10000 contenu connexe trouvé

Comment pouvons-nous extraire des tableaux de PDF sans OCR ?
Présentation de l'article:Extraction de tableaux sans OCR à partir de documents PDF Les documents PDF contiennent souvent des tableaux, qui sont des structures de données essentielles pour de nombreuses applications. Cependant,...
2024-11-01
commentaire 0
1141

Analyse de documents rapide et sale : combiner GOT-OCR et LLama en Python
Présentation de l'article:Explorons-nous pour effectuer une analyse OCR LL pour une image. Est-ce que cela sera la meilleure méthode proposée par un expert avec des décennies d'expérience ? Pas vraiment. Mais cela vient de quelqu'un qui adopte une approche similaire dans la vie réelle.
2025-01-09
commentaire 0
760
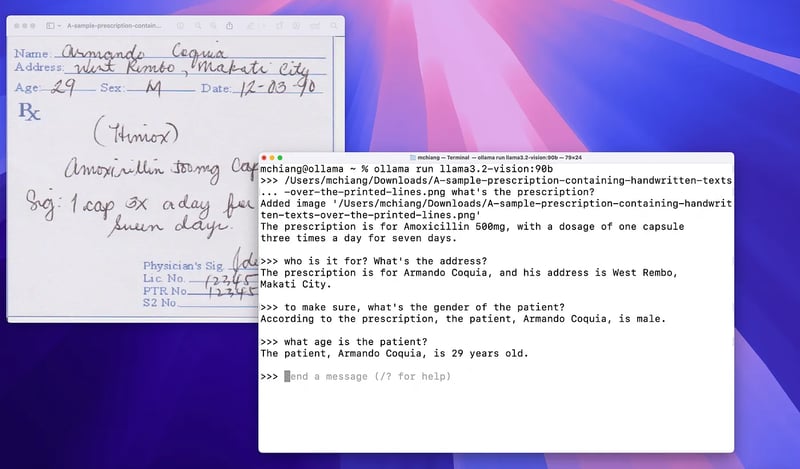
Ollama-OCR pour l'OCR de haute précision avec Ollama
Présentation de l'article:Llama 3.2-Vision est un grand modèle de langage multimodal disponible en tailles 11B et 90B, capable de traiter à la fois les entrées de texte et d'image pour générer des sorties de texte. Le modèle excelle dans la reconnaissance visuelle, le raisonnement d'image, la description d'image et la réponse
2024-11-27
commentaire 0
638

Existe-t-il une implémentation OCR en Java pur ?
Présentation de l'article:Implémentation Java OCRLa question se pose : existe-t-il une implémentation Java pure de l'OCR ? L'utilisateur exprime sa curiosité quant à ses performances et...
2024-11-17
commentaire 0
555

Les tableaux peuvent-ils être extraits de ce PDF sans OCR ?
Présentation de l'article:Extraction de tableaux structurés à partir de PDFExtraire des tableaux structurés à partir de documents PDF peut être une tâche difficile, en particulier pour les fichiers non image....
2024-10-29
commentaire 0
696

Existe-t-il une implémentation purement Java de l'OCR ?
Présentation de l'article:Implémentation Java OCR La question se pose de savoir s'il existe des implémentations Java pures de l'OCR. Cette enquête découle de la curiosité sur la façon dont l'OCR...
2024-11-11
commentaire 0
434














