

L'ensemble du processus de création d'un robot avec NodeJS_node.js

Aujourd'hui, apprenons également le tutoriel crawler de Tang, puis suivons l'exploration simple de CNode.
Créer un projet craelr-demo
Nous créons d'abord un projet Express, puis supprimons tout le contenu du fichier app.js, car nous n'avons pas besoin d'afficher le contenu sur le Web pour le moment. Bien entendu, on peut aussi directement npm install express dans un dossier vide pour utiliser les fonctions Express dont nous avons besoin.
Analyse du site Web cible
Comme le montre l'image, cela fait partie de la balise div sur la page d'accueil de CNode. Nous utilisons cette série d'identifiants et de classes pour localiser les informations dont nous avons besoin.
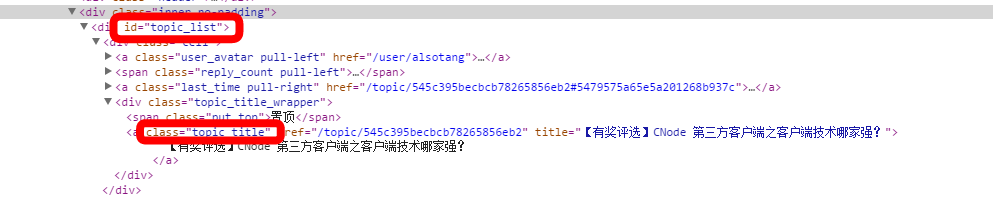
Utilisez le superagent pour obtenir les données sources
superagent est une bibliothèque Http utilisée par l'API ajax Son utilisation est similaire à jQuery Nous lançons une requête get via celle-ci et affichons le résultat dans la fonction de rappel.
var express = require('express');
var url = require('url'); //Analyser l'url de l'opération
var superagent = require('superagent'); //N'oubliez pas de npm install
pour ces trois dépendances externes var cheerio = require('cheerio');
var eventproxy = require('eventproxy');
var targetUrl = 'https://cnodejs.org/';
superagent.get(targetUrl)
.end(function (err, res) {
console.log(res);
});
Son résultat res est un objet contenant des informations sur l'URL cible, et le contenu du site Web est principalement dans son texte (chaîne).
Utilisez cheerio pour analyser
cheerio agit comme une fonction jQuery côté serveur. Nous utilisons d'abord son .load() pour charger du HTML, puis filtrons les éléments via le sélecteur CSS.
var $ = cheerio.load(res.text);
//Filtrer les données via le sélecteur CSS
$('#topic_list .topic_title').each(function (idx, element) {
console.log(élément);
});
Le résultat est un objet. Appelez la fonction .each(function(index, element)) pour parcourir chaque objet et renvoyer les éléments HTML DOM.

Le résultat de la sortie console.log($element.attr('title')); est 广州 2014年12月06日 NodeParty 之 UC 场
Les titres comme console.log($element.attr('href')); sont affichés sous forme d'URL comme /topic/545c395becbcb78265856eb2. Utilisez ensuite la fonction url.resolve() de NodeJS1 pour compléter l'URL complète.
superagent.get(tUrl)
.end(function (err, res) {
Si (erreur) {
return console.error(err);
>
var topicUrls = [];
var $ = cheerio.load(res.text);
//Obtenez tous les liens sur la page d'accueil
$('#topic_list .topic_title').each(function (idx, element) {
var $element = $(element);
var href = url.resolve(tUrl, $element.attr('href'));
console.log(href);
//topicUrls.push(href);
});
});
Utilisez eventproxy pour explorer simultanément le contenu de chaque sujet
Le didacticiel montre des exemples de méthodes (séries) profondément imbriquées et de méthodes de compteur. Eventproxy utilise des méthodes d'événement (parallèles) pour résoudre ce problème. Lorsque toute l'exploration est terminée, eventproxy reçoit le message d'événement et appelle automatiquement la fonction de traitement pour vous.
//Première étape : obtenir une instance d'eventproxy
var ep = new eventproxy();
//Étape 2 : Définir la fonction de rappel pour les événements d'écoute.
