La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. E-mail de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
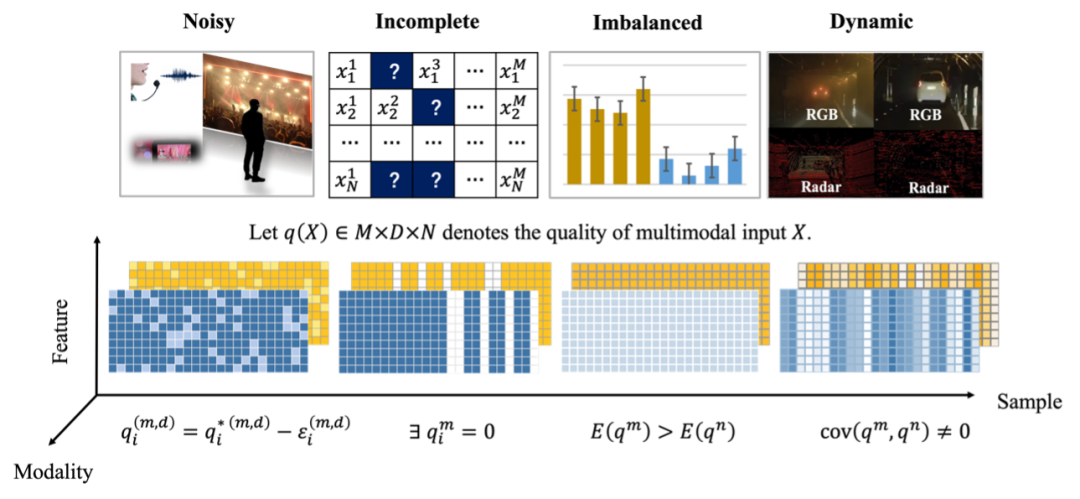
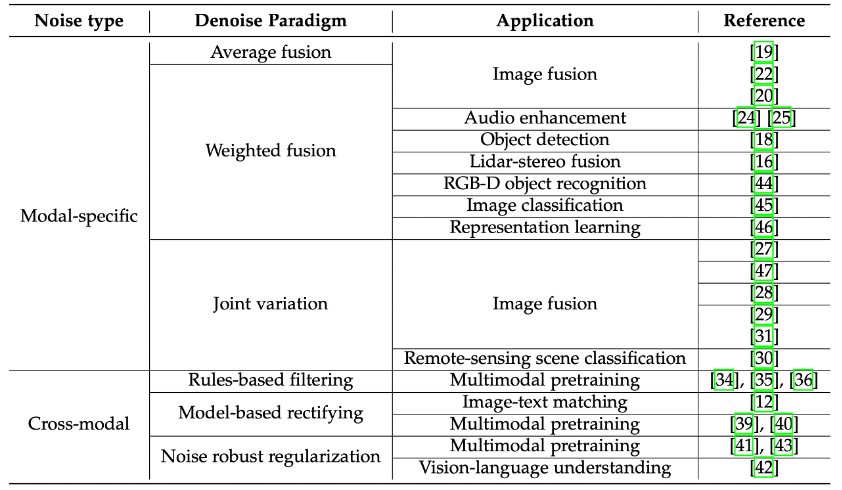
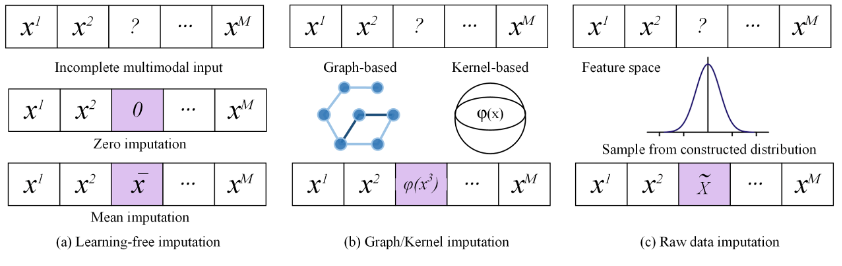
La fusion multimodale est l'une des tâches de base de l'intelligence multimodale. La motivation de la fusion multimodale est d'utiliser conjointement des informations efficaces provenant de différentes modalités pour améliorer la précision et la stabilité des tâches en aval. Les méthodes traditionnelles de fusion multimodale reposent souvent sur des données de haute qualité et sont difficiles à adapter aux données multimodales complexes et de mauvaise qualité dans les applications réelles. Une étude sur la fusion de données multimodales de faible qualité "Multimodal Fusion on Low-quality" publiée conjointement par l'Université de Tianjin, l'Université Renmin de Chine, l'Agence de Singapour pour la science, la technologie et la recherche, l'Université du Sichuan, l'Université de Xi'an de Electronic Science and Technology and Harbin Institute of Technology (Shenzhen) Data: A Comprehensive Survey" présente les défis de fusion des données multimodales dans une perspective unifiée et trie les méthodes de fusion existantes de données multimodales de faible qualité et le développement potentiel. orientations dans ce domaine. http://arxiv.org/abs/2404.18947https://github.com/QingyangZhang/awesome-low-quality-multimodal-learning Modèle de fusion multimodale traditionnelLes humains perçoivent le monde en fusionnant des informations provenant de plusieurs modalités. Même lorsque les signaux de certaines modalités ne sont pas fiables, les humains ont la capacité de traiter ces signaux de données multimodales de faible qualité et de percevoir l'environnement. Bien que l'apprentissage multimodal ait fait de grands progrès, les modèles d'apprentissage automatique multimodaux n'ont toujours pas la capacité de fusionner efficacement des données multimodales de faible qualité dans le monde réel. Dans la pratique, les performances des modèles de fusion multimodaux traditionnels diminueront considérablement dans les scénarios suivants : (1) Données multimodales bruyantes : Certaines caractéristiques de certaines modalités sont perturbées par le bruit et la perte d'informations d'origine . Dans le monde réel, des facteurs environnementaux inconnus, des pannes de capteurs et une perte de signal pendant la transmission peuvent introduire des interférences sonores, nuisant ainsi à la fiabilité du modèle de fusion multimodale. (2)Données multimodales manquantes : En raison de divers facteurs pratiques, certaines modalités des échantillons de données multimodales réellement collectées peuvent manquer. Par exemple, dans le domaine médical, les données multimodales composées des différents résultats d'examens physiologiques des patients peuvent manquer gravement, et certains patients peuvent n'avoir jamais subi un certain examen. (3) Données multimodales déséquilibrées : En raison du phénomène incohérent d'attributs de codage hétérogènes et des différences de qualité de l'information entre les modalités, le problème d'un apprentissage déséquilibré entre les modalités se produit. Au cours du processus de fusion multimodale, le modèle peut trop s'appuyer sur certaines modalités et ignorer les informations potentiellement efficaces contenues dans d'autres modalités. (4) Données multimodales dynamiques de faible qualité : En raison de la complexité et du changement de l'environnement d'application, des différents échantillons, du temps et de l'espace différents, la qualité modale a des caractéristiques changeantes dynamiques. L’apparition de données modales de mauvaise qualité est souvent difficile à prédire à l’avance, ce qui