

PHP cURL 应用

对于做过数据采集的人来说,cURL一定不会陌生。虽然在PHP中有file_get_contents函数可以获取远程链接的数据,但是它的可控制性太差了,对于各种复杂情况的采集情景,file_get_contents显得有点无能为力。因此,本文将为你介绍采集神器cURL的使用。
工具
火狐浏览器(FireFox) + Firebug
“工欲善其事,必先利其器。” 在分析案例之前,先让我们学习一下如何利用神器Firebug获取我们必要的信息。
使用F12打开Firebug,我们可以得到如图(一)界面:

箭头图标是“元素选择”工具,单击一次会高亮图标,同时,鼠标在页面内的移动会同时在HTML菜单中选定相应的内容,此时单击内容则表示选定了该元素,图标高亮取消。如图(二)所示:

- 控制台
JS里面的console.log系列函数的打印就是在这里输出。 - HTML
HTML内容,注意这里看到的不一定是采集要解析的内容,采集时候对内容的分析,一律以查看源码(Ctrl+U)为准,这里只是能快速定位元素的结构,然后再选择一个比较特殊的参照,在源码中定位相应的位置。
比如,你在HTML里面看到一个标签是<div id="demo" class="demo">Demo</div>,但是你查看源码时候看到的内容可能是<div class="demo" id="demo">Demo</div>,如果你对采集内容按照前者去做正则匹配,那么你会得不到结果。 - CSS
这里是CSS文件内容 - 脚本
这里是Javascript文件内容 - DOM
Dom节点内容 - 网络
每一个请求链接的数据,这里是我们采集要关注和分析的地方,它能够显示每一个请求的参数、请求头、Cookie数据等。在页面提交会刷新的情况下,需要使用保持,使得页面请求内容在刷新后仍然留着控制台中,如图(三)所示:
另外,火狐还有一款 Tamper data 扩展也能得到请求数据,必要时可以安装使用。 Cookies
Cookie数据


在图(一)中还看到下面有很多可选的小菜单项,其中保持是我们要关注的,当选择它的时候,即使提交表单刷新了页面,下面内容区域的数据还是会保留,这个对于分析提交数据特别关键。
总结
我们在分析采集请求的时候,主要关心“网络”菜单里的请求数据,必要时候使用“保持”以查看刷新页面的请求数据,请求前可以使用“清除”先清除下面的内容。
案例解析
一、简单的采集
这里所指的简单采集,是指一个单一页面GET请求的采集,它简单得即使通过file_get_contents函数也能轻松获得页面返回结果。
- 代码片段之file_get_contents
<code><?php $url = 'http://demo.zjmainstay.cn/php/curl/simple.html';
$content = file_get_contents($url);
echo $content;
</code></code>- 代码片段之cURL
<code><?php $url = 'http://demo.zjmainstay.cn/php/curl/simple.html';
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
echo $content;
</code></code>二、需要参数的采集
这种情况,页面请求需要传入一些参数,可以是GET请求,也可以是POST请求。这种情况的采集,使用file_get_contents外带一些参数还是可以实现的,但是这里我们将不再展示。
- 代码片段之cURL GET
这种请求,我们可以选择搜索引擎作为演示,比如我百度搜索一个词语“PHP cURL”,在输入回车后,我们会得到一个类似http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&ch=&tn=baidu&bar=&wd=PHP%20cURL的链接,注意这里的链接可能不同浏览器、不同入口方式访问得到不一样结果,因此不必介意链接是否一样。通过输入多个关键词并观察链接,我们可以确定 wd 参数就是我们要传入的动态参数,而其他参数则可以不变,因此得到我们下面的采集代码。
<code><?php $keyword = 'PHP cURL';
$url = 'http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&ch=&tn=baidu&bar=&wd=' . urlencode($keyword);
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
echo $content;
</code></code>有些时候,一些参数并不是必须的,这时候我们可以删掉它,比如上面的链接可以只保留http://www.baidu.com/s?ie=utf-8&wd=PHP%20cURL,ie=utf-8 这个参数可能影响结果的编码,所以暂且留着它。就这样简单的代码,我们就可以采集到百度搜索的结果了。
- 代码片段之cURL POST
对于POST类型的请求,我们平时并不少见,比如有些搜索就是使用POST方式提交,这时候我们就需要使用POST类型来提交参数了。这个在PHP cURL里面有相应的参数:CURLOPT_POST 和 CURLOPT_POSTFIELDS , CURLOPT_POST 的设置可以指定当前提交是否为POST方式,CURLOPT_POSTFIELDS则用于设定提交的参数,可以是参数串,也可以是参数数组,比如:
<code>curl_setopt($ch, CURLOPT_POSTFIELDS, 'ie=utf-8&wd=PHP%20cURL');
或
curl_setopt($ch, CURLOPT_POSTFIELDS, array(
'ie' => 'utf-8',
'wd' => 'PHP%20cURL',
));
</code>下面是我做的一个POST模拟搜索PHP POST 搜索,后端是使用了前面的百度关键词搜索,基本原理就是,客户端提交一个关键词到我服务器,我服务器使用该关键词请求百度的搜索,然后得到结果,返回到客户端。
