumé, les principales contributions de cet article sont les suivantes :
- Pour autant que nous le sachions, cet article est le premier Un examen complet des méthodes de prédiction d'occupation 3D basées sur la vision pour la conduite autonome.
- Cet article fournit un résumé structurel des méthodes de prédiction d'occupation tridimensionnelle basées sur la vision sous trois perspectives : l'amélioration des fonctionnalités, la convivialité de calcul et l'efficacité des étiquettes, et effectue une analyse approfondie et une comparaison des différentes catégories de méthodes.
- Cet article présente quelques perspectives d'avenir inspirantes pour la prévision d'occupation 3D basée sur la vision et fournit un référentiel github régulièrement mis à jour pour collecter des articles, des ensembles de données et des codes pertinents.
La figure 3 montre un aperçu temporel des méthodes de prédiction d'occupation 3D basées sur la vision, et la figure 4 montre la taxonomie de la structure hiérarchique correspondante.
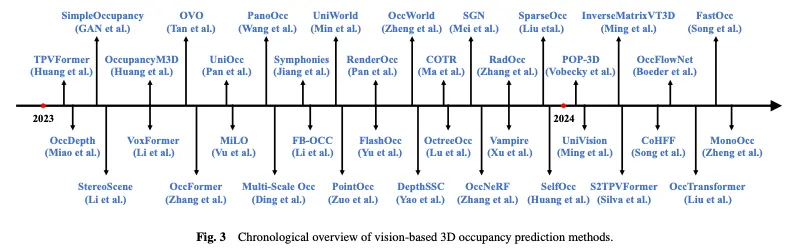
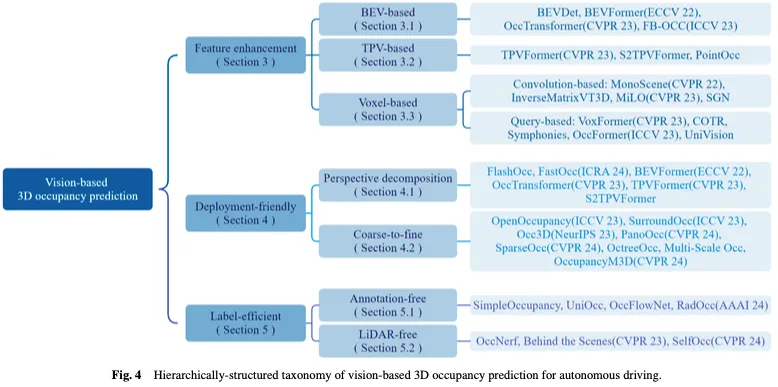
Contexte connexe
Génération de valeur réelle
La génération d'étiquettes GT est un défi pour la prévision d'occupation en 3D. Bien que de nombreux ensembles de données de perception 3D, tels que nuScenes et Waymo, fournissent des étiquettes de segmentation des nuages de points lidar, ces étiquettes sont rares et difficiles à superviser des tâches denses de prédiction d'occupation 3D. L'importance d'utiliser une occupation dense comme étiquette GT a été démontrée par Wei et al. Certaines recherches récentes se concentrent sur la génération d'étiquettes d'occupation denses à l'aide d'annotations de segmentation de nuages de points lidar clairsemées, fournissant des ensembles de données et des références utiles pour les tâches de prédiction d'occupation 3D.
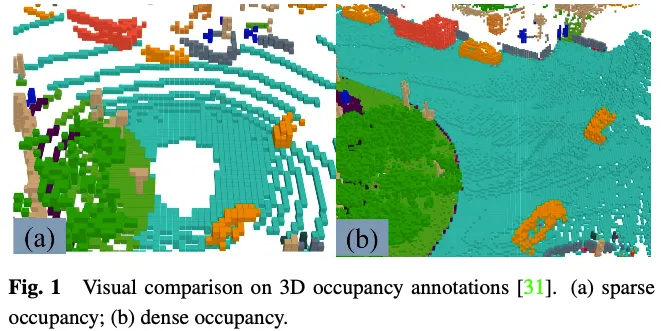
L'étiquette GT dans la tâche de prédiction d'occupation 3D indique si chaque élément de l'espace 3D est occupé et l'étiquette sémantique de l'élément occupé. En raison du grand nombre d’éléments dans l’espace tridimensionnel, il est difficile d’étiqueter manuellement chaque élément. Une approche courante consiste à voxéliser la vérité terrain des tâches de segmentation de nuages de points 3D existantes, puis à générer des GT pour les prédictions d'occupation 3D via un vote basé sur les étiquettes sémantiques des points médians des voxels. Cependant, la vérité terrain générée de cette manière est en réalité simplifiée. Comme le montre la figure 1, il existe encore de nombreux éléments occupés dans des endroits tels que les routes qui ne sont pas signalés comme occupés. Les outils de supervision dotés de modèles avec cette réalité de terrain simplifiée entraîneront une dégradation des performances du modèle. Par conséquent, certains travaillent sur la manière de générer automatiquement ou semi-automatiquement des annotations d’occupation 3D denses de haute qualité.
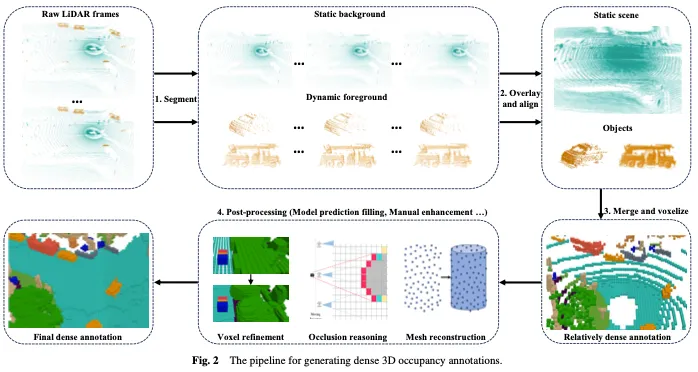
Comme le montre la figure 2, la génération d'annotations d'occupation 3D denses comprend généralement les quatre étapes suivantes :
- Prenez des images lidar brutes continues et segmentez les points lidar en arrière-plan statique et en premier plan dynamique.
- Superposez des images lidar continues sur un arrière-plan statique et effectuez une compensation de mouvement en fonction des informations de positionnement pour aligner les nuages de points multi-images afin d'obtenir des nuages de points plus denses. Des images lidar continues sont superposées au premier plan dynamique, et le nuage de points du premier plan dynamique est aligné en fonction de l'image cible et de l'identifiant de la cible pour le rendre plus dense. Notez que bien que le nuage de points soit relativement dense, il reste encore quelques lacunes après la voxélisation qui nécessitent un traitement ultérieur.
- Fusionnez les nuages de points de premier plan et d'arrière-plan, puis voxélisez-les et utilisez un mécanisme de vote pour déterminer la sémantique des voxels, ce qui donne des annotations de voxels relativement denses.
- Les voxels obtenus à l'étape précédente sont affinés par post-traitement pour obtenir des annotations plus denses et plus fines comme GT.
Ensembles de données
Dans cette section, nous introduisons certains ensembles de données open source à grande échelle couramment utilisés pour la prévision d'occupation 3D, et une comparaison entre eux est donnée dans le tableau 1.
