
 Périphériques technologiques
IA
Application d'algorithmes dans la construction de 58 plateformes de portraits
Périphériques technologiques
IA
Application d'algorithmes dans la construction de 58 plateformes de portraits
Application d'algorithmes dans la construction de 58 plateformes de portraits


1. Le contexte de la construction de la plateforme 58 portraits
Tout d'abord, permettez-moi de partager avec vous le contexte de la construction de la plateforme 58 portraits.
1. Plateforme de profilage traditionnelle
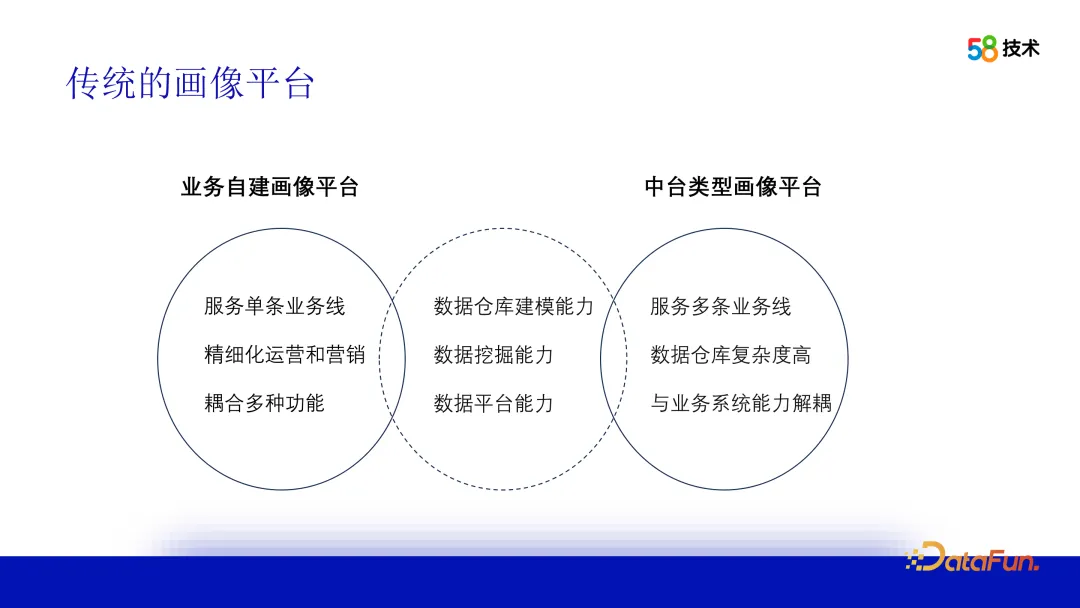
Construire une plate-forme de profilage d'utilisateurs repose sur des capacités de modélisation d'entrepôt de données, d'intégration de données multilignes et de création de portraits d'utilisateurs précis. également requis, comprendre le comportement, les intérêts et les besoins des utilisateurs et fournir des capacités côté algorithme. Enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de portrait d'utilisateur et fournir des services de portrait. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales.
2.58 L'arrière-plan de la construction du portrait de la plate-forme intermédiaire

58 La construction de la plate-forme de portraits d'utilisateurs est principalement due aux besoins commerciaux suivants :
- Recommandation personnalisée : le côté commercial doit créer des milliers de personnes basées sur des portraits d'utilisateurs Des milliers d'aspects de la distribution de contenu.
- Fonctionnement raffiné : le fonctionnement du produit nécessite que la plate-forme de portrait fournisse des fonctions telles que l'analyse des foules et la sélection des foules afin de mener des activités opérationnelles plus raffinées pour différents groupes de personnes.
- Croissance de la valeur utilisateur : une forte croissance du trafic est passée. Comment utiliser la plateforme de portrait pour augmenter la valeur des utilisateurs existants est un besoin urgent.
3. Vientiane
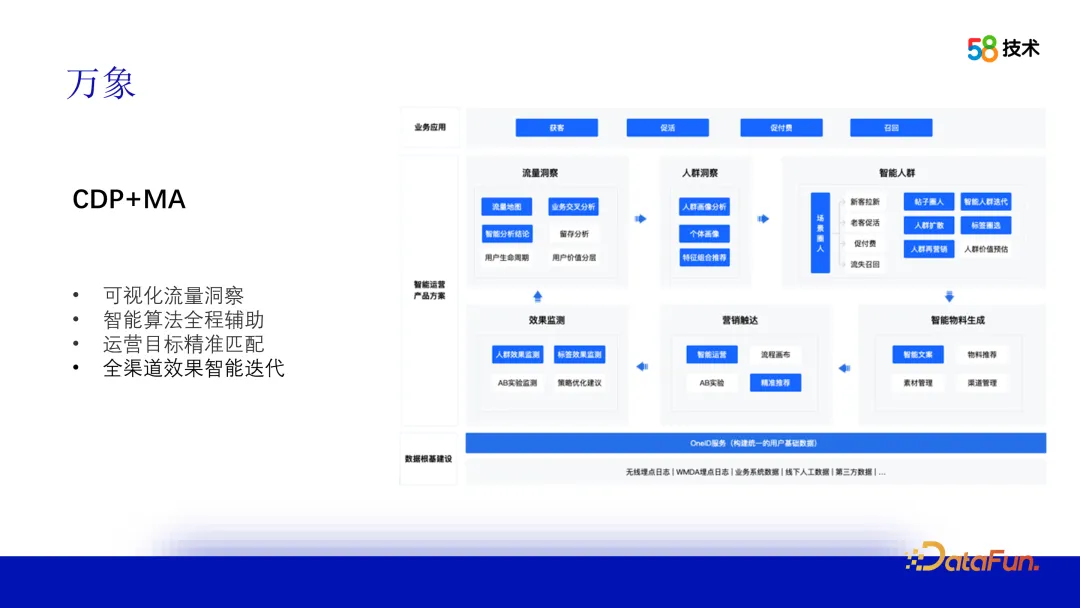
Afin de résoudre les besoins commerciaux actuels et les défis de l'environnement externe, nous avons proposé UA+CDP+MA, un ensemble de solutions de plateforme de portrait d'utilisateur. Utilisez le service OneID pour créer des données de base sur le portrait des utilisateurs, combiner des informations sur le trafic et les foules, utiliser des algorithmes pour générer intelligemment des foules et faire correspondre les matériaux pour un marketing précis. Dans le même temps, surveillez l'effet et recyclez les données pour optimiser la stratégie et itérer la foule. Fournir des solutions de croissance intelligentes aux parties commerciales afin de réaliser des opérations précises et une croissance commerciale.