如图(四)是利用Firebug对请求数据的分析,得到我们需要提交的请求链接和请求参数:

然后下面是我们的代码:
<code><?php $keyword = 'PHP cURL';
//参数方法一
// $post = 'wd=' . urlencode($keyword);
//参数方法二
$post = array(
'wd' => urlencode($keyword),
);
$url = 'http://demo.zjmainstay.cn/php/curl/search.php';
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
curl_setopt($ch, CURLOPT_POST, 1); //发送POST类型数据
curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //POST数据,$post可以是数组,也可以是拼接
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
var_dump($content);
</code>三、需要Referer的采集
对于一些程序,它可能判断来源网址,如果发现referer不是自己的网站,则拒绝访问,这时候,我们就需要添加CURLOPT_REFERER参数,模拟来路,使得程序能够正常采集。
<code><?php $keyword = 'PHP cURL';
//参数方法一
// $post = 'wd=' . urlencode($keyword);
//参数方法二
$post = array(
'wd' => urlencode($keyword),
);
$url = 'http://demo.zjmainstay.cn/php/curl/search_refer.php';
$refer = 'http://demo.zjmainstay.cn/'; //来路地址
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
curl_setopt($ch, CURLOPT_REFERER, $refer); //来路模拟
curl_setopt($ch, CURLOPT_POST, 1); //发送POST类型数据
curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //POST数据,$post可以是数组,也可以是拼接
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
var_dump($content);
</code>search_refer.php的源码如下,做了简单的Referer判断拦截:
<code><?php if(empty($_POST['wd'])) {
exit('Deny empty params.');
}
//Referer判断
if(stripos($_SERVER['HTTP_REFERER'], $_SERVER['HTTP_HOST']) === false) {
exit('Deny');
}
$keyword = addslashes(trim(strip_tags($_POST['wd'])));
$url = 'http://www.baidu.com/s?ie=utf-8&wd=' . urlencode($keyword);
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
echo $content;
</code></code>四、需要cookie支持的采集
对于模拟登录的应用,单单提交参数和模拟来路并不能解决问题,这时候我们就需要保存或者提交相应的Cookie参数,这个在PHP cURL里面也提供了相应的参数:
CURLOPT_COOKIE: 直接使用字符串方式提交cookie参数
CURLOPT_COOKIEFILE: 使用文件方式提交cookie参数
CURLOPT_COOKIEJAR: 保存提交后反馈的cookie数据
下面是PHP100的模拟登录示例:
<code><?php header("content-Type: text/html; charset=UTF-8");
$cookie_file = tempnam('./temp', 'cookie');
$login_url="http://bbs.php100.com/login.php";
$post_fields="cktime=36000&step=2&pwuser=username&pwpwd=password";
//提交登录表单请求
$ch=curl_init($login_url);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_POST,1);
curl_setopt($ch,CURLOPT_POSTFIELDS,$post_fields);
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file); //存储提交后得到的cookie数据
curl_exec($ch);
curl_close($ch);
//登录成功后,获取bbs首页数据
$url="http://bbs.php100.com/index.php";
$ch=curl_init($url);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_COOKIEFILE,$cookie_file); //使用提交后得到的cookie数据做参数
$contents=curl_exec($ch);
curl_close($ch);
//转码显示
echo iconv('gbk', 'UTF-8', $contents);
</code></code>五、压缩网页采集(gzip)
