

如何用爬虫下载中国土地市场网的土地成交数据?

作为毕业狗想研究下土地出让方面的信息,需要每一笔的土地出让数据。想从中国土地市场网的土地成交结果公告(http://www.landchina.com/default.aspx?tabid=263&ComName=default)中点击每一笔土地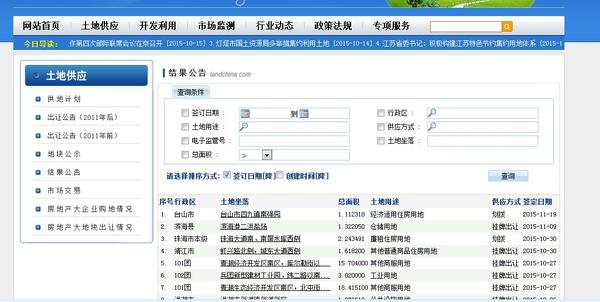 ,在跳转后的详细页面中下载“土地用途” “成交价格” “供地方式” “项目位置”等信息,
,在跳转后的详细页面中下载“土地用途” “成交价格” “供地方式” “项目位置”等信息,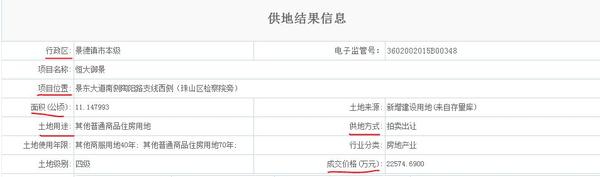 由于共有100多万笔土地成交信息,手动查找是不可能了,想问下能不能用爬虫给下载下来?以及预计难度和耗费时间?跪谢各位。
由于共有100多万笔土地成交信息,手动查找是不可能了,想问下能不能用爬虫给下载下来?以及预计难度和耗费时间?跪谢各位。
回复内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 |
|
之前帮老师爬过这个信息,从1995年-2015年有170多万条,算了下时间需要40多个小时才能爬完。我爬到2000年就没有继续爬了。当时写代码的时候刚学爬虫,不懂原理,发现这个网页点击下一页以及改变日期后,网址是不会变的,网址是不会变的,网址是不会变的Orz,对于新手来说根本不知道是为什么。后来就去找办法,学了点selenium,利用它来模拟浏览器操作,更改日期、点击下一页什么的都可以实现了。好处是简单粗暴,坏处是杀鸡用牛刀,占用了系统太多资源。再到后来,学会了一点抓包技术,知道了原来日期和换页都是通过post请求的。今天下午就把程序修改了一下,用post代替了原来的selenium。废话不说,上代码了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 |
|
1. 多线程
2. 防止封IP
3. 用Mongdb存储大型非结构化数据
了解更多可以访问探码科技大数据介绍页面:http://www.tanmer.com/bigdata 我抓过这个网站的结束合同,还是比较好抓的。抓完生成表格,注意的就是选择栏的异步地区等内容,需要对他的js下载下来队形异步请求。提交数据即可。请求的时候在他的主页有一个id。好像是这么个东西,去年做的,记不清了,我有源码可以给你分享。用java写的 我是爬虫小白,请教下,不是说不能爬取asp的页面吗?
详细内容页的地址是”default.aspx?tabid=386&comname=default&wmguid=75c725。。。“,网站是在default.aspx页读取数据库显示详细信息,不是说读不到数据库里的数据吗?