pose des défis à la fusion multimodale. Afin de caractériser pleinement la nature et les méthodes de traitement des données multimodales de faible qualité, cet article résume les méthodes actuelles d'apprentissage automatique dans le domaine de la fusion multimodale de faible qualité, passe systématiquement en revue le processus de développement dans ce domaine et les questions qui nécessitent des recherches plus approfondies sont explorées plus en détail. Figure 1. Diagramme schématique de la classification des données multimodales de faible qualité, le jaune et le bleu représentent les deux modalités, plus la couleur est foncée, plus la qualité est élevée Méthode de débruitage en multi-modal fusion Le bruit est l'une des causes les plus courantes de dégradation de la qualité des données multimodales. Cet article se concentre principalement sur deux types de bruit : (1) Bruit multimodal lié au mode. Ce type de bruit peut être provoqué par des facteurs tels que des erreurs de capteurs (telles que des erreurs d'instruments dans le diagnostic médical), des facteurs environnementaux (tels que la pluie et le brouillard en conduite autonome), et le bruit est limité à certains niveaux de fonctionnalités dans un mode spécifique. (2) Bruit cross-modal au niveau sémantique. Ce type de bruit est causé par le désalignement de la sémantique de haut niveau entre les modalités et est plus difficile à gérer que le bruit multimodal au niveau de la couche de fonctionnalités. Heureusement, en raison de la complémentarité entre les modes de données multimodaux et de la redondance des informations, la combinaison d'informations provenant de plusieurs modalités pour le débruitage s'est avérée être une stratégie efficace dans le processus de fusion multimodale. Classification des méthodes : Les méthodes de débruitage multimodal au niveau des fonctionnalités dépendent fortement des modalités spécifiques impliquées dans la tâche réelle. Cet article prend principalement la tâche de fusion d'images multimodales comme exemple pour illustrer. Dans la fusion d'images multimodale, les méthodes de débruitage les plus courantes incluent la fusion pondérée et la variation conjointe. Méthode de fusion pondéréeConsidérant que le bruit caractéristique est aléatoire et que les données réelles obéissent à une distribution spécifique, l'influence du bruit est éliminée par sommation pondérée méthode de variation conjointe est l'expansion du simple traditionnel ; -le débruitage variationnel d'image modal peut transformer le processus de débruitage en un processus de résolution de problèmes d'optimisation et utiliser des informations complémentaires provenant de multiples modalités pour améliorer l'effet de débruitage. Le bruit multimodal au niveau sémantique résulte de paires d'échantillons multimodaux faiblement alignés ou mal alignés. Par exemple, dans la tâche de détection de cible multimodale consistant à combiner des images RVB et thermiques, en raison des différences entre les capteurs, bien que la même cible apparaisse dans les deux modalités, sa position et son attitude précises sont Il peut y avoir de légères différences ( faible alignement) dans différentes modalités, ce qui pose des problèmes pour estimer avec précision les informations de position. Dans la tâche de compréhension du contenu des médias sociaux, les informations sémantiques contenues dans les modalités d'image et de texte d'un échantillon (comme un Weibo) peuvent être très différentes, voire non pertinentes (complètement mal alignées), ce qui apporte encore plus de défis à la fusion multimodale. Les moyens de gérer le bruit sémantique intermodal incluent le filtrage de règles, le filtrage de modèles, la régularisation de modèles robustes au bruit et d'autres méthodes. Bien que le traitement du