
 Périphériques technologiques
IA
Modèle de base de grand graphique open source de HKU, OpenGraph : forte capacité de généralisation, propagation vers l'avant pour prédire de nouvelles données
Périphériques technologiques
IA
Modèle de base de grand graphique open source de HKU, OpenGraph : forte capacité de généralisation, propagation vers l'avant pour prédire de nouvelles données
Modèle de base de grand graphique open source de HKU, OpenGraph : forte capacité de généralisation, propagation vers l'avant pour prédire de nouvelles données

Le problème du manque de données dans le domaine de l'apprentissage des graphes a été résolu grâce à de nouvelles astuces !
OpenGraph, un modèle de base basé sur des graphiques spécialement conçu pour la prédiction zéro sur une variété d'ensembles de données graphiques.
L'équipe de Chao Huang, responsable du Hong Kong Big Data Intelligence Laboratory, a également proposé des techniques d'amélioration et d'ajustement du modèle afin d'améliorer l'adaptabilité du modèle à de nouvelles tâches.
Actuellement, ce travail a été téléchargé sur GitHub.
Présentation des techniques d'augmentation des données. Ce travail explore principalement des stratégies approfondies pour améliorer la capacité de généralisation des modèles graphiques (en particulier lorsqu'il existe des différences significatives entre les données d'entraînement et de test).
OpenGraph est un modèle général de structure de graphe qui effectue une propagation vers l'avant via la prédiction de propagation pour obtenir une prédiction sans échantillon de nouvelles données.
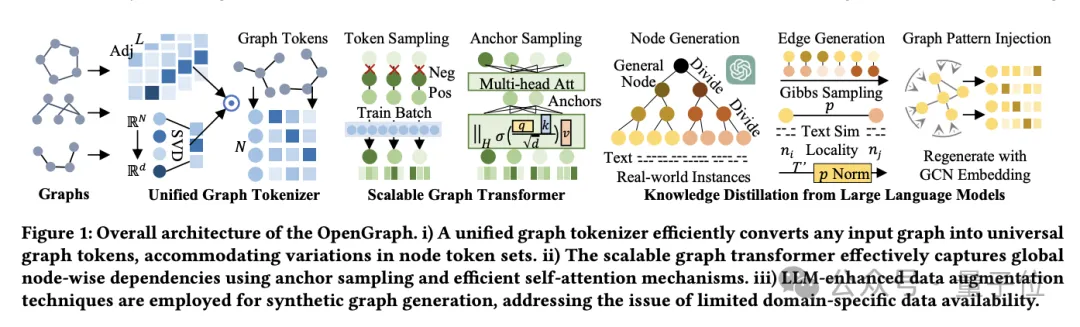
Afin d'atteindre l'objectif, l'équipe a résolu les 3 défis suivants :
- Différences de jetons entre les ensembles de données : Différents ensembles de données graphiques ont souvent des ensembles de jetons graphiques différents, et nous avons besoin du modèle pour être capable de croiser des ensembles de données. Faire des prédictions.
- Modélisation des relations entre nœuds : lors de la création d'un modèle de graphe général, il est crucial de modéliser efficacement les relations entre nœuds, ce qui est lié à l'évolutivité et à l'efficacité du modèle.
- Pénibilité des données : Face au problème de l'acquisition de données, nous effectuons l'amélioration des données via de grands modèles de langage pour simuler des relations complexes entre structures de graphes et améliorer la qualité de la formation des modèles.
Grâce à une série de méthodes innovantes, telles que le BERT Tokenizer prenant en compte la topologie et le Transformer graphique basé sur des ancres, OpenGraph relève efficacement les défis ci-dessus. Les résultats des tests sur plusieurs ensembles de données démontrent l'excellente capacité de généralisation du modèle et permettent une évaluation efficace de la capacité de généralisation des couleurs du modèle.
Modèle OpenGraph
L'architecture du modèle OpenGraph se compose principalement de 3 parties principales :
- Unified graph Tokenizer.
- Transformateur graphique extensible.
- Technologie de distillation des connaissances basée sur un grand modèle de langage.
Tout d’abord, parlons du graphe unifié Tokenizer.
Afin de s'adapter aux différences de nœuds et d'arêtes dans différents ensembles de données, l'équipe a développé le graphe unifié Tokenizer, qui normalise les données graphiques en séquences de jetons.
Ce processus comprend un lissage matriciel de contiguïté d'ordre élevé et un mappage tenant compte de la topologie.