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !
Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Que signifie le code d'état http 520 ?
Oct 13, 2023 pm 03:11 PM
Que signifie le code d'état http 520 ?
Oct 13, 2023 pm 03:11 PM
Le code d'état HTTP 520 signifie que le serveur a rencontré une erreur inconnue lors du traitement de la demande et ne peut pas fournir d'informations plus spécifiques. Utilisé pour indiquer qu'une erreur inconnue s'est produite lorsque le serveur traitait la demande, ce qui peut être dû à des problèmes de configuration du serveur, à des problèmes de réseau ou à d'autres raisons inconnues. Cela est généralement dû à des problèmes de configuration du serveur, des problèmes de réseau, une surcharge du serveur ou des erreurs de codage. Si vous rencontrez une erreur de code d'état 520, il est préférable de contacter l'administrateur du site Web ou l'équipe d'assistance technique pour plus d'informations et d'assistance.
 Qu'est-ce que le code d'état http 403 ?
Oct 07, 2023 pm 02:04 PM
Qu'est-ce que le code d'état http 403 ?
Oct 07, 2023 pm 02:04 PM
Le code d'état HTTP 403 signifie que le serveur a rejeté la demande du client. La solution au code d'état http 403 est la suivante : 1. Vérifiez les informations d'authentification. Si le serveur requiert une authentification, assurez-vous que les informations d'identification correctes sont fournies ; 2. Vérifiez les restrictions d'adresse IP. Si le serveur a restreint l'adresse IP, assurez-vous que les informations d'identification sont correctes. l'adresse IP du client est restreinte. Sur liste blanche ou non sur liste noire ; 3. Vérifiez les paramètres d'autorisation du fichier. Si le code d'état 403 est lié aux paramètres d'autorisation du fichier ou du répertoire, assurez-vous que le client dispose des autorisations suffisantes pour accéder à ces fichiers ou répertoires. etc.
 Comprendre les scénarios d'application courants de redirection de pages Web et comprendre le code d'état HTTP 301
Feb 18, 2024 pm 08:41 PM
Comprendre les scénarios d'application courants de redirection de pages Web et comprendre le code d'état HTTP 301
Feb 18, 2024 pm 08:41 PM
Comprendre la signification du code d'état HTTP 301 : scénarios d'application courants de redirection de pages Web Avec le développement rapide d'Internet, les exigences des utilisateurs en matière d'interaction avec les pages Web sont de plus en plus élevées. Dans le domaine de la conception Web, la redirection de pages Web est une technologie courante et importante, mise en œuvre via le code d'état HTTP 301. Cet article explorera la signification du code d'état HTTP 301 et les scénarios d'application courants dans la redirection de pages Web. Le code d'état HTTP 301 fait référence à une redirection permanente (PermanentRedirect). Lorsque le serveur reçoit le message du client
 Comment utiliser Nginx Proxy Manager pour implémenter le saut automatique de HTTP à HTTPS
Sep 26, 2023 am 11:19 AM
Comment utiliser Nginx Proxy Manager pour implémenter le saut automatique de HTTP à HTTPS
Sep 26, 2023 am 11:19 AM
Comment utiliser NginxProxyManager pour implémenter le saut automatique de HTTP à HTTPS Avec le développement d'Internet, de plus en plus de sites Web commencent à utiliser le protocole HTTPS pour crypter la transmission des données afin d'améliorer la sécurité des données et la protection de la vie privée des utilisateurs. Le protocole HTTPS nécessitant la prise en charge d'un certificat SSL, un certain support technique est requis lors du déploiement du protocole HTTPS. Nginx est un serveur HTTP et un serveur proxy inverse puissants et couramment utilisés, et NginxProxy
 Envoyer une requête POST avec les données du formulaire à l'aide de la fonction http.PostForm
Jul 25, 2023 pm 10:51 PM
Envoyer une requête POST avec les données du formulaire à l'aide de la fonction http.PostForm
Jul 25, 2023 pm 10:51 PM
Utilisez la fonction http.PostForm pour envoyer une requête POST avec des données de formulaire. Dans le package http du langage Go, vous pouvez utiliser la fonction http.PostForm pour envoyer une requête POST avec des données de formulaire. Le prototype de la fonction http.PostForm est le suivant : funcPostForm(urlstring,dataurl.Values)(resp*http.Response,errerror)where, u
 HTTP 200 OK : comprendre la signification et le but d'une réponse réussie
Dec 26, 2023 am 10:25 AM
HTTP 200 OK : comprendre la signification et le but d'une réponse réussie
Dec 26, 2023 am 10:25 AM
Code d'état HTTP 200 : explorez la signification et l'utilisation des réponses réussies Les codes d'état HTTP sont des codes numériques utilisés pour indiquer l'état de la réponse d'un serveur. Parmi eux, le code d'état 200 indique que la demande a été traitée avec succès par le serveur. Cet article explorera la signification spécifique et l'utilisation du code d'état HTTP 200. Tout d’abord, comprenons la classification des codes d’état HTTP. Les codes d'état sont divisés en cinq catégories, à savoir 1xx, 2xx, 3xx, 4xx et 5xx. Parmi eux, 2xx indique une réponse réussie. Et 200 est le code d'état le plus courant dans 2xx
 Application rapide : analyse de cas de développement pratique du téléchargement HTTP asynchrone PHP de plusieurs fichiers
Sep 12, 2023 pm 01:15 PM
Application rapide : analyse de cas de développement pratique du téléchargement HTTP asynchrone PHP de plusieurs fichiers
Sep 12, 2023 pm 01:15 PM
Application rapide : analyse de cas de développement pratique de PHP Téléchargement HTTP asynchrone de plusieurs fichiers Avec le développement d'Internet, la fonction de téléchargement de fichiers est devenue l'un des besoins fondamentaux de nombreux sites Web et applications. Pour les scénarios dans lesquels plusieurs fichiers doivent être téléchargés en même temps, la méthode de téléchargement synchrone traditionnelle est souvent inefficace et prend du temps. Pour cette raison, utiliser PHP pour télécharger plusieurs fichiers de manière asynchrone via HTTP est devenu une solution de plus en plus courante. Cet article analysera en détail comment utiliser le HTTP asynchrone PHP à travers un cas de développement réel.
 Problèmes et solutions courants en matière de communication et de sécurité réseau en C#
Oct 09, 2023 pm 09:21 PM
Problèmes et solutions courants en matière de communication et de sécurité réseau en C#
Oct 09, 2023 pm 09:21 PM
Problèmes courants de communication réseau et de sécurité et solutions en C# À l'ère d'Internet d'aujourd'hui, la communication réseau est devenue un élément indispensable du développement logiciel. En C#, nous rencontrons généralement certains problèmes de communication réseau, tels que la sécurité de la transmission des données, la stabilité de la connexion réseau, etc. Cet article abordera en détail les problèmes courants de communication réseau et de sécurité en C# et fournira les solutions correspondantes et des exemples de code. 1. Problèmes de communication réseau Interruption de la connexion réseau : pendant le processus de communication réseau, la connexion réseau peut être interrompue, ce qui peut entraîner