2. Le rôle de l'algorithme dans la construction de 58 plateformes de portraits

La construction du côté algorithme dans 58 plateformes de portraits d'utilisateurs comprend principalement deux aspects, l'un est la construction de système d'étiquetage, L'autre est la construction de capacités de plate-forme.
1. Construction du système de balises
Le système de balises de Vientiane comprend plusieurs catégories telles que les attributs sociaux, la situation géographique, les habitudes comportementales, les attributs de préférence, la stratification des utilisateurs, etc., avec un total de plus de 1 500 balises. Nous les divisons en deux types selon la méthode de production :
- Balises de faits : les étudiants de Shucang utilisent des statistiques ou des règles pour développer et produire via SQL, etc.
- Balise d'algorithme : l'équipe d'algorithmes traite et produit via l'exploration de données et d'autres moyens.
2. Exemples de balises d'algorithme
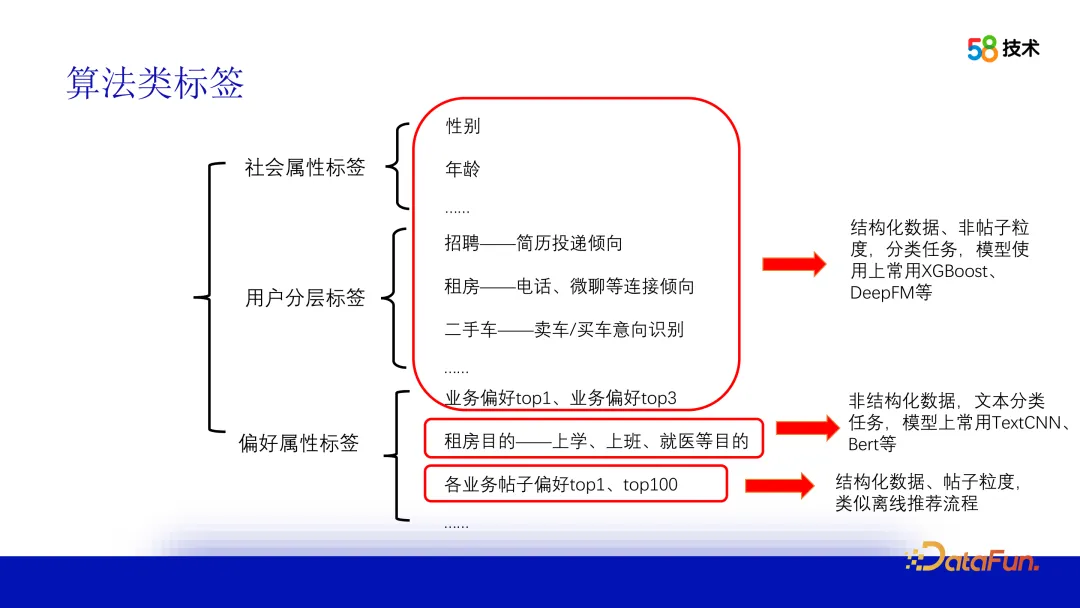
Les balises d'algorithme peuvent être classées en fonction de la source de données et de la granularité. Comme le sexe, l'âge, la tendance commerciale et d'autres étiquettes, la source de données est généralement des données structurées, qui sont souvent traitées comme une tâche de classification, et le modèle peut utiliser XGBoost, DeepFM, etc. Il existe également des balises de but de location, qui doivent identifier le but de l'utilisateur à partir du texte des publications parcourues par l'utilisateur. La source de données de ce type de balise est constituée de données non structurées, qui peuvent être traitées à l'aide d'une classification de texte et d'autres méthodes. Dans nos balises de préférence de contenu, si les utilisateurs préfèrent les publications topN dans différentes entreprises, nous devons créer un processus de recommandation hors ligne pour produire de telles balises.
