

在Windows环境下配置MySQL集群_MySQL

前言
最近在项目中用到了MySQL集群,所以就和小伙伴们研究了两天。下面给大家分享一下成果。
小编始终觉得对新事物的学习,没有比看图这种方式更好地理解了。所以先来看一张mysql集群的架构图(摘自百度百科-MySQL Cluster):

上图一共分了四层:Applications、SQL、Storage、Management。
如果您的英语不是体育老师教的的话,那么您肯定已经猜出来每一层的职责了:
—–Applications主要是指需要连接数据库的应用程序;
—–SQL中每一个mysqld都是一个sql节点,Applications需要通过连接sql节点来存储数据,您可以把它看成应用程序与数据库集群进行数据交换的大门
—–Storage有‘仓库’的意思,所以数据都是存在数据节点(ndbd)中的,而且每个数据节点的数据都是一致的,都是一整套最新的数据
—–Management中就是管理节点,一个MySQL中只有一个管理节点,用来管理其他节点
综上所述,一个MySQL集群中包括三种节点(不包括Applications):管理节点、数据节点,sql节点。
一、下载集群版mysql
下载mysql-cluster-gpl-7.4.7-win32或mysql-cluster-gpl-7.4.7-winx64
下载地址:http://yunpan.cn/cd892RtysQ3Vk (提取码:45c8)
MySQL官网下载地址:http://dev.mysql.com/downloads/cluster/
二、配置MySQL集群
需要用三台机器(没有条件的朋友可以考虑用虚拟机),一台配置管理节点:另外两台每台配置一个数据节点和一个SQL节点(也可以用五台计算机,每台计算机配置一个节点):
管理节点:192.168.25.50
数据节点A:192.168.25.49
数据节点B:192.168.25.48
SQL节点A:192.168.25.49
SQL节点B:192.168.25.48
1、首先将下载压缩包解压到每台电脑的C:/mysql目录下:

当然放在其他盘的目录里也可以。
2、配置管理节点
在配置管理节点(192.168.25.50)的计算机上的C:\Mysql\Bin目录下建立cluster-logs和config两个文件夹。cluster-logs用来存储日志文件,在config文件夹中建立my.ini和config.ini两个配置文件:
my.ini
<code class="hljs ruby">[mysql_cluster] # Options for management node process config-file=C:/mysql/bin/config/config.ini</code>
config.ini
<code class="hljs ruby"><code class="hljs ruby">[ndbd default]
# Options affecting ndbd processes on all data nodes:
NoOfReplicas=2 # Number of replicas
DataDir=C:/mysql/bin/cluster-data # Directory for each data node's data files
# Forward slashes used in directory path,
# rather than backslashes. This is correct;
# see Important note in text
DataMemory=80M # Memory allocated to data storage
IndexMemory=18M # Memory allocated to index storage
# For DataMemory and IndexMemory, we have used the
# default values. Since the "world" database takes up
# only about 500KB, this should be more than enough for
# this example Cluster setup.
[ndb_mgmd]
# Management process options:
HostName=192.168.25.50 # Hostname or IP address of management node
DataDir=C:/mysql/bin/cluster-logs # Directory for management node log files
[ndbd]
# Options for data node "A":
HostName=192.168.25.49 # Hostname or IP address
[ndbd]
# Options for data node "B":
HostName=192.168.25.48 # Hostname or IP address
[mysqld]
# SQL node A options:
HostName=192.168.25.49 # Hostname or IP address
[mysqld]
# SQL node B options:
HostName=192.168.25.48 # Hostname or IP address</code></code><code class="hljs ruby">3、配置数据节点
<code class="hljs ruby">在配置数据节点(192.168.25.48、192.168.25.49)的计算机上的C:\Mysql\Bin目录下建立cluster-data文件夹,用来存放数据:
<code class="hljs ruby">SQL节点不用任何配置,至此,整个MySQL集群就搭建完成了。
<code class="hljs ruby">三、启动MySQL集群
<code class="hljs ruby">启动MySQL集群时,有一个启动顺序:先启动管理节点,再启动数据节点,再启动sql节点。
<code class="hljs ruby">1、启动管理节点:
<code class="hljs ruby">在cmd中运行如下命令
<code class="hljs ruby"><code class="hljs ruby"><code class="hljs tex">c:\mysql\bin\ndb_mgmd.exe --configdir=c:\mysql\bin\config --config-file=c:\mysql\bin\config\config.ini --ndb-nodeid=1 --reload –initial</code></code></code>
<code class="hljs ruby"><code class="hljs tex"><img src="/static/imghw/default1.png" data-src="http://img.bitscn.com/upimg/allimg/c150828/1440K00Q50-3M20.jpg" class="lazy" alt="这里写图片描述" title="\" />
<code class="hljs ruby"><code class="hljs tex">2、启动每个数据节点:
<code class="hljs ruby"><code class="hljs tex">在cmd中运行如下命令:
<code class="hljs ruby"><code class="hljs ruby"><code class="hljs tex"><code class="hljs tex">c:\mysql\bin\ndbd.exe --ndb-connectstring=192.168.25.50</code></code></code></code>
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><img src="/static/imghw/default1.png" data-src="http://img.bitscn.com/upimg/allimg/c150828/1440K00QF310-4B34.jpg" class="lazy" alt="这里写图片描述" title="\" />