Le lissage de la matrice de contiguïté d'ordre élevé utilise la puissance d'ordre élevé de la matrice de contiguïté pour résoudre le problème des connexions clairsemées, tandis que le mappage sensible à la topologie convertit la matrice de contiguïté en une séquence de nœuds et utilise la décomposition rapide des valeurs singulières (SVD) pour minimiser perte d'informations, conservant plus d'informations sur la structure du graphique.
Le second est le transformateur graphique extensible.
Après la tokenisation, OpenGraph utilise l'architecture Transformer pour simuler les dépendances entre les nœuds, et utilise principalement les technologies suivantes pour optimiser les performances et l'efficacité du modèle :
Premièrement, l'échantillonnage de séquences de jetons utilise la technologie d'échantillonnage pour réduire le nombre de relations dont le modèle a besoin. à traiter, réduisant ainsi les coûts de formation en temps et en espace.
Le second est le mécanisme d'auto-attention de l'échantillonnage d'ancres. Cette méthode réduit encore la complexité de calcul et améliore efficacement l'efficacité de la formation et la stabilité du modèle grâce au transfert d'informations entre les nœuds d'apprentissage par étapes.
La dernière étape est la distillation des connaissances de grands modèles de langage.
Afin de résoudre les problèmes de confidentialité des données et de diversité des catégories rencontrés lors de la formation de modèles de graphes généraux, l'équipe s'est inspirée des capacités de connaissance et de compréhension des grands modèles de langage (LLM) et a utilisé LLM pour générer diverses données de structure de graphe.
Ce mécanisme d'amélioration des données améliore efficacement la qualité et la praticité des données en simulant les caractéristiques des graphiques du monde réel.
L'équipe génère également d'abord un ensemble de nœuds adapté à l'application spécifique, chaque nœud ayant une description textuelle afin de générer des arêtes.
Face à des ensembles de nœuds à grande échelle tels que les plateformes de commerce électronique, les chercheurs gèrent ce problème en subdivisant les nœuds en sous-catégories plus spécifiques.
Par exemple, des « produits électroniques » aux « téléphones mobiles », « ordinateurs portables » spécifiques, etc., ce processus est répété jusqu'à ce que les nœuds soient suffisamment affinés pour être proches des instances réelles.
L'algorithme d'arbre d'invite subdivise les nœuds en fonction de la structure arborescente et génère des entités plus détaillées.
Partez d'une catégorie générale telle que « produit », affinez-la progressivement en sous-catégories spécifiques, et enfin formez un arbre de nœuds.
En ce qui concerne la génération d'arêtes, à l'aide de l'échantillonnage de Gibbs, les chercheurs forment des arêtes basées sur l'ensemble de nœuds généré.
Afin de réduire la charge de calcul, nous ne parcourons pas directement toutes les arêtes possibles via LLM, mais nous utilisons d'abord LLM pour calculer la similarité du texte entre les nœuds, puis utilisons un algorithme simple pour déterminer la relation entre les nœuds.
Sur cette base, l'équipe a introduit plusieurs ajustements techniques :
- Normalisation dynamique des probabilités : Grâce à un ajustement dynamique, la similarité est mappée sur une plage de probabilité plus adaptée à l'échantillonnage.
- Localité du nœud : Présente le concept de localité et établit uniquement des connexions entre des sous-ensembles locaux de nœuds pour simuler la localité du réseau dans le monde réel.
- Injection de modèle de topologie graphique : Utilisez un réseau convolutif de graphique pour modifier la représentation des nœuds afin de mieux s'adapter aux caractéristiques de la structure du graphique et de réduire l'écart de distribution.
Les étapes ci-dessus garantissent que les données graphiques générées sont non seulement riches et diversifiées, mais également proches des modèles de connexion et des caractéristiques structurelles du monde réel.
Vérification expérimentale et analyse des performances
Il convient de noter que cette expérience se concentre sur la formation du modèle OpenGraph à l'aide d'un ensemble de données généré uniquement par LLM et sur son test sur un ensemble de données de scénarios réels diversifiés, couvrant les tâches de classification de nœuds et de prédiction de liens.
Le plan expérimental est le suivant :
Réglage de l'échantillon zéro.
Pour évaluer les performances d'OpenGraph sur des données invisibles, nous entraînons le modèle sur l'ensemble d'entraînement généré, puis l'évaluons sur un ensemble de test du monde réel complètement différent. Il garantit que les données de formation et de test ne se chevauchent pas dans les nœuds, les arêtes et les fonctionnalités.