bruit des données ait longtemps été largement étudié dans les tâches classiques d'apprentissage automatique, dans des scénarios multimodaux, comment utiliser conjointement les différences entre les modalités Complémentarité et cohérence pour affaiblir l'impact du bruit reste un problème de recherche urgent à résoudre. De plus, contrairement au débruitage traditionnel au niveau des fonctionnalités, comment résoudre le bruit au niveau sémantique pendant le processus de pré-entraînement et d'inférence des grands modèles multimodaux est un problème intéressant et extrêmement difficile. Tableau 1. Classification des méthodes de fusion multimodale pour le bruit Méthodes de fusion de données multimodales manquantes Dans des scénarios réels Les données multimodales collectées sont souvent incomplètes. En raison de divers facteurs tels que des dommages au périphérique de stockage et un processus de transmission de données peu fiable, les données multimodales perdent souvent inévitablement une partie des informations modales. Par exemple : dans le système de recommandation, l'historique de navigation et la cote de crédit de l'utilisateur constituent des données multimodales. Cependant, en raison de problèmes d'autorisation et de confidentialité, il est souvent impossible de collecter complètement toutes les informations modales de l'utilisateur à construire. données multimodales. Dans le diagnostic médical, en raison du matériel limité dans certains hôpitaux et du coût élevé des examens spécifiques, les données diagnostiques multimodales des différents patients sont souvent très incomplètes. Classification des méthodes : Selon le principe de classification « si l'achèvement explicite des données multimodales manquantes est requis », les méthodes de fusion de données multimodales manquantes peuvent être divisées en : (1) Méthode de fusion multimodale basée sur la complétion La méthode de fusion multimodale basée sur la complétion comprend des méthodes de complétion indépendantes du modèle : telles que le remplissage direct des modes manquants avec des valeurs 0 ou des modes résiduels Méthode de complétion de la moyenne ; Méthode de complétion basée sur un graphe ou un noyau : ce type de méthode n'apprend pas directement comment compléter les données multimodales originales, mais construit un graphe ou un noyau pour chaque modalité, puis apprend les informations de similarité ou de corrélation. entre les paires d'échantillons, puis complétez les données manquantes ; complétez directement le niveau de fonctionnalité d'origine : certaines méthodes utilisent des modèles génératifs, tels que le réseau contradictoire génératif GAN et ses variantes Complétez directement les fonctionnalités manquantes. (2) Méthode de fusion multimodale sans complétion. Différentes des méthodes basées sur la complétion, les méthodes qui ne nécessitent pas de complétion se concentrent sur la façon d'utiliser les informations utiles contenues dans les modalités non manquantes pour fusionner les meilleures représentations possibles. Ce type de méthode a souvent un impact négatif. sur ce qui est attendu d'être appris. La représentation unifiée ajoute des contraintes afin que cette représentation puisse refléter les informations complètes des données modales observables pour contourner le processus d'achèvement de la fusion multimodale.  Bien que de nombreuses méthodes aient été proposées au pays et à l'étranger pour résoudre le clustering. Problèmes de fusion de données multimodales incomplètes dans les tâches classiques d'apprentissage automatique telles que la classification et la classification, mais il existe encore des défis plus profonds. Exemple : L'évaluation de la qualité des données d'achèvement dans les programmes d'achèvement modal manquants est souvent négligée.
