

Photoshop 非常漂亮的3D小屋

本教程可能是翻译国外的教程。中文部分翻译的不是很好。很多过程的意思都没有翻译正确。不过原作者的教写的非常详细,我们只要参照过程图来做,还是可以做出来的。
最终效果 
1、首先,创建500px * 500ps白色背景的文件。选择钢笔工具(P)和作出如下所示的一个形状。 
2、双击图层调出图层样式,参数设置如下图。 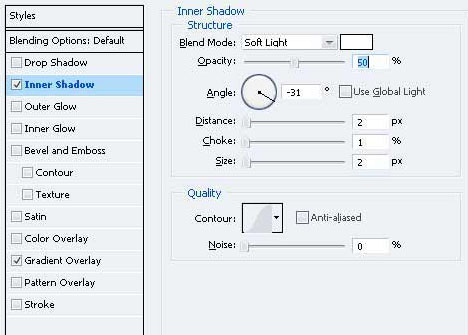

3、把做好的图形复制一层,执行:编辑“>变换”水平翻转,把两个部分对接起来。 
4、由于类似的颜色,形状给这两个单位看看屋顶。 有一个需要修正它。 打开重复的层图层样式,并应用以下更改。 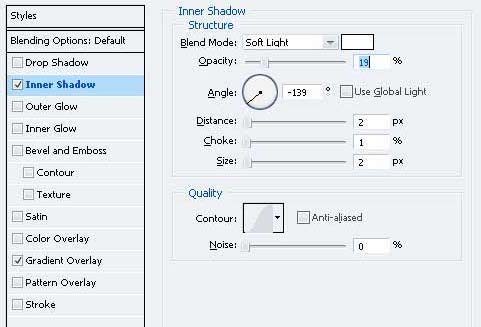
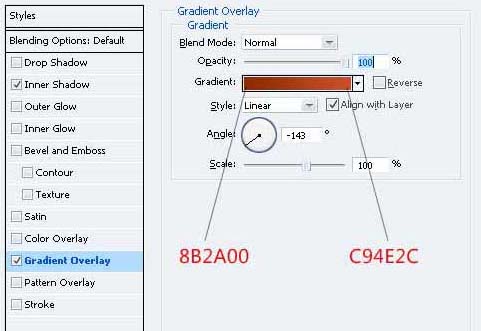
5、设置前景色“830F00” 绘制一个这样的形状如下所示的钢笔工具(规划)。 命名为“屋顶左”。 
6、把刚才做好的图形复制一层,命名为“屋顶的右”。进入“编辑>变换”水平翻转和移动向右重复的形状,让你得到下图所示的效果。 
7、在背景图层上面新建一个图层,用钢笔工具勾出下图所示的路径填充黑色,将其命名为“身体。” 
8、双击层并给予这些图层样式。 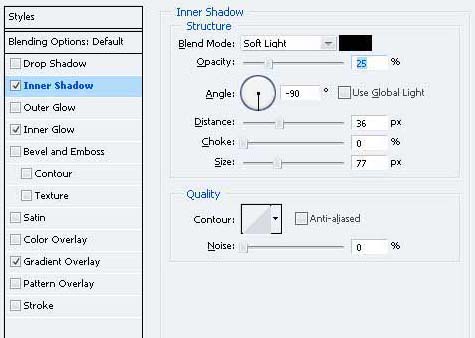
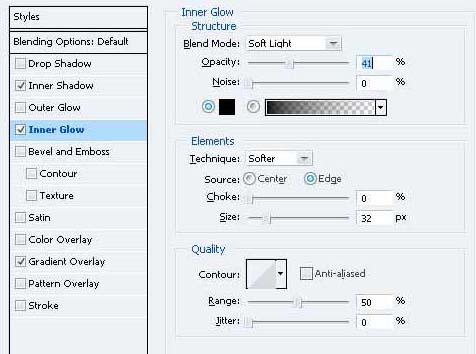
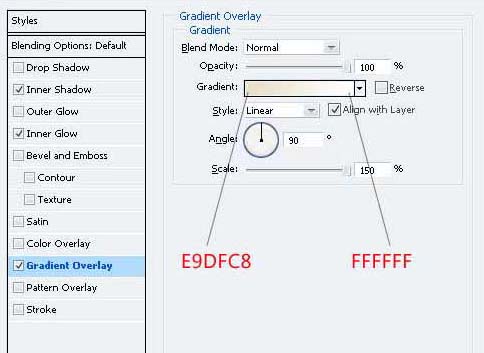
9、您需要把房子的屋顶加上影子。为此,命令的“屋顶的左侧”层上的“屋顶的右侧”层总结两个层次的选择,然后命令+按住Shift键单击。移动选择下来,在新的图层填充颜色“5F5343的选择。” 
10、转到滤镜“>模糊”高斯模糊,进入10px然后单击确定。 
#p#