Moins d'exemples de paramètres.
Considérant qu'il est difficile pour de nombreuses méthodes d'effectuer efficacement une prédiction zéro-shot, nous introduisons un paramètre de quelques-shots Une fois le modèle de base pré-entraîné sur les données de pré-entraînement, des échantillons k-shot sont utilisés pour un réglage précis. .
Les résultats sur 2 tâches et 8 ensembles de tests montrent qu'OpenGraph surpasse considérablement les méthodes existantes en matière de prédiction zéro-shot.
De plus, les modèles pré-entraînés existants fonctionnent parfois moins bien que les modèles formés à partir de zéro sur des tâches inter-ensembles de données.
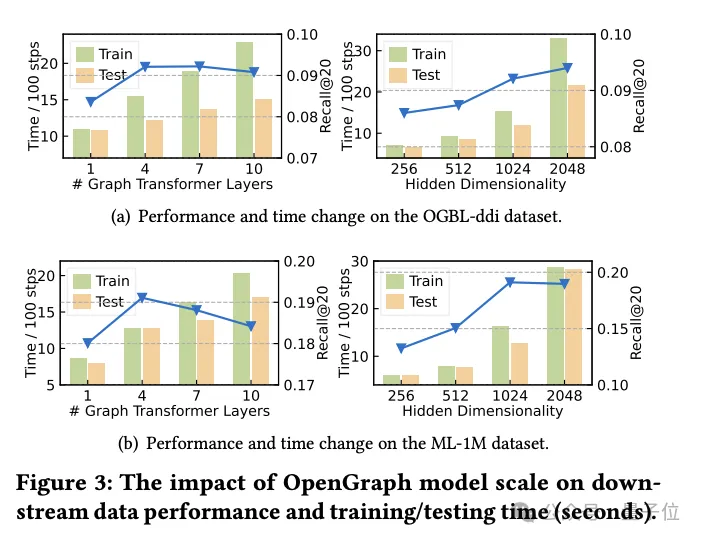
Recherche sur l'impact de la conception du graph Tokenizer
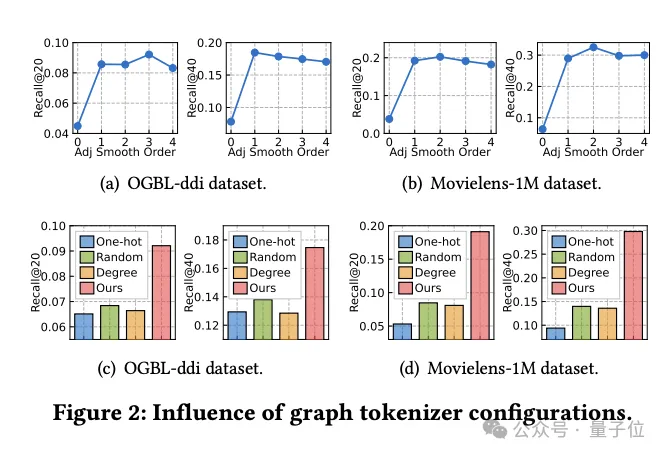
Dans le même temps, l'équipe a exploré comment la conception du graph Tokenizer affecte les performances du modèle.
Tout d'abord, des expériences ont montré que ne pas effectuer de lissage de la matrice de contiguïté (l'ordre de lissage est 0) réduirait considérablement les performances, indiquant la nécessité d'un lissage.
Les chercheurs ont ensuite essayé plusieurs alternatives simples tenant compte de la topologie : des identifiants codés à chaud sur des ensembles de données, une cartographie aléatoire et des représentations basées sur le degré des nœuds.
Les résultats expérimentaux montrent que les performances de ces alternatives ne sont pas idéales.
Plus précisément, la représentation des identifiants dans les ensembles de données est la pire, et la représentation basée sur le degré fonctionne également mal, tandis que la cartographie aléatoire, bien que légèrement meilleure, présente un écart de performances significatif par rapport à la cartographie optimisée tenant compte de la topologie.
Impact des techniques de génération de données
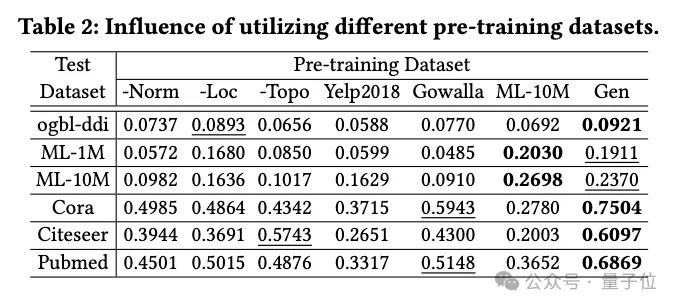
L'équipe a étudié l'impact de différents ensembles de données de pré-formation sur les performances d'OpenGraph, y compris des ensembles de données générés à l'aide de méthodes de distillation des connaissances basées sur LLM, ainsi que plusieurs ensembles de données réels.