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex">3、启动每个sql节点:
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex">在cmd中运行如下命令:
<code class="hljs ruby"><code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck">c:\mysql\bin\mysqld.exe --ndbcluster --ndb-connectstring=192.168.25.50 --console</code></code></code></code></code>
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><img src="/static/imghw/default1.png" data-src="http://img.bitscn.com/upimg/allimg/c150828/1440K00Q921Z-55413.jpg" class="lazy" alt="这里写图片描述" title="\" />
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck">现在整个MySQL集群就已经启动了。
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck">4、查看每个节点的状态:
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck">在管理节点所在计算机上(192.168.25.50)打开ndb_mgm.exe,或者直接在cmd中运行
<code class="hljs ruby"><code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex">c:\mysql\bin\ndb_mgm</code></code></code></code></code></code>
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex">执行“show”命令,可以查看到每个节点的连接状态:
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><img src="/static/imghw/default1.png" data-src="http://img.bitscn.com/upimg/allimg/c150828/1440K00R15620-A262.jpg" class="lazy" alt="这里写图片描述" title="\" />
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex">这就表明每个节点均连接正常。下面测试数据。
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex">三、测试MySQL集群
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex">1、在sql节点A建立数据库并插入数据:
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex">在sql节点A的计算机上(192.168.25.49)的cmd中运行C:\mysql\bin\mysql.exe -u root -p命令登录mysql,接下来需要输入密码时,密码默认为空(直接回车)。
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex">创建数据库并插入数据:<br />
—–创建名为”MySQL_Cluster_Test”的数据库:
<code class="hljs ruby"><code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"> create database MySQL_Cluster_Test;</code></code></code></code></code></code></code>
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql">—–创建表”T_User”:
<code class="hljs ruby"><code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql">use MySQL_Cluster_Test; create table T_User(Name varchar(32),Age int) engine=ndbcluster;</code></code></code></code></code></code></code></code>
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql">注意建表语句后面一定要加上 engine=ndbcluster
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql">—–插入数据:
<code class="hljs ruby"><code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql">insert into T_User values('DannyHoo',26);</code></code></code></code></code></code></code></code></code>
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql">—–查询数据:
<code class="hljs ruby"><code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql">select * from T_User;</code></code></code></code></code></code></code></code></code></code>
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql"><img src="/static/imghw/default1.png" data-src="http://img.bitscn.com/upimg/allimg/c150828/1440K00R32Q0-L038.jpg" class="lazy" alt="这里写图片描述" title="\">
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql">2、在sql节点B也可以查询到数据。
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql">同样在sql节点B的计算机上(192.168.25.48)的cmd中运行C:\mysql\bin\mysql.exe -u root -p命令登录mysql。
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql">执行 show databases; 命令可以查看到在sql节点A新建的数据库;<br>
执行use MySQL_Cluster_Test;<br>
select * from T_User;<br>
可以查询到在sql节点A插入的数据。
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql"><img src="/static/imghw/default1.png" data-src="http://img.bitscn.com/upimg/allimg/c150828/1440K00R56250-Y330.jpg" class="lazy" alt="这里写图片描述" title="\">