3. Prenez la balise de préférence de contenu comme exemple pour expliquer le processus d'étiquetage
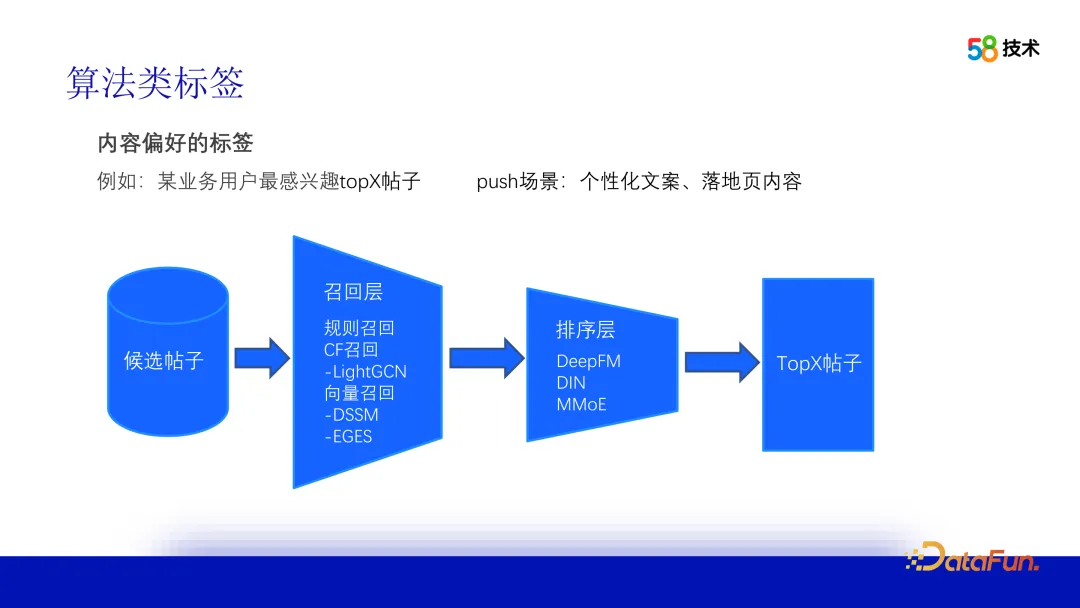
Prenons l'exemple de la balise de préférence de contenu. Pour produire cette balise, un processus de recommandation hors ligne doit être établi. Face à des millions de messages ou plus, nous effectuons d'abord une sélection préliminaire jusqu'à l'étape de rappel, en utilisant un filtrage populaire, des règles, collaboratif et d'autres méthodes, telles que le réseau neuronal convolutif (LightGCN) et le modèle des tours jumelles (DSSM) dans la figure. Ensuite, sur la base des publications rappelées, l'approche Pointwise est utilisée pour trier le modèle CTR. Le résultat final correspond aux N principales publications qui intéressent le plus les utilisateurs. Dans des applications pratiques, en prenant le scénario push comme exemple, les attributs clés peuvent être extraits des publications Top 1 pour générer une copie personnalisée. Dans le même temps, la page de destination peut être la page de détails de la publication Top 1 ou la page de liste des publications Top N.

Lors de la création de balises de préférence de contenu, en tenant compte des caractéristiques géographiques et de catégorie de l'entreprise locale de 58, les utilisateurs ne sont généralement intéressés que par les publications de régions ou de catégories spécifiques dans les recommandations. Ainsi, lors de la vectorisation du rappel (comme par exemple en utilisant le modèle EGES), il peut y avoir un grand nombre de posts hors site ou hors catégorie. Pour résoudre ce problème, nous représentons les informations sur la ville en hexadécimal, remplaçons 0 par -1, puis intégrons cet encodage directement dans le vecteur généré précédemment. Cela peut garantir que les publications dans la même ville ou dans le même but sont incluses dans la similarité. Les calculs présentent la plus grande similitude entre eux, améliorant ainsi la précision du rappel et de la recommandation.
Lors de l'étape de tri, les informations multimodales, y compris le contenu textuel, sont utilisées pour améliorer la précision des recommandations. Par exemple, le titre du message, en tant que fonctionnalité de texte, peut être représenté par intégration à l'aide de modèles pré-entraînés tels que BERT et M3E. Cependant, cela pose un défi en termes de ressources informatiques en raison du grand nombre de postes. Pour résoudre ce problème, nous utilisons Spark NLP, une bibliothèque de traitement du langage naturel basée sur Apache Spark Machine Learning. Bien qu'il n'y ait pas de modèle BERT chinois dans la bibliothèque native, grâce à certaines transformations, nous l'avons appliqué avec succès à l'inférence hors ligne à grande échelle.