Les ensembles de données de pré-formation comparés dans l'expérience incluent l'ensemble de données après suppression d'une certaine technologie de la méthode de génération d'équipe, 2 ensembles de données réels (Yelp2018 et Gowalla) qui ne sont pas liés à l'ensemble de données de test, 1 avec les données de test Définissez un ensemble de données réelles similaire (ML-10M) .
Les résultats expérimentaux montrent que l'ensemble de données généré montre de bonnes performances sur tous les ensembles de tests ; la suppression des techniques de trois générations affecte de manière significative les performances, vérifiant l'efficacité de ces techniques.
Lors d'un entraînement avec des ensembles de données réels (tels que Yelp et Gowalla) qui ne sont pas liés à l'ensemble de test, les performances se dégradent parfois, ce qui peut être dû aux différences de distribution entre les différents ensembles de données.
L'ensemble de données ML-10M obtient les meilleures performances sur des ensembles de données de test similaires tels que ML-1M et ML-10M , soulignant l'importance de la similarité entre les ensembles de données d'entraînement et de test.
Recherche sur la technologie d'échantillonnage Transformer
Dans cette partie de l'expérience, l'équipe de recherche a exploré deux technologies d'échantillonnage utilisées dans le module graphe Transformer :
échantillonnage de séquence de jetons (Seq) et échantillonnage d'ancre (Anc).
Ils ont mené des expériences d'ablation détaillées sur ces deux méthodes d'échantillonnage pour évaluer leur impact spécifique sur les performances du modèle.
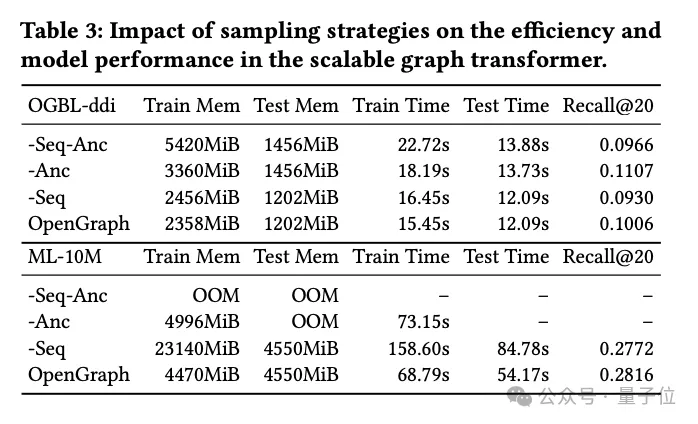
Les résultats expérimentaux montrent que qu'il s'agisse d'un échantillonnage de séquences de jetons ou d'un échantillonnage de points d'ancrage, les deux peuvent réduire efficacement la complexité spatiale et temporelle du modèle pendant les étapes de formation et de test. Ceci est particulièrement important pour le traitement de données graphiques à grande échelle et peut améliorer considérablement l’efficacité.
Du point de vue des performances, l'échantillonnage de séquences de jetons a un impact positif sur les performances globales du modèle. Cette stratégie d'échantillonnage optimise la représentation du graphique en sélectionnant des jetons clés, améliorant ainsi la capacité du modèle à gérer des structures graphiques complexes.
En revanche, les expériences sur l'ensemble de données ddi montrent que l'échantillonnage d'ancrage peut avoir un impact négatif sur les performances du modèle. L'échantillonnage d'ancre simplifie la structure du graphique en sélectionnant des nœuds spécifiques comme points d'ancrage, mais cette méthode peut ignorer certaines informations clés sur la structure du graphique, affectant ainsi la précision du modèle.
En résumé, bien que les deux techniques d'échantillonnage aient leurs avantages, dans les applications pratiques, la stratégie d'échantillonnage appropriée doit être soigneusement sélectionnée en fonction d'ensembles de données spécifiques et des exigences de la tâche.
Conclusion de la recherche
Cette recherche vise à développer un cadre hautement adaptable capable d'identifier et d'analyser avec précision des modèles topologiques complexes de diverses structures de graphes.