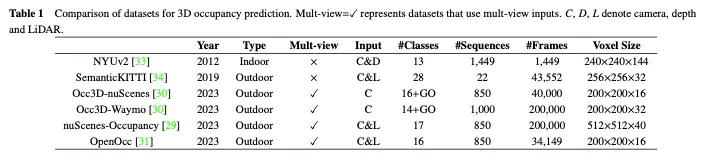
L'ensemble de données NUYv2 se compose de séquences vidéo de diverses scènes intérieures, capturées par les caméras RVB et Depth de Microsoft Kinect. Il contient 1 449 paires d'images RVB et de profondeur alignées densément étiquetées, et 407 024 images non étiquetées provenant de 3 villes. Bien que principalement destiné à une utilisation en intérieur et non adapté aux scénarios de conduite autonome, certaines études ont utilisé cet ensemble de données pour la prédiction d'occupation en 3D.
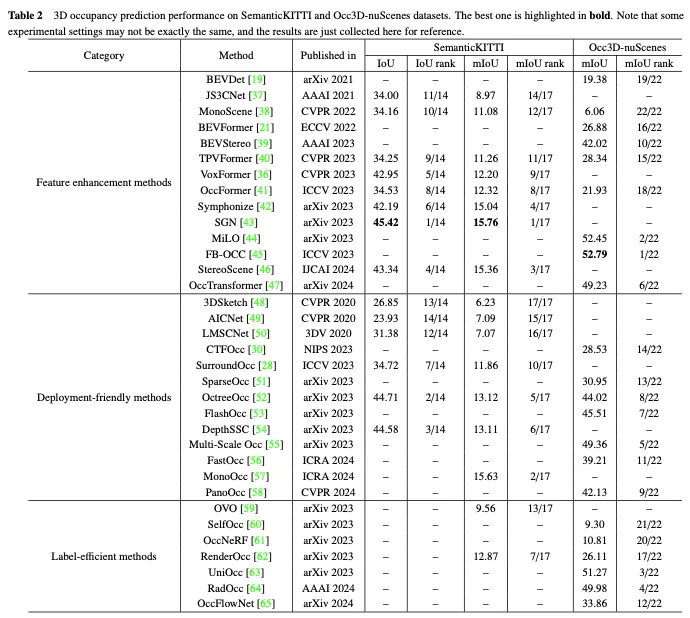
SemanticKITTI est un ensemble de données largement utilisé pour la prédiction d'occupation 3D, comprenant 22 séquences et plus de 43 000 images de l'ensemble de données KITTI. Il crée des annotations d'occupation 3D denses en superposant les futures images, en segmentant les voxels et en attribuant des étiquettes via un vote par points. De plus, il trace les rayons pour examiner pour chaque pose de la voiture quels voxels sont visibles par le capteur, et ignore les voxels invisibles pendant l'entraînement et l'évaluation. Cependant, comme il est basé sur l'ensemble de données KITTI, il utilise uniquement les images de la caméra frontale comme entrée, tandis que les ensembles de données suivants utilisent généralement des images multi-vues. Comme le montre le tableau 2, nous avons collecté les résultats d'évaluation des méthodes existantes sur l'ensemble de données SemanticKITTI.
L'occupation NuScenes est un ensemble de données de prédiction d'occupation 3D basé sur NuScenes, un ensemble de données de conduite autonome à grande échelle dans des environnements extérieurs. Il contient 850 séquences, 200 000 frames et 17 catégories sémantiques. L'ensemble de données utilise initialement un pipeline d'augmentation et de purification (AAP) pour générer des étiquettes d'occupation 3D grossières, suivi d'une augmentation manuelle pour affiner les étiquettes. En outre, il présente OpenOccupancy, la première référence en matière de connaissance sémantique de l'occupation ambiante, pour évaluer les méthodes avancées de prédiction d'occupation 3D.
Par la suite, Tian et al. Ils introduisent un pipeline de génération d'étiquettes semi-automatique qui exploite les ensembles de données de perception 3D étiquetés existants et identifie les types de voxels en fonction de leur visibilité. En outre, ils ont établi la référence Occ3d pour la prévision d’occupation 3D à grande échelle afin d’améliorer l’évaluation et la comparaison de différentes méthodes. Comme le montre le tableau 2, nous avons collecté les résultats d'évaluation des méthodes existantes sur l'ensemble de données Occ3D nuScenes.
De plus, similaire à Occ3D Nude et Nude Occupancy, OpenOcc est également un ensemble de données conçu pour la prédiction d'occupation 3D basée sur l'ensemble de données Nude. Il contient 850 séquences, 34 149 images et 16 classes. Notez que cet ensemble de données fournit des annotations supplémentaires pour huit objets de premier plan, ce qui facilite les tâches en aval telles que la planification de mouvements.
Principaux défis
Bien que la prédiction d'occupation 3D basée sur la vision ait fait des progrès significatifs ces dernières années, elle se heurte toujours à des limites en termes de représentation des caractéristiques, d'application pratique et de coûts d'annotation. Pour cette tâche, il y a trois défis clés : (1) Il est difficile d'obtenir des caractéristiques 3D parfaites à partir d'une entrée visuelle 2D. L'objectif de la prédiction d'occupation 3D basée sur la vision est d'obtenir une perception et une compréhension détaillées des scènes 3D à partir de l'entrée d'images uniquement. Cependant, le manque d'informations de profondeur et de géométrie inhérentes aux images pose un défi important pour l'apprentissage des représentations d'entités 3D directement à partir de celles-ci. (2) Lourde charge de calcul dans un espace tridimensionnel. La prédiction d'occupation 3D nécessite généralement l'utilisation de fonctionnalités de voxel 3D pour représenter l'espace de l'environnement, ce qui implique inévitablement des opérations telles que la convolution 3D pour l'extraction de fonctionnalités, ce qui augmente considérablement la surcharge de calcul et de mémoire et entrave le déploiement pratique. (3) Annotations coûteuses à grain fin. La prédiction d'occupation 3D implique de prédire l'état d'occupation et la catégorie sémantique des voxels haute résolution, mais pour y parvenir, cela nécessite souvent une annotation sémantique fine de chaque voxel, ce qui prend du temps et coûte cher, créant un goulot d'étranglement pour cette tâche.
En réponse à ces défis clés, les travaux de recherche sur la prédiction d'occupation tridimensionnelle basée sur la vision pour la conduite autonome ont progressivement formé trois axes principaux : l'amélioration des fonctionnalités, la convivialité de déploiement et l'efficacité de l'étiquetage. Les méthodes d'amélioration des fonctionnalités atténuent la différence entre la sortie de l'espace 3D et l'entrée de l'espace 2D en optimisant les capacités de représentation des fonctionnalités du réseau. L'approche conviviale au déploiement vise à réduire considérablement la consommation de ressources tout en garantissant les performances en concevant une architecture réseau simple et efficace. Des méthodes d'étiquetage efficaces devraient permettre d'obtenir des performances satisfaisantes même lorsque les annotations sont insuffisantes ou totalement absentes. Nous fournissons ensuite un aperçu complet des approches actuelles autour de ces trois branches.
Méthode d'amélioration des fonctionnalités
La tâche de prédiction d'occupation 3D basée sur la vision implique de prédire l'état d'occupation et les informations sémantiques de l'espace voxel 3D à partir de l'espace d'image 2D, ce qui pose un défi clé pour obtenir des caractéristiques 3D parfaites à partir d'une entrée visuelle 2D. Pour résoudre ce problème, certaines méthodes améliorent la prédiction d'occupation du point de vue de l'amélioration des caractéristiques, notamment l'apprentissage à partir d'une vue à vol d'oiseau (BEV), d'une vue à trois vues (TPV) et d'une représentation de voxel tridimensionnel.