//La méthode after est une surveillance répétée
//params : eventname(String) nom de l'événement, times(Number) nombre de temps d'écoute, fonction de rappel
ep.after('topic_html', topicUrls.length, function(topics){
// topic est un tableau contenant les 40 paires
dans ep.emit('topic_html', pair) 40 fois //.map
sujets = sujets.map(fonction(topicPair){
//utiliser cheerio
var topicUrl = topicPair[0];
var topicHtml = topicPair[1];
var $ = cheerio.load(topicHtml);
retour ({
titre : $('.topic_full_title').text().trim(),
href : topicUrl,
commentaire1 : $('.reply_content').eq(0).text().trim()
});
});
//résultat
console.log('résultat :');
console.log(sujets);
});
//Étape 3 : Déterminez le
qui libère le message d'événement topicUrls.forEach (fonction (topicUrl) {
Superagent.get(topicUrl)
.end(function (err, res) {
console.log('fetch 'topicUrl 'avec succès');
ep.emit('topic_html', [topicUrl, res.text]);
});
});
Les résultats sont les suivants
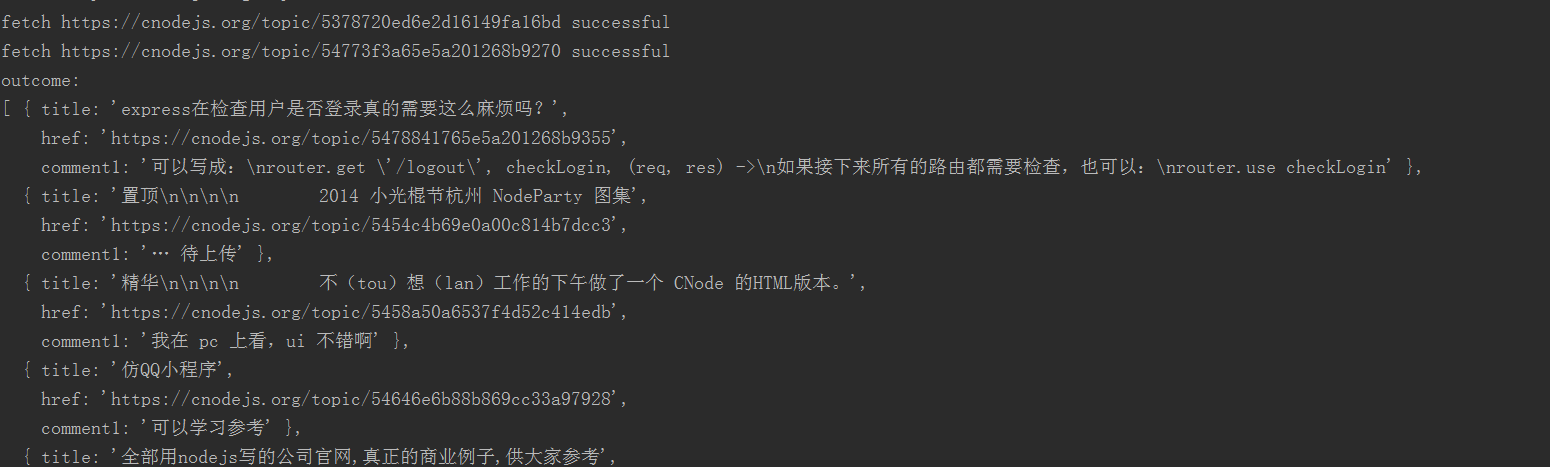
Exercice prolongé (défi)
Obtenir le nom d'utilisateur et les points du message
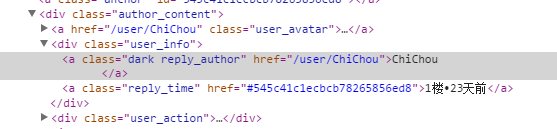
Recherchez le nom de classe de l'utilisateur qui a commenté dans le code source de la page de l'article. Le nom de classe est réponse_auteur. Comme vous pouvez le voir dans le premier élément de console.log $('.reply_author').get(0), tout ce dont nous avons besoin est ici.
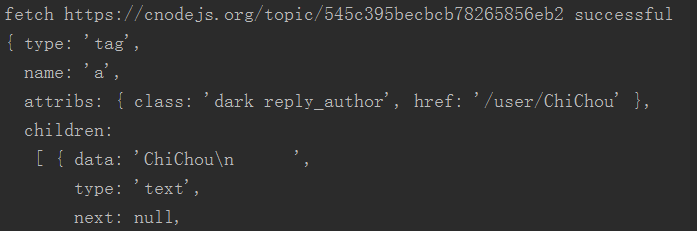
Tout d’abord, explorons un article et obtenons tout ce dont nous avons besoin en même temps.
var userHref = url.resolve(tUrl, $('.reply_author').get(0).attribs.href);
console.log(userHref);
console.log($('.reply_author').get(0).children[0].data);
Nous pouvons capturer des informations sur les points via https://cnodejs.org/user/username
$('.reply_author').each(function (idx, element) {
var $élément = $(élément);
console.log($element.attr('href'));
});
Sur la page d'informations utilisateur $('.big').text().trim() se trouvent les informations sur les points.
Utilisez la fonction .get(0) de cheerio pour obtenir le premier élément.
var userHref = url.resolve(tUrl, $('.reply_author').get(0).attribs.href);
console.log(userHref);
Ceci n'est qu'une capture d'un seul article, il en reste encore 40 qui doivent être modifiés.