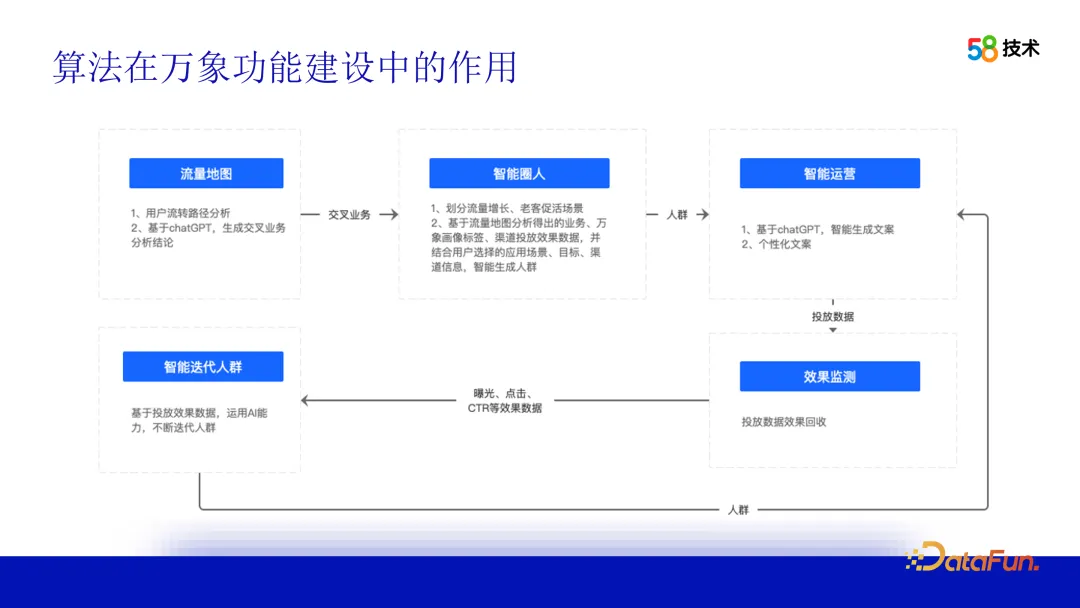
Les algorithmes jouent également un rôle central dans la construction fonctionnelle de la plateforme de portraits d'utilisateurs de 58 villes. En prenant comme exemple les capacités d'exploitation intelligentes, nous utilisons des cartes de trafic pour identifier les corrélations entre différentes entreprises et fournir des suggestions ou des conclusions opérationnelles aux parties commerciales. Sur la base de ces suggestions, le côté commercial peut générer directement un package de foule d'opérateurs via la fonction de cercle intelligent et le connecter aux canaux correspondants pour la livraison. L'effet de livraison peut être surveillé via la plateforme et optimisé de manière itérative en fonction des données d'effet pour améliorer continuellement les effets opérationnels.
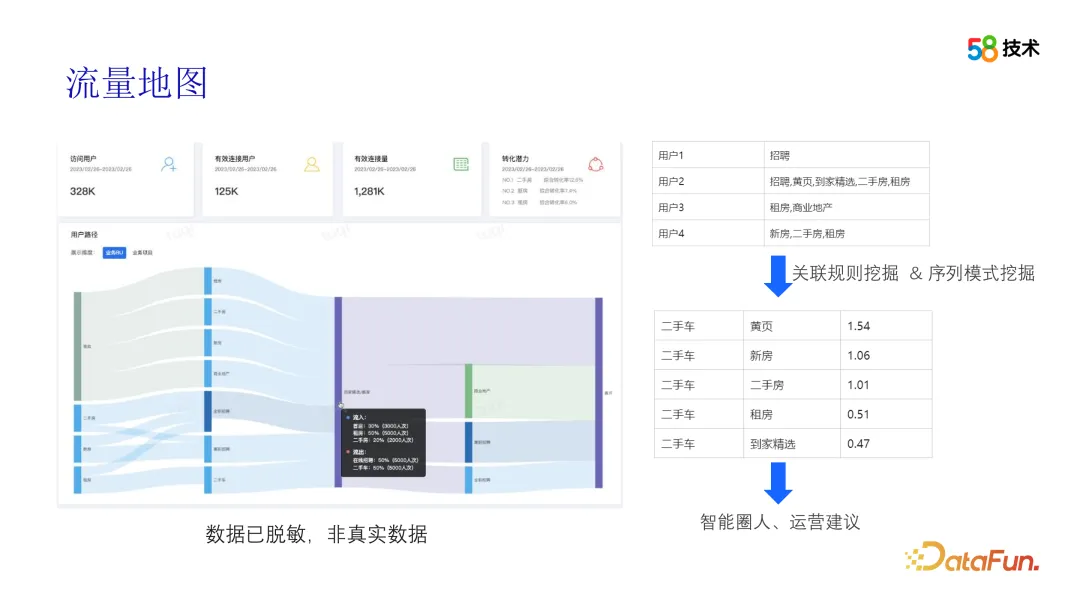
Comment fonctionne l'algorithme ? Ensuite, nous le présenterons en plusieurs parties. Le premier est la carte du trafic. Nous utilisons la technologie d'exploration de données et de visualisation de données OLAP pour effectuer une analyse approfondie du comportement de navigation des utilisateurs de 58APP entre différentes entreprises. En analysant et en traitant ces données, les parcours des utilisateurs entre différentes entreprises peuvent être affichés, offrant ainsi à l'équipe opérationnelle une vue intuitive du comportement des utilisateurs. Dans ce processus, les algorithmes peuvent non seulement nous aider à identifier les modèles de comportement des utilisateurs, mais également à extraire des corrélations entre différentes entreprises grâce à l'analyse des corrélations et à d'autres technologies. Ces corrélations nous fournissent de précieuses suggestions opérationnelles et soutiennent l’équipe opérationnelle dans les opérations transversales.