11、您可能注意到,经过过滤器已被应用,阴影是在屋外的身体,这看起来不正确流向。要修正它的“身体”层,Ctrl键单击,按Command + Shift +我颠倒选择。与“影子”层选择,按Delete键。 
12、现在,您需要添加一个房子的突出部分, -这就是门。选择矩形选框工具(M)和在新的图层填充黑色选择。 
13、给门下面的图层样式。 


14、现在,我们需要添加一些细节的大门。选择圆角矩形工具(按Shift + U)和绘制的3px半径黑色矩形。 
15、去它的混合选项并应用这些设置。 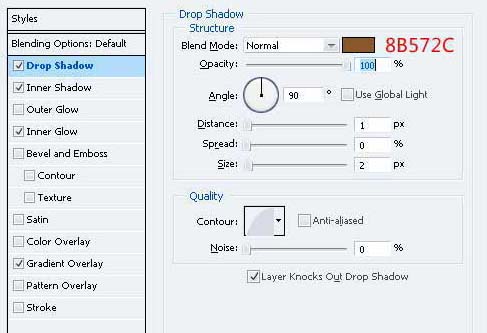
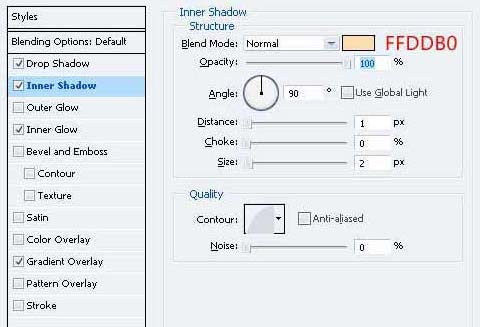
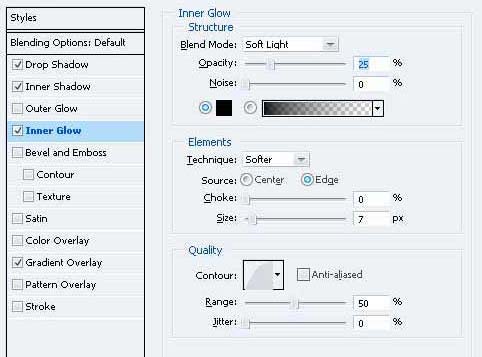
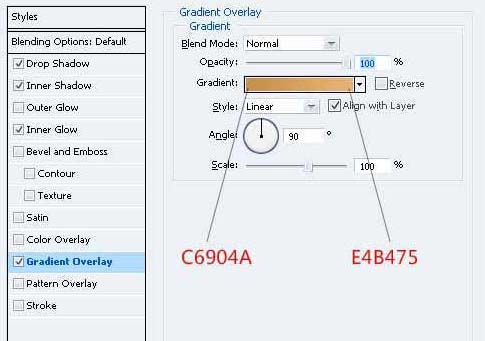
16、重复的形状和移动下来,让你有这样的事情。 
17、现在可以添加到门。椭圆工具使用(ü)就门口一个小圆圈。 
18、给圆加阴影和径向渐变。 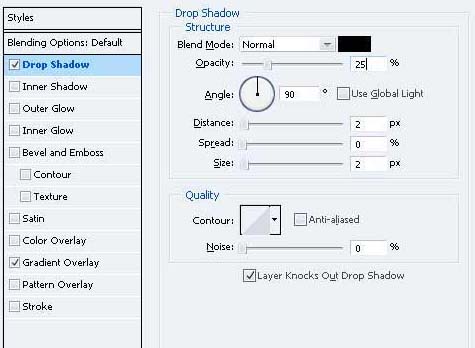

19、您可以添加一门上面的板。使用钢笔工具(规划)作出如下所示的一个形状。 
20、去它的混合选项,并给它一个作为屋顶类似的语气渐变叠加。 
#p#
21、用钢笔工具(规划),再作类似下面这一形状。 
22、给下面的形状图层样式。 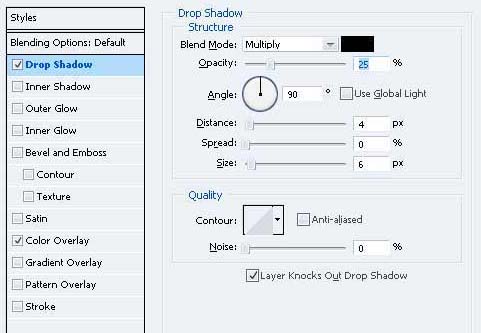
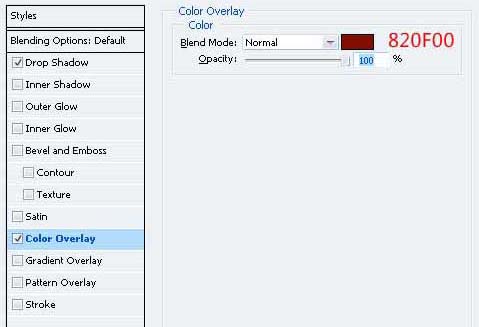
23、创建一个新层,填补它与黑色的选择。 确保这层下面的“门”在图层面板层上。 
24、给黑条对下列颜色渐变叠加。 
25、作为进一步的细节,您可以添加一个门,一步房子。 为喜欢与钢笔工具(规划)1以下的形状。 
26、加上渐变叠加。 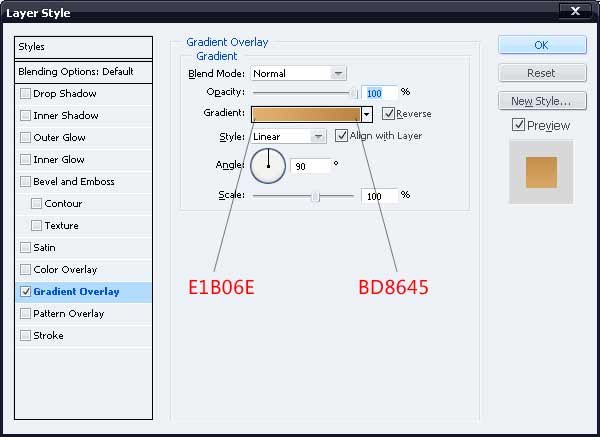
