
 développement back-end
Tutoriel Python
为什么0.1+0.2=0.30000000000000004而1.1+2.2=3.3000000000000003?
développement back-end
Tutoriel Python
为什么0.1+0.2=0.30000000000000004而1.1+2.2=3.3000000000000003?
为什么0.1+0.2=0.30000000000000004而1.1+2.2=3.3000000000000003?

如图: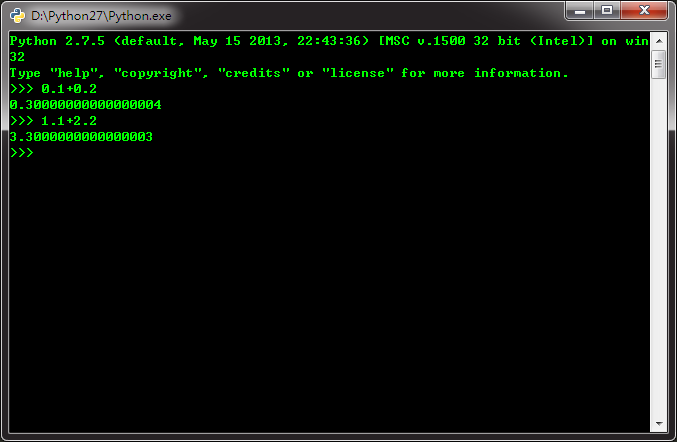
回复内容:
不管是什么数, 在计算机中最终都会被转化为 0 和 1 进行存储, 所以需要弄明白以下几点问题- 一个小数如何转化为二进制
- 浮点数的二进制如何存储
浮点数的二进制表示
首先我们要了解浮点数二进制表示, 有以下两个原则:
- 整数部分对 2 取余然后逆序排列
- 小数部分乘 2 取整数部分, 然后顺序排列
0.1 的表示是什么?
我们继续按照浮点数的二进制表示来计算
0.1 * 2 = 0.2 整数部分取 0
0.2 * 2 = 0.4 整数部分取 0
0.4 * 2 = 0.8 整数部分取 0
0.8 * 2 = 1.6 整数部分取 1
0.6 * 2 = 1.2 整数部分取 1
0.2 * 2 = 0.4 整数部分取 0
…
所以你会发现, 0.1 的二进制表示是 0.00011001100110011001100110011……0011
0011作为二进制小数的循环节不断的进行循环.
这就引出了一个问题, 你永远不能存下 0.1 的二进制, 即使你把全世界的硬盘都放在一起, 也存不下 0.1 的二进制小数.
浮点数的二进制存储
Python 和 C 一样, 采用 IEEE 754 规范来存储浮点数. IEEE 754 对双精度浮点数的存储规范将 64 bit 分为 3 部分.
- 第 1 bit 位用来存储 符号, 决定这个数是正数还是负数
- 然后使用 11 bit 来存储指数部分
- 剩下的 52 bit 用来存储尾数
Double-precision_floating-point_format
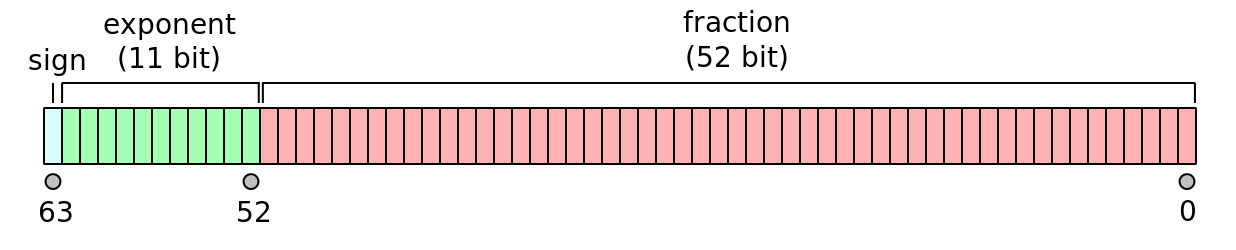

而且可以指出的是, double 能存储的数的个数是有限的, double 能代表的数必然不超过 2^64 个, 那么现实世界上有多少个小数呢? 无限个. 计算机能做的只能是一个接近这个小数的值, 是这个值在一定精度下与逻辑认为的值相等. 换句话说, 每个小数的存储(但是不是所有的), 都会伴有精度的丢失.