Méthodes basées sur BEV
Une méthode efficace pour apprendre l'occupation est basée sur la vue à vol d'oiseau (BEV), qui fournit des fonctionnalités insensibles à l'occlusion et contient certaines informations géométriques de profondeur. En apprenant de solides représentations BEV, une reconstruction robuste de scènes d’occupation 3D peut être obtenue. Tout d'abord, un réseau fédérateur 2D est utilisé pour extraire les caractéristiques de l'image à partir de l'entrée visuelle, puis les caractéristiques BEV sont obtenues par transformation du point de vue, et enfin, la prédiction d'occupation 3D est complétée sur la base de la représentation des caractéristiques BEV. La méthode basée sur BEV est illustrée à la figure 5.
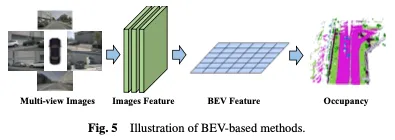
Une approche simple consiste à tirer parti de l'apprentissage BEV à partir d'autres tâches, par exemple en utilisant des méthodes telles que BEVDet et BEVFormer dans la détection d'objets 3D. Pour étendre ces méthodes d'apprentissage des occupations, des chefs d'occupation peuvent être ajoutés ou remplacés pendant la formation pour obtenir les résultats finaux. Cette adaptation permet l'intégration de l'estimation de l'occupation dans les cadres existants basés sur BEV, permettant la détection et la reconstruction simultanées de l'occupation 3D dans une scène. Basé sur la puissante base de référence BEVFormer, OccTransformer utilise l'augmentation des données pour augmenter la diversité des données de formation afin d'améliorer les capacités de généralisation du modèle et exploiter la puissante structure d'image pour extraire des fonctionnalités plus informatives des données d'entrée. Il introduit également une tête Unet 3D pour mieux capturer les informations spatiales de la scène, ainsi que des fonctions de perte supplémentaires pour améliorer l'optimisation du modèle.
Méthodes basées sur TPV
Bien que les représentations basées sur BEV présentent certains avantages par rapport aux images car elles fournissent essentiellement une projection descendante de l'espace 3D, elles manquent intrinsèquement de la capacité d'utiliser un seul plan pour décrire l'espace 3D. structure 3D fine d’une scène. La méthode basée sur trois angles de vision (TPV) utilise trois plans de projection orthogonaux pour modéliser l'environnement 3D, ce qui améliore encore la capacité de représentation des caractéristiques visuelles pour la prédiction de l'occupation. Tout d’abord, les caractéristiques de l’image sont extraites de l’entrée visuelle à l’aide d’un réseau fédérateur 2D. Par la suite, ces caractéristiques de l'image sont promues dans un espace à trois vues, et finalement une prédiction d'occupation 3D est obtenue sur la base de la représentation des caractéristiques de trois points de vue de projection. La méthode basée sur BEV est illustrée à la figure 7.
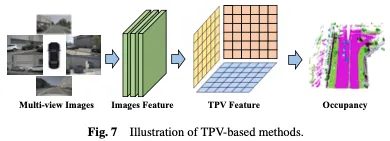
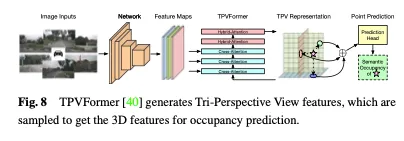
En plus des fonctionnalités BEV, TPVFormer génère également des fonctionnalités dans les vues de face et de côté de la même manière. Chaque plan modélise l'environnement 3D sous un angle différent et leur combinaison fournit une description complète de l'ensemble de la structure 3D. Plus précisément, afin d'obtenir les caractéristiques d'un point dans l'espace tridimensionnel, nous le projetons d'abord sur chacun des trois plans et utilisons l'interpolation bilinéaire pour obtenir les caractéristiques de chaque point projeté. Ensuite, nous résumons les trois caractéristiques de projection en caractéristiques synthétiques de points 3D. Par conséquent, la représentation TPV peut décrire des scènes 3D à des résolutions arbitraires et générer différentes caractéristiques pour différents points de l'espace 3D. Il propose en outre un encodeur basé sur un transformateur (TPVFormer) pour obtenir efficacement des caractéristiques TPV à partir d'images 2D et effectuer une attention croisée d'image entre les requêtes de grille TPV et les caractéristiques d'image 2D correspondantes, convertissant ainsi les informations 2D en mise à niveau vers l'espace 3D. Enfin, l’attention hybride croisée entre les fonctionnalités TPV permet l’interaction entre les trois plans. L'architecture globale de TPVFormer est illustrée à la figure 8.
Méthodes basées sur le voxel
En plus de convertir l'espace 3D en perspective projetée (comme BEV ou TPV), il existe également des méthodes qui opèrent directement sur la représentation du voxel 3D. L’un des principaux avantages de ces méthodes est la possibilité d’apprendre directement à partir de l’espace 3D d’origine, minimisant ainsi la perte d’informations. En exploitant les données brutes de voxels tridimensionnels, ces méthodes peuvent capturer et utiliser efficacement des informations spatiales complètes, ce qui permet une compréhension plus précise et plus complète de l'occupation. Tout d’abord, un réseau fédérateur 2D est utilisé pour extraire les caractéristiques de l’image, puis un mécanisme basé sur la convolution spécialement conçu est utilisé pour relier les représentations 2D et 3D, ou une approche basée sur des requêtes est utilisée pour obtenir directement la représentation 3D. Enfin, une tête d'occupation 3D est utilisée pour compléter la prédiction finale basée sur la représentation 3D apprise. La méthode basée sur les voxels est illustrée à la figure 9.
Méthodes basées sur la convolution
Une approche consiste à utiliser une architecture convolutive spécialement conçue pour combler le fossé entre la 2D et la 3D et apprendre la représentation d'occupation en 3D. Un exemple frappant de cette approche est l’adoption de l’architecture U-Net comme support de pontage de fonctionnalités. L'architecture U-Net adopte une structure codeur-décodeur avec des connexions sautées entre les chemins de suréchantillonnage et de sous-échantillonnage, conservant les informations sur les fonctionnalités de bas niveau et de haut niveau pour atténuer la perte d'informations. Grâce à des couches convolutives de différentes profondeurs, la structure U-Net peut extraire des caractéristiques de différentes échelles, aidant ainsi le modèle à capturer des détails locaux et des informations contextuelles globales dans l'image, améliorant ainsi la compréhension du modèle des scènes complexes et effectuant une prédiction d'occupation efficace.
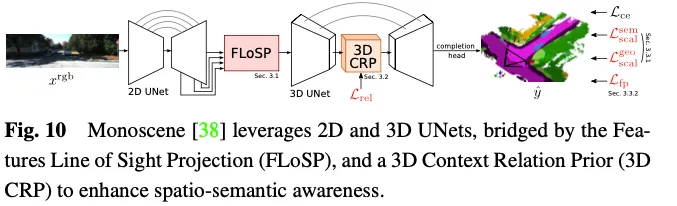
Monoscene utilise U-net pour la prédiction d'occupation 3D basée sur la vision. Il introduit un mécanisme appelé projection en ligne de visée d'entités bidimensionnelles (FLoSP), qui utilise la projection en perspective d'entités pour projeter des entités bidimensionnelles sur un espace tridimensionnel et calcule l'espace d'entités tridimensionnelles sur la base d'entités bidimensionnelles. sur le principe d'imagerie et les paramètres de la caméra. Les coordonnées de chaque point pour échantillonner les caractéristiques dans l'espace des caractéristiques tridimensionnelles. Cette méthode promeut les fonctionnalités 2D dans une carte de fonctionnalités 3D unifiée et sert de composant clé reliant les U-net 2D et 3D. Monoscene propose également une couche 3D Contextual Relation Prior (3D CRP) insérée au niveau du goulot d'étranglement 3D UNet, qui apprend un graphe de relation de scène sémantique voxel à voxel à n voies. Cela fournit au réseau un champ de réception global et améliore la conscience sémantique spatiale grâce au mécanisme de découverte de relations. L'architecture globale de Monoscene est illustrée à la figure 10.