<code class="hljs ruby"><code class="hljs tex"><code class="hljs tex"><code class="hljs brainfuck"><code class="hljs tex"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql"><code class="hljs sql">到这里,整个集群的搭建和测试就完成了。假如一个数据节点宕机,并不会影响整个集群的运行,任何一个数据节点死掉甚至物理损坏都不用担心,因为每个数据节点保存的数据都是完整的一份数据(在你操作数据的时候,它早就自动为你把最新的数据备份到每一个数据节点上啦)。你可以测试一下,这时手动停止某个数据节点和sql节点,另外一个数据节点和sql节点还会正常运行。当你把停止的数据节点和sql节点重新启动时,会发现又重新连接到集群里了,而且每个数据节点的数据都是最新的。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Impossible de démarrer dans l'environnement de récupération Windows
Feb 19, 2024 pm 11:12 PM
Impossible de démarrer dans l'environnement de récupération Windows
Feb 19, 2024 pm 11:12 PM
L'environnement de récupération Windows (WinRE) est un environnement utilisé pour réparer les erreurs du système d'exploitation Windows. Après avoir entré WinRE, vous pouvez effectuer une restauration du système, une réinitialisation d'usine, désinstaller les mises à jour, etc. Si vous ne parvenez pas à démarrer WinRE, cet article vous guidera à travers les correctifs pour résoudre le problème. Impossible de démarrer dans l'environnement de récupération Windows Si vous ne pouvez pas démarrer dans l'environnement de récupération Windows, utilisez les correctifs fournis ci-dessous : Vérifiez l'état de l'environnement de récupération Windows Utilisez d'autres méthodes pour accéder à l'environnement de récupération Windows Avez-vous accidentellement supprimé la partition de récupération Windows ? Effectuez une mise à niveau sur place ou une nouvelle installation de Windows ci-dessous, nous avons expliqué tous ces correctifs en détail. 1] Vérifiez le Wi-Fi
 Quelles sont les différences entre Python et Anaconda ?
Sep 06, 2023 pm 08:37 PM
Quelles sont les différences entre Python et Anaconda ?
Sep 06, 2023 pm 08:37 PM
Dans cet article, nous découvrirons les différences entre Python et Anaconda. Qu’est-ce que Python ? Python est un langage open source qui met l'accent sur la facilité de lecture et de compréhension du code en indentant les lignes et en fournissant des espaces. La flexibilité et la facilité d'utilisation de Python le rendent idéal pour une variété d'applications, notamment le calcul scientifique, l'intelligence artificielle et la science des données, ainsi que pour la création et le développement d'applications en ligne. Lorsque Python est testé, il est immédiatement traduit en langage machine car il s’agit d’un langage interprété. Certains langages, comme le C++, nécessitent une compilation pour être compris. La maîtrise de Python est un avantage important car il est très facile à comprendre, développer, exécuter et lire. Cela rend Python
 Le nœud évacue complètement Proxmox VE et rejoint à nouveau le cluster
Feb 21, 2024 pm 12:40 PM
Le nœud évacue complètement Proxmox VE et rejoint à nouveau le cluster
Feb 21, 2024 pm 12:40 PM
Description du scénario pour que les nœuds évacuent complètement de ProxmoxVE et rejoignent le cluster Lorsqu'un nœud du cluster ProxmoxVE est endommagé et ne peut pas être réparé rapidement, le nœud défectueux doit être expulsé proprement du cluster et les informations résiduelles doivent être nettoyées. Sinon, les nouveaux nœuds utilisant l'adresse IP utilisée par le nœud défectueux ne pourront pas rejoindre le cluster normalement ; de même, une fois le nœud défectueux qui s'est séparé du cluster réparé, bien que cela n'ait rien à voir avec le cluster, il le fera. ne pas pouvoir accéder à la gestion Web de ce nœud unique. En arrière-plan, des informations sur les autres nœuds du cluster ProxmoxVE d'origine apparaîtront, ce qui est très ennuyeux. Expulsez les nœuds du cluster. Si ProxmoxVE est un cluster hyper-convergé Ceph, vous devez vous connecter à n'importe quel nœud du cluster (à l'exception du nœud que vous souhaitez supprimer) sur le système hôte Debian et exécuter la commande.