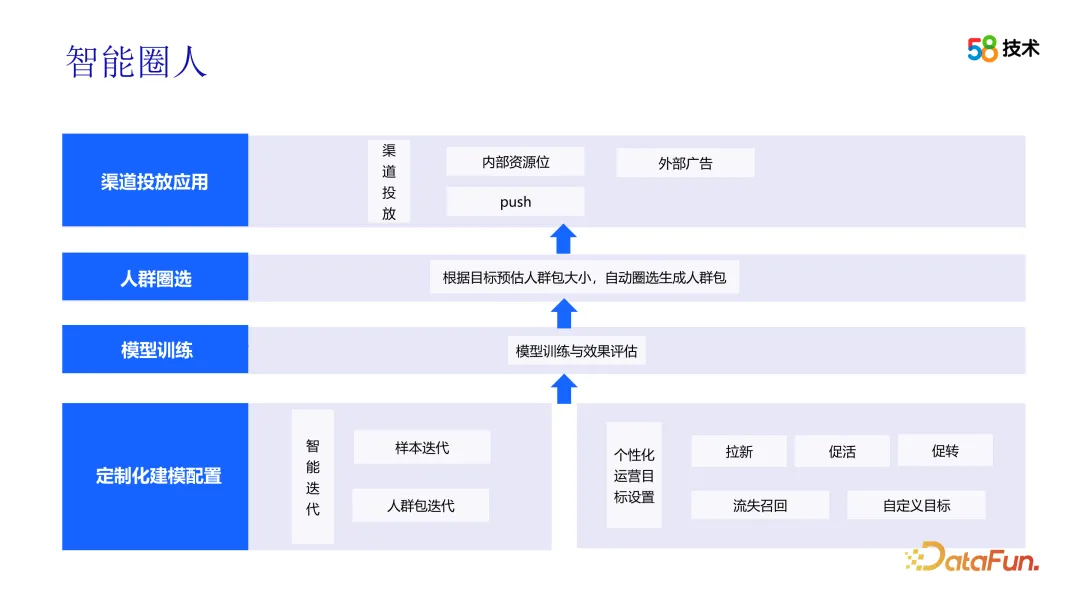
Après avoir reçu les suggestions d'opération, l'équipe d'opération peut utiliser la fonction de cercle intelligent pour sélectionner le groupe cible. Afin d'atteindre cet objectif, l'équipe opérationnelle doit d'abord configurer des objectifs opérationnels personnalisés et préciser s'il s'agit d'attirer de nouveaux clients, de promouvoir l'activité ou de favoriser les conversions, etc. Ensuite, vous devez définir l'effet souhaité, y compris la taille du package de foule et l'effet de livraison attendu. En outre, l’équipe opérationnelle doit également sélectionner des canaux de diffusion appropriés pour garantir que le groupe cible puisse recevoir des informations pertinentes sur les activités opérationnelles.
Le processus de génération de packages de foule est une boîte noire pour l'équipe des opérations. Pour résoudre ce problème, nous fournissons davantage d'explications et de descriptions des principes et des étapes de l'algorithme afin que les équipes opérationnelles puissent mieux comprendre et appliquer la technologie. Dans le même temps, nous fournissons davantage d’outils et d’interfaces visuels pour aider l’équipe opérationnelle à visualiser et analyser intuitivement les caractéristiques et les effets des paquets de foule.
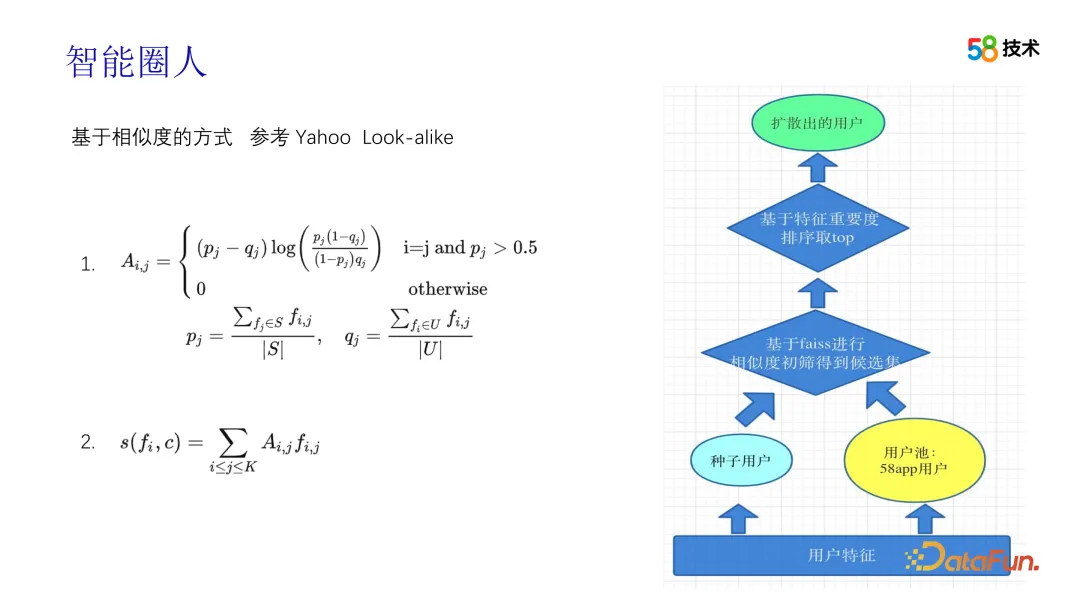
Dans le processus de génération de paquets de foule, nous utilisons principalement la technologie Look-alike. Nous avons traversé plusieurs étapes dans l'évolution de cette technologie. Au début, nous avons appris de la solution de Yahoo et divisé la sortie du package crowd en modules de rappel et de tri. Le module de rappel construit d'abord les vecteurs de caractéristiques de tous les utilisateurs, puis utilise minHash et la technologie de hachage sensible locale pour compresser les vecteurs de caractéristiques, et réalise une récupération similaire à k-NN grâce à une méthode similaire au clustering et au bucketing, et calcule rapidement la relation entre les graines. utilisateurs et sur la base de la similarité par paire entre les groupes candidats, topN est sélectionné comme groupe de rappel pour chaque utilisateur de départ. Lors de l'étape de tri, la valeur de l'information est d'abord utilisée pour filtrer les fonctionnalités, puis les scores sont calculés en fonction des fonctionnalités filtrées, et enfin les scores sont triés pour finalement produire un package de foule. Tout au long du processus, l’algorithme a joué un rôle clé en garantissant l’exactitude et l’efficacité du package crowd.