Méthodes basées sur des requêtes
Une autre façon d'apprendre à partir de l'espace 3D consiste à générer un ensemble de requêtes pour capturer une représentation de la scène. Dans cette approche, des techniques basées sur des requêtes sont utilisées pour générer des suggestions de requêtes, qui sont ensuite utilisées pour apprendre des représentations complètes de scènes 3D. Par la suite, des mécanismes d’attention croisée et d’auto-attention sur les images sont appliqués pour affiner et améliorer les représentations apprises. Cette approche améliore non seulement la compréhension de la scène, mais permet également une reconstruction et une prévision précises de l'occupation dans l'espace 3D. De plus, l'approche basée sur les requêtes offre une plus grande flexibilité pour ajuster et optimiser en fonction de différentes sources de données et stratégies de requête, permettant une meilleure capture des informations contextuelles locales et globales pour faciliter la représentation des prévisions d'occupation 3D.
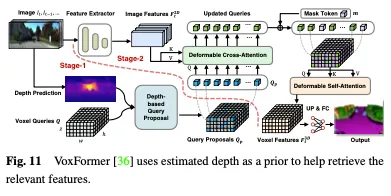
La profondeur peut être utilisée comme un a priori précieux pour sélectionner les requêtes d'occupation. Dans Voxformer, la profondeur estimée est utilisée comme un a priori pour prédire l'occupation et sélectionner les requêtes pertinentes. Seules les requêtes occupées sont utilisées pour collecter des informations à partir d'images en utilisant une attention déformable. Les propositions de requête mises à jour et les jetons masqués sont ensuite combinés pour reconstruire les caractéristiques du voxel. Voxformer extrait les caractéristiques 2D des images RVB, puis utilise un ensemble clairsemé de requêtes de voxels 3D pour indexer ces caractéristiques 2D, en utilisant la matrice de projection de la caméra pour lier les positions 3D au flux d'images. Plus précisément, les requêtes voxels sont des paramètres apprenables de formes de maillage 3D conçus pour interroger des caractéristiques d'images dans des volumes 3D à l'aide de mécanismes d'attention. L'ensemble du cadre est une cascade en deux étapes composée de propositions indépendantes de la classe et d'une segmentation spécifique à la classe. L'étape 1 génère des suggestions de requêtes indépendantes de la classe, tandis que l'étape 2 adopte une architecture de type MAE pour propager les informations à tous les voxels. Enfin, les caractéristiques du voxel sont suréchantillonnées pour la segmentation sémantique. L'architecture globale de VoxFormer est illustrée à la figure 11.
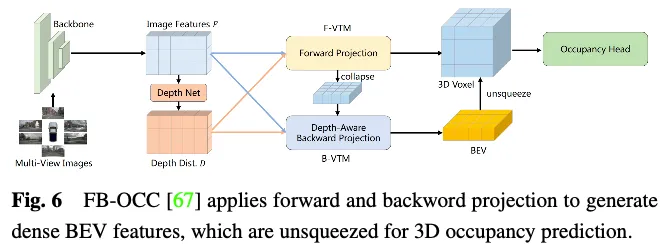
La comparaison des performances des méthodes d'amélioration des fonctionnalités sur l'ensemble de données Occ3D nuScenes est présentée dans le tableau 3. Les résultats montrent que les méthodes qui traitent directement les représentations de voxels obtiennent souvent de bonnes performances car elles ne subissent pas de perte d'informations significative lors du calcul. De plus, bien que les méthodes basées sur BEV n'aient qu'un seul point de vue projeté pour la représentation des caractéristiques, elles peuvent toujours atteindre des performances comparables en raison de la richesse des informations contenues dans la vue à vol d'oiseau et de leur insensibilité à l'occlusion et aux changements d'échelle. De plus, en reconstruisant les informations 3D à partir de plusieurs vues complémentaires, les méthodes basées sur la vue à trois perspectives (TPV) sont capables d'atténuer les ambiguïtés géométriques potentielles et de capturer un contexte de scène plus complet, permettant ainsi une prédiction efficace de l'occupation 3D. Notamment, FB-OCC utilise des modules de conversion de vue avant et arrière, leur permettant de s'améliorer mutuellement pour obtenir une représentation de véhicule électrique pur de meilleure qualité et atteindre d'excellentes performances. Cela montre que les méthodes basées sur BEV ont également un grand potentiel pour améliorer la prévision d'occupation 3D grâce à une amélioration efficace des fonctionnalités.
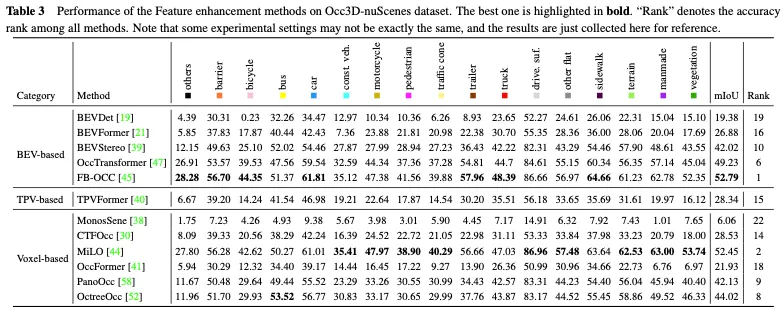
Méthodes conviviales pour le déploiement
Apprendre des représentations d'occupation directement à partir de l'espace 3D est extrêmement difficile en raison de sa vaste portée et de la nature complexe des données. La haute dimensionnalité et le calcul intensif associés à la représentation de voxels 3D rendent le processus d'apprentissage très exigeant en ressources, ce qui n'est pas propice aux applications de déploiement pratiques. Par conséquent, les méthodes de conception de représentations 3D conviviales pour le déploiement visent à réduire les coûts de calcul et à améliorer l’efficacité de l’apprentissage. Cette section présente des méthodes permettant de relever les défis informatiques liés à l'estimation de l'occupation des scènes 3D, en se concentrant sur le développement de méthodes précises et efficaces plutôt que sur le traitement direct de l'intégralité de l'espace 3D. Les techniques discutées incluent la décomposition en perspective et le raffinement grossier à fin, qui ont été démontrés dans des travaux récents pour améliorer l'efficacité informatique des prévisions d'occupation 3D.
Méthodes de décomposition en perspective
En séparant les informations de point de vue des caractéristiques de la scène 3D ou en les projetant dans un espace de représentation unifié, la complexité informatique peut être efficacement réduite, rendant le modèle plus robuste et généralisable. L'idée principale de cette méthode est de découpler la représentation de la scène tridimensionnelle des informations de point de vue, réduisant ainsi le nombre de variables à prendre en compte dans le processus d'apprentissage des fonctionnalités et réduisant la complexité de calcul. Le découplage des informations de point de vue permet au modèle de mieux généraliser et de s'adapter aux différentes transformations de point de vue sans avoir à réapprendre l'intégralité du modèle.
Pour répondre à la charge de calcul liée à l'apprentissage à partir de l'ensemble de l'espace 3D, une approche courante consiste à utiliser les représentations Bird's Eye View (BEV) et Three View View (TPV). En décomposant l'espace 3D en représentations de vues individuelles, la complexité informatique est considérablement réduite tout en continuant à capturer les informations essentielles pour la prévision de l'occupation. L'idée clé est d'abord d'apprendre des perspectives BEV et TPV, puis de récupérer les informations complètes d'occupation 3D en combinant les informations obtenues à partir de ces différentes vues. Cette stratégie de décomposition en perspective permet une estimation de l'occupation plus efficace et efficiente par rapport à l'apprentissage direct à partir de l'ensemble de l'espace 3D.