有些没有接触过压缩页面的朋友估计会在这里被坑死,因为他们会发现采集回来的内容是乱码,并且无论使用iconv还是强大的mb_convert_encoding都无法还原数据,然后又没有概念,各种抓狂却找不到方法,哈哈,我曾经也是这样~
如图(五)是乱码表现形式:

还好最后功夫不负有心人,还是找到了,它就是CURLOPT_ENCODING参数。
比如,采集搜狐的新闻时候就遇到gzip压缩问题,下面是示例:
<code><?php $url = 'http://news.sohu.com/';
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
curl_setopt($ch, CURLOPT_ENCODING, "gzip"); //指定gzip压缩
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
echo $content;
</code></code>手册说明:支持的编码有"identity","deflate"和"gzip"。如果为空字符串"",请求头会发送所有支持的编码类型。
后面一句表明,使用curl_setopt($ch, CURLOPT_ENCODING, "");也是可以的,但是不能不加这个参数。
六、SSL链接的采集
有些请求链接是https类型的,这时候使用cURL采集可能会失败,这时候,我们可以使用 var_dump(curl_error($ch));的方法打印错误提示,然后根据错误提示查找相应的解决方案。比如SSL错误常见提示:SSL certificate problem: unable to get local issuer certificate,这时候,我们就需要利用参数:CURLOPT_SSL_VERIFYPEER 和 CURLOPT_SSL_VERIFYHOST 来禁用SSL证书的验证,我尝试过只使用CURLOPT_SSL_VERIFYPEER参数禁用失败,所以大家最好同时使用两个参数。
下面是代码示例:
<code><?php $searchStr = 'RC376981638HK';
$post = 'accion=LocalizaUno&numero='.$searchStr.'&ecorreo=&numeros=';
$url = 'https://aplicacionesweb.correos.es/localizadorenvios/track.asp';
$ch = curl_init($url); //初始化curl
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
curl_setopt($ch, CURLOPT_POST, 1); //发送POST类型数据
curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //POST数据,$post可以是数组,也可以是拼接参数串
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); //SSL 报错时使用
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); //SSL 报错时使用
$contents = curl_exec($ch); //执行并存储结果
// var_dump(curl_error($ch)); //获取失败是使用(采集错误提示)
curl_close($ch);
echo $contents;
</code></code>七、代理采集
大家都知道,国内存在万恶的墙,所以,假如我们需要获取某些被墙数据时,就需要用到国外代理服务器;又或者我们需要采集大量数据时,需要不断切换IP,也会用到代理。
使用代理在PHP cURL里面有几个相对应的参数:CURLOPT_PROXY、CURLOPT_PROXYPORT 和 CURLOPT_PROXYUSERPWD,还有另外几个,这里不列举。
CURLOPT_PROXY 指定代理IP参数
CURLOPT_PROXYPORT 指定代理端口参数
CURLOPT_PROXYUSERPWD 指定需要验证的代理的账号密码,"[username]:[password]"格式的字符串
关于代理账号获取,大家自己发挥,我这里提供网上搜索到的一个列表:cURL 高匿代理
下面是代理采集示例:
<code><?php $url = 'http://demo.zjmainstay.cn/php/curl/dump_ip.php?t=' . time();
echo "本地IP:" . file_get_contents($url) . "\n伪造IP:";
$ip = '183.224.1.116';
$port = '80';
//伪造请求头参数,如果是高匿代理这里不需要提供
$header = array(
'X-FORWARDED-FOR: ' . $ip,
'CLIENT-IP: ' . $ip,
);
$ch = curl_init($url); //初始化curl
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
curl_setopt($ch, CURLOPT_PROXY, $ip);
curl_setopt($ch, CURLOPT_PROXYPORT, $port);
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
echo $content;
</code></code>八、 多线程采集
对于大量采集工作,为了提高采集效率,使用PHP cURL提供的多线程采集是必不可少的。手册上提供的多线程采集例子好像都不太好用,我刚开始也从里面测试了几个例子,但是发现都是执行卡死,根本无法执行完成,前几天突然又测试了一下,然后发现curl_multi_info_read函数下面的Example #1是可以执行的,它的内容在$res上,但是没有打印出来,而且雅虎的请求比较慢,会卡住,前面两个链接都能正常返回。