Bien que de nombreuses méthodes aient été proposées au pays et à l'étranger pour résoudre le clustering. Problèmes de fusion de données multimodales incomplètes dans les tâches classiques d'apprentissage automatique telles que la classification et la classification, mais il existe encore des défis plus profonds. Exemple : L'évaluation de la qualité des données d'achèvement dans les programmes d'achèvement modal manquants est souvent négligée.
De plus, la stratégie consistant à utiliser des informations de localisation de données manquantes a priori pour masquer les modalités manquantes elle-même est difficile à combler le manque d'information et le déséquilibre d'information provoqués par les modalités manquantes.
Tableau 2. Classification des méthodes de fusion pour les données multimodales manquantes Dans de nombreux Dans l'apprentissage modal, la formation conjointe est généralement utilisée pour intégrer des données de différentes modalités afin d'améliorer les performances globales et les performances de généralisation de le modèle. Cependant, ce type de paradigme de formation conjointe largement adopté qui utilise un objectif d’apprentissage unifié ignore l’hétérogénéité des données selon les différentes modalités.
L'hétérogénéité des différentes modalités en termes de sources de données et de formulaires
leur confère des caractéristiques différentes en termes de vitesse de convergence, etc., ce qui rend difficile le bon traitement et l'apprentissage de toutes les modalités en même temps, cela entraîne des difficultés pour l'apprentissage conjoint multimodal
D'un autre côté, cette différence se reflète également dans la qualité des données monomodales
. Bien que toutes les modalités décrivent le même concept, elles varient dans la quantité d'informations liées à l'événement cible ou à l'objet cible. Les réseaux de neurones profonds basés sur l'objectif d'apprentissage du maximum de vraisemblance ont des caractéristiques d'apprentissage gourmandes, ce qui donne lieu à des modèles multimodaux qui reposent souvent sur des modalités de haute qualité avec des informations hautement discriminantes et sont plus faciles à apprendre, tout en modélisant insuffisamment d'autres informations modales.
Afin de relever ces défis et d'améliorer la qualité de l'apprentissage des modèles multimodaux, des recherches connexes sur l'apprentissage multimodal équilibré
ont récemment reçu une large attention.
Classification des méthodes :
Selon différents angles d'équilibre, les méthodes associées peuvent être divisées en méthodes basées sur des différences caractéristiques
et
méthodes basées sur des différences de qualité.
(1) Les cadres de formation conjointe multimodaux largement utilisés
ignorent souvent les différences inhérentes aux propriétés d'apprentissage des données monomodales, ce qui peut avoir un impact négatif sur les performances du modèle. La méthode basée sur les différences caractéristiques part des différences dans les caractéristiques d'apprentissage de chaque modalité et tente de résoudre ce problème en termes d'objectifs d'apprentissage, d'optimisation et d'architecture.
(2) Des recherches récentes ont en outre révélé que les modèles multimodaux
s'appuient souvent fortement sur certaines modalités d'information de haute qualité tout en ignorant d'autres modalités, ce qui entraîne un apprentissage insuffisant de toutes les modalités. Les méthodes basées sur les différences de qualité partent de cette perspective et tentent de résoudre ce problème et de promouvoir l'utilisation équilibrée de différentes modalités dans les modèles multimodaux du point de vue des objectifs d'apprentissage, des méthodes d'optimisation, de l'architecture du modèle et de l'amélioration des données.