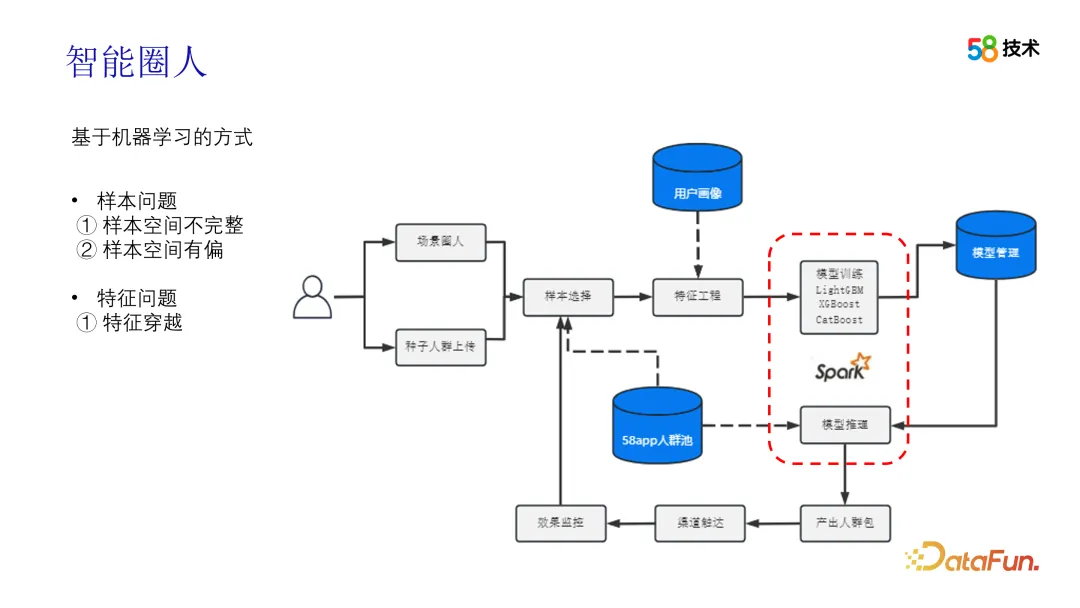
En plus des solutions basées sur la similarité, les méthodes basées sur l'apprentissage automatique donnent également de bons résultats. Dans les applications pratiques, les utilisateurs peuvent lancer des demandes via des personnes en cercle de scène ou via le téléchargement de masse. La différence est de savoir si la foule de graines est téléchargée par les utilisateurs ou automatiquement exploitée par nous. Après avoir obtenu la population de semences, c'est-à-dire les échantillons positifs, nous devons sélectionner des échantillons négatifs. Nous pouvons utiliser un échantillonnage négatif aléatoire global violent, ou nous pouvons utiliser des algorithmes tels que l'apprentissage PU ou TSA pour compléter la sélection des échantillons négatifs. Vient ensuite l'étape de sélection des fonctionnalités, qui est divisée en deux options. L'une consiste à préparer à l'avance les fonctionnalités sélectionnées manuellement. Après l'ingénierie des fonctionnalités fixes, des modèles tels que DeepFM peuvent être utilisés pour terminer la formation et l'estimation du CTR, et TopN est sélectionné comme. le package crowd basé sur CTR ; Une autre option consiste à utiliser toutes les balises comme fonctionnalités, à sélectionner et à éliminer automatiquement les fonctionnalités via les valeurs IV et les corrélations, puis à utiliser le framework AutoML pour terminer l'ingénierie des fonctionnalités et la formation du modèle, et enfin effectuer l'inférence sur la 58App. pool de foule et sortie basés sur le package TopN Crowd, connectez-vous au canal pour contacter et enfin collectez les données d'effet de livraison pour terminer l'itération de sélection d'échantillon.
Il y a quelques points dignes d'attention dans le schéma ci-dessus. Le premier est l'itération des échantillons. Lors de la récupération des données d'effet, non seulement les données d'exposition doivent être filtrées, mais également les données non exposées, c'est-à-dire le biais d'exposition. être traité par débias. Dans le même temps, l'effet après itération doit être évalué et vérifié hors ligne pour garantir l'effet de l'itération. De plus, le problème du parcours doit également être considéré en termes de fonctionnalités, en particulier dans la nouvelle scène, où le facteur temps de sélection des fonctionnalités doit être pris en compte.