不过,还好当时的例子不好用,然后我经过搜索找到了一个很厉害的项目,CurlMulti ,它对PHP cURL Multi 进行了一个良性扩展的封装,能够很好地提供采集支持。
关于CurlMulti的使用我就不多介绍,官网上面提供了demo,使用过程有技术难题可以直接加入Q群讨论,作者@Ares 和其他的采集大牛都会提供技术解答帮助。
下面是PHP cURL Multi的一个简单示例:
<code><?php $urls = array(
"http://demo.zjmainstay.cn/php/curl/curl_multi_1.php",
"http://demo.zjmainstay.cn/php/curl/curl_multi_2.php",
);
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_RETURNTRANSFER, 1); //不直接输出结果
curl_multi_add_handle($mh, $conn[$i]);
}
$active = null;
$res = array();
do {
$status = curl_multi_exec($mh, $active);
$info = curl_multi_info_read($mh);
if (false !== $info) {
//采集信息处理
$res[] = array(
'content' => curl_multi_getcontent($info['handle']),
'info' => $info,
);
curl_close($info['handle']);
}
} while ($status === CURLM_CALL_MULTI_PERFORM || $active);
curl_multi_close($mh);
var_dump($res);
</code>九、302跳转(301跳转)
对于一些应用,比如模拟登录,如果遇上302跳转,会导致cookie丢失而使得模拟登录失败,请求现象如图(六)所示:

这个时候,可以使用:
<code>curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true); </code>
关于CURLOPT_FOLLOWLOCATION,手册说明是:
<code>启用时会将服务器服务器返回的"Location: "放在header中递归的返回给服务器,使用CURLOPT_MAXREDIRS可以限定递归返回的数量。</code>
我个人理解,通俗点讲就是后面的跳转会继续跟踪访问,而且cookie在header里面被保留了下来。
十、模拟上传文件
在PHP手册的curl_setopt函数中,关于CURLOPT_POSTFIELDS有如下描述:
<code>全部数据使用HTTP协议中的"POST"操作来发送。要发送文件,在文件名前面加上@前缀并使用完整路径。这个参数可以通过urlencoded后的字符串类似'para1=val1¶2=val2&...'或使用一个以字段名为键值,字段数据为值的数组。如果value是一个数组,Content-Type头将会被设置成multipart/form-data。</code>
对于上传文件,这句话包含两个信息:
<code>1. 要上传文件,post的数据参数必须使用数组,使得Content-Type头将会被设置成multipart/form-data。 2. 要上传文件,在文件名前面加上@前缀并使用完整路径。</code>
因此,模拟文件上传可以按照如下实现:
<code>//上传D盘下的test.jpg文件,文件必须存在,否则curl处理失败且没有任何提示
$data = array('name' => 'Foo', 'file' => '@d:/test.jpg');
$ch = curl_init('http://localhost/upload.php');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
curl_exec($ch);</code>本地测试的时候,在upload.php文件中打印出\\(_POST和\$_FILES即可验证是否上传成功,如下: ``` _POST);
print_r($_FILES);
<code>输出结果类似:</code>
Array ( [name] => Foo ) Array ( [file] => Array ( [name] => test.jpg [type] => application/octet-stream [tmp_name] => D:\xampp\tmp\php2EA0.tmp [error] => 0 [size] => 139999 ) )
<code> 关于CURLOPT_POSTFIELDS的赋值,另外补充一句描述:</code>
传递一个数组到CURLOPT_POSTFIELDS,cURL会把数据编码成 multipart/form-data,而然传递一个URL-encoded字符串时,数据会被编码成 application/x-www-form-urlencoded。
<code>即:</code>
curl_setopt(\(ch, CURLOPT_POSTFIELDS, 'param1=val1¶m2=val2&...'); 和 curl_setopt(\)ch, CURLOPT_POSTFIELDS, array('param1' => 'val1', 'param2' => 'val2', ...));
<code>相当于html的form表单中:</code>

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Le didacticiel d'introduction officiel de Huawei au langage de programmation Cangjie est publié. Découvrez comment obtenir la version universelle du SDK dans un seul article.