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 La différence entre nodejs et vuejs
Apr 21, 2024 am 04:17 AM
La différence entre nodejs et vuejs
Apr 21, 2024 am 04:17 AM
Node.js est un environnement d'exécution JavaScript côté serveur, tandis que Vue.js est un framework JavaScript côté client permettant de créer des interfaces utilisateur interactives. Node.js est utilisé pour le développement côté serveur, comme le développement d'API de service back-end et le traitement des données, tandis que Vue.js est utilisé pour le développement côté client, comme les applications monopage et les interfaces utilisateur réactives.
 Nodejs est-il un framework backend ?
Apr 21, 2024 am 05:09 AM
Nodejs est-il un framework backend ?
Apr 21, 2024 am 05:09 AM
Node.js peut être utilisé comme framework backend car il offre des fonctionnalités telles que des performances élevées, l'évolutivité, la prise en charge multiplateforme, un écosystème riche et une facilité de développement.
 Comment connecter Nodejs à la base de données MySQL
Apr 21, 2024 am 06:13 AM
Comment connecter Nodejs à la base de données MySQL
Apr 21, 2024 am 06:13 AM
Pour vous connecter à une base de données MySQL, vous devez suivre ces étapes : Installez le pilote mysql2. Utilisez mysql2.createConnection() pour créer un objet de connexion contenant l'adresse de l'hôte, le port, le nom d'utilisateur, le mot de passe et le nom de la base de données. Utilisez connection.query() pour effectuer des requêtes. Enfin, utilisez connection.end() pour mettre fin à la connexion.
 Quelle est la différence entre les fichiers npm et npm.cmd dans le répertoire d'installation de nodejs ?
Apr 21, 2024 am 05:18 AM
Quelle est la différence entre les fichiers npm et npm.cmd dans le répertoire d'installation de nodejs ?
Apr 21, 2024 am 05:18 AM
Il existe deux fichiers liés à npm dans le répertoire d'installation de Node.js : npm et npm.cmd. Les différences sont les suivantes : différentes extensions : npm est un fichier exécutable et npm.cmd est un raccourci de fenêtre de commande. Utilisateurs Windows : npm.cmd peut être utilisé à partir de l'invite de commande, npm ne peut être exécuté qu'à partir de la ligne de commande. Compatibilité : npm.cmd est spécifique aux systèmes Windows, npm est disponible multiplateforme. Recommandations d'utilisation : les utilisateurs Windows utilisent npm.cmd, les autres systèmes d'exploitation utilisent npm.
 Quelles sont les variables globales dans nodejs
Apr 21, 2024 am 04:54 AM
Quelles sont les variables globales dans nodejs
Apr 21, 2024 am 04:54 AM
Les variables globales suivantes existent dans Node.js : Objet global : global Module principal : processus, console, nécessiter Variables d'environnement d'exécution : __dirname, __filename, __line, __column Constantes : undefined, null, NaN, Infinity, -Infinity
 Y a-t-il une grande différence entre nodejs et java ?
Apr 21, 2024 am 06:12 AM
Y a-t-il une grande différence entre nodejs et java ?
Apr 21, 2024 am 06:12 AM
Les principales différences entre Node.js et Java résident dans la conception et les fonctionnalités : Piloté par les événements ou piloté par les threads : Node.js est piloté par les événements et Java est piloté par les threads. Monothread ou multithread : Node.js utilise une boucle d'événements monothread et Java utilise une architecture multithread. Environnement d'exécution : Node.js s'exécute sur le moteur JavaScript V8, tandis que Java s'exécute sur la JVM. Syntaxe : Node.js utilise la syntaxe JavaScript, tandis que Java utilise la syntaxe Java. Objectif : Node.js convient aux tâches gourmandes en E/S, tandis que Java convient aux applications de grande entreprise.
 Nodejs est-il un langage de développement back-end ?
Apr 21, 2024 am 05:09 AM
Nodejs est-il un langage de développement back-end ?
Apr 21, 2024 am 05:09 AM
Oui, Node.js est un langage de développement backend. Il est utilisé pour le développement back-end, notamment la gestion de la logique métier côté serveur, la gestion des connexions à la base de données et la fourniture d'API.
 Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Étapes de déploiement de serveur pour un projet Node.js : Préparez l'environnement de déploiement : obtenez l'accès au serveur, installez Node.js, configurez un référentiel Git. Créez l'application : utilisez npm run build pour générer du code et des dépendances déployables. Téléchargez le code sur le serveur : via Git ou File Transfer Protocol. Installer les dépendances : connectez-vous en SSH au serveur et installez les dépendances de l'application à l'aide de npm install. Démarrez l'application : utilisez une commande telle que node index.js pour démarrer l'application ou utilisez un gestionnaire de processus tel que pm2. Configurer un proxy inverse (facultatif) : utilisez un proxy inverse tel que Nginx ou Apache pour acheminer le trafic vers votre application