Tableau 3. Classification des méthodes de fusion de données multimodales équilibrées La méthode d'apprentissage cible principalement l'hétérogénéité des données multimodales. Les différences de caractéristiques d'apprentissage ou de qualité des données entre les différentes modalités. Ces méthodes proposent des solutions sous différentes perspectives telles que les objectifs d'apprentissage, les méthodes d'optimisation, l'architecture du modèle et l'amélioration des données. L'apprentissage multimodal équilibré est actuellement un domaine en plein essor, avec de nombreuses directions théoriques et applicatives qui n'ont pas été pleinement explorées. Par exemple, les méthodes actuelles se limitent principalement aux tâches multimodales typiques, qui sont principalement des tâches discriminatives et quelques tâches génératives. De plus, les grands modèles multimodaux doivent également combiner des données modales avec des qualités différentes. Sur cette base, il est prévu d'étendre les modèles existants dans des scénarios de grands modèles multimodaux. Rechercher ou concevoir de nouvelles solutions.
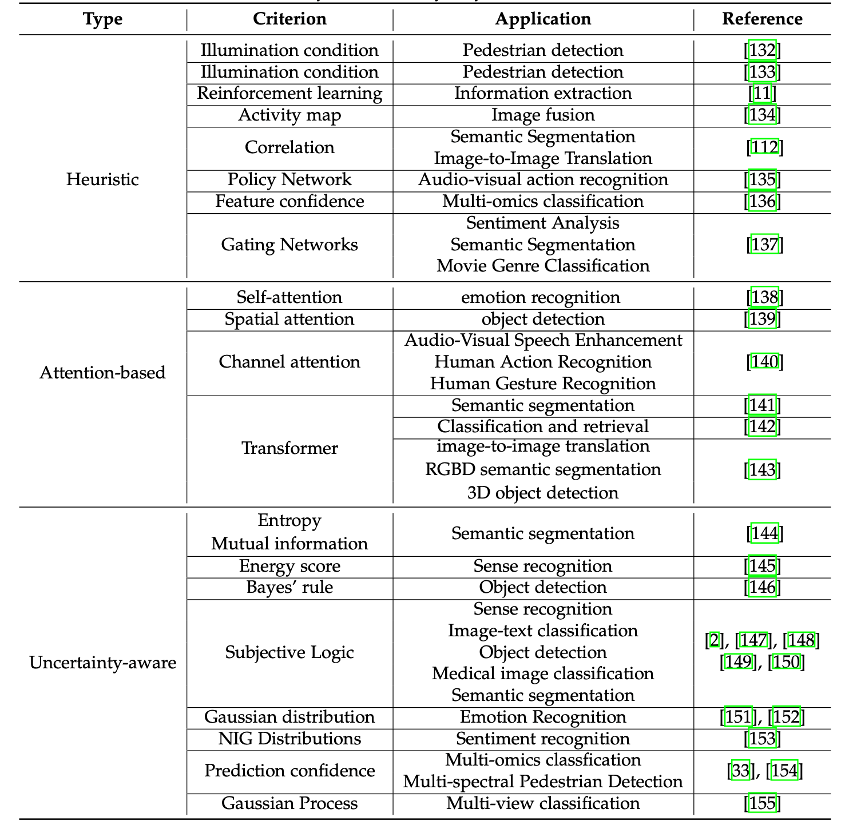
Méthode de fusion multimodale dynamiqueDonnées multimodales dynamiques
fait référence au fait que la qualité des modalités varie selon l'entrée exemples et scénarios Changements dynamiques. Par exemple, dans des scénarios de conduite autonome, le système obtient des informations sur la surface de la route et les cibles grâce à des capteurs RVB et infrarouges. Dans de bonnes conditions d'éclairage, la caméra RVB peut mieux soutenir la prise de décision du système intelligent car elle peut capturer la richesse des textures et des couleurs. informations de la cible ; Cependant, la nuit, lorsque la lumière est insuffisante, les informations de perception fournies par le capteur infrarouge sont plus fiables. Comment permettre au modèle de percevoir automatiquement les changements de qualité des différentes modalités, afin d'effectuer une fusion précise et stable, est la tâche principale de la méthode de fusion multimodale dynamique. Tableau 4. Classification des méthodes de fusion multimodale dynamique
Les méthodes de fusion multimodale dynamique peuvent être grossièrement divisées en trois catégories :
(1) Méthode de fusion dynamique heuristique :
La fusion dynamique heuristique La méthode repose sur la compréhension du concepteur d'algorithmes du scénario d'application du modèle multimodal et est généralement obtenue en introduisant un mécanisme de fusion dynamique
Par exemple, dans la tâche de détection de cible multimodale de la collaboration RVB/signal thermique, les chercheurs ont conçu de manière heuristique un module de perception de la lumière pour évaluer dynamiquement la situation d'éclairage de l'image d'entrée et ajuster dynamiquement les poids RVB et Fusion. de modalités thermiques pour l’adaptation environnementale. Lorsque la luminosité est élevée, le mode RVB est principalement utilisé pour la prise de décision, et vice versa, le mode thermique est principalement utilisé pour la prise de décision. (2) Méthode de fusion dynamique basée sur le mécanisme d'attention : La méthode de fusion dynamique basée sur le mécanisme d'attention se concentre principalement sur la
fusion de la couche de présentation
. Le mécanisme d'attention lui-même a des caractéristiques dynamiques, il peut donc être naturellement utilisé dans des tâches de fusion dynamique multimodale. L'attention personnelle, l'attention spatiale, l'attention du canal et le transformateur et d'autres mécanismes sont largement utilisés dans la construction de modèles de fusion multimodaux. De telles méthodes apprennent automatiquement à effectuer une fusion dynamique, en fonction des objectifs des tâches. La fusion basée sur le mécanisme d'attention peut s'adapter dans une certaine mesure à des données multimodales dynamiques de faible qualité en l'absence de conseils explicites ou heuristiques.