Jun 25, 2024 am 08:05 AM
Le didacticiel d'introduction officiel de Huawei au langage de programmation Cangjie est publié. Découvrez comment obtenir la version universelle du SDK dans un seul article.
Jun 25, 2024 am 08:05 AM
Selon les informations de ce site du 24 juin, lors du discours d'ouverture de la conférence des développeurs Huawei HDC2024 le 21 juin, Gong Ti, président du département logiciel Huawei Terminal BG, a officiellement annoncé le langage de programmation Cangjie auto-développé par Huawei. Ce langage a été développé depuis 5 ans et est désormais disponible en avant-première pour les développeurs. Le site Web officiel des développeurs de Huawei a maintenant lancé la vidéo officielle du didacticiel d'introduction du langage de programmation Cangjie pour permettre aux développeurs de démarrer et de le comprendre. Ce didacticiel amènera les utilisateurs à découvrir Cangjie, à apprendre Cangjie et à appliquer Cangjie, notamment en utilisant le langage Cangjie pour estimer pi, calculer les règles de tige et de branche pour chaque mois de 2024, voir N façons d'exprimer les arbres binaires en langage Cangjie et utiliser l'énumération. types pour implémenter des calculs algébriques, la simulation du système de signaux à l'aide d'interfaces et d'extensions, et une nouvelle syntaxe à l'aide des macros Cangjie, etc. Ce site a une adresse d'accès au tutoriel : ht
 Après 5 ans de recherche et développement, le langage de programmation de nouvelle génération de Huawei « Cangjie » a officiellement lancé sa version préliminaire
Jun 22, 2024 am 09:54 AM
Après 5 ans de recherche et développement, le langage de programmation de nouvelle génération de Huawei « Cangjie » a officiellement lancé sa version préliminaire
Jun 22, 2024 am 09:54 AM
Ce site a rapporté le 21 juin que lors de la conférence des développeurs Huawei HDC2024 cet après-midi, Gong Ti, président du département logiciel Huawei Terminal BG, a officiellement annoncé le langage de programmation Cangjie auto-développé par Huawei et a publié une version préliminaire pour les développeurs du langage HarmonyOSNEXT Cangjie. C'est la première fois que Huawei publie publiquement le langage de programmation Cangjie. Gong Ti a déclaré : « En 2019, le projet de langage de programmation Cangjie est né chez Huawei. Après 5 ans d'accumulation de R&D et d'investissements importants en R&D, il rencontre enfin les développeurs mondiaux aujourd'hui. Le langage de programmation Cangjie intègre des fonctionnalités de langage moderne, une optimisation complète de la compilation et une implémentation du Runtime. et la prise en charge prête à l'emploi de la chaîne d'outils IDE créent une expérience de développement conviviale et d'excellentes performances de programme pour les développeurs. « Selon les rapports, le langage de programmation Cangjie est un outil d'intelligence tous scénarios.