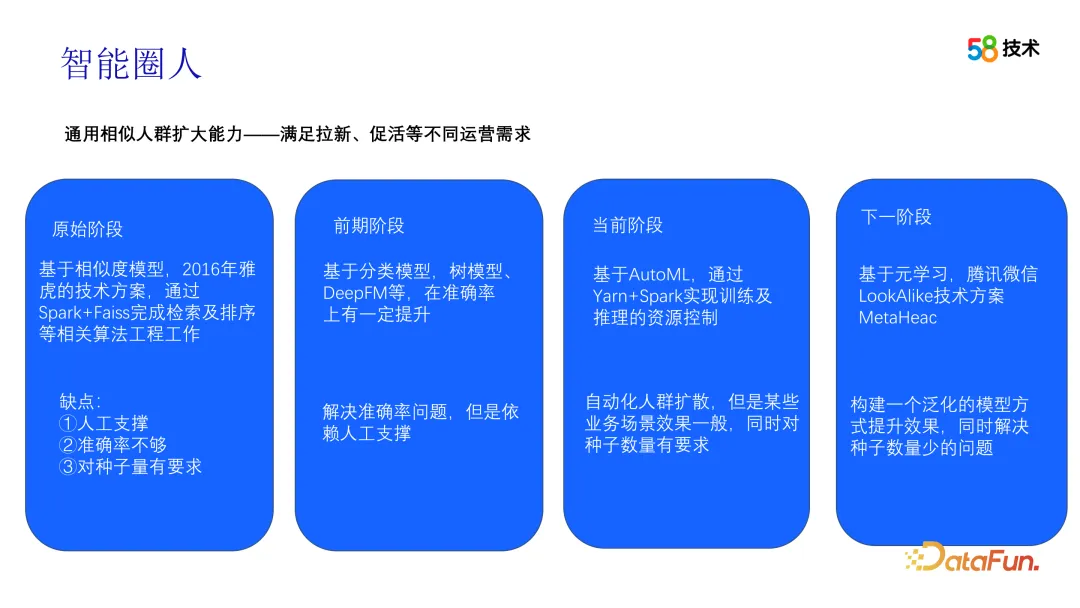
À mesure que de plus en plus de données sont accumulées dans des scénarios opérationnels, nous commençons à essayer d'utiliser ces données pour mener des expériences hors ligne afin d'optimiser notre plan d'itération. L’une d’elles est la méthode Look-alike basée sur Tencent WeChat, qui adopte une méthode de méta-apprentissage. Plus précisément, cette méthode crée un modèle généralisé, termine la construction du modèle lors de l'étape hors ligne, puis utilise une petite quantité d'ensembles de données pour entraîner le modèle personnalisé et effectuer un travail d'inférence lors de l'étape en ligne. Cette méthode peut résoudre le problème du surajustement du modèle lorsque la taille de l’échantillon est relativement petite. La diffusion de foule multi-scénarios et multi-cibles est également l’une de nos prochaines orientations.
3. 58 cas d'application de la plateforme de portrait
1. Placement personnalisé des ressources
Le placement personnalisé des ressources dans 58App comprend l'écran d'ouverture, la position de la bannière et la fenêtre flottante, les cartes de flux de frais, etc. , tous utilisent les fonctions correspondantes de la plate-forme de portrait de 58 utilisateurs. Par exemple, l'opération de prix utilise la capacité de sélection d'étiquettes de la plate-forme de portrait pour générer des packages de foule et diffuser du contenu spécifique pour eux, complétant ainsi le raffinement de milliers de personnes.
2. Push personnalisé
Notre plateforme de portraits est également entièrement connectée à la plateforme push de 58. Les étudiants en opération peuvent créer des groupes via la sélection du cercle de Vientiane ou des sosies, configurer une rédaction personnalisée et les atteindre via des utilisateurs push pour atteindre des objectifs opérationnels. .
3. Recommandation de recherche
La recommandation de recherche est l'application la plus courante basée sur les portraits d'utilisateurs. 58 Les deux entreprises de voitures neuves et de voitures d'occasion ne disposent pas de personnel algorithmique, mais elles souhaitent également créer des applications personnalisées, elles ont donc accédé aux balises de préférence de contenu mentionnées ci-dessus. La balise TopN de préférence de contenu est utilisée dans les domaines de ressources tels que les recommandations de voitures neuves et les recommandations associées sur la page d'accueil. Dans la position de recherche de voitures d'occasion, cette étiquette est également utilisée dans les invites du champ de recherche et de la série de voitures associée sur la page de découverte de recherche. Par rapport à la méthode précédente d'utilisation des règles, l'accès aux balises de préférence de contenu comme solution dès le début du projet a également donné de bons résultats.
4. Perspectives et résumé
La plate-forme de portrait actuelle de 58 possède déjà des capacités de plate-forme de portrait communes dans l'industrie, et grâce à la bénédiction de l'algorithme, elle a atteint un fonctionnement intelligent et d'autres capacités. Il améliore non seulement les effets opérationnels du côté commercial, mais fournit également aux utilisateurs des services personnalisés tout en apportant une meilleure expérience utilisateur. Ensuite, nous coopérerons en profondeur avec les entreprises pour explorer davantage de scénarios d'application, résumer et affiner, optimiser et innover au cours du processus de coopération, et mettre à niveau la technologie pour répondre aux divers besoins et défis. Nous sommes impatients de créer de meilleures solutions pour les utilisateurs et les entreprises. Grande valeur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le dernier classement des dix meilleures applications de trading en 2025
Mar 11, 2025 pm 04:06 PM
Le dernier classement des dix meilleures applications de trading en 2025
Mar 11, 2025 pm 04:06 PM
Les dix applications de trading dans le cercle de la monnaie sont: 1. Le classement est basé sur la considération complète de la force technique, de l'expérience utilisateur, de la sécurité, de la sélection des devises, de la conformité et d'autres facteurs de l'échange.