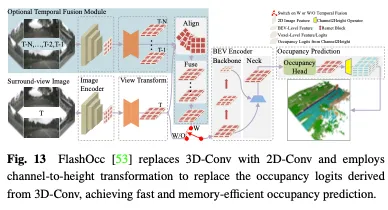
Méthodes grossières à fines
Apprendre des caractéristiques de voxel global à grain fin haute résolution directement à partir d'espaces 3D à grande échelle prend du temps et représente un défi. Par conséquent, certaines méthodes ont commencé à explorer le paradigme d’apprentissage des fonctionnalités grossier à fin. Plus précisément, le réseau apprend d'abord une représentation grossière à partir d'une image, puis affine et récupère une représentation fine de la scène entière. Ce processus en deux étapes permet d’obtenir des prévisions plus précises et plus efficaces de l’occupation des lieux.
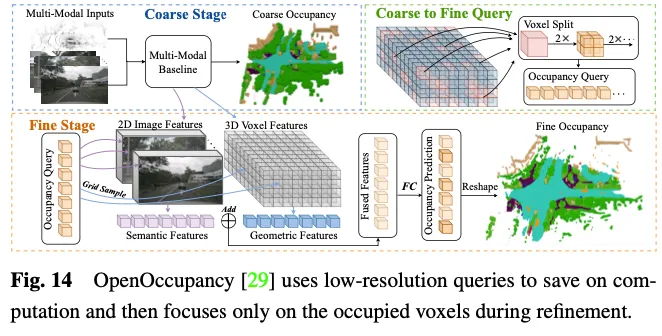
OpenOccupancy adopte une approche en deux étapes pour apprendre la représentation de l'occupation dans l'espace 3D. Comme le montre la figure 14.
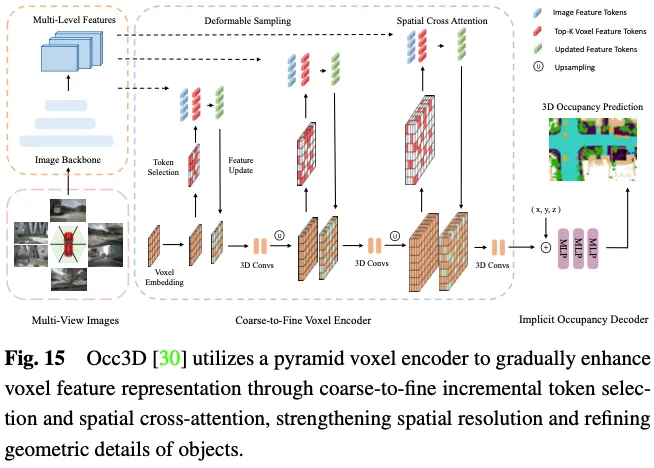
La prévision de l'occupation 3D nécessite une représentation géométrique détaillée, et l'utilisation de tous les marqueurs voxels 3D pour interagir avec les ROI dans des images multi-vues entraînera des coûts de calcul et de mémoire importants. Comme le montre la figure 15, Occ3D propose une stratégie de sélection de jetons incrémentielle pour sélectionner sélectivement les jetons de voxel de premier plan et incertains pendant le processus de calcul d'attention croisée, réalisant ainsi une adaptation sans sacrifier la précision du calcul. Plus précisément, au début de chaque couche pyramidale, chaque étiquette de voxel est entrée dans un classificateur binaire pour prédire si le voxel est vide ou non, supervisé par des cartes d'occupation binaires de vérité terrain pour entraîner le classificateur. PanoOcc propose d'intégrer de manière transparente la détection d'objets et la segmentation sémantique dans un cadre d'apprentissage commun pour promouvoir une compréhension plus complète des environnements 3D. Le procédé utilise des requêtes voxels pour regrouper des informations spatio-temporelles à partir d'images multi-images et multi-vues, fusionnant l'apprentissage des caractéristiques et la représentation de la scène en une représentation d'occupation unifiée. En outre, il explore la rareté de l'espace 3D en introduisant un module de rareté d'occupation, qui répartit progressivement l'occupation pendant le processus de suréchantillonnage de grossier à fin, améliorant ainsi considérablement l'efficacité du stockage.
La comparaison des performances des méthodes conviviales pour le déploiement sur l'ensemble de données Occ3D nuScenes est présentée dans le tableau 4. Étant donné que les résultats ont été collectés à partir de différents articles présentant des différences en termes de structure, de taille d'image et de plate-forme informatique, seules quelques conclusions préliminaires peuvent être tirées. Généralement, dans des contextes expérimentaux similaires, les méthodes grossières à fines surpassent les méthodes de décomposition en perspective en termes de performances en raison de moins de perte d'informations, tandis que la décomposition en perspective présente généralement de meilleures performances en temps réel et une utilisation moindre de la mémoire. De plus, les modèles dotés d’une structure plus lourde et traitant des images plus grandes peuvent obtenir une meilleure précision mais également nuire aux performances en temps réel. Bien que les versions légères de méthodes telles que FlashOcc et FastOcc soient proches des exigences d'un déploiement pratique, leur précision doit encore être améliorée. Pour les méthodes faciles à déployer, la stratégie de décomposition en perspective et la stratégie grossière à fine s'efforcent de réduire continuellement la charge de calcul tout en maintenant la précision de la prédiction d'occupation 3D.
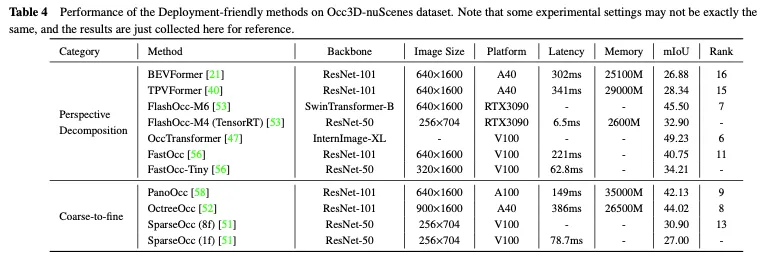
Méthodes d'étiquetage efficaces
Parmi les méthodes existantes pour créer des étiquettes d'occupation précises, il existe deux étapes de base. La première consiste à collecter des nuages de points lidar correspondant à des images multi-vues et à les annoter pour une segmentation sémantique. L'autre consiste à utiliser les informations de suivi d'objets dynamiques pour fusionner des nuages de points multi-images grâce à des algorithmes complexes. Les deux étapes sont assez coûteuses, ce qui limite la capacité du réseau d’occupation à exploiter le grand nombre d’images multi-vues dans des scénarios de conduite autonome. Ces dernières années, les champs de rayonnement neuronal (Nerf) ont été largement utilisés dans le rendu d’images bidimensionnelles. Il existe plusieurs méthodes qui tracent l'occupation 3D prévue sur des cartes 2D à la manière de Nerf et entraînent le réseau d'occupation sans impliquer d'annotations fines ou de nuages de points lidar, ce qui réduit considérablement le coût de l'annotation des données.