浮点数计算的问题
现在我们可以回顾你提出的问题
0.1 + 0.2 == 0.30.1 在计算机存储中真正的数字是 0.1000000000000000055511151231257827021181583404541015625
0.2 是
0.200000000000000011102230246251565404236316680908203125
0.3 是
0.299999999999999988897769753748434595763683319091796875
这就是为什么 0.1 + 0.2 != 0.3 的原因
至于 1.1 + 2.2 与之类似
首先声明这不是bug,原因在与十进制到二进制的转换导致的精度问题!其次这几乎出现在很多的编程语言中:C、C++、Java、Javascript、Python中,准确的说:“使用了IEEE754浮点数格式”来存储浮点类型(float 32,double 64)的任何编程语言都有这个问题!简要介绍下IEEE 754浮点格式:它用科学记数法以底数为2的小数来表示浮点数。IEEE浮点数(共32位)用1位表示数字符号,用8为表示指数,用23为来表示尾数(即小数部分)。此处指数用移码存储,尾数则是原码(没有符号位)。之所以用移码是因为移码的负数的符号位为0,这可以保证浮点数0的所有位都是0。双精度浮点数(64位),使用1位符号位、11位指数位、52位尾数位来表示。
因为科学记数法有很多种方式来表示给定的数字,所以要规范化浮点数,以便用底数为2并且小数点左边为1的小数来表示(注意是二进制的,所以只要不为0则一定有一位为1),按照需要调节指数就可以得到所需的数字。例如:十进制的1.25 => 二进制的1.01 => 则存储时指数为0、尾数为1.01、符号位为0.(十进制转二进制)
回到开头,为什么“0.1+0.2=0.30000000000000004”?首先声明这是javascript语言计算的结果(注意Javascript的数字类型是以64位的IEEE 754格式存储的)。正如同十进制无法精确表示1/3(0.33333...)一样,二进制也有无法精确表示的值。例如1/10。64位浮点数情况下:
十进制0.1=> 二进制0.00011001100110011...(循环0011)
=>尾数为1.1001100110011001100...1100(共52位,除了小数点左边的1),指数为-4(二进制移码为00000000010),符号位为0=> 存储为:0 00000000100 10011001100110011...11001=> 因为尾数最多52位,所以实际存储的值为0.00011001100110011001100110011001100110011001100110011001
十进制0.2=> 二进制0.0011001100110011...(循环0011)
=>尾数为1.1001100110011001100...1100(共52位,除了小数点左边的1),指数为-3(二进制移码为00000000011),符号位为0=> 存储为:0 00000000011 10011001100110011...11001
因为尾数最多52位,所以实际存储的值为0.00110011001100110011001100110011001100110011001100110011
两者相加:
0.00011001100110011001100110011001100110011001100110011001 + 0.00110011001100110011001100110011001100110011001100110011 = 0.01001100110011001100110011001100110011001100110011001100
转换成10进制之后得到:0.30000000000000004!
相关链接:
Language agnostic - Is floating point math broken? - Stack Overflow http://stackoverflow.com/questions/588004/is-floating-point-math-broken
Floating Point Arithmetic and Agent Based Models http://www.macaulay.ac.uk/fearlus/floating-point/ 因为二进制无法准确的描述十进制小数. 所以float的运算存在误差.
1.1+2.2跟0.1+0.2的计算结果不同是因为精度问题. 比如:
1.1= 1000000101E-9
0.1=101011....E-15
(上述数值通过手工计算可能存在问题)
具体题主可以看一下小数在计算机内存中的存储方式.

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment utiliser Python pour trouver la distribution ZIPF d'un fichier texte
Mar 05, 2025 am 09:58 AM
Comment utiliser Python pour trouver la distribution ZIPF d'un fichier texte
Mar 05, 2025 am 09:58 AM
Ce tutoriel montre comment utiliser Python pour traiter le concept statistique de la loi de Zipf et démontre l'efficacité de la lecture et du tri de Python de gros fichiers texte lors du traitement de la loi. Vous vous demandez peut-être ce que signifie le terme distribution ZIPF. Pour comprendre ce terme, nous devons d'abord définir la loi de Zipf. Ne vous inquiétez pas, je vais essayer de simplifier les instructions. La loi de Zipf La loi de Zipf signifie simplement: dans un grand corpus en langage naturel, les mots les plus fréquents apparaissent environ deux fois plus fréquemment que les deuxième mots fréquents, trois fois comme les troisième mots fréquents, quatre fois comme quatrième mots fréquents, etc. Regardons un exemple. Si vous regardez le corpus brun en anglais américain, vous remarquerez que le mot le plus fréquent est "th
 Comment utiliser la belle soupe pour analyser HTML?