 Comment intégrer efficacement les services Node.js ou Python sous l'architecture LAMP?
Apr 01, 2025 pm 02:48 PM
Comment intégrer efficacement les services Node.js ou Python sous l'architecture LAMP?
Apr 01, 2025 pm 02:48 PM
De nombreux développeurs de sites Web sont confrontés au problème de l'intégration de Node.js ou des services Python sous l'architecture de lampe: la lampe existante (Linux Apache MySQL PHP) a besoin d'un site Web ...
 Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
L'exécution du projet H5 nécessite les étapes suivantes: Installation des outils nécessaires tels que le serveur Web, Node.js, les outils de développement, etc. Créez un environnement de développement, créez des dossiers de projet, initialisez les projets et écrivez du code. Démarrez le serveur de développement et exécutez la commande à l'aide de la ligne de commande. Aperçu du projet dans votre navigateur et entrez l'URL du serveur de développement. Publier des projets, optimiser le code, déployer des projets et configurer la configuration du serveur Web.
 Depin ouvre la voie, l'IA aide: un coup d'œil sur la carte Depai de la physique décentralisée et de l'intelligence artificielle
Mar 05, 2025 am 09:18 AM
Depin ouvre la voie, l'IA aide: un coup d'œil sur la carte Depai de la physique décentralisée et de l'intelligence artificielle
Mar 05, 2025 am 09:18 AM
L'intelligence artificielle physique décentralisée (DEPAI) mène une nouvelle direction dans le développement de l'intelligence artificielle et fournit des solutions innovantes pour le contrôle des robots et des infrastructures connexes. Cet article mènera des discussions approfondies sur DePAI et ses applications dans les domaines de l'acquisition de données, du fonctionnement à distance et de l'intelligence spatiale, et analysera ses perspectives de développement. Comme l'a dit le PDG de Nvidia, Huang Renxun, le "moment Chatgpt" dans le domaine des robots généraux arrivera bientôt. Le processus de développement de l'intelligence artificielle, du matériel aux logiciels, se dirige maintenant vers le monde physique. À l'ère de la popularité des robots futurs, DePai offre des opportunités importantes pour construire un écosystème de l'intelligence artificielle physique basée sur Web3, en particulier lorsque les forces centralisées n'ont pas encore complètement dominé le marché. La large application d'agents autonomes de l'intelligence artificielle physique apportera des robots,
 Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Description de la question: Comment obtenir les données de la région d'expédition de la version à l'étranger? Y a-t-il des ressources prêtes à l'emploi disponibles? Soyez précis dans le commerce électronique transfrontalier ou les entreprises mondialisées ...
 Comment APACHE ou NGINX fonctionne-t-il avec PHP: Quelle est la différence entre MOD_PHP5, PHP-CGI et PHP-FPM?
Apr 01, 2025 pm 12:15 PM
Comment APACHE ou NGINX fonctionne-t-il avec PHP: Quelle est la différence entre MOD_PHP5, PHP-CGI et PHP-FPM?
Apr 01, 2025 pm 12:15 PM
Le mécanisme de travail collaboratif entre Apache ou Nginx et PHP: la comparaison de MOD_PHP5, PHP-CGI et PHP-FPM est d'utiliser Apache ou Nginx pour créer un serveur Web et utiliser PHP pour le backend ...
 Depin ouvre la voie, l'IA aide: un coup d'œil sur le graphique de dépai de l'intelligence artificielle physique décentralisée
Mar 05, 2025 pm 12:48 PM
Depin ouvre la voie, l'IA aide: un coup d'œil sur le graphique de dépai de l'intelligence artificielle physique décentralisée
Mar 05, 2025 pm 12:48 PM
La montée de l'intelligence artificielle physique décentralisée (DEPAI): L'intégration des robots et de la technologie de l'intelligence artificielle Web3 change chaque jour qui passe, et l'intelligence artificielle physique décentralisée (DEPAI) a apporté des solutions révolutionnaires au contrôle des robots et de l'intelligence artificielle physique. DePai prospère de l'acquisition de données réelles à des opérations robotiques intelligentes basées sur un déploiement décentralisé des infrastructures physiques (DEPIN). Comme l'a dit Huang Renxun, le PDG de Nvidia: "Le moment de Chatgpt dans le domaine des robots généraux arrive bientôt." À l'avenir, l'intelligence artificielle physique autonome
 De quel pays est le Nexo Exchange?
Mar 05, 2025 pm 05:09 PM
De quel pays est le Nexo Exchange?
Mar 05, 2025 pm 05:09 PM
Nexo Exchange: Plateforme de prêt de crypto-monnaie suisse Analyse approfondie Nexo est une plate-forme qui fournit des services de prêt de crypto-monnaie, en soutenant l'hypothèque et les prêts de plus de 40 actifs cryptographiques, devises fiduciaires et de stablescoines. Il domine les marchés européens et américains et s'engage à améliorer l'efficacité, la sécurité et la conformité de la plate-forme. De nombreux investisseurs veulent savoir où est enregistré l'échange Nexo et la réponse est: la Suisse. Nexo a été fondée en 2018 par la société suisse FinTech Credssimo. NEXO Exchange Emplacement géographique et réglementation: Nexo a son siège à Zug, en Suisse, une région bien connue adaptée aux crypto-monnaies. La plate-forme coopère activement à la supervision de divers gouvernements et a été dans le réseau d'application de la loi sur le crime financier des États-Unis (FINCEN) et le Canadian Finance