27、为了让大门有进一步的3D界面,添加一些厚度它。 设置前景色为“A26431”,并以此为如下所示的一个形状。 
28、现在是时候制作窗户的时候。通过填写开始做一个新层上有一个黑色的选择等。 
29、使用矩形选框工具(米),填充白色显示一个新的层中进行选择。 
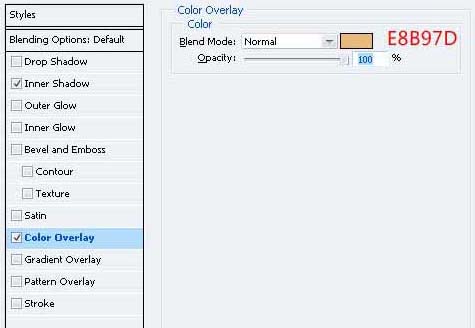
30、还要向窗户混合选项截面,并给予这些样式。 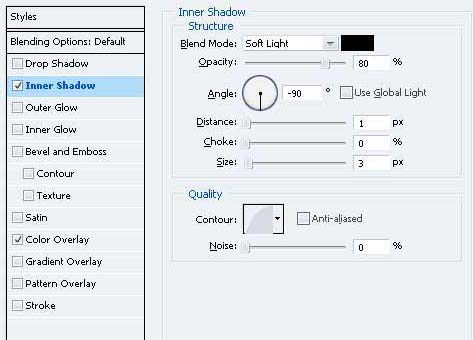
#p#
31、现在,你需要快门。 就像你所取得的大门,作出快门并在一个窗口的正面。 制作它的复制和移动到另一边,给予阴影的百叶窗,如果你想要的。 
32、只要增加细节,添加一个平板,像你的窗口没有向门口。 唯一的区别是,你需要运用图层样式的大门一步的平板您为窗口决策。 
33、创建一个图层组和它提出的所有层,构成了窗口。 复制层设置了两次并将它转换为60%,其原始大小。 放在门右侧的小窗口。 
34、现在,您可以添加一个烟囱的房子。 创建一个新层,并就此事,填充黑色选择。 
35、给予这些色彩的渐变叠加。 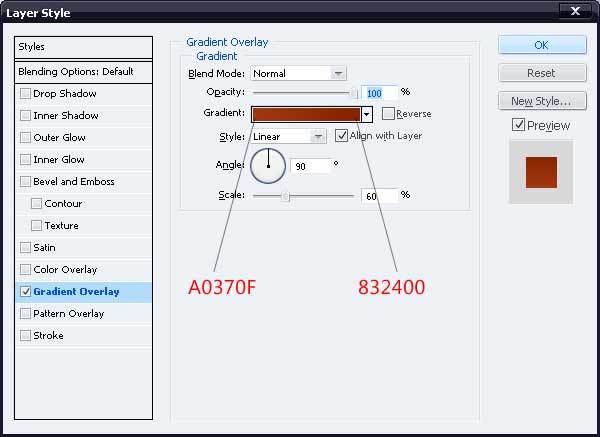
36、请有类似下面一让烟囱看三维形状。 
37、再作其它的烟囱颜色的形状。 
38、给这些图形加上渐变色。 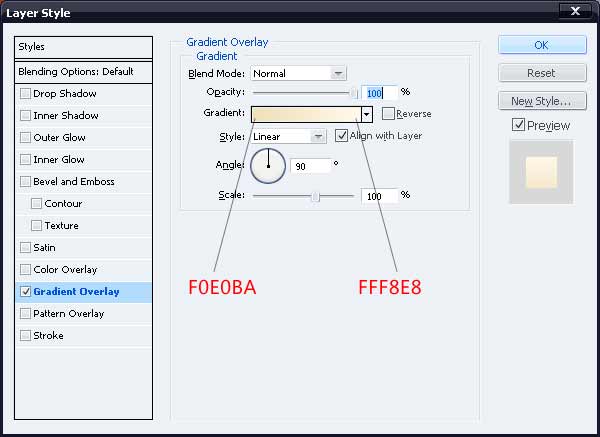
39、设置前景色“D6C08D”,并作出这样的形状。 
#p#
40、现在添加阴影,房子的图标基地。 创建一个新层,然后使用矩形选框工具(米)来填充黑色选择。 
41、执行:滤镜“>模糊”高斯模糊,然后滤镜“>模糊”,参数设置如下图。 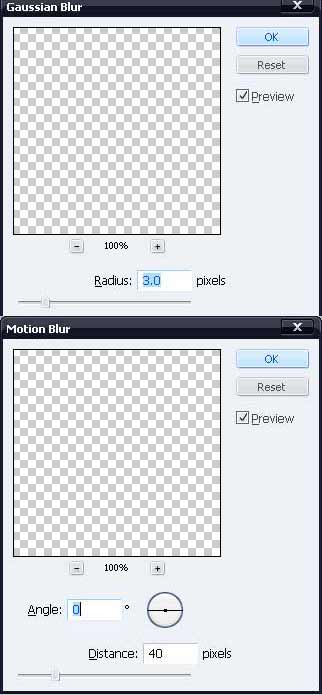
42、制作一个类似的阴影门一步。您可以设置从80-90%或20-30%的阴影不透明度。我加了一些草,完成最终效果。 
最终效果。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 En savoir plus sur les emojis 3D Fluent dans Microsoft Teams
Apr 24, 2023 pm 10:28 PM
En savoir plus sur les emojis 3D Fluent dans Microsoft Teams
Apr 24, 2023 pm 10:28 PM
N'oubliez pas, surtout si vous êtes un utilisateur de Teams, que Microsoft a ajouté un nouveau lot d'émojis 3DFluent à son application de visioconférence axée sur le travail. Après que Microsoft a annoncé des emojis 3D pour Teams et Windows l'année dernière, le processus a en fait permis de mettre à jour plus de 1 800 emojis existants pour la plate-forme. Cette grande idée et le lancement de la mise à jour des emoji 3DFluent pour les équipes ont été promus pour la première fois via un article de blog officiel. La dernière mise à jour de Teams apporte FluentEmojis à l'application. Microsoft affirme que les 1 800 emojis mis à jour seront disponibles chaque jour.