Mar 10, 2025 pm 06:54 PM
Comment utiliser la belle soupe pour analyser HTML?
Mar 10, 2025 pm 06:54 PM
Cet article explique comment utiliser la belle soupe, une bibliothèque Python, pour analyser HTML. Il détaille des méthodes courantes comme find (), find_all (), select () et get_text () pour l'extraction des données, la gestion de diverses structures et erreurs HTML et alternatives (Sel
 Comment effectuer l'apprentissage en profondeur avec TensorFlow ou Pytorch?
Mar 10, 2025 pm 06:52 PM
Comment effectuer l'apprentissage en profondeur avec TensorFlow ou Pytorch?
Mar 10, 2025 pm 06:52 PM
Cet article compare TensorFlow et Pytorch pour l'apprentissage en profondeur. Il détaille les étapes impliquées: préparation des données, construction de modèles, formation, évaluation et déploiement. Différences clés entre les cadres, en particulier en ce qui concerne le raisin informatique
 Sérialisation et désérialisation des objets Python: partie 1
Mar 08, 2025 am 09:39 AM
Sérialisation et désérialisation des objets Python: partie 1
Mar 08, 2025 am 09:39 AM
La sérialisation et la désérialisation des objets Python sont des aspects clés de tout programme non trivial. Si vous enregistrez quelque chose dans un fichier Python, vous effectuez une sérialisation d'objets et une désérialisation si vous lisez le fichier de configuration, ou si vous répondez à une demande HTTP. Dans un sens, la sérialisation et la désérialisation sont les choses les plus ennuyeuses du monde. Qui se soucie de tous ces formats et protocoles? Vous voulez persister ou diffuser des objets Python et les récupérer dans son intégralité plus tard. C'est un excellent moyen de voir le monde à un niveau conceptuel. Cependant, à un niveau pratique, le schéma de sérialisation, le format ou le protocole que vous choisissez peut déterminer la vitesse, la sécurité, le statut de liberté de maintenance et d'autres aspects du programme
 Modules mathématiques en python: statistiques
Mar 09, 2025 am 11:40 AM
Modules mathématiques en python: statistiques
Mar 09, 2025 am 11:40 AM
Le module statistique de Python fournit de puissantes capacités d'analyse statistique de données pour nous aider à comprendre rapidement les caractéristiques globales des données, telles que la biostatistique et l'analyse commerciale. Au lieu de regarder les points de données un par un, regardez simplement des statistiques telles que la moyenne ou la variance pour découvrir les tendances et les fonctionnalités des données d'origine qui peuvent être ignorées et comparer les grands ensembles de données plus facilement et efficacement. Ce tutoriel expliquera comment calculer la moyenne et mesurer le degré de dispersion de l'ensemble de données. Sauf indication contraire, toutes les fonctions de ce module prennent en charge le calcul de la fonction moyenne () au lieu de simplement additionner la moyenne. Les nombres de points flottants peuvent également être utilisés. Importer au hasard Statistiques d'importation de fracTI
 Gestion des erreurs professionnelles avec Python
Mar 04, 2025 am 10:58 AM
Gestion des erreurs professionnelles avec Python
Mar 04, 2025 am 10:58 AM
Dans ce tutoriel, vous apprendrez à gérer les conditions d'erreur dans Python d'un point de vue système entier. La gestion des erreurs est un aspect critique de la conception, et il traverse les niveaux les plus bas (parfois le matériel) jusqu'aux utilisateurs finaux. Si y
 Quelles sont les bibliothèques Python populaires et leurs utilisations?
Mar 21, 2025 pm 06:46 PM
Quelles sont les bibliothèques Python populaires et leurs utilisations?
Mar 21, 2025 pm 06:46 PM
L'article traite des bibliothèques Python populaires comme Numpy, Pandas, Matplotlib, Scikit-Learn, Tensorflow, Django, Flask et Demandes, détaillant leurs utilisations dans le calcul scientifique, l'analyse des données, la visualisation, l'apprentissage automatique, le développement Web et H et H
 Stracage des pages Web en Python avec une belle soupe: recherche et modification DOM
Mar 08, 2025 am 10:36 AM
Stracage des pages Web en Python avec une belle soupe: recherche et modification DOM
Mar 08, 2025 am 10:36 AM
Ce tutoriel s'appuie sur l'introduction précédente à la belle soupe, en se concentrant sur la manipulation de Dom au-delà de la simple navigation sur les arbres. Nous explorerons des méthodes et techniques de recherche efficaces pour modifier la structure HTML. Une méthode de recherche DOM commune est ex