Méthodes sans annotations
SimpleOccupancy génère d'abord des caractéristiques de voxel 3D explicites de la scène à partir des caractéristiques de l'image via une transformation de vue, puis les restitue dans une carte de profondeur 2D à la manière de Nerf. La carte de profondeur 2D est supervisée par une carte de profondeur clairsemée générée à partir du nuage de points lidar. Les cartes de profondeur sont également utilisées pour synthétiser des images surround pour l'auto-supervision. UniOcc utilise deux MLP distincts pour convertir les logits de voxels 3D en densité de voxels et en logits sémantiques de voxels. Ensuite, UniOCC suit le rendu général des volumes pour obtenir des cartes de profondeur multi-vues et des cartes sémantiques, comme le montre la figure 17. Ces cartes 2D sont supervisées par des étiquettes générées à partir de nuages de points LiDAR segmentés. RenderOcc crée des représentations volumétriques 3D de type NeRF à partir d'images multi-vues et génère des rendus 2D à l'aide de techniques de rendu volumétrique avancées qui peuvent fournir une supervision 3D directe en utilisant uniquement des étiquettes sémantiques et de profondeur 2D. Grâce à cette supervision du rendu 2D, le modèle apprend la cohérence multi-vues en analysant les intersections des rayons de divers troncs de caméra pour acquérir une compréhension plus approfondie des relations géométriques dans l'espace 3D. En outre, il introduit le concept de rayons auxiliaires pour utiliser les rayons des images voisines afin d'améliorer la contrainte de cohérence multi-vues de l'image actuelle, et développe une stratégie de formation à l'échantillonnage dynamique pour filtrer les rayons mal alignés. Pour résoudre le problème de déséquilibre entre les catégories dynamiques et statiques, OccFlowNet introduit en outre le flux d'occupation pour prédire le flux de scène pour chaque voxel dynamique sur la base de cadres de délimitation 3D. Grâce au streaming de voxels, les voxels dynamiques peuvent être déplacés vers l'emplacement correct dans le laps de temps, éliminant ainsi le besoin de filtrage dynamique des objets pendant le rendu. Pendant l'entraînement, les voxels correctement prédits et les voxels dans les cadres de délimitation sont transformés à l'aide de flux pour s'aligner sur l'emplacement cible dans la période temporelle, suivi d'un alignement sur la grille à l'aide d'une interpolation pondérée basée sur la distance.
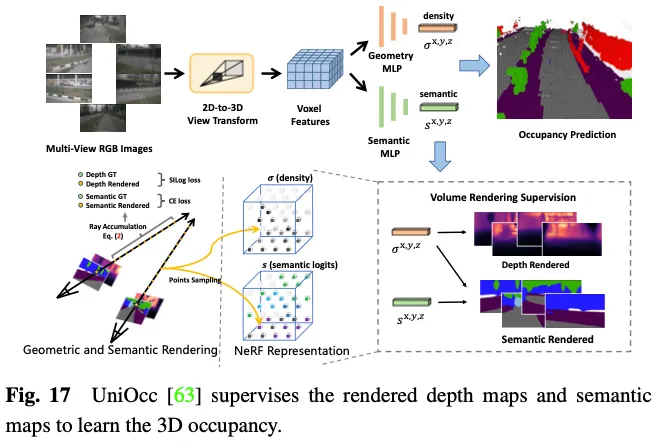
L'approche ci-dessus élimine le besoin d'annotations d'occupation 3D explicites, réduisant ainsi considérablement le fardeau de l'annotation manuelle. Cependant, ils s'appuient toujours sur des nuages de points lidar pour fournir des étiquettes de profondeur ou sémantiques afin de superviser les cartes rendues, ce qui ne permet pas encore d'obtenir un cadre entièrement auto-supervisé pour la prédiction d'occupation 3D.
Méthodes sans LiDAR
OccNerf n'utilise pas de nuages de points LiDAR pour fournir des étiquettes de profondeur et sémantiques. Au lieu de cela, comme le montre la figure 18, il utilise un champ d'occupation paramétré pour gérer des scènes extérieures illimitées, réorganise la stratégie d'échantillonnage et utilise le rendu de volume pour convertir le champ d'occupation en une carte de profondeur multi-caméras, qui est finalement supervisée par multi-frame. consistance photométrique . De plus, le procédé exploite un modèle de segmentation sémantique à vocabulaire ouvert pré-entraîné pour générer des étiquettes sémantiques 2D, supervisant le modèle pour fournir des informations sémantiques aux champs occupés. Dans les coulisses, une séquence d'images à vue unique est utilisée pour reconstruire la scène de conduite. Il traite les caractéristiques du tronc de l'image d'entrée comme un champ de densité et restitue un composite des autres vues. L'ensemble du modèle est entraîné avec une perte de reconstruction d'image spécialement conçue. SelfOcc prédit les valeurs de champ de distance signées des fonctionnalités BEV ou TPV pour restituer des cartes de profondeur 2D. De plus, les cartes couleur et sémantiques originales sont également rendues et supervisées par des étiquettes générées à partir de séquences d'images multi-vues.
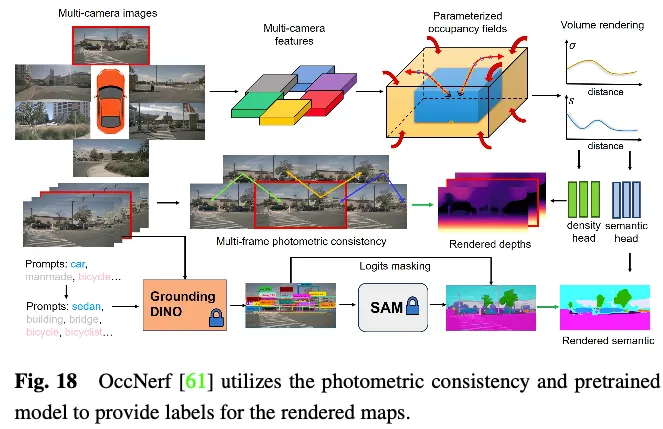
Ces méthodes évitent le besoin d'étiquettes de profondeur ou sémantiques à partir des nuages de points lidar. Au lieu de cela, ils exploitent des données d'image ou des modèles pré-entraînés pour obtenir ces étiquettes, permettant ainsi un cadre véritablement auto-supervisé pour la prédiction d'occupation 3D. Bien que ces méthodes permettent d'obtenir des modèles de formation les plus cohérents avec une expérience d'application pratique, une exploration plus approfondie est nécessaire pour obtenir des performances satisfaisantes.
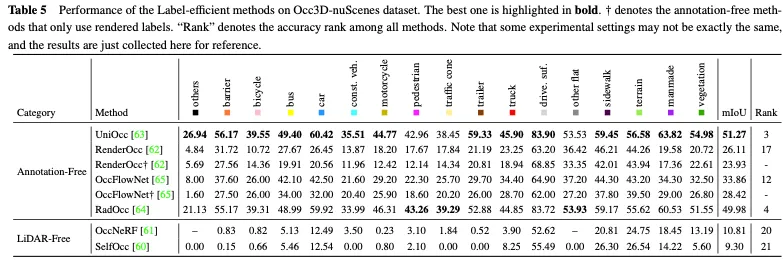
Le Tableau 5 montre la comparaison des performances des méthodes efficaces en matière d'étiquettes sur l'ensemble de données Occ3D nuScenes. La plupart des méthodes sans annotations utilisent la supervision du rendu 2D en complément de la supervision explicite de l'occupation 3D et obtiennent certaines améliorations de performances. Parmi eux, UniOcc et RadOcc ont même obtenu d'excellents classements de 3 et 4 respectivement parmi toutes les méthodes, ce qui prouve pleinement que le mécanisme sans annotation peut favoriser l'extraction d'informations supplémentaires précieuses. En utilisant uniquement la supervision du rendu 2D, ils peuvent toujours atteindre une précision comparable, illustrant la faisabilité d'économiser le coût de l'annotation explicite d'occupation 3D. L'approche sans lidar établit un cadre complet auto-supervisé pour la prévision d'occupation 3D, éliminant ainsi le besoin de balises et de données lidar. Cependant, comme le nuage de points lui-même manque d’informations précises sur la profondeur et la géométrie, ses performances sont grandement limitées.