(3) Méthodes de fusion dynamique tenant compte de l'incertitude :
Les méthodes de fusion dynamique tenant compte de l'incertitude ont souvent des
mécanismes de fusion plus clairs et explicables
. Différentes des modes de fusion complexes basés sur des mécanismes d'attention, les méthodes de fusion dynamique tenant compte de l'incertitude s'appuient sur des estimations d'incertitude des modalités (telles que les preuves, l'énergie, l'entropie, etc.) pour s'adapter aux données multimodales de faible qualité. Plus précisément, la perception de l'incertitude peut être utilisée pour caractériser les changements de qualité de chaque mode des données d'entrée. Lorsque la qualité d'une certaine modalité de l'échantillon d'entrée devient faible, l'incertitude de la prise de décision du modèle basée sur cette modalité devient plus élevée, fournissant des indications claires pour la conception ultérieure du mécanisme de fusion. De plus, par rapport aux heuristiques et aux mécanismes d’attention, les méthodes de fusion dynamique tenant compte de l’incertitude peuvent offrir de bonnes garanties théoriques.
Bien que la supériorité des méthodes de fusion dynamique tenant compte de l'incertitude ait été prouvée expérimentalement et théoriquement dans les tâches de fusion multimodales traditionnelles, cependant, dans les modèles multimodaux de In SOTA (non limitées aux modèles de fusion, tels que CLIP/BLIP, etc.), les idées dynamiques ont également un grand potentiel d'exploration et d'application. De plus, les mécanismes de fusion dynamique avec des garanties théoriques sont souvent limités au niveau décisionnel. Comment les faire fonctionner au niveau de la représentation mérite également d'être réfléchi et exploré. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Périphériques technologiques
Périphériques technologiques


















 Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
 Bitwise: les entreprises achètent un bitcoin une grande tendance négligée
Mar 05, 2025 pm 02:42 PM
Bitwise: les entreprises achètent un bitcoin une grande tendance négligée
Mar 05, 2025 pm 02:42 PM
 Dépassant considérablement la SFT, le secret derrière O1 / Deepseek-R1 peut également être utilisé dans les grands modèles multimodaux
Mar 12, 2025 pm 01:03 PM
Dépassant considérablement la SFT, le secret derrière O1 / Deepseek-R1 peut également être utilisé dans les grands modèles multimodaux
Mar 12, 2025 pm 01:03 PM
 Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
 Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
 Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
 CONTRIBLÉE DE MADIFICATION DE LA ROUTE TYPECHO: Pourquoi mon / Test / Tag / son / 10086 correspondant à TestTagIndex au lieu de TestTagPage?
Apr 01, 2025 am 09:03 AM
CONTRIBLÉE DE MADIFICATION DE LA ROUTE TYPECHO: Pourquoi mon / Test / Tag / son / 10086 correspondant à TestTagIndex au lieu de TestTagPage?
Apr 01, 2025 am 09:03 AM
 Dessin graphique de sablier Python: comment éviter les erreurs variables non définies?
Apr 01, 2025 pm 06:27 PM
Dessin graphique de sablier Python: comment éviter les erreurs variables non définies?
Apr 01, 2025 pm 06:27 PM