 Huawei lance le recrutement bêta d'un aperçu du langage de programmation HarmonyOS NEXT Cangjie
Jun 22, 2024 am 04:07 AM
Huawei lance le recrutement bêta d'un aperçu du langage de programmation HarmonyOS NEXT Cangjie
Jun 22, 2024 am 04:07 AM
Selon les informations de ce site du 21 juin, le langage de programmation Cangjie développé par Huawei a été officiellement dévoilé aujourd'hui, et le responsable a annoncé le lancement de la version bêta du recrutement HarmonyOSNEXT Cangjie pour les développeurs de langage. Cette mise à niveau est une mise à niveau précoce vers la version préliminaire du développeur, qui fournit le SDK du langage Cangjie, les guides du développeur et les plug-ins DevEcoStudio associés permettant aux développeurs d'utiliser le langage Cangjie pour développer, déboguer et exécuter des applications HarmonyOSNext. Période d'inscription : du 21 juin 2024 au 21 octobre 2024 Conditions de candidature : Cet événement de recrutement HarmonyOSNEXT Cangjie Language Developer Preview Beta est ouvert uniquement aux développeurs suivants : 1) Les vrais noms ont été renseignés dans la certification Huawei Developer Alliance 2) Complete H ;
 L'Université de Tianjin et l'Université de Beihang sont profondément impliquées dans le projet « Cangjie » de Huawei et ont lancé le premier cadre de programmation d'agents d'IA « Cangqiong » basé sur des langages de programmation nationaux.
Jun 23, 2024 am 08:37 AM
L'Université de Tianjin et l'Université de Beihang sont profondément impliquées dans le projet « Cangjie » de Huawei et ont lancé le premier cadre de programmation d'agents d'IA « Cangqiong » basé sur des langages de programmation nationaux.
Jun 23, 2024 am 08:37 AM
Selon les informations de ce site du 22 juin, Huawei a présenté hier le langage de programmation auto-développé par Huawei, Cangjie, aux développeurs du monde entier. Il s'agit de la première apparition publique du langage de programmation Cangjie. Selon des enquêtes sur ce site, l'Université de Tianjin et l'Université d'aéronautique et d'astronautique de Pékin ont été profondément impliquées dans la recherche et le développement du « Cangjie » de Huawei. Université de Tianjin : compilateur de langage de programmation Cangjie L'équipe d'ingénierie logicielle du département d'intelligence et d'informatique de l'université de Tianjin s'est associée à l'équipe de Huawei Cangjie pour participer en profondeur à la recherche sur l'assurance qualité du compilateur de langage de programmation Cangjie. Selon certaines informations, le compilateur Cangjie est le logiciel de base en symbiose avec le langage de programmation Cangjie. Lors de la phase préparatoire du langage de programmation Cangjie, un compilateur de haute qualité qui lui correspond est devenu l'un des objectifs principaux. À mesure que le langage de programmation Cangjie évolue, le compilateur Cangjie est constamment mis à niveau et amélioré. Au cours des cinq dernières années, l'Université de Tianjin
 Partagez plusieurs frameworks de projets open source .NET liés à l'IA et au LLM
May 06, 2024 pm 04:43 PM
Partagez plusieurs frameworks de projets open source .NET liés à l'IA et au LLM
May 06, 2024 pm 04:43 PM
Le développement des technologies d’intelligence artificielle (IA) bat son plein aujourd’hui et elles ont montré un grand potentiel et une grande influence dans divers domaines. Aujourd'hui, Dayao partagera avec vous 4 cadres de projets liés au modèle d'IA open source .NET LLM, dans l'espoir de vous fournir une référence. https://github.com/YSGStudyHards/DotNetGuide/blob/main/docs/DotNet/DotNetProjectPicks.mdSemanticKernelSemanticKernel est un kit de développement logiciel (SDK) open source conçu pour intégrer de grands modèles de langage (LLM) tels qu'OpenAI, Azure
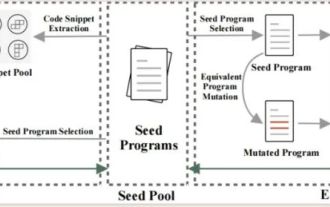
 Les indicateurs du MoE open source national explosent : capacités de niveau GPT-4, le prix de l'API n'est que de 1 %