Perspectives futures
Motivés par les approches ci-dessus, nous résumons les tendances actuelles et proposons plusieurs orientations de recherche importantes qui ont le potentiel de faire progresser considérablement la vision basée sur la vision du point de vue des données, des méthodes et des tâches de conduite autonome. champ de prédiction.
Niveau de données
L'obtention de suffisamment de données de conduite réelles est cruciale pour améliorer les capacités globales du système de perception de la conduite autonome. La génération de données est une approche prometteuse car elle n’entraîne aucun coût d’acquisition et offre la flexibilité nécessaire pour manipuler la diversité des données selon les besoins. Bien que certaines méthodes utilisent des indices tels que du texte pour contrôler le contenu des données de conduite générées, elles ne peuvent garantir l'exactitude des informations spatiales. En revanche, 3D Occupancy fournit une représentation fine et exploitable de la scène, facilitant la génération de données contrôlables et l'affichage des informations spatiales par rapport aux nuages de points, aux images multi-vues et aux dispositions BEV. WoVoGen propose une diffusion sensible au volume qui peut cartographier l'occupation 3D en images multi-vues réalistes. Une fois les modifications apportées à l'occupation 3D, comme l'ajout d'un arbre ou le changement de voiture, le modèle de diffusion synthétisera la nouvelle scène de conduite correspondante. L'occupation tridimensionnelle modifiée enregistre des informations de position tridimensionnelles, garantissant ainsi l'authenticité des données synthétiques.
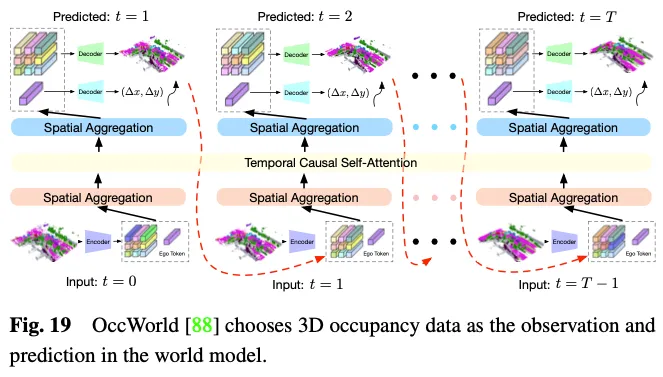
Le modèle mondial de conduite autonome devient de plus en plus important. Il fournit un cadre simple et élégant qui améliore la capacité du modèle à comprendre l'ensemble de la scène sur la base d'observations environnementales et à générer directement des données d'évolution dynamique appropriées. L’exploitation de l’occupation 3D en tant qu’observation environnementale dans un modèle mondial présente des avantages évidents étant donné sa capacité à représenter de manière experte et détaillée l’ensemble des données de la scène de conduite. Comme le montre la figure 19, OccWorld sélectionne l'occupation 3D comme entrée du modèle mondial et utilise un module de type GPT pour prédire à quoi devraient ressembler les futures données d'occupation 3D. UniWorld exploite des modèles d'occupation 3D disponibles dans le commerce basés sur BEV, mais construit également un modèle mondial en traitant des images multi-vues passées pour prédire les futures données d'occupation 3D. Cependant, quel que soit le mécanisme utilisé, il existe inévitablement un écart entre les données générées et les données réelles. Pour résoudre ce problème, une approche réalisable consiste à combiner la prédiction d'occupation 3D avec la méthode émergente de contenu généré par l'intelligence artificielle 3D (3D AIGC) pour générer des données de scène plus réalistes, tandis qu'une autre approche consiste à combiner des méthodes d'adaptation de domaine pour réduire l'écart de champ.
Niveau méthodologique
En ce qui concerne les méthodes de prédiction d'occupation 3D, il existe des défis permanents qui nécessitent une attention particulière dans les catégories que nous avons décrites précédemment : méthodes d'amélioration des fonctionnalités, méthodes faciles à déployer et méthodes efficaces en matière d'étiquetage. Les méthodes d'amélioration des fonctionnalités doivent être développées dans le but d'améliorer considérablement les performances tout en maintenant une consommation contrôlable des ressources informatiques. Il convient de garder à l’esprit une approche conviviale pour le déploiement afin de réduire l’utilisation de la mémoire et la latence tout en garantissant que la dégradation des performances est minimisée. Des méthodes d'étiquetage efficaces devraient être développées dans le but de réduire le besoin d'annotations coûteuses tout en obtenant des performances satisfaisantes. L’objectif ultime pourrait être de parvenir à un cadre unifié combinant améliorations des fonctionnalités, convivialité de déploiement et efficacité de l’étiquetage pour répondre aux attentes des applications de conduite autonome du monde réel.
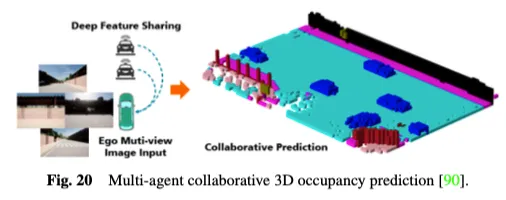
De plus, les systèmes de perception de la conduite autonome à agent unique existants sont intrinsèquement incapables de résoudre des problèmes clés, tels que la sensibilité à l'occlusion, les capacités de détection à longue portée insuffisantes et le champ de vision limité, ce qui rend difficile la réalisation d'une conscience environnementale globale. Afin de surmonter le goulot d'étranglement des méthodes de détection collaboratives mono-agent, les méthodes de détection collaborative multi-agents ouvrent une nouvelle dimension, permettant aux véhicules de partager des informations complémentaires avec d'autres éléments du trafic pour obtenir une perception globale de l'environnement. Comme le montre la figure 20, la méthode collaborative multi-agents de prédiction d'occupation 3D utilise la puissance de la détection et de l'apprentissage collaboratifs pour la prédiction d'occupation 3D. En partageant des fonctionnalités entre les véhicules automatisés connectés, elle peut acquérir une compréhension plus approfondie de l'environnement routier 3D. CoHFF est le premier cadre collaboratif de prédiction d'occupation sémantique basé sur la vision, qui améliore la prédiction d'occupation sémantique 3D locale grâce à une fusion hybride de fonctionnalités de tâche sémantique et d'occupation, ainsi que de fonctionnalités d'attention orthogonales compressées partagées entre les véhicules, améliorant considérablement les performances. le système vélo. Cependant, cette méthode nécessite souvent de communiquer avec plusieurs agents simultanément, confrontée à une contradiction entre précision et bande passante. C’est donc une direction de recherche intéressante que de déterminer quels agents nécessitent le plus de coordination et d’identifier les domaines dans lesquels la collaboration est la plus précieuse pour atteindre le meilleur équilibre entre précision et rapidité.