Les chercheurs visent à améliorer considérablement la capacité de généralisation du modèle dans les tâches d’apprentissage de graphes zéro-shot, y compris une variété d’applications en aval, en exploitant pleinement les capacités du modèle proposé.
Le modèle est construit avec la prise en charge d'une architecture de transformateur graphique évolutive et d'un mécanisme d'augmentation des données amélioré par LLM pour améliorer l'efficacité et la robustesse d'OpenGraph.
Grâce à des tests approfondis sur plusieurs ensembles de données standards, l’équipe a démontré les excellentes performances de généralisation du modèle.
Il est entendu qu'en tant que première tentative de construction d'un modèle basé sur des graphiques, le travail de l'équipe se concentrera à l'avenir sur l'augmentation des capacités d'automatisation du framework, notamment l'identification automatique des connexions bruyantes et la réalisation d'un apprentissage contrefactuel.
Dans le même temps, l'équipe prévoit d'apprendre et d'extraire des modèles communs et transférables de diverses structures graphiques afin de promouvoir davantage la portée d'application et l'effet du modèle.
Lien de référence :
[1] Article : https://arxiv.org/pdf/2403.01121.pdf.
[2] Bibliothèque de codes sources : https://github.com/HKUDS/OpenGraph.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
Quelles bibliothèques sont utilisées pour les opérations du numéro de point flottantes en Go?
Apr 02, 2025 pm 02:06 PM
La bibliothèque utilisée pour le fonctionnement du numéro de point flottante dans le langage go présente comment s'assurer que la précision est ...
 Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
Gitee Pages STATIQUE Le déploiement du site Web a échoué: comment dépanner et résoudre les erreurs de fichier unique 404?
Apr 04, 2025 pm 11:54 PM
GiteEpages STATIQUE Le déploiement du site Web a échoué: 404 Dépannage des erreurs et résolution lors de l'utilisation de Gitee ...
 Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
Comment exécuter le projet H5
Apr 06, 2025 pm 12:21 PM
L'exécution du projet H5 nécessite les étapes suivantes: Installation des outils nécessaires tels que le serveur Web, Node.js, les outils de développement, etc. Créez un environnement de développement, créez des dossiers de projet, initialisez les projets et écrivez du code. Démarrez le serveur de développement et exécutez la commande à l'aide de la ligne de commande. Aperçu du projet dans votre navigateur et entrez l'URL du serveur de développement. Publier des projets, optimiser le code, déployer des projets et configurer la configuration du serveur Web.
 Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou fournies par des projets open source bien connus?
Apr 02, 2025 pm 04:12 PM
Quelles bibliothèques de GO sont développées par de grandes entreprises ou des projets open source bien connus? Lors de la programmation en Go, les développeurs rencontrent souvent des besoins communs, ...
 Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Comment spécifier la base de données associée au modèle de Beego ORM?
Apr 02, 2025 pm 03:54 PM
Dans le cadre du cadre de beegoorm, comment spécifier la base de données associée au modèle? De nombreux projets Beego nécessitent que plusieurs bases de données soient opérées simultanément. Lorsque vous utilisez Beego ...
 Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Comment résoudre le problème de conversion de type user_id lors de l'utilisation du flux redis pour implémenter les files d'attente de messages dans le langage Go?
Apr 02, 2025 pm 04:54 PM
Le problème de l'utilisation de Redessstream pour implémenter les files d'attente de messages dans le langage GO consiste à utiliser le langage GO et redis ...
 La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La production de pages H5 nécessite-t-elle une maintenance continue?
Apr 05, 2025 pm 11:27 PM
La page H5 doit être maintenue en continu, en raison de facteurs tels que les vulnérabilités du code, la compatibilité des navigateurs, l'optimisation des performances, les mises à jour de sécurité et les améliorations de l'expérience utilisateur. Des méthodes de maintenance efficaces comprennent l'établissement d'un système de test complet, à l'aide d'outils de contrôle de version, de surveiller régulièrement les performances de la page, de collecter les commentaires des utilisateurs et de formuler des plans de maintenance.
 Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Comment obtenir les données de la région d'expédition de la version à l'étranger? Quelles sont les ressources prêtes à l'emploi disponibles?
Apr 01, 2025 am 08:15 AM
Description de la question: Comment obtenir les données de la région d'expédition de la version à l'étranger? Y a-t-il des ressources prêtes à l'emploi disponibles? Soyez précis dans le commerce électronique transfrontalier ou les entreprises mondialisées ...