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Paint 3D sous Windows 11 : guide de téléchargement, d'installation et d'utilisation
Apr 26, 2023 am 11:28 AM
Paint 3D sous Windows 11 : guide de téléchargement, d'installation et d'utilisation
Apr 26, 2023 am 11:28 AM
Lorsque les rumeurs ont commencé à se répandre selon lesquelles le nouveau Windows 11 était en développement, chaque utilisateur de Microsoft était curieux de savoir à quoi ressemblerait le nouveau système d'exploitation et ce qu'il apporterait. Après de nombreuses spéculations, Windows 11 est là. Le système d'exploitation est livré avec une nouvelle conception et des modifications fonctionnelles. En plus de quelques ajouts, il s’accompagne de fonctionnalités obsolètes et supprimées. L'une des fonctionnalités qui n'existe pas dans Windows 11 est Paint3D. Bien qu'il propose toujours Paint classique, idéal pour les dessinateurs, les griffonneurs et les griffonneurs, il abandonne Paint3D, qui offre des fonctionnalités supplémentaires idéales pour les créateurs 3D. Si vous recherchez des fonctionnalités supplémentaires, nous recommandons Autodesk Maya comme le meilleur logiciel de conception 3D. comme
 Obtenez une femme virtuelle en 3D en 30 secondes avec une seule carte ! Text to 3D génère un humain numérique de haute précision avec des détails de pores clairs, se connectant de manière transparente à Maya, Unity et d'autres outils de production.
May 23, 2023 pm 02:34 PM
Obtenez une femme virtuelle en 3D en 30 secondes avec une seule carte ! Text to 3D génère un humain numérique de haute précision avec des détails de pores clairs, se connectant de manière transparente à Maya, Unity et d'autres outils de production.
May 23, 2023 pm 02:34 PM
ChatGPT a injecté une dose de sang de poulet dans l’industrie de l’IA, et tout ce qui était autrefois impensable est devenu aujourd’hui une pratique de base. Le Text-to-3D, qui continue de progresser, est considéré comme le prochain point chaud dans le domaine de l'AIGC après la diffusion (images) et le GPT (texte), et a reçu une attention sans précédent. Non, un produit appelé ChatAvatar a été mis en version bêta publique discrète, recueillant rapidement plus de 700 000 vues et attention, et a été présenté sur Spacesoftheweek. △ChatAvatar prendra également en charge la technologie Imageto3D qui génère des personnages stylisés en 3D à partir de peintures originales à perspective unique/multi-perspective générées par l'IA. Le modèle 3D généré par la version bêta actuelle a reçu une large attention.
 Une interprétation approfondie de l'algorithme de perception visuelle 3D pour la conduite autonome
Jun 02, 2023 pm 03:42 PM
Une interprétation approfondie de l'algorithme de perception visuelle 3D pour la conduite autonome
Jun 02, 2023 pm 03:42 PM
Pour les applications de conduite autonome, il est finalement nécessaire de percevoir des scènes 3D. La raison est simple : un véhicule ne peut pas conduire sur la base des résultats de perception obtenus à partir d’une image. Même un conducteur humain ne peut pas conduire sur la base d’une image. Étant donné que la distance de l'objet et les informations sur la profondeur de la scène ne peuvent pas être reflétées dans les résultats de perception 2D, ces informations sont la clé permettant au système de conduite autonome de porter des jugements corrects sur l'environnement. De manière générale, les capteurs visuels (comme les caméras) des véhicules autonomes sont installés au-dessus de la carrosserie du véhicule ou sur le rétroviseur intérieur. Peu importe où elle se trouve, la caméra obtient la projection du monde réel dans la vue en perspective (PerspectiveView) (du système de coordonnées mondiales au système de coordonnées de l'image). Cette vue est très similaire au système visuel humain,
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