Niveau de tâche
Dans les benchmarks d'occupation 3D actuels, certaines catégories ont une sémantique claire, comme « voiture », « piéton » et « camion ». En revanche, la sémantique d’autres catégories telles que « artificiel » et « végétation » a tendance à être vague et générale. Ces catégories contiennent une sémantique large et non définie et devraient être subdivisées en catégories plus fines pour fournir des descriptions détaillées des scénarios de conduite. De plus, pour les catégories inconnues qui n’ont jamais été vues auparavant, elles sont souvent considérées comme un obstacle général à l’expansion flexible de la perception de nouvelles catégories basées sur des signaux humains. Pour ce problème, les tâches de vocabulaire ouvert montrent de fortes performances en matière de perception d'images 2D et peuvent être étendues pour améliorer les tâches de prédiction d'occupation 3D. OVO propose un cadre qui prend en charge la prédiction d'occupation 3D à vocabulaire ouvert. Il utilise des segmenteurs 2D figés et des encodeurs de texte pour obtenir des références sémantiques pour les vocabulaires ouverts. Ensuite, trois niveaux d'alignement différents sont utilisés pour extraire le modèle d'occupation 3D, lui permettant ainsi d'effectuer des prédictions de mots ouverts. POP-3D a conçu un cadre auto-supervisé qui combine trois modalités à l'aide de puissants modèles de langage visuel pré-entraînés. Il facilite les tâches à vocabulaire ouvert telles que la segmentation d'occupation sans tir et la récupération 3D basée sur du texte.
La perception des changements dynamiques dans l'environnement environnant est cruciale pour l'exécution sûre et fiable des tâches en aval de la conduite autonome. Bien que les prédictions d'occupation 3D puissent fournir des représentations denses d'occupation de scènes à grande échelle basées sur les observations actuelles, elles se limitent pour la plupart à représenter l'espace 3D actuel et ne prennent pas en compte les états futurs des objets environnants le long de la chronologie. Récemment, plusieurs méthodes ont été proposées pour examiner davantage les informations temporelles et introduire des tâches de prédiction d'occupation 4D, plus pratiques dans les scénarios réels de conduite autonome. Cam4Occ établit pour la première fois une nouvelle référence pour la prédiction d'occupation 4D en utilisant pour la première fois l'ensemble de données nuScenes largement utilisé. Le benchmark comprend différentes mesures pour évaluer les prévisions d'occupation pour les objets mobiles généraux (OGM) et les objets statiques généraux (GSO), respectivement. En outre, il fournit plusieurs modèles de base pour illustrer la construction d’un cadre de prédiction d’occupation 4D. Bien que la tâche de prédiction d'occupation 3D à vocabulaire ouvert et la tâche de prédiction d'occupation 4D visent à améliorer les capacités de perception de la conduite autonome dans des environnements dynamiques ouverts sous différentes perspectives, elles sont toujours considérées comme des tâches d'optimisation indépendantes. Un paradigme modulaire basé sur des tâches dans lequel plusieurs modules ont des objectifs d'optimisation incohérents peut entraîner une perte d'informations et une accumulation d'erreurs. Combiner la prédiction dynamique ouverte de l'occupation avec des tâches de conduite autonome de bout en bout et cartographier directement les données brutes des capteurs pour contrôler les signaux est une direction de recherche prometteuse.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quels sont les fonds de fiducie de cryptage en niveaux de gris?
Mar 05, 2025 pm 12:33 PM
Quels sont les fonds de fiducie de cryptage en niveaux de gris?
Mar 05, 2025 pm 12:33 PM
Investissement en niveaux de gris: le canal des investisseurs institutionnels pour entrer sur le marché des crypto-monnaies. La société a lancé plusieurs fiducies cryptographiques, ce qui a attiré une attention généralisée, mais l'impact de ces fonds sur les prix des jetons varie considérablement. Cet article présentera en détail certains des principaux fonds de fiducie de crypto de Graycale. Grayscale Major Crypto Trust Funds disponibles dans un investissement GrayScale GRAYS (fondée par DigitalCurrencyGroup en 2013) gère une variété de fonds fiduciaires d'actifs cryptographiques, fournissant des investisseurs institutionnels et des particuliers élevés avec des canaux d'investissement conformes. Ses principaux fonds comprennent: ZCash (Zec), Sol,
 Bitwise: les entreprises achètent un bitcoin une grande tendance négligée
Mar 05, 2025 pm 02:42 PM
Bitwise: les entreprises achètent un bitcoin une grande tendance négligée
Mar 05, 2025 pm 02:42 PM
Observation hebdomadaire: les entreprises thésaurisation du Bitcoin - un changement de brassage que je souligne souvent certaines tendances du marché négligées dans des mémos hebdomadaires. Le mouvement de Microstrategy est un exemple brutal. Beaucoup de gens peuvent dire: "Microstrategy et Michaelsaylor sont déjà bien connus, à quoi allez-vous faire attention?" Cette vue est unilatérale. Des recherches approfondies sur l'adoption du bitcoin en tant qu'actif de réserve au cours des derniers mois montrent qu'il ne s'agit pas d'un cas isolé, mais d'une tendance majeure qui émerge. Je prédis qu'au cours des 12 à 18 prochains mois, des centaines d'entreprises suivront le pas et achèteront de grandes quantités de Bitcoin
 Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
La bibliothèque utilisée pour le fonctionnement du numéro de point flottante dans le langage go présente comment s'assurer que la précision est ...
 Dépassant considérablement la SFT, le secret derrière O1 / Deepseek-R1 peut également être utilisé dans les grands modèles multimodaux
Mar 12, 2025 pm 01:03 PM
Dépassant considérablement la SFT, le secret derrière O1 / Deepseek-R1 peut également être utilisé dans les grands modèles multimodaux
Mar 12, 2025 pm 01:03 PM
Des chercheurs de l'Université de Shanghai Jiaotong, de Shanghai Ailab et de l'Université chinoise de Hong Kong ont lancé le projet open source Visual-RFT (visual d'amélioration), qui ne nécessite qu'une petite quantité de données pour améliorer considérablement les performances du gros modèle de langage visuel (LVLM). Visual-RFT combine intelligemment l'approche d'apprentissage en renforcement basée sur les règles de Deepseek-R1 avec le paradigme de relâchement de renforcement d'OpenAI (RFT), prolongeant avec succès cette approche du champ de texte au champ visuel. En concevant les récompenses de règles correspondantes pour des tâches telles que la sous-catégorisation visuelle et la détection d'objets, Visual-RFT surmonte les limites de la méthode Deepseek-R1 limitée au texte, au raisonnement mathématique et à d'autres domaines, fournissant une nouvelle façon de formation LVLM. Vis
 Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou des projets open source bien connus? Lors de la programmation en Go, les développeurs rencontrent souvent des besoins communs, ...
 Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Description de la question: Comment obtenir les données de la région d'expédition de la version à l'étranger? Y a-t-il des ressources prêtes à l'emploi disponibles? Soyez précis dans le commerce électronique transfrontalier ou les entreprises mondialisées ...
 Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
GiteEpages STATIQUE Le déploiement du site Web a échoué: 404 Dépannage des erreurs et résolution lors de l'utilisation de Gitee ...
 Qu'est-ce que Binance Launchpool? Comment participer à Binance Launchpool?
Mar 05, 2025 pm 03:06 PM
Qu'est-ce que Binance Launchpool? Comment participer à Binance Launchpool?
Mar 05, 2025 pm 03:06 PM
Binance LaunchPool Analyse approfondie: guide d'extraction à haut rendement et explication détaillée des projets bio. En tant que plus grand échange de crypto-monnaie au monde, Binance a sélectionné des projets de haute qualité avec LaunchPool, offrant aux investisseurs des mines et des opportunités faciles d'obtenir de nouveaux jetons. Qu'est-ce que Binance Launchpool? Binance LaunchPool est une plate-forme qui gagne gratuitement de nouveaux jetons en promettant une monnaie spécifiée. Ceci est similaire aux nouveaux abonnements en actions en bourse, mais il y a moins de participants, une concurrence inférieure et de petits investissements peuvent également obtenir des rendements élevés.