May 07, 2024 pm 05:34 PM
Les indicateurs du MoE open source national explosent : capacités de niveau GPT-4, le prix de l'API n'est que de 1 %
May 07, 2024 pm 05:34 PM
Le dernier modèle open source national à grande échelle du MoE est devenu populaire juste après ses débuts. Les performances de DeepSeek-V2 atteignent le niveau GPT-4, mais il est open source, gratuit pour un usage commercial et le prix de l'API ne représente que 1 % de celui de GPT-4-Turbo. Par conséquent, dès sa sortie, il a immédiatement déclenché de nombreuses discussions. À en juger par les indicateurs de performance publiés, les capacités chinoises complètes de DeepSeekV2 dépassent celles de nombreux modèles open source. Dans le même temps, les modèles fermés tels que GPT-4Turbo et Wenkuai 4.0 sont également au premier échelon. La maîtrise complète de l'anglais se situe également au même premier échelon que LLaMA3-70B et surpasse Mixtral8x22B, qui est également un MoE. Il montre également de bonnes performances en connaissances, mathématiques, raisonnement, programmation, etc. Et prend en charge le contexte 128K. Imaginez ceci
 Le site Web officiel et les documents de développement du langage de programmation Cangjie développé par Huawei sont en ligne et s'intègrent pour la première fois à l'écosystème Hongmeng.
Jun 22, 2024 am 03:10 AM
Le site Web officiel et les documents de développement du langage de programmation Cangjie développé par Huawei sont en ligne et s'intègrent pour la première fois à l'écosystème Hongmeng.
Jun 22, 2024 am 03:10 AM
Selon les informations de ce site du 21 juin, avant la conférence des développeurs Huawei HDC2024, le langage de programmation Cangjie développé par Huawei a été officiellement dévoilé et le site officiel de Cangjie est désormais en ligne. L'introduction du site officiel montre que le langage de programmation Cangjie est un langage de programmation de nouvelle génération pour l'intelligence tous scénarios, axé sur « l'intelligence native, tous les scénarios naturels, les hautes performances et une sécurité renforcée ». Intégrez-vous à l'écosystème Hongmeng pour offrir aux développeurs une bonne expérience de programmation. Le site officiel joint à ce site présente ce qui suit : cadre de programmation intelligent natif intégré à AgentDSL, intégration organique du langage naturel et du langage de programmation, expression symbolique simplifiée, combinaison libre de modèles, prenant en charge le développement de diverses applications intelligentes. Exécution naturellement légère et évolutive pour toutes les scènes, conception modulaire en couches, quelle que soit la taille de la mémoire, elle peut être adaptée à l'extension de domaine pour tous les scénarios ;
 L'Université Tsinghua et Zhipu AI open source GLM-4 : lancent une nouvelle révolution dans le traitement du langage naturel
Jun 12, 2024 pm 08:38 PM
L'Université Tsinghua et Zhipu AI open source GLM-4 : lancent une nouvelle révolution dans le traitement du langage naturel
Jun 12, 2024 pm 08:38 PM
Depuis le lancement du ChatGLM-6B le 14 mars 2023, les modèles de la série GLM ont reçu une large attention et une grande reconnaissance. Surtout après que ChatGLM3-6B soit open source, les développeurs sont pleins d'attentes pour le modèle de quatrième génération lancé par Zhipu AI. Cette attente a finalement été pleinement satisfaite avec la sortie du GLM-4-9B. La naissance du GLM-4-9B Afin de donner aux petits modèles (10B et moins) des capacités plus puissantes, l'équipe technique de GLM a lancé ce nouveau modèle open source de la série GLM de quatrième génération : GLM-4-9B après près de six mois de exploration. Ce modèle compresse considérablement la taille du modèle tout en garantissant la précision, et offre une vitesse d'inférence plus rapide et une efficacité plus élevée. L’exploration de l’équipe technique du GLM n’a pas