 Comment utiliser Docker pour gérer et développer des clusters multi-nœuds
Nov 07, 2023 am 10:06 AM
Comment utiliser Docker pour gérer et développer des clusters multi-nœuds
Nov 07, 2023 am 10:06 AM
À l’ère actuelle du cloud computing, la technologie de conteneurisation est devenue l’une des technologies les plus populaires dans le monde open source. L'émergence de Docker a rendu le cloud computing plus pratique et efficace et est devenu un outil indispensable pour les développeurs et le personnel d'exploitation et de maintenance. L'application de la technologie de cluster multi-nœuds est largement utilisée sur la base de Docker. Grâce au déploiement de clusters multi-nœuds, nous pouvons utiliser les ressources plus efficacement, améliorer la fiabilité et l'évolutivité, et également être plus flexibles dans le déploiement et la gestion. Ensuite, nous présenterons comment utiliser Docker pour
 Méthode d'optimisation de base de données dans un environnement PHP à haute concurrence
Aug 11, 2023 pm 03:55 PM
Méthode d'optimisation de base de données dans un environnement PHP à haute concurrence
Aug 11, 2023 pm 03:55 PM
Méthode d'optimisation de base de données PHP dans un environnement à haute concurrence Avec le développement rapide d'Internet, de plus en plus de sites Web et d'applications doivent faire face à des défis de haute concurrence. Dans ce cas, l'optimisation des performances de la base de données devient particulièrement importante, en particulier pour les systèmes qui utilisent PHP comme langage de développement back-end. Cet article présentera quelques méthodes d'optimisation de base de données dans un environnement PHP à haute concurrence et donnera des exemples de code correspondants. Utilisation du regroupement de connexions Dans un environnement à forte concurrence, la création et la destruction fréquentes de connexions à des bases de données peuvent entraîner des goulots d'étranglement en termes de performances. Par conséquent, l’utilisation du pool de connexions peut
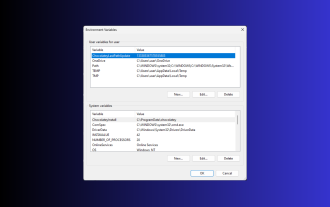 11 façons de définir des variables d'environnement sur Windows 3
Sep 15, 2023 pm 12:21 PM
11 façons de définir des variables d'environnement sur Windows 3
Sep 15, 2023 pm 12:21 PM
La définition de variables d'environnement sur Windows 11 peut vous aider à personnaliser votre système, à exécuter des scripts et à configurer des applications. Dans ce guide, nous aborderons trois méthodes ainsi que des instructions étape par étape afin que vous puissiez configurer votre système à votre guise. Il existe trois types de variables d'environnement Variables d'environnement système : les variables globales ont la priorité la plus basse et sont accessibles à tous les utilisateurs et applications sous Windows et sont généralement utilisées pour définir les paramètres à l'échelle du système. Variables d'environnement utilisateur – Priorité plus élevée, ces variables s'appliquent uniquement à l'utilisateur actuel et au processus exécuté sous ce compte, et sont définies par l'utilisateur ou l'application exécuté sous ce compte. Variables d'environnement de processus - ont la priorité la plus élevée, elles sont temporaires et s'appliquent au processus en cours et à ses sous-processus, fournissant ainsi au programme
 Quels sont les packages d'environnement intégré PHP ?
Jul 24, 2023 am 09:36 AM
Quels sont les packages d'environnement intégré PHP ?
Jul 24, 2023 am 09:36 AM
Les packages d'environnement intégré PHP incluent : 1. PhpStorm, un puissant environnement intégré PHP ; 2. Eclipse, un environnement de développement intégré open source ; 3. Visual Studio Code, un éditeur de code open source léger 4. Sublime Text, un éditeur de texte populaire ; , largement utilisé dans divers langages de programmation ; 5. NetBeans, un environnement de développement intégré développé par Apache Software Foundation ; 6. Zend Studio, un environnement de développement intégré conçu pour les développeurs PHP.
 Quels sont les clusters courants en php ?
Aug 31, 2023 pm 05:45 PM
Quels sont les clusters courants en php ?
Aug 31, 2023 pm 05:45 PM
Les clusters courants en PHP incluent le cluster LAMP, le cluster Nginx, le cluster Memcached, le cluster Redis et le cluster Hadoop. Introduction détaillée : 1. Le cluster LAMP fait référence à une combinaison de Linux, Apache, MySQL et PHP. Il s'agit d'un environnement de développement PHP commun, plusieurs serveurs exécutent la même application et sont équilibrés via un équilibreur de charge. sont distribués sur différents serveurs ; 2. Cluster Nginx, Nginx est un serveur Web hautes performances, etc.
